




💡 本文会带给你
- 如何构建自己的训练数据集
- 构建文本对话的步骤
实现情绪对话机器人需要结合情感计算(Affective Computing)、心理学模型和大语言模型技术,下面我们主要为文本对话方式浅谈下技术方案和实施步骤,首先探讨数据集构建步骤。
一. 核心架构设计
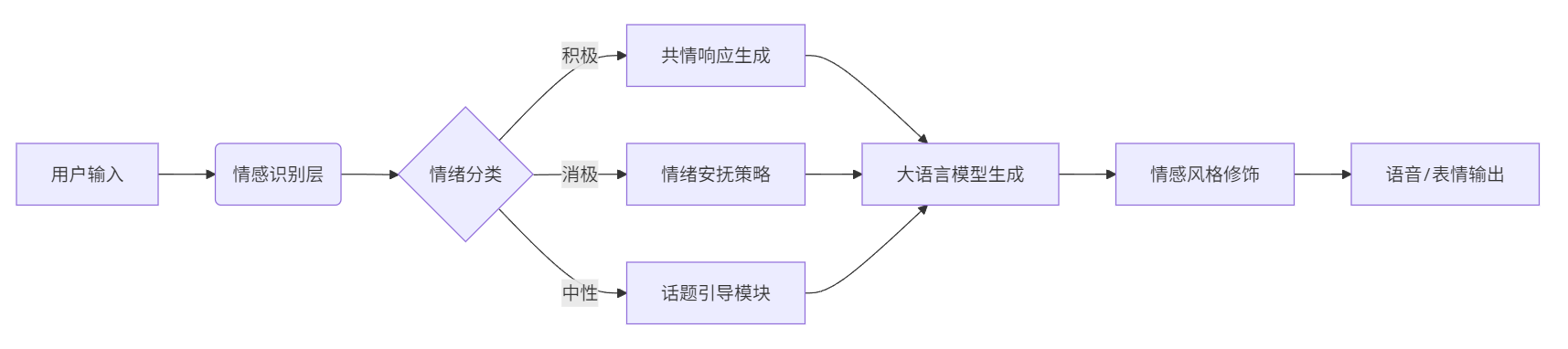
1. 核心架构

2. 程序目录
In [ ]:
emotion/ ├── app/ # 主应用目录 ├── core/ # 核心算法模块 ├── data/ # 数据管理 ├── configs/ # 配置文件 ├── tests/ # 单元测试 ├── docs/ # 文档 ├── scripts/ # 运维脚本 └── requirements.txt # Python依赖
二. 实现步骤

2.1. 数据准备阶段
数据集来源,可以由用户提供、网上爬虫、自己生成标注或借助AI模型批量生成等方式。
本项目数据基于现有开源数据集,借助AI模型快速实现情绪化数据集制作。AI尽可能选择效果好的在线API接口,数据质量好,不建议使用本地的模型性处理。本例使用智谱清言API接口实现数据制作。
开源数据集选大型清洁汉语会话语料库(LCCC),该语料库包含:LCCC-base 和 LCCC-large。
数据集成生成流程

1.1 下载LCCC
从魔塔社区下载 modelscope download --dataset OmniData/LCCC --local_dir LCCC
下载后我们从LCCC-base_valid.json文件,抽取1000条数据,作为基础提问数据,然乎对每条数据调用AI模型API接口生成“温”柔和“毒舌”两种风格的回答语。
In [ ]:
#抽取1000条数据 script.py
import json
import random
import argparse
from pathlib import Path
def conversations(input_file: str, output_file: str, sample_size: int = 1000):
"""
从JSON文件中随机抽取指定数量的不重复对话数据
:param input_file: 输入JSON文件路径
:param output_file: 输出JSON文件路径
:param sample_size: 要抽取的对话数量
"""
# 验证输入文件
input_path = Path(input_file)
if not input_path.exists():
raise FileNotFoundError(f"输入文件 {input_file} 不存在")
if input_path.suffix.lower() != '.json':
raise ValueError("输入文件必须是JSON格式")
# 读取原始数据
try:
with open(input_file, 'r', encoding='utf-8') as f:
data = json.load(f)
except json.JSONDecodeError:
raise ValueError("输入文件不是有效的JSON格式")
# 验证数据格式
if not isinstance(data, list):
raise ValueError("JSON数据应该是列表格式")
if not all(isinstance(item, list) for item in data):
raise ValueError("每个对话条目应该是列表格式")
# 检查数据量是否足够
unique_data = [tuple(conv) for conv in data] # 转换为元组以便检查唯一性
if len(set(unique_data)) < sample_size:
raise ValueError(f"唯一数据只有 {len(set(unique_data))} 条,不足以抽取 {sample_size} 条不重复数据")
# 随机抽样(确保不重复)
sampled_data = random.sample(list(set(unique_data)), sample_size)
# 转换回原始格式(列表的列表)
sampled_data = [list(conv) for conv in sampled_data]
# 保存抽样结果
try:
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(sampled_data, f, ensure_ascii=False, indent=2)
except IOError:
raise IOError(f"无法写入输出文件 {output_file}")
print(f"成功从 {len(data)} 条数据中抽取 {sample_size} 条不重复数据")
print(f"原始数据唯一条目数: {len(set(unique_data))}")
print(f"结果已保存到: {output_file}")
if __name__ ==



















构建微调数据集&spm=1001.2101.3001.5002&articleId=147196319&d=1&t=3&u=66def9c425fe412fb0c6af20983cc243)
 8383
8383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










