






“ 近年来,大语言模型(LLM)在代码理解与生成任务中展现出强大能力,逐渐被引入到代码漏洞检测领域。然而,直接将完整函数输入 LLM 进行判断,往往面临两大现实问题:函数体过长,超过上下文窗口限制、结构与语义信息混杂,关键信息被“淹没”。
为解决上述问题,研究者提出VulTrLM,一种通过 AST 解构与语义注释增强,显式引导 LLM 关注漏洞关键语义的检测框架。”
📄 论文标题:VulTrLM: LLM-assisted Vulnerability Detection via AST Decomposition and Comment Enhancement
📅 发表时间:Empirical Software Engineering, 2025
🏫 作者单位:湖南科技大学、湖南大学等
💡开源代码:即将发布在Zenodo
01—方法介绍
图1所示是针对CVE-2020-36138的FFmpeg代码示例,揭示了FFmpeg项目中decode_frame()函数存在的空指针解引用漏洞。该案例研究揭示了预训练模型的两大关键缺陷:
(1)预训练模型可能无法推断出具有复杂逻辑的语句的语义。第 3–4 行定义了 has_tile_bits 和 has_strip_bits,二者本应互斥,同时为真会直接退出。但模型若只关注局部语法,可能无法理解这一语义约束。类似地,第8行看似常规安全检查,模型可能忽略在tiled为真时仍需校验strip字段,导致不安全的 strip 数据绕过检查,形成漏洞。
(2)预训练模型可能难以理解执行路径。大量使用 if 与直接 return(如第 10、14、18 行)会引入漏洞风险,因为部分 return 只有在多个条件同时满足时才会触发。若不能准确建模这些执行路径,预训练模型很难预测潜在漏洞。

图 1. 针对CVE-2020-36138的FFmpeg代码示例
VulTrLM 的核心思想并非“让 LLM 读更多代码”,而是:“把代码拆清楚,再讲明白。”整体流程由三个关键步骤组成:
① AST 解构
将函数拆分为多个语义清晰的 AST 子结构,降低单次输入复杂度。
② 注释增强
为 AST 节点生成自然语言注释,显式描述其语义与潜在风险。
③ LLM 漏洞判断
将“结构化代码 + 语义注释”输入 LLM,完成漏洞预测。
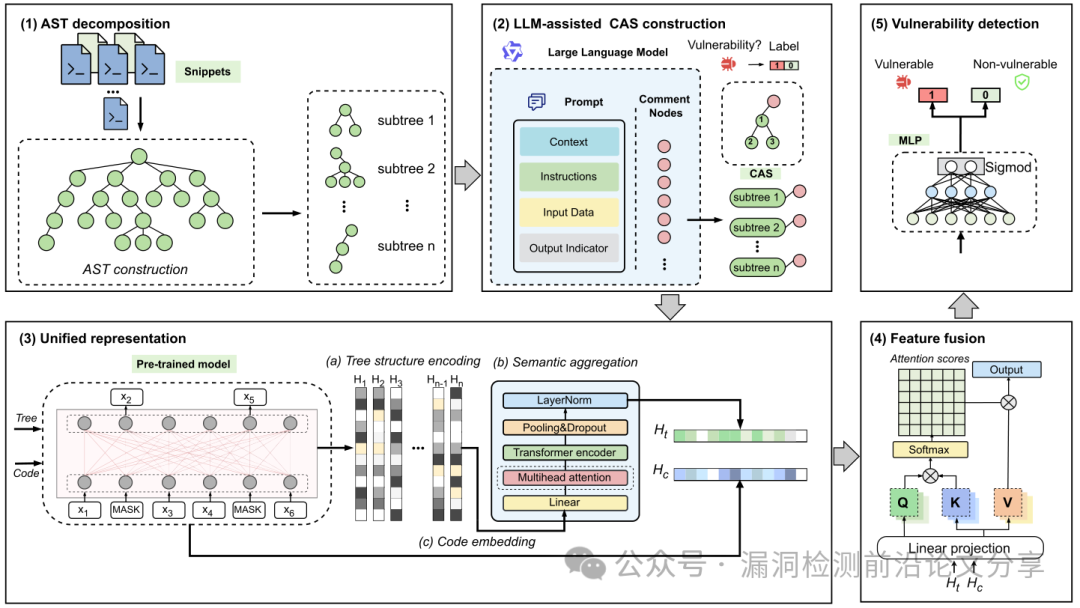
图 2. ZSVulD整体流程
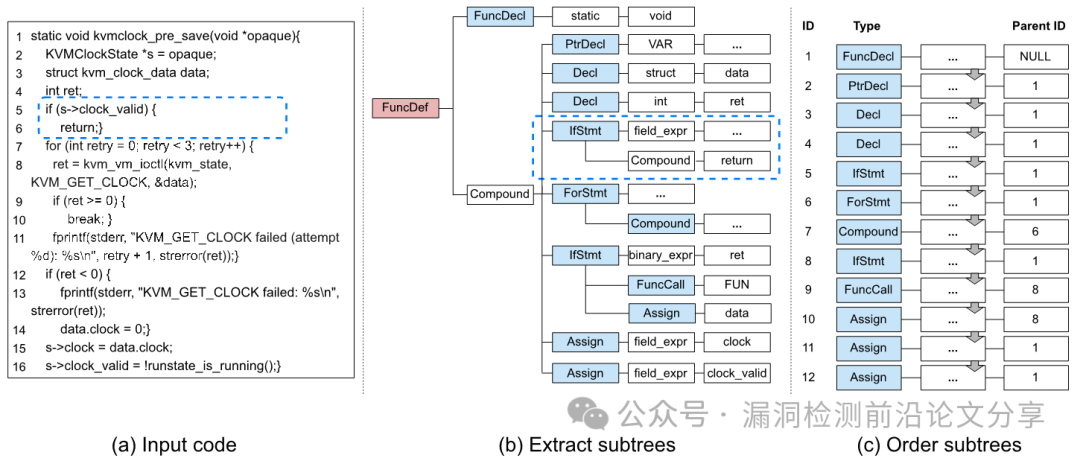
图 3. 展示了对一段代码片段应用AST(抽象语法树)分解的结果
小结:VulTrLM 将 LLM 从“被动阅读者”转变为“被引导的分析者”。
02—关键机制
- AST 级别的上下文拆解,缓解 LLM 上下文窗口受限问题。
- 注释驱动的语义显式化,降低 LLM 对隐式语义推理的负担。
- 无需模型微调,以 Prompt 方式即可适配不同 LLM。
- 兼顾可解释性,每一步判断都可追溯到具体 AST 结构。
|
模块 |
实现方式 |
主要作用 |
|---|---|---|
|
AST 解构模块 |
基于语法树拆分函数结构 |
降低上下文复杂度,突出关键逻辑 |
|
语义注释增强 |
为代码结构生成自然语言描述 |
显式提示潜在漏洞语义 |
|
LLM 推理模块 |
基于 Prompt 的漏洞判断 |
提升对复杂漏洞模式的理解能力 |
|
结果聚合 |
整合子结构预测结果 |
获得函数级漏洞判断 |
小结:结构化拆分 + 自然语言增强,是 VulTrLM 性能提升的关键。
03—实验结果
实验在主流漏洞数据集Devign、Reveal和SVulD(Distinguishing look-alike innocent and vulnerable code by subtle semanticrepresentation learning and explanation)上验证了提出方法的有效性,主要实验结果如下。
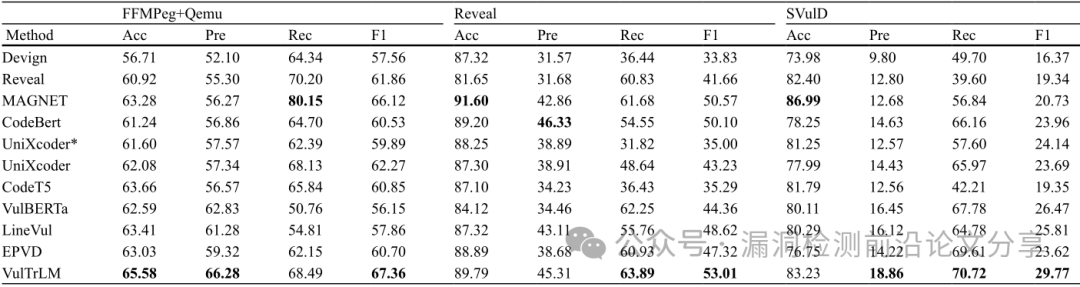
(1)实验评估了VulTrLM与现有非大型语言模型(LLM)漏洞检测基线评估结果的比较,结果如表1所示。
表1.与现有非LLM漏洞检测基线评估结果的比较
(2)实验评估了VulTrLM与现有基于大型语言模型(LLM)的漏洞检测基线评估结果的比较。结果见表2。
表2. 集成学习对未见数据集的影响

小结:VulTrLM在函数级漏洞检测方面表现出显著优势。在FFMPeg+Qemu、Reveal和SVulD测试集上,VulTrLM分别取得了67.36%、53.01%和29.77%的优异F1分数,分别超越最佳基线方法1.87%、4.82%和12.46%。
📌 总结
VulTrLM 为 LLM 在漏洞检测中的应用提供了一个重要启示:不是让大模型理解复杂程序,而是让程序变得更容易被理解。
通过 AST 解构与语义注释增强,该框架在不依赖模型微调的前提下,显著提升了 LLM 在真实漏洞检测任务中的可用性与稳定性。
📣 欢迎留言讨论
-
你认为未来漏洞检测的关键在于更强的 LLM,还是更好的程序结构化表示?
-
AST + 注释这种“显式语义提示”是否会成为 LLM 程序分析的标配?
📌 点赞 + 收藏 + 分享,你的支持,是我们持续解析高水平软件安全论文的最大动力!


















 283
283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










