



一、Dia功能介绍
Dia是Nari Labs推出的开源文本转语音(TTS)模型,拥有16亿参数,根据文本脚本直接生成高度逼真的
对话语音,支持多说话者标记、情感语调控制以及非语言提示(如笑声、咳嗽声等),通过语音克隆功能生
成与特定音频相似的声音。
Dia的代码和权重已在Hugging Face和GitHub上开源,用户可以下载并本地部署,也可以通过Gradio界面在线体验。
二、Dia的主要功能
自然对话生成:能根据文本脚本生成高度逼真的对话语音,支持多说话者标记,适合多人对话场景
情感与语调控制:用户可以通过音频提示或固定种子调整生成语音的情感和语调,使语音更具表现力。
非语言提示:支持生成非语言音频提示,如笑声、咳嗽声、清嗓子等,让对话更加生动自然。
零样本语音克隆:Dia支持零样本语音克隆,用户可以上传一个简短的参考音频片段,模型将复制该片段的语音风
格。这使得用户无需对每个新说话者进行微调即可生成个性化语音。
实时语音合成:Dia优化了推理管道,能在消费级设备上实现实时语音生成。在企业级GPU上,Dia能以实时速度
生成音频。
三、主要功能
-
预训练模型:提供了预训练的模型权重,可直接从 Hugging Face 下载使用。
-
推理代码:包含完整的推理代码,方便用户进行语音生成。
-
多平台支持:支持在不同的设备上运行,包括 GPU 和 CPU。
-
可配置性:用户可以根据需要调整生成参数,如最大令牌数、分类器自由引导比例、采样温度等。
-
音频提示:支持使用音频提示进行语音克隆,使生成的语音更符合特定的风格。
四、操作步骤
1. 从官网进入平台
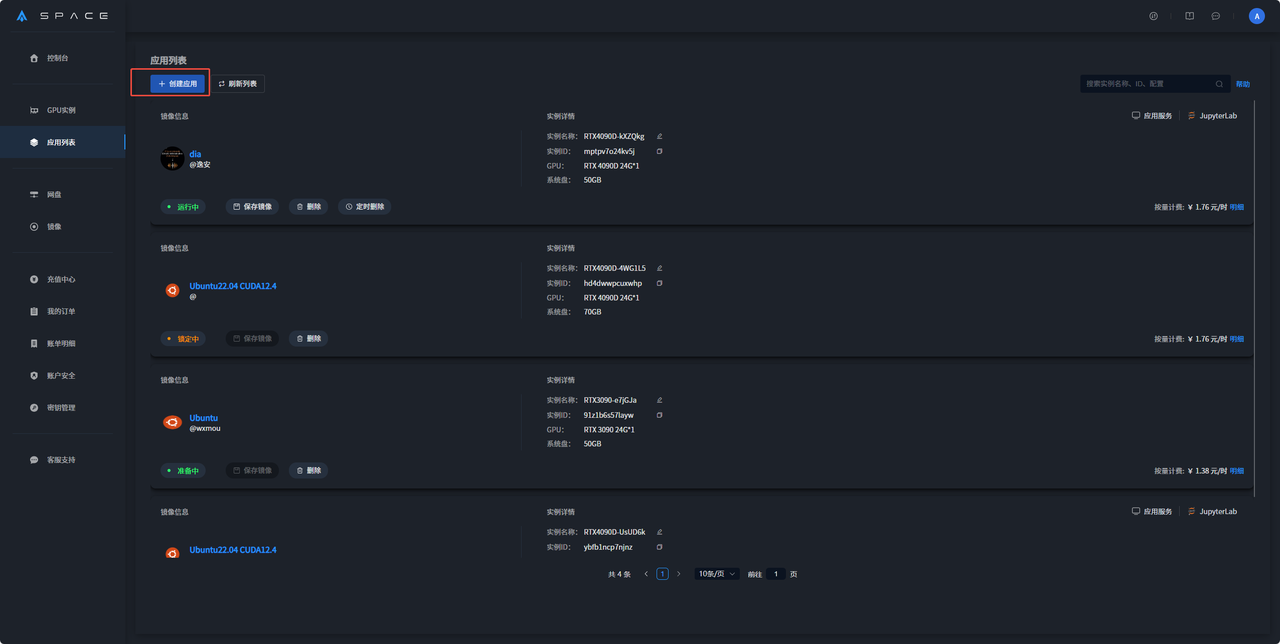
 2. 在应用列表界面中选择创建应用
2. 在应用列表界面中选择创建应用
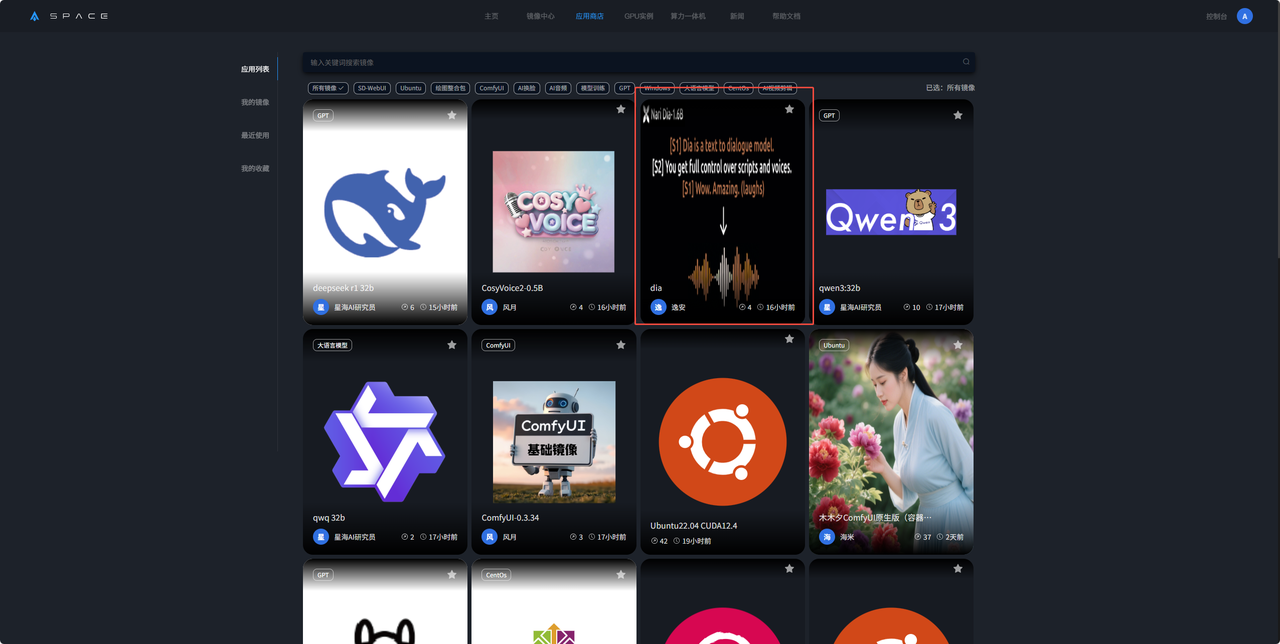
3. 在应用商店中选择dia并点击部署
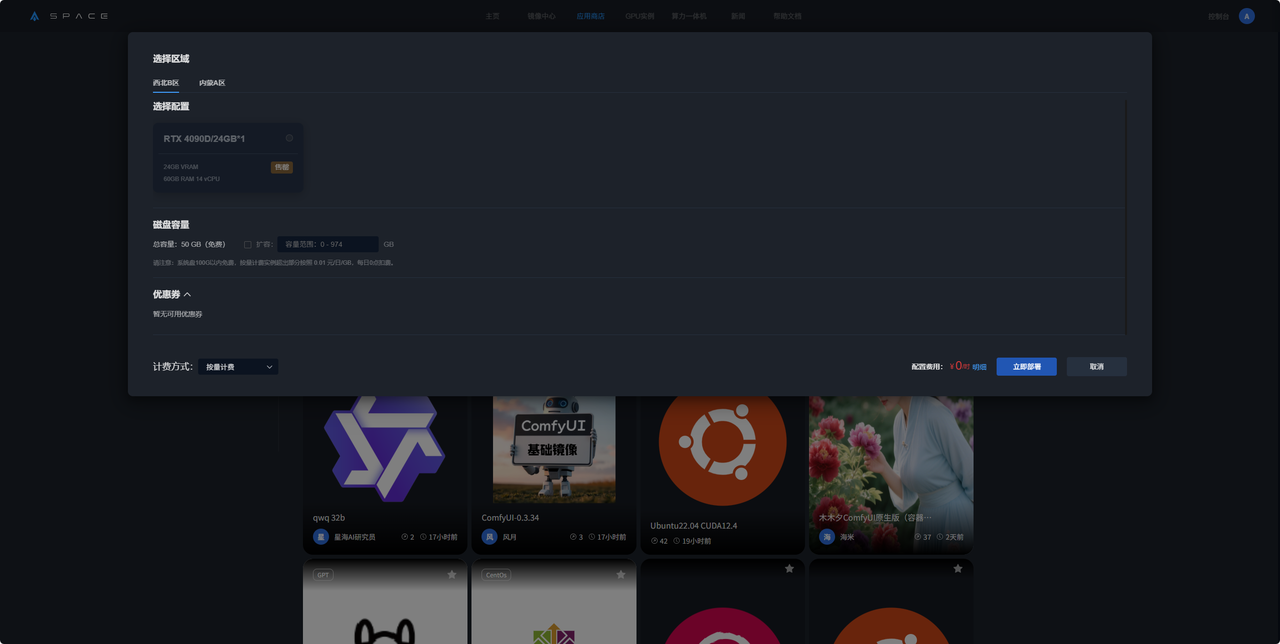
4. 选择区域,GPU、磁盘配置后点击立即部署。
5. 待开机后,启动应用服务 (刚开机后点击启动若是出现502问题,请关闭页面等2-3分钟后再重新启动服务)
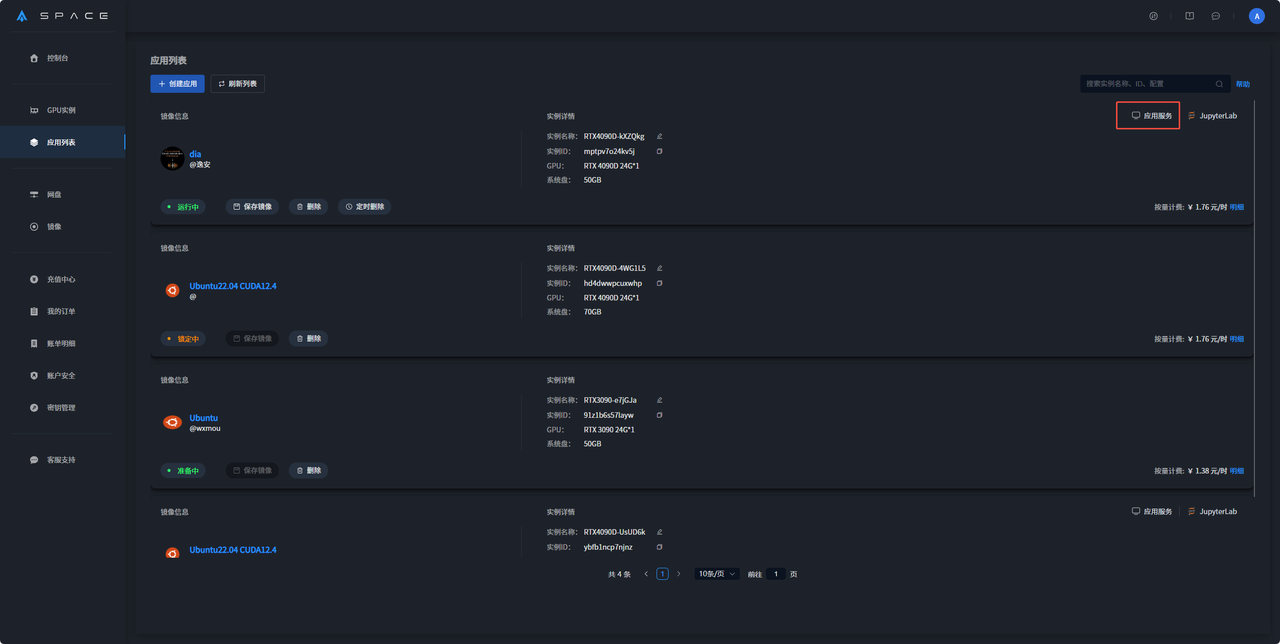
打开后界面如下
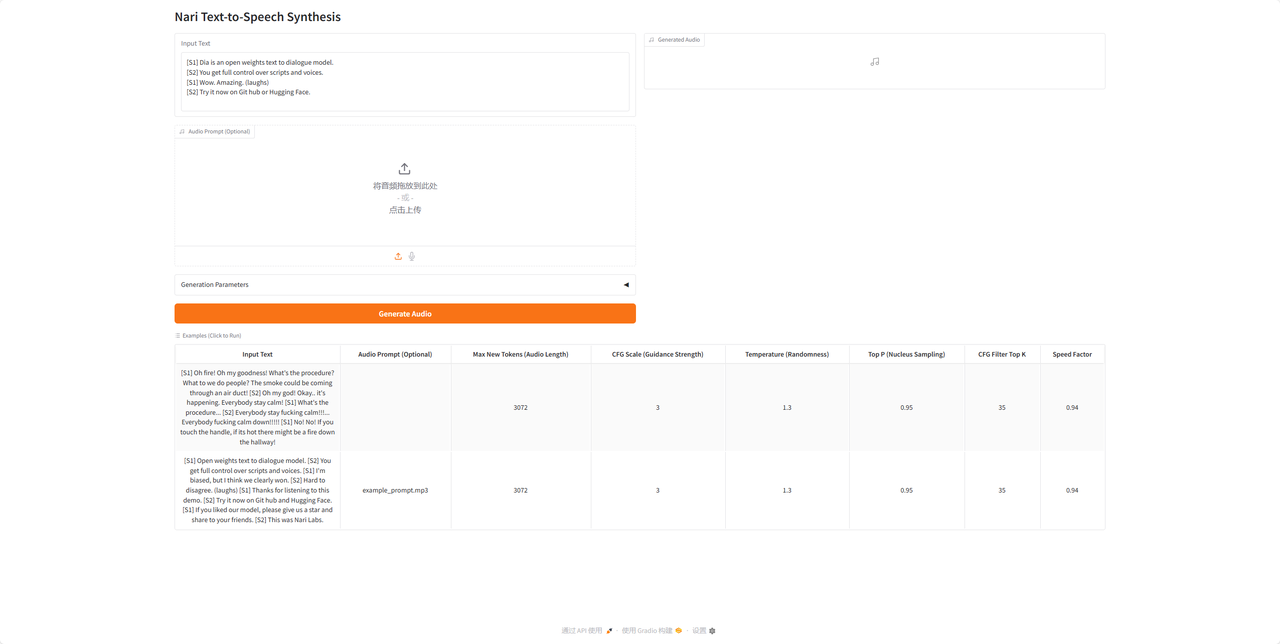
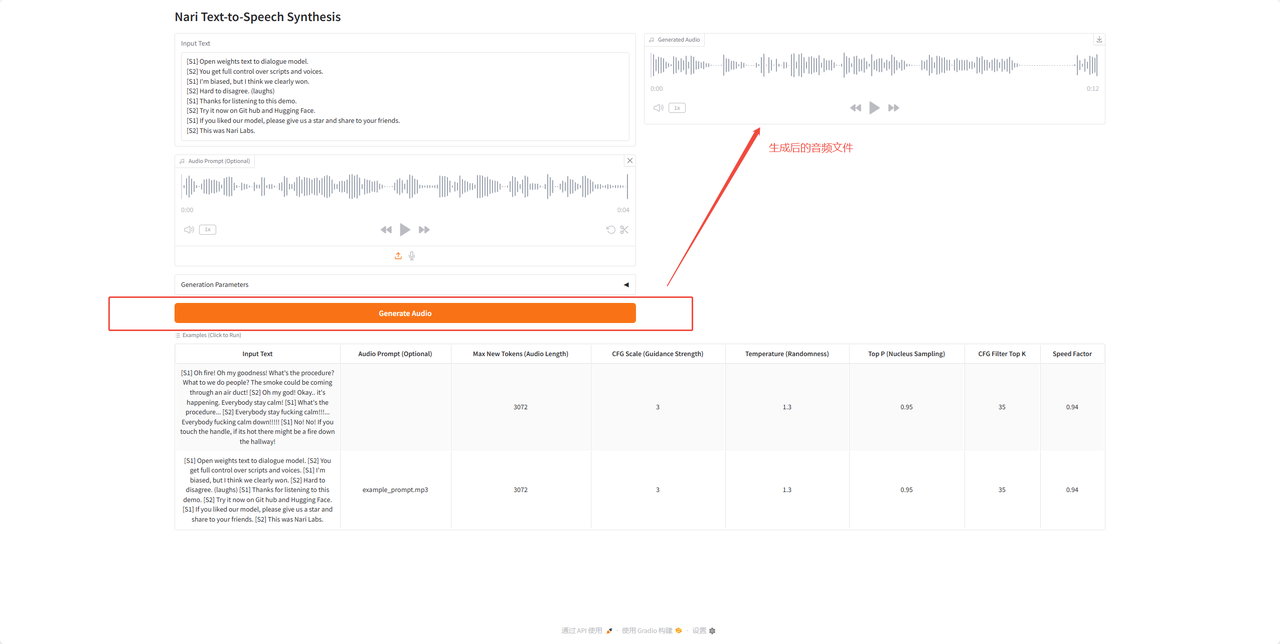
6. 在对话框中输入文字,其中S1、S2代表第一个说话和第二个人说话。
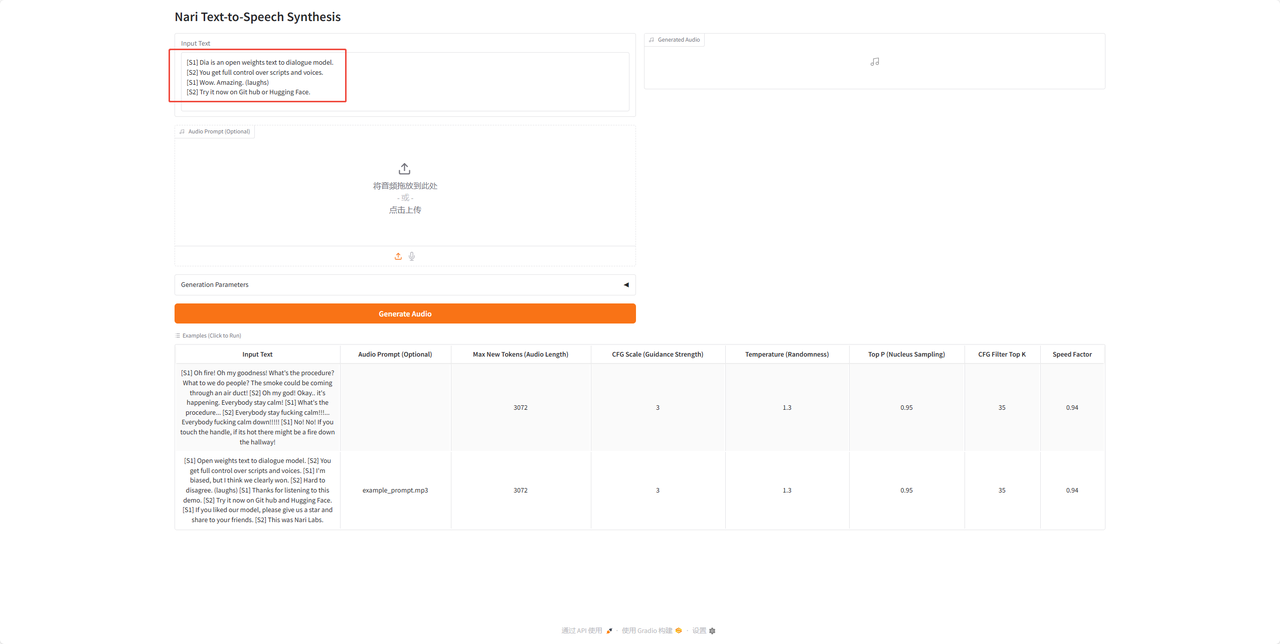
7.音频文件上传。
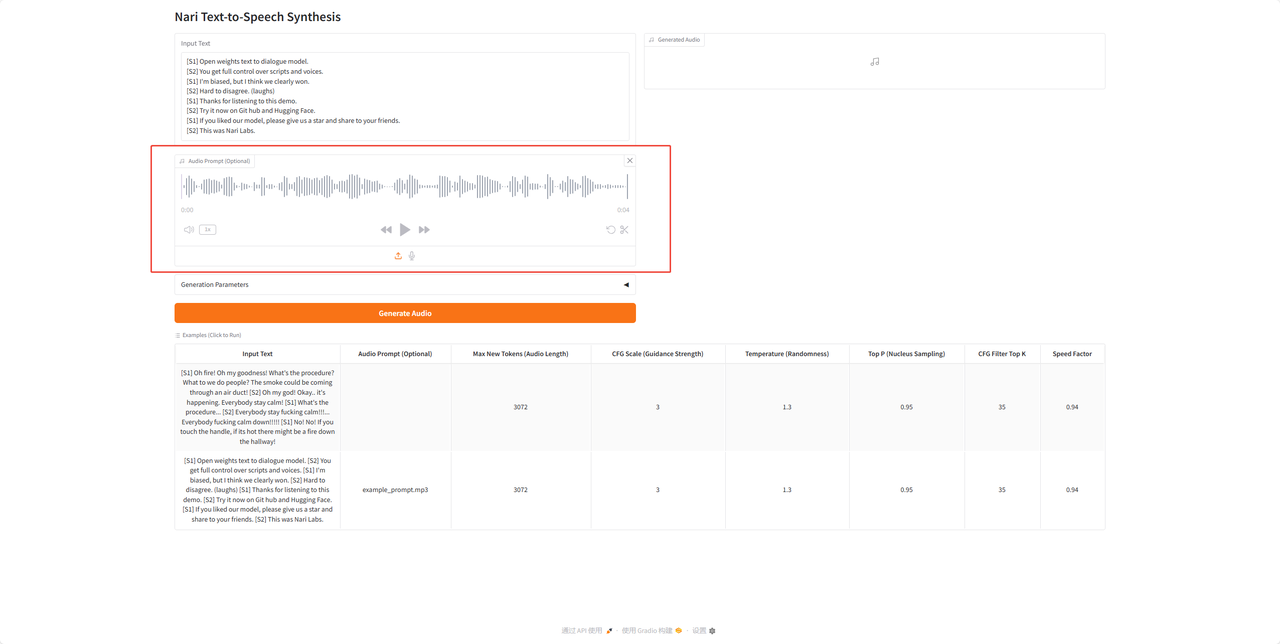
8.点击生成按钮生成新的音频文件。


















 1475
1475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










