




本文提出了一种新型高效的模型异质性个性化联邦学习框架FedLoRA,该框架基于LoRA(Low-Rank Adaptation)调整技术。FedLoRA通过在每个客户端的本地异构模型中插入一个小型低秩同质适配器(adapter),并利用迭代训练方法实现全局与局部知识的交换。这些小型适配器在联邦学习服务器上被聚合生成全局适配器,从而支持客户端之间的知识转移。理论分析证明了FedLoRA的收敛性。通过在两个基准数据集上的广泛实验表明,FedLoRA在测试准确率上优于六种最先进的基线方法,比最佳方法高出1.35%,并且在计算开销上减少了11.81倍,在通信成本上节省了7.41倍。
1 引言
随着全球数据隐私法律(如GDPR)的实施,传统依赖于集中数据进行模型训练的机器学习范式面临着越来越严峻的隐私保护挑战。联邦学习(FL)作为一种协作式学习范式应运而生。在典型的联邦学习系统中,中央服务器向客户端广播全局模型,客户端在本地数据上进行训练后,将更新后的模型上传回服务器。服务器对收到的本地模型进行聚合以更新全局模型,这一过程不断重复,直到全局模型收敛。在整个过程中,仅模型参数在服务器与客户端之间传输,而本地数据不会暴露。
然而,上述设计要求所有客户端必须训练具有相同结构的模型(即同质模型),这使得传统联邦学习范式在面对不同类型的数据异质性时显得力不从心:
-
数据异质性(统计异质性):联邦学习客户端的本地数据通常遵循非独立同分布(non-IID)。仅在本地数据上训练的模型可能比在非IID数据上训练的全局联邦学习模型表现更好。
-
资源异质性:参与联邦学习的客户端可能是具有不同硬件资源(如计算能力和带宽)的移动边缘设备。传统联邦学习要求所有资源异质的客户端训练具有相同结构的模型,这会导致模型性能瓶颈,因为资源受限的客户端只能支持较小的模型。
-
模型异质性:当联邦学习的参与者是企业时,它们通常会维护包含异构模型的私有模型库。在联邦学习训练过程中对这些模型进行微调,不仅可以节省训练时间,还可以保护知识产权。
这些挑战激发了模型异质性个性化联邦学习(MHPFL)领域的研究。现有的MHPFL方法可以分为以下三类:
-
基于知识蒸馏的MHPFL方法:依赖于与本地数据具有相同分布的公共数据集,但合适的公共数据集并不总是可用的。其他不依赖公共数据集的知识蒸馏方法由于需要在本地进行蒸馏,往往会为联邦学习客户端带来高昂的计算和/或通信成本。
-
基于模型混合的MHPFL方法:将每个本地模型拆分为用于本地训练的异构部分和用于模型聚合的同构部分。服务器仅对模型的部分参数进行聚合,导致最终的异构本地模型性能欠佳。
-
基于互学习的MHPFL方法:为每个客户端分配一个大型异构模型和一个小型同构模型。这两个模型在本地通过互学习进行训练,只有小型同构模型被上传到服务器进行聚合。在本地训练两个模型会带来额外的计算成本,此外,模型结构的选择也会影响最终性能。
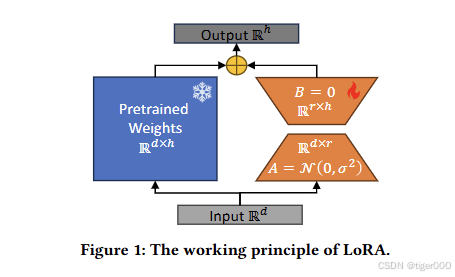
LoRA(Low-Rank Adaptation)作为一种新兴的预训练大型语言模型(LLMs)微调方法,通过在预训练模型旁添加一个低秩适配器分支来适应下游任务。在训练过程中,冻结预训练的大型模型,仅训练低秩适配器。由于仅训练小型适配器,LoRA实现了高效的计算和存储。
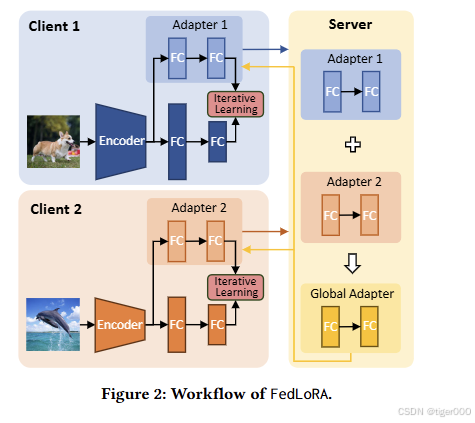
受LoRA启发,我们提出了一个基于LoRA调整的高效模型异质性个性化联邦学习框架FedLoRA,用于监督学习任务。FedLoRA属于互学习类别,每个客户端持有异构数据和模型。FedLoRA通过以下步骤实现:
-
在每轮通信中,客户端首先将本地适配器替换为从联邦学习服务器收到的全局同质适配器。
-
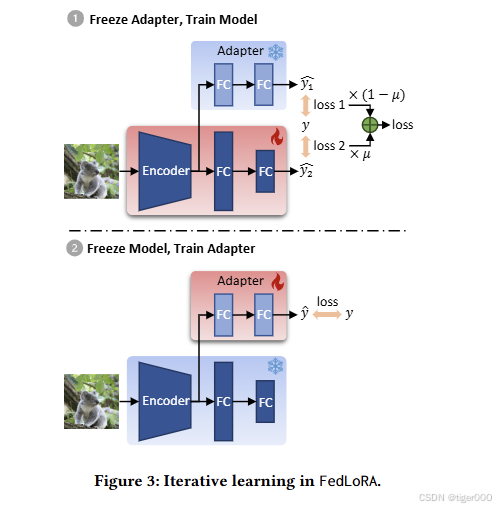
然后,客户端通过我们提出的迭代学习方法交替训练本地异构模型和同质适配器,以实现全局与局部知识的转移。
-
最后,客户端将更新后的本地同质适配器上传到服务器进行聚合,类似于FedAvg算法,以更新全局适配器。
简而言之,适配器被视为“知识载体”,用于聚合以支持客户端之间的知识转移。每个客户端仅额外训练一个小型适配器,并且仅与服务器通信小型同质适配器。这种设计确保了FedLoRA能够高效地实现模型异质性个性化联邦学习。由于LoRA适配器的插入改变了本地模型训练过程,我们基于本地迭代训练推导了FedLoRA的非凸收敛率,并证明了其随时间收敛。通过在两个基准数据集上的广泛实验表明,与六种最先进的方法相比,FedLoRA在模型同质和模型异质场景中均具有显著优势,测试准确率比最佳方法高出1.35%,计算开销减少了11.81倍,通信成本节省了7.41倍。
2 相关工作
现有的模型异质性个性化联邦学习(MHPFL)方法可以分为两个主要分支:部分模型异质性和完全模型异质性。
-
部分模型异质性:客户端持有全局模型的不同子网络,这些异构子网络可以在服务器上进行聚合,例如FedRolex、HeteroFL、FjORD、HFL、Fed2和FedResCuE等。
-
完全模型异质性:客户端持有的模型具有完全不同的结构,无法直接在服务器上进行聚合。这一分支可以进一步细分为以下几类:
-
基于知识蒸馏的MHPFL方法:依赖公共数据集的知识蒸馏方法(如Cronus、FedGEMS、Fed-ET、FSFL、FCCL、DS-FL、FedMD、FedKT、FedDF、FedHeNN、FedAUX、CFD、FedKEMF、KT-pFL)通过在公共数据集上聚合不同客户端异构模型的输出logits来构建全局logits。然而,公共数据集并不总是可用的,并且只有当公共数据集与私有数据具有相同的分布时,算法才能表现良好。此外,传输每个公共数据样本的logits会为大规模公共数据集带来高昂的通信成本。其他不依赖公共数据集的知识蒸馏方法(如FedZKT和FedGen)引入了零样本知识蒸馏,通过训练生成器来生成公共数据集,但这种方法耗时较长。HFD、FedGKT、FD、FedProto等方法允许每个客户端将其看到的类别样本的局部(平均)logits或表示上传到服务器,服务器按类别聚合生成全局类别logits或表示,然后将这些全局表示发送回客户端,用于与局部logits计算蒸馏损失,从而导致计算开销增加。
-
基于模型混合的MHPFL方法:这些方法将每个客户端的本地模型拆分为两个部分:一个特征提取器和一个分类器,仅共享其中一部分。例如,FedMatch、FedRep、FedBABU和FedAlt/FedSim共享同构特征提取器以增强模型泛化能力,并个性化本地分类器。相反,FedClassAvg、LG-FedAvg和CHFL共享同构分类器以改进模型分类,并个性化本地特征提取器。由于仅共享整个模型的部分参数,最终的异构本地模型面临性能瓶颈。
-
基于互学习的MHPFL方法:FML和FedKD为每个客户端分配了一个小型同构模型和一个大型异构模型,并以互学习的方式进行训练。在本地训练后,小型同构模型被上传到服务器进行聚合。简而言之,小型同构模型作为信息媒介实现了大型异构模型之间的知识转移。然而,这些方法没有探索两个模型之间的结构和参数容量之间的关系,这可能会影响最终模型性能以及为每个客户端训练额外小型同构模型的计算成本。
-
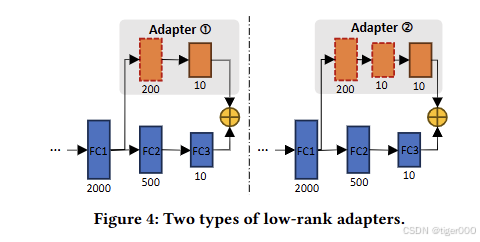
我们的见解是,FedLoRA通过小型低秩同质适配器实现了客户端本地大型异构模型之间的知识转移,这些适配器是大型本地异构模型全连接层的低秩版本。它不依赖任何公共数据集,并且由于仅在客户端上训练小型低秩额外适配器并在联邦学习服务器与客户端之间传输这些适配器,因此计算和通信成本较低。






























 1067
1067

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










