



ComfyUI整合包是艺术创作领域的一大突破,它结合了Stable Diffusion的先进技术和Lora模型的创意潜力,为AI绘画提供了一套完整的工作流解决方案。本文将为您详细介绍如何利用ComfyUI整合包和1000套工作流,轻松成为AI绘画大师。
ComfyUI整合包概述
ComfyUI整合包是专为AI绘画设计的强大工具,它集成了Stable Diffusion和Lora模型,提供一站式绘画体验。
该整合包不仅简化了绘画流程,还提供了丰富的功能,如提示词编辑、参数调整、图像优化等,让艺术创作更加轻松和高效。
高效使用ComfyUI整合包的关键
选择合适的模板:ComfyUI整合包提供了1000套工作流模板,您可以根据需求选择最适合的模板。
输入精准的提示词:提示词的选择对生成图像的效果至关重要,需要根据主题和风格选择合适的提示词。
调整参数:在ComfyUI整合包中调整图像参数,如亮度、对比度、色彩饱和度等,以达到理想的效果。
生成和优化:生成图像后,可以进一步调整和优化,以达到最终的艺术效果。
创作步骤:使用ComfyUI整合包进行艺术创作
确定主题和风格:明确想要创作的AI艺术风格和主题。
选择合适的模板:根据主题和风格选择合适的模板。
输入提示词:根据主题输入合适的提示词,以引导生成图像。
调整参数:在ComfyUI整合包中调整图像参数,如亮度、对比度、色彩饱和度等,以达到理想的效果。
生成和优化:生成图像后,可以进一步调整和优化,以达到最终的艺术效果。

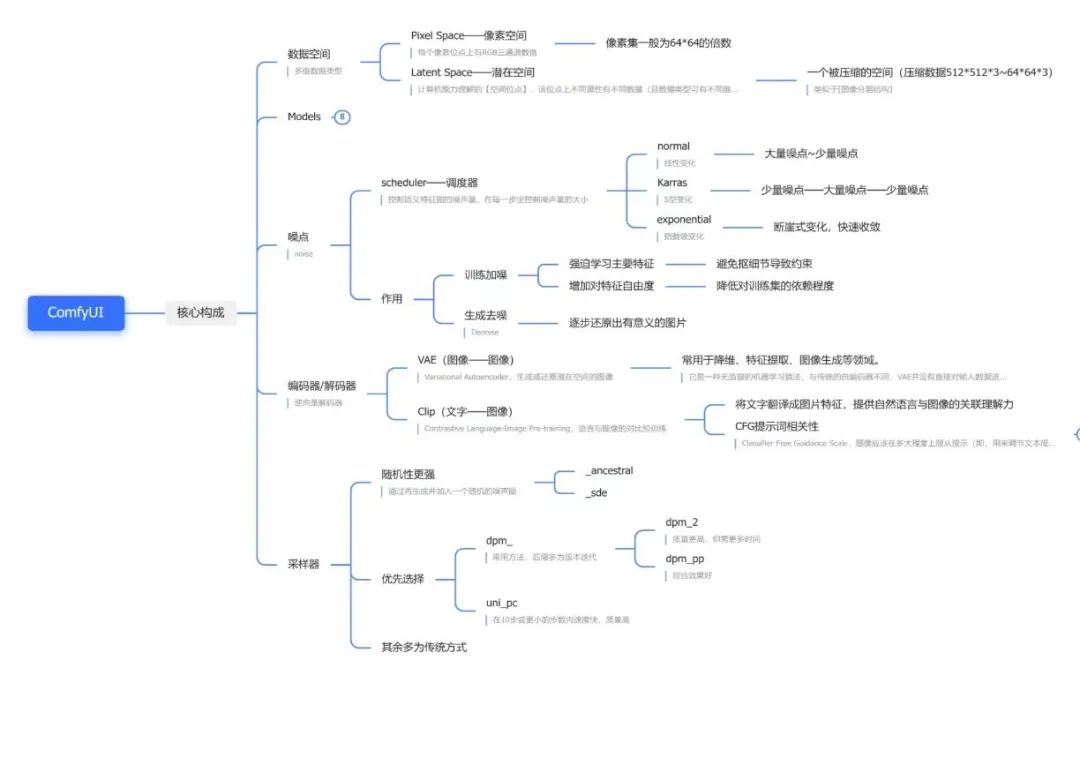
一、SD主流 UI
Stable Diffusion(SD)因为其开源特性,有着较高的受欢迎程度,并且基于SD的开源社区及教程、插件等,都是所有工具里最多的。基于SD,有不同的操作界面,可以理解为一个工具的不同客户端。WebUI和ComfyUI是两种较为流行的操作界面选项
- WebUI :
优点:界面友好,插件丰富,新手小白基本也能秒上手
缺点:吃显存,对配置要求较高,出图较慢
- ComfyUI :
优点:性能好,速度快,支持工作流的导入导出分享,对小显存友好(GPU小于3G以下依然可以工作),基于工作流,对出图逻辑理解更清晰
缺点:对新手用户不太友好,有一定学习成本
二者各有优缺点,根据自身情况选择即可。
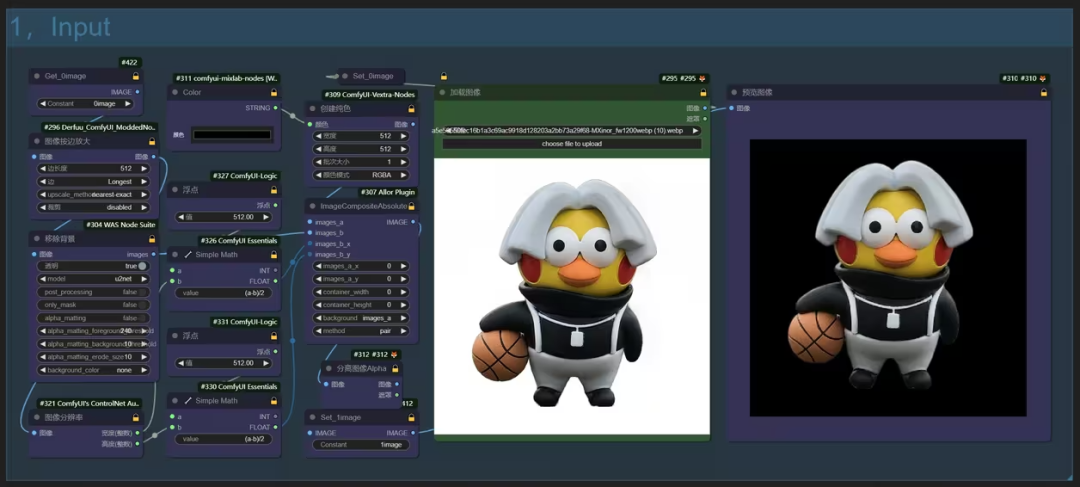
我为什么选择Comfyui?
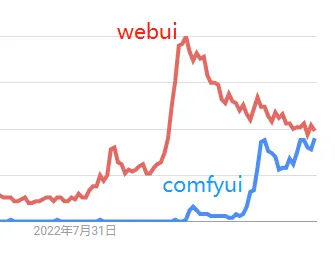
Comfyui的热度持续上升,在谷歌搜索上,有越来越多的人开始关注Comfyui。为什么会有越来越多的人关注?因为大家使用webui久了之后,发现很难对生成过程有完全的控制,或者一张图片的生产不是点击几下就能完成的,它有很多到工序:主体、配景、背景、风格、文字、特效等等各种各样的细节问题需要去控制,如果全部采用webui,操作起来非常麻烦,全部需要反复手工(尤其是要守在电脑前一个个去操作),而采用Comfyui,搭建完工作流程后,只需要点击运行,即可全流程自动完成。
二、ComfyUI 能干啥?
-
- 基础文生图
-
- 基础图生图
-
- 真人转动漫/动漫转真人
-
- 线稿上色
-
- 老旧照片修复
-
- 隐藏艺术字
-
- 改变人物姿态
-
- 四维彩超宝宝长相预测
-
- 红包封面
-
- 真人电子AI写真定制
-
- 赛博朋克风格转换
-
- 专属表情包
-
- 手机壁纸
-
14. 更多:这里不一一举例了,类似的玩法在网上可以看到很多,ComfyUI只是一个工具,具体如何应用,就要依靠自身的想象力了



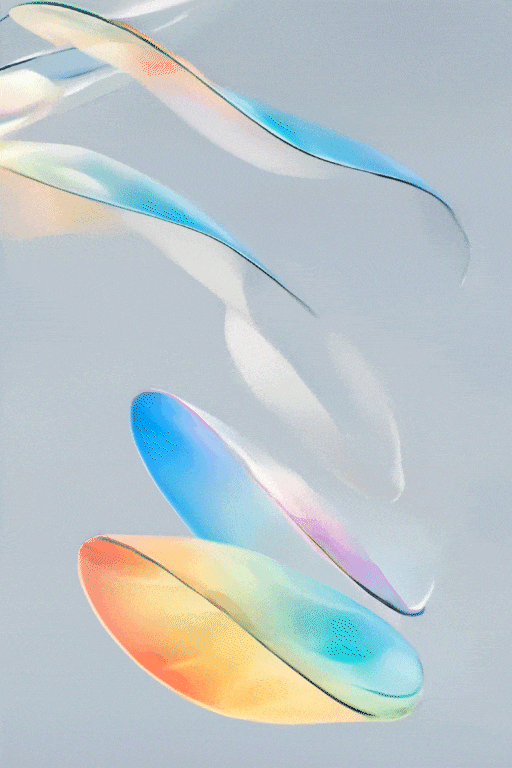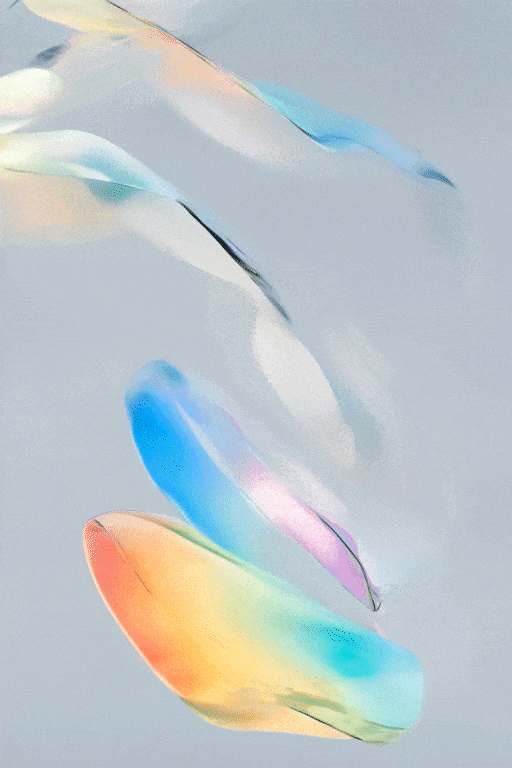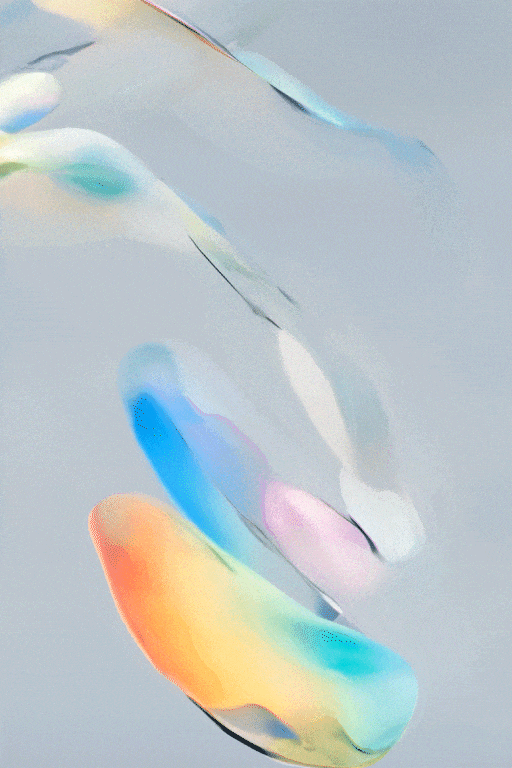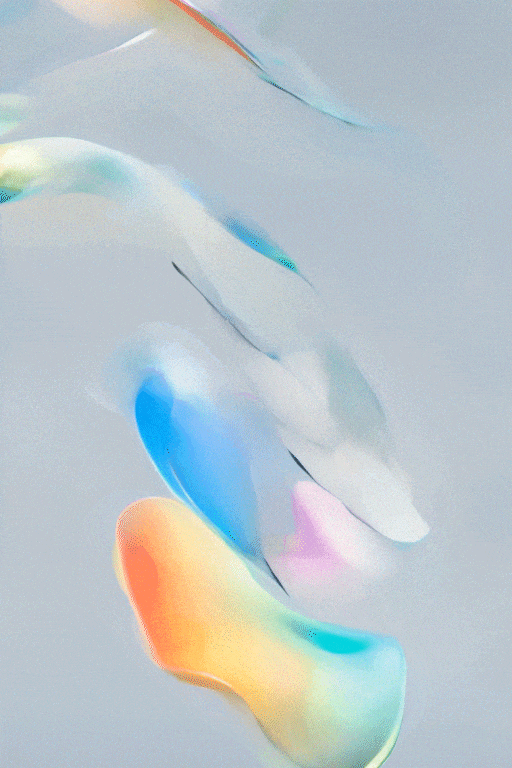
SVD图文转视频的效果展示
ComfyUI 安装方式
1.在b 站或后期圈gzh 下载整合包完成后然后解压。
使用的磁盘最好有20g以上的空间,因为再下载一些模型还是比较占用磁盘空间的。
“A绘世启动器.exe”文件即为一键启动文件,可以先不启动,先下载好模型。
下载模型,或者和webui共用模型 模型文件通常以.safetensors结尾。
首先将comfy ui根目录下的“extra_model_paths.yaml.example”文件重命名为“extra_model_paths.yaml”。
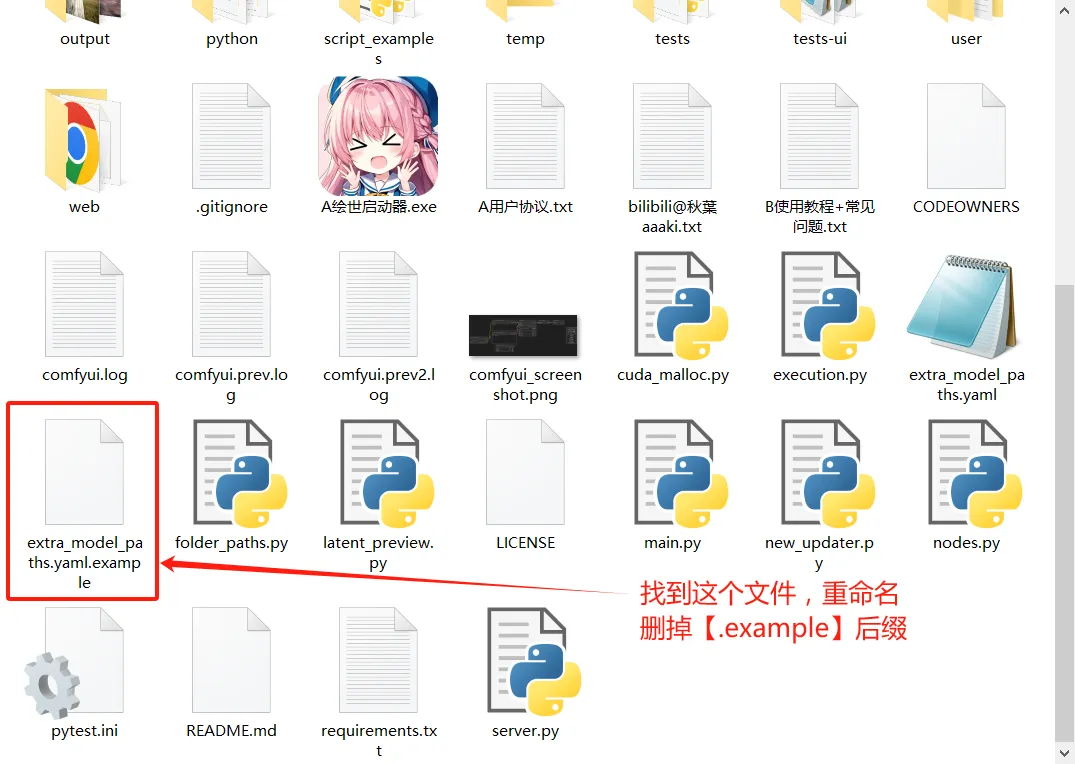
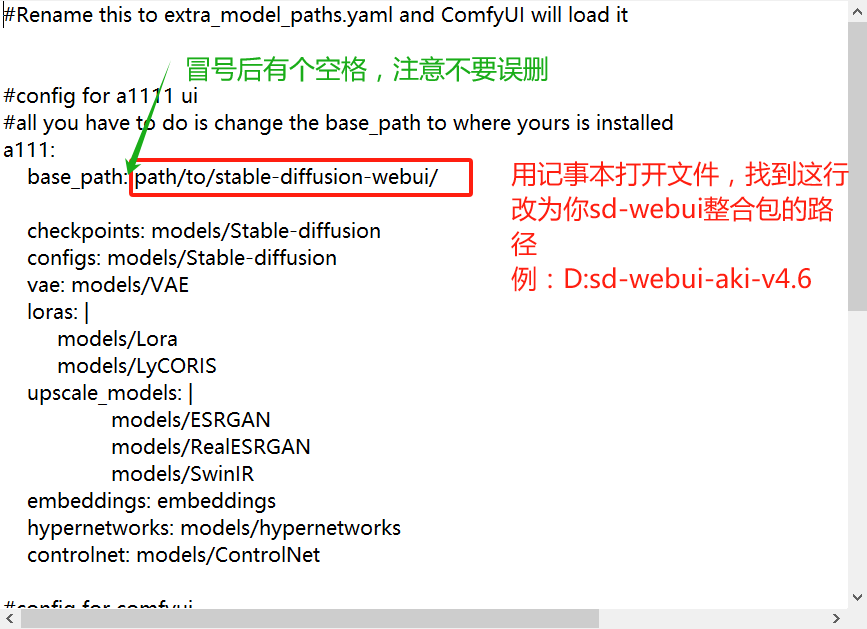
然后将base_path:后面改为你的webui目录:
点击“A绘世启动器.exe”。启动后软件会自动更新一些文件,一般不会很久。
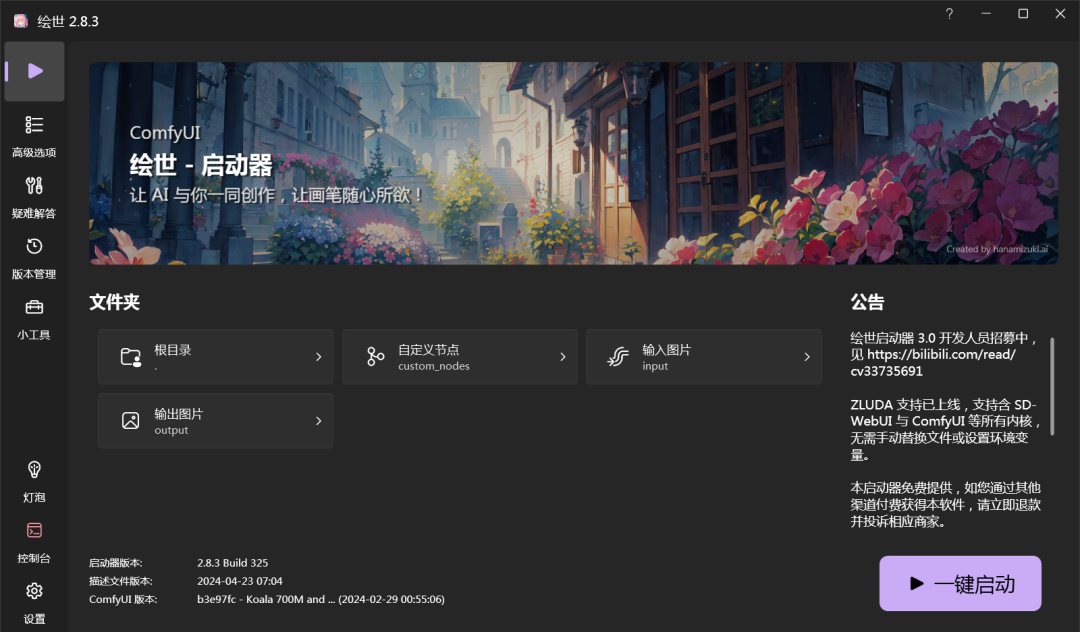
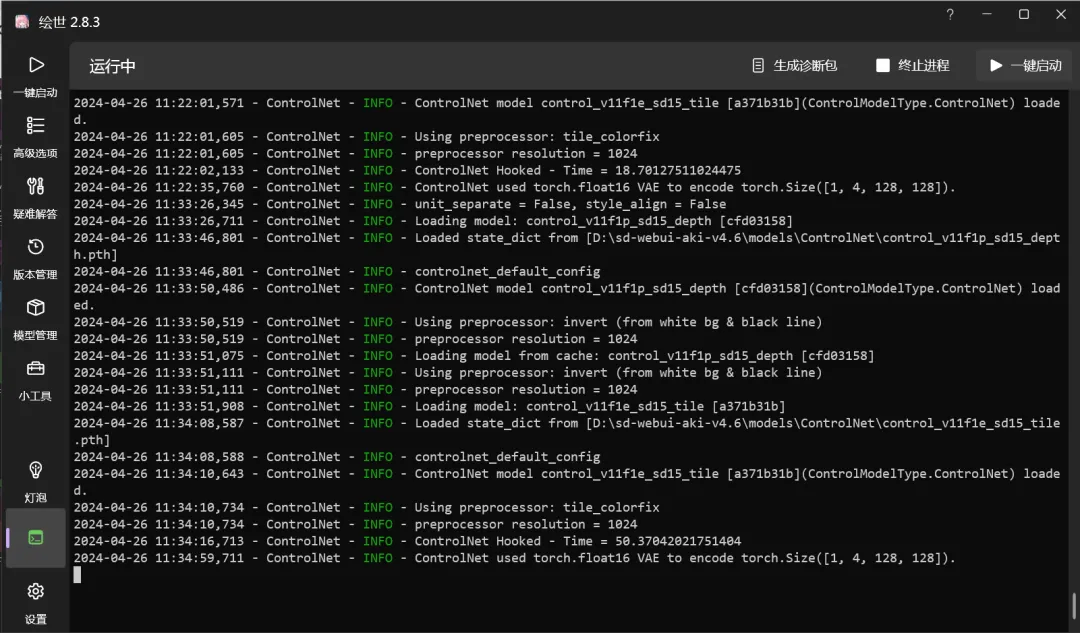
然后点击右下角的“一键启动”,第一次启动,可能比较慢,等一会即可,启动完成会自动打开浏览器。如果使用过程中遇到问题,可以查看左下角“控制台”页面里的日志。
设置中文 第一次打开如果是英文,可以设置一下语言。先点击小齿轮,进入设置页面:
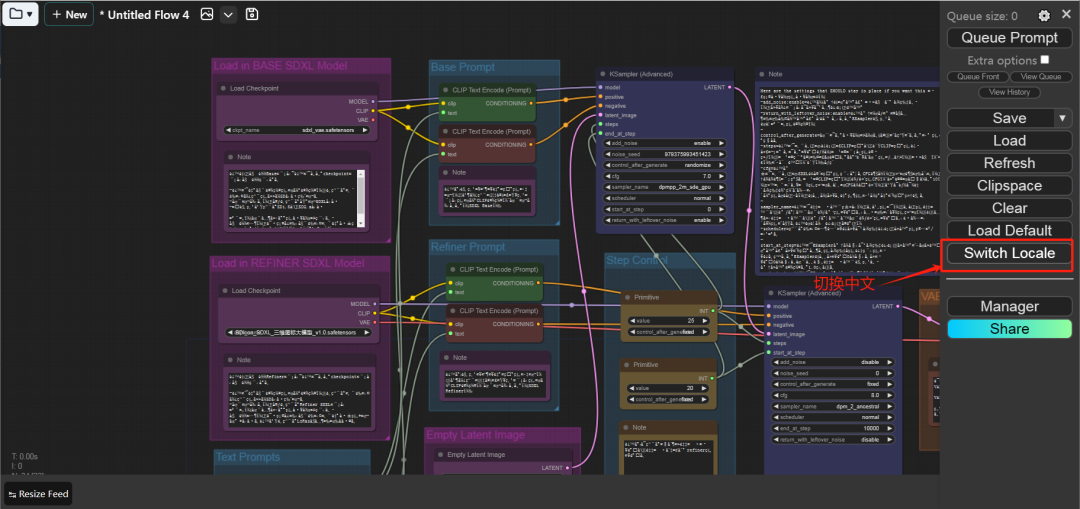
然后滑到最下面,找到:AGLTranslation-langualge选项,改为中文即可。
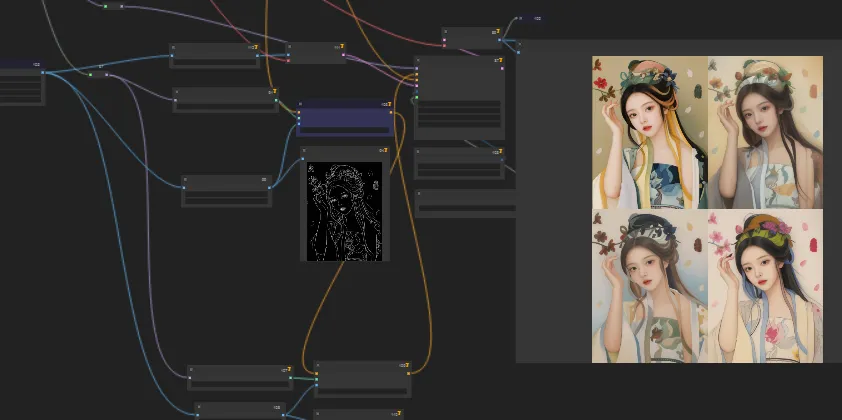
ComfyUI 工作流基础教程
No.1
文生图工作流
原理简介
1、首先将prompt文本转换为词特征向量
2、词特征向量和随机图向量一起encode降维输入潜空间,进行屡次降噪
输出图 = 输入图 -【(根据prompt预测的噪声+根据随机图预测的噪声-根据随机图预测的噪声)* 权重系数 +根据随机图预测的噪声】* 降噪次数
3、输出数据decode
在软件中,已经内置了许多工作流模版,下图对文生图作为基础工作流的各模块进行一个简单介绍。
下图中工作流对应文生图原理,根据Base Model生成词特征向量和随机图进行解码、屡次降噪、并编码生成图片。

ComfyUI 文生图基本工作流
提示词撰写
写提示词需要注意,长度约60字,SD的提示词不像自然语言生图的工具直接组织为句子输入,输入形式为关键词排列,越关键的越靠前,或使用权重设置如(keyword:1.4)提高权重;(keyword:0.7)降低权重
Prompt内容一般包含
-
主体
-
环境(地点,灯光,天气)
-
作画形式(油画、水粉、素描、相机……)
-
风格(年代、人物、艺术类型、国家……)
其他注意事项
-
构图建议使用图生图
-
在prompt中使用别人训练好的embedding模型可以生成特定的视觉特征(某特定人物、某物种……)
embedding:filename
尺寸设置
宽和高必须是8的倍数,Batch_size决定了一次生成多少张图像(可能影响速度,建议一次一张)

尺寸设置参数
采样器参数设置
(参数设置可以参考模型作者提供的最佳方案)
**Seed:**随机种子数,这个数字控制每次生成的图片相似程度,图片需要保持一致的时候,该数字不变
Control-after-generated:
生成完之后种子数的变化情况设置
**Step:**降噪步数
CFG:Prompt权重系数(一般6-8)
**Sampler-name:**采样器名称
**Scheduler:**调度器名称(降噪)
**Denoise:**初始噪声(文生图一般为1)
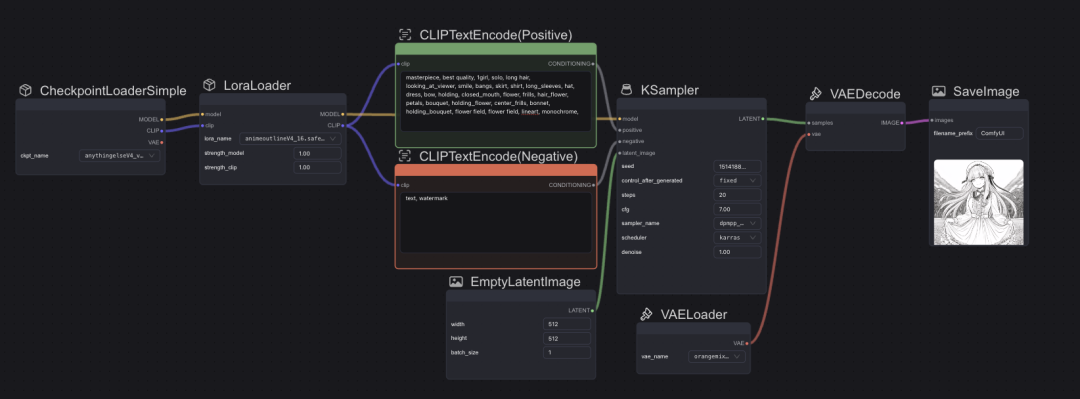
Lora配置
添加lora模块,更改clip、model连线,更换作者推荐的Vae模块等其他参数
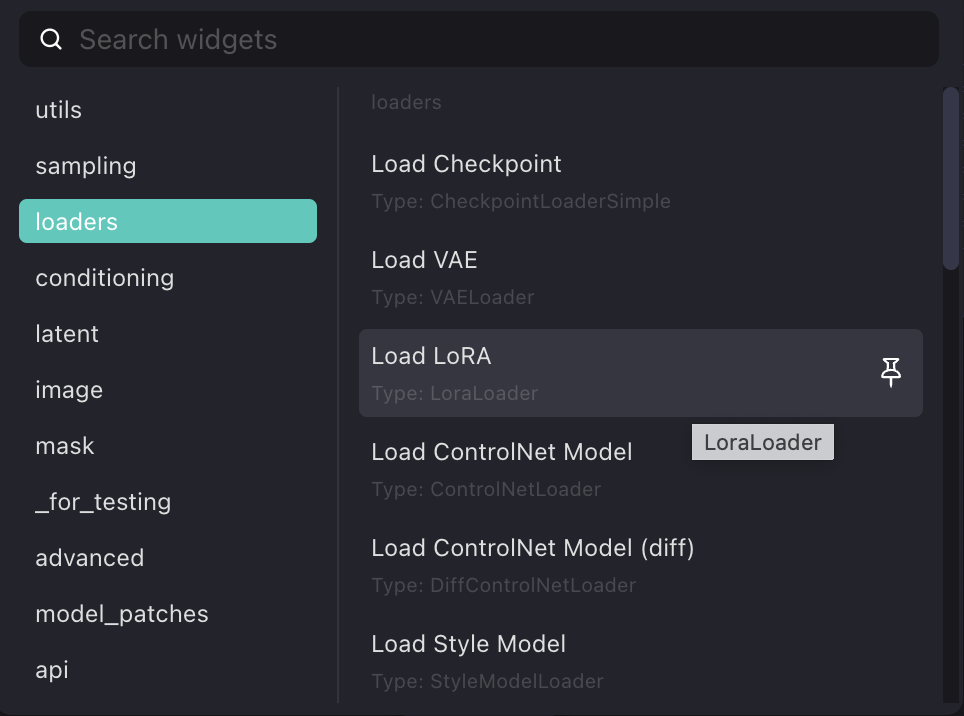
添加模块
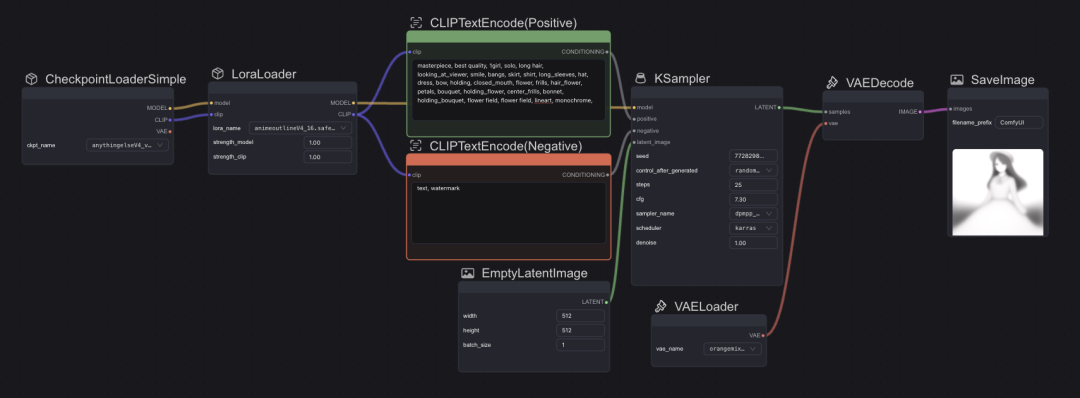
启动
此时设置完所有的模型和参数,按照教程的参数设置运行后依然会发现出图很糊,据说M系列Mac容易遇到该问题,根据教程,在终端pip安装 torchvision==0.16.2,成功解决该问题。
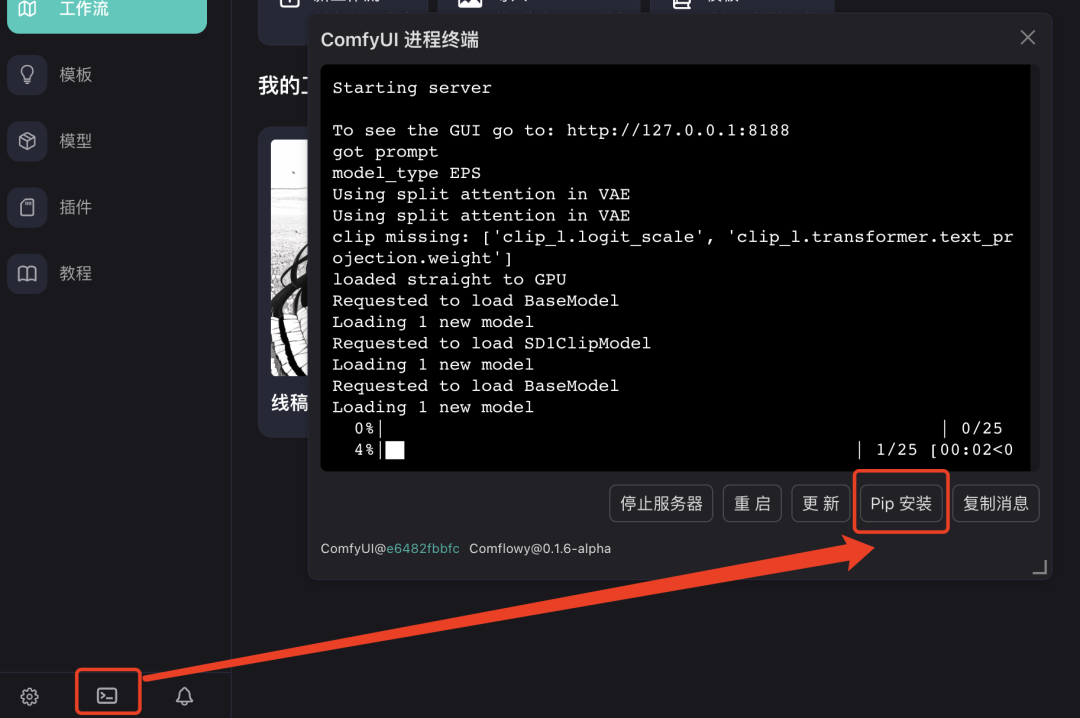
打开终端进行pip安装,输入 torchvision==0.16.2
解决图片输出模糊的问题
No.2
图生图工作流
方法一:重绘 - 基于输入图进行重新绘制
输入图代替随机图,和文字一起作为潜空间的输入。
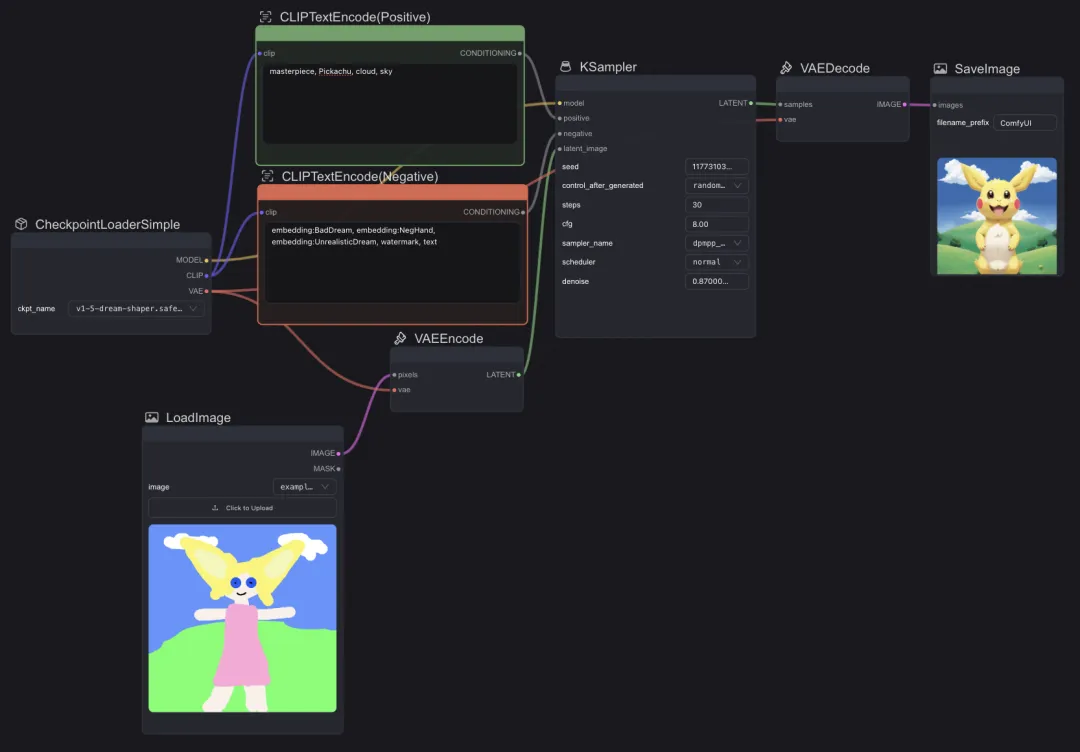
方法二:参考 - 基于输入图参考进行内容补充(unCLIP)、风格迁移(Style)拓展
先对图文进行解码,然后和随机图一起输入潜空间
unCLIP model workflow
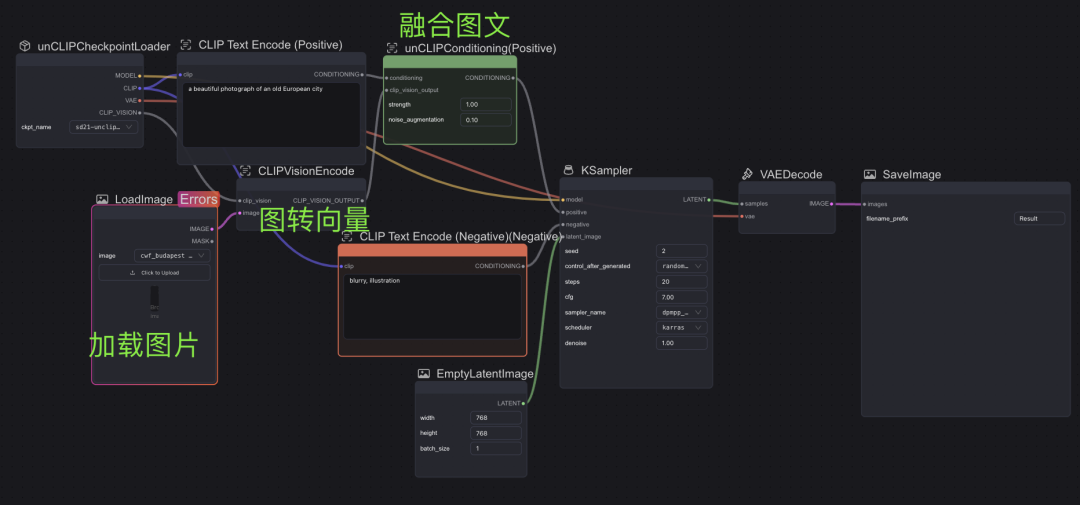
对于unCLIP重绘方式,可以直接使用模版搭好的工作流,其中增加了上图所示三个模块,并将初始CheckpointLoader、对应的unclip模型进行替换(模型:sd2.1-unclip, 对应随机图尺寸 768 * 768)
当使用两张图进行元素融合,可以看到结果大致实现将鸭子和水波元素进行了混合,但与预期效果差距较大,但融合的元素难以控制,若要提高符合预期的质量仍然需要进行更多的参数调整。
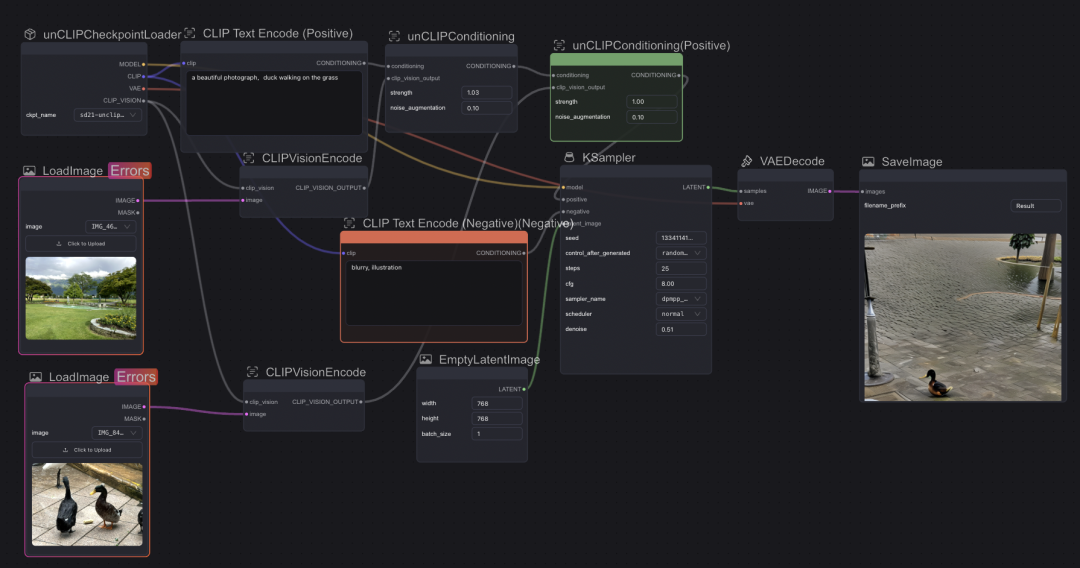
初始输入图片高度调整为768 跑unCLIP工作流
Style model workflow
风格迁移工作流中则需要将上传的图片编码为向量、理解风格、理解提示词,通过Style节点处理后导入采样器,一般为名画、人物雕塑类。
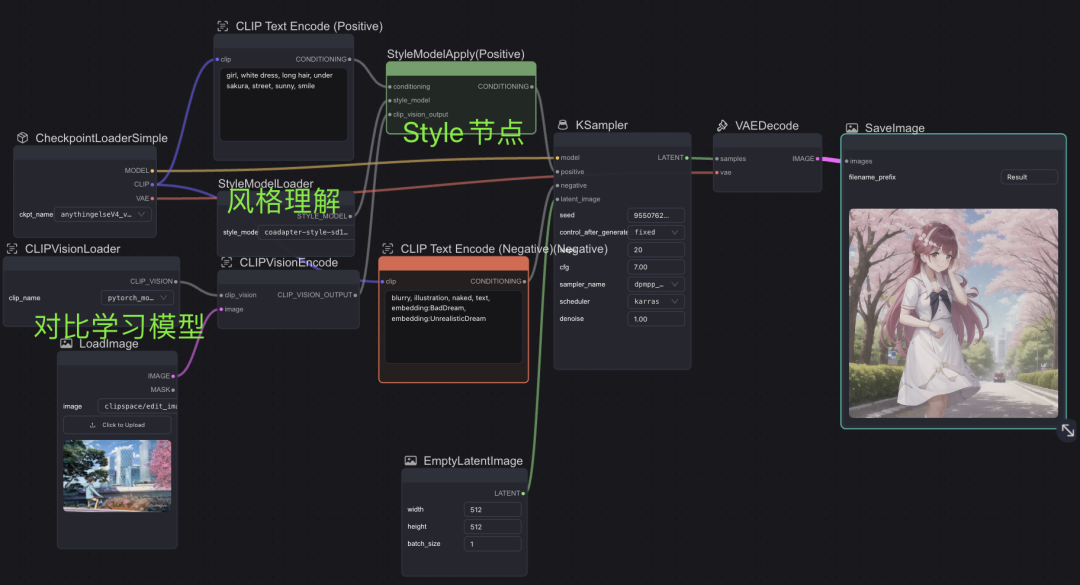
跑Style Model Workflow
此处使用了新海城画风的图片输入,整体而言,风格更加依赖模型,同样参数下,模型AnythingElse为二次元专用生成了左边的效果,DreamShaper为写实风生成了右边的效果,输出图风格更多与模型风格、prompt内容更相关,与上传的风格迁移的参考图片关系不大。

AnythingElse(左),DreamShaper(右)
ComfyUI 工作流分享
6 月工作流更新
AI模特、AI换脸、AI抠图、AI制作PPT、AI音频、AI视频、AI物体消除
资料软件免费放送
次日同一发放请耐心等待
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
感兴趣的小伙伴,赠送全套AIGC学习资料和安装工具,包含AI绘画、AI人工智能等前沿科技教程,模型插件,具体看下方。
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

**一、AIGC所有方向的学习路线**
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!

三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】



















 3082
3082

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










