




 本文主要介绍了线性回归和逻辑回归。线性回归可用于连续数据预测和离散数据二分类,但二分类时有缺点。逻辑回归基于此场景诞生,借助sigmoid函数将线性回归结果映射为概率值。还从代价函数角度推导逻辑回归,分析了判定边界、代价函数及梯度下降等内容。
本文主要介绍了线性回归和逻辑回归。线性回归可用于连续数据预测和离散数据二分类,但二分类时有缺点。逻辑回归基于此场景诞生,借助sigmoid函数将线性回归结果映射为概率值。还从代价函数角度推导逻辑回归,分析了判定边界、代价函数及梯度下降等内容。
一,线性和非线性什么关系?
线性就是一次函数。不管是几元函数!!!
参考博文:https://blog.csdn.net/u010916338/article/details/84967688
二,线性回归
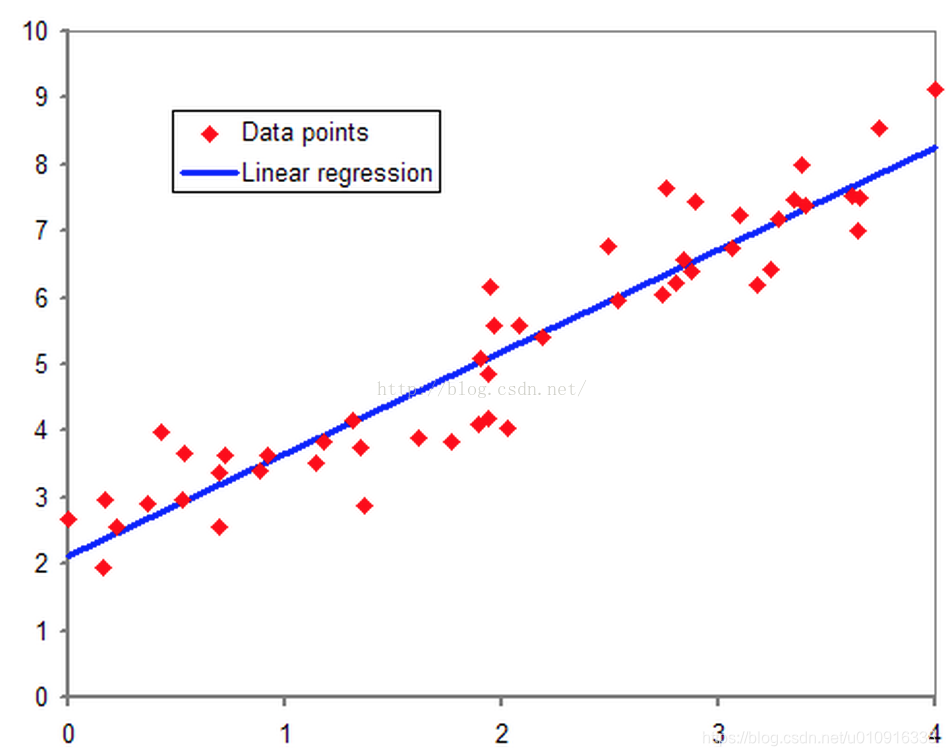
2.1 解释线性回归
如图所示,对于二维数据,线性回归就是能搞够找到一条直线拟合数据。对于三维就是能够找到一个平面拟合数据。对于更高纬就没有办法描述了,但是无论多少维度,拟合函数一定是一次的。可以用或
来表示。
2.2 线性回归有哪些功能?
(1)预测(针对连续数据)
(2)二分类(针对离散数据)
比如说医生需要判断病人是否生病;银行要判断一个人的信用程度是否达到可以给他发信用卡的程度;邮件收件箱要自动对邮件分类为正常邮件和垃圾邮件等等。
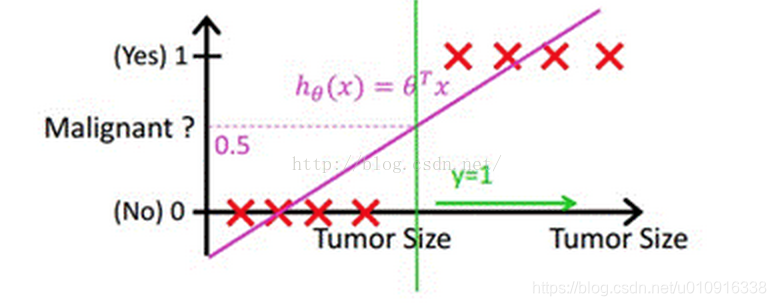
2.3 线性回归二分类时的缺点
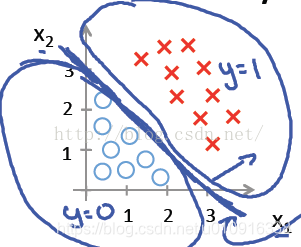
下图中X为数据点肿瘤的大小,Y为观测结果是否是恶性肿瘤。通过构建线性回归模型,如hθ(x)所示,构建线性回归模型后,我们设定一个阈值0.5,预测hθ(x)≥0.5的这些点为恶性肿瘤,而hθ(x)<0.5为良性肿瘤。
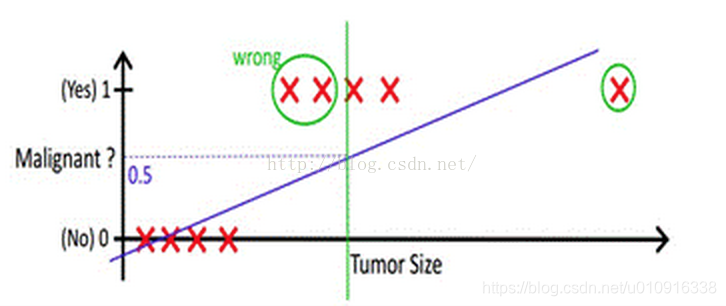
但很多实际的情况下,我们需要学习的分类数据并没有这么精准,比如说上述例子中突然有一个不按套路出牌的数据点出现,如下图所示。(注:不要拿y=0.5那条横线去分割,应该拿x=2那条竖线即图中绿线去分割,绿线左边是一类,绿线右边是一类。原因是:y=0.5是x=5映射出来的,所以最主要内因还是看x。)
三,逻辑回归
基于2.3这样的场景,逻辑回归就诞生了,逻辑回归仍然是一个二分类问题。它的核心思想是,如果线性回归的结果输出是一个连续值,而值的范围是无法限定的,如下面三幅图所示。那我们有没有办法把这个结果值映射为可以帮助我们判断的结果呢?答案是肯定的,sigmoid函数就是这样一个函数。
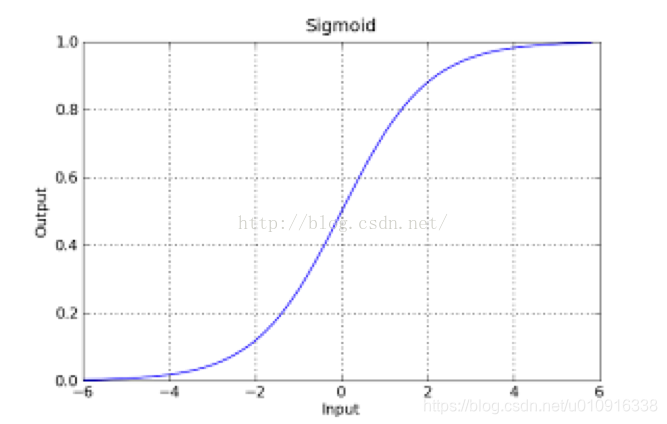
3.1 sigmoid函数
sigmoid函数也称为Logistic函数(logistic function)。sigmoid的输出结果是 (0,1) 的一个概率值。公式为: 。函数图形如下:
3.2 sigmoid函数求导时有一个特性 (这个特性后面会用到!!!)
3.3 逻辑回归表达式
逻辑回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射。即先把特征线性求和,然后使用函数g(z)来预测。
按照惯例让,那么:
 3.4 逻辑回归软分类
3.4 逻辑回归软分类
对于输入x(注:这里的x是一个向量()),分类结果为类别1和类别0的概率分别为:
对上面的表达式合并一下就是:
(注:自行带入验证一下,刚好能包含上面两种情况!!!)
3.5 公式约定
整篇博客的公式都按照此约定解读!!!
x表示向量(),表示一个输入。
表示第
个向量,表示第
个输入。
表示向量x(
)的第
个分量。
表示第
个向量
的第
个分量。
y不是向量,表示一个值,即标签值。
表示与第
个x向量对应的值。
表示向量(
),表示参数。
表示向量(
)的第
个分量
3.6 最大似然估计
似然函数:
(注:表示第
个向量,表示第
个输入。
表示与第
个x向量对应的值。)
对数似然函数:
以只有一个训练样本的情况为例,对对数似然函数求倒数:
(注:参考3.2)
(注:
表示向量x(
)的第
个分量。)
对于多个样本:
(注:
表示第
个向量
的第
个分量。)
3.7 梯度上升
注意:这里是求,在样本确定参数θ不断调整的情况下,事件发生的最大概率,即求似然函数的最大值,所以要用梯度上升。另外梯度方向本身就是上升最快的方向,这里描述为梯度上升为的是便于理解。
(注:是学习率,即步长。
只是代表了
θ向量的一个分量变化的情况,实际上n个θ分量都是这样变化的)
梯度以及梯度下降,参考博文:
https://blog.csdn.net/u010916338/article/details/81288309
https://blog.csdn.net/u010916338/article/details/83310442
四,从代价函数角度推导逻辑回归
4.1 判定边界
判定边界:可以理解为是用来对不同类别的数据分割的边界,边界的两旁都是是不同类别的数据。
分析sigmoid函数,发现:当g(z)≥0.5时, z≥0。
(1)对于, 则
,此时意味着预测y=1;
(2)反之,当预测y = 0时,;
所以我们认为是一个决策边界,当
大于0或小于0时,逻辑回归模型分别预测不同的分类结果。
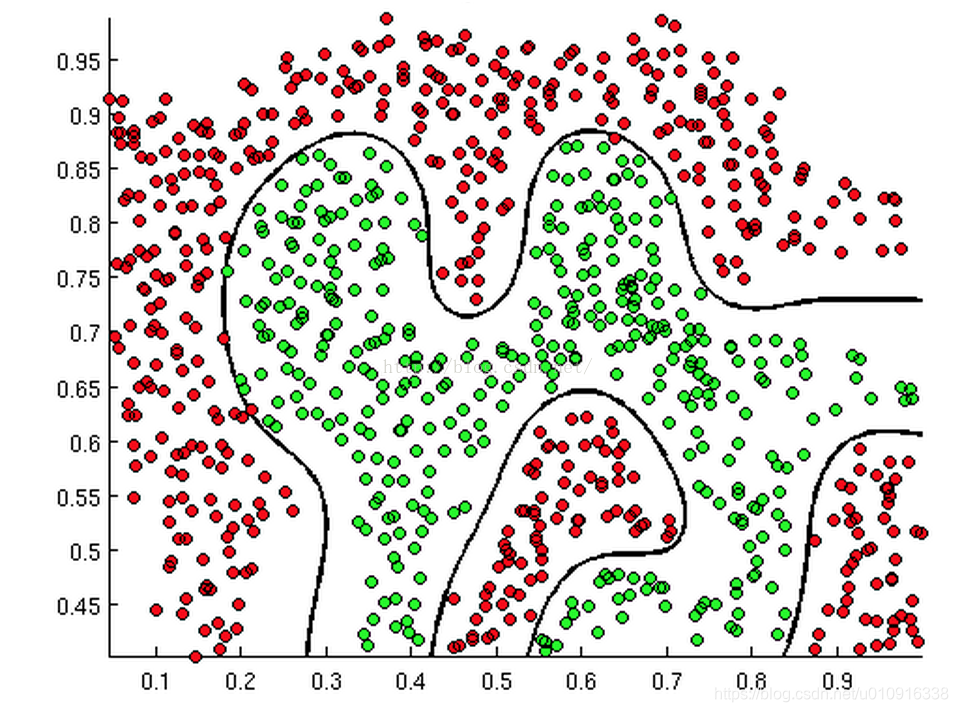
4.1.1 线性判定边界
例如:,其中
分别取-3, 1, 1。当
时, y = 1。
是一个决策边界,如下图所示:
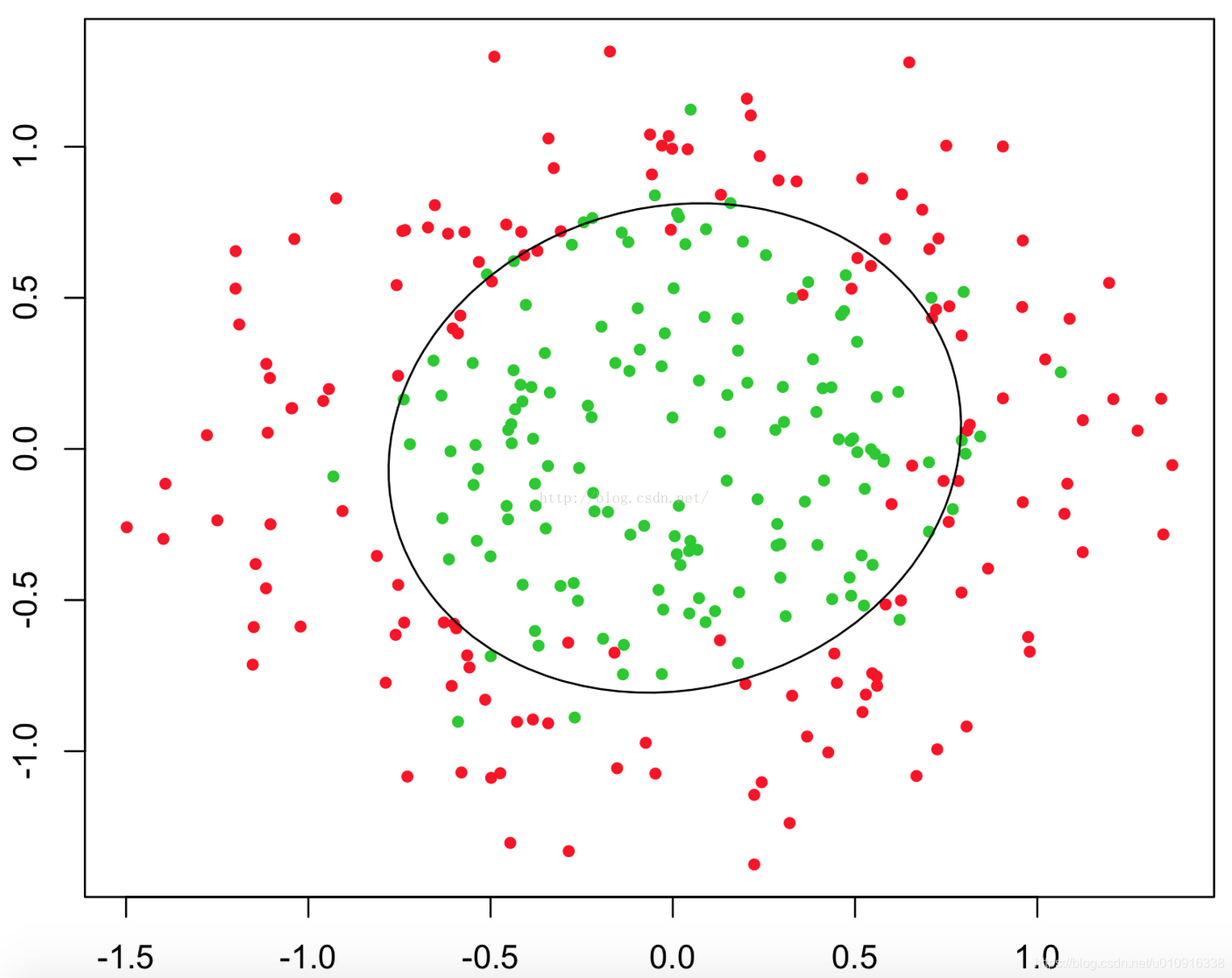
4.1.2 非线性判定边界
例如: ,
分别取-1,0,0,1, 1。当
时,y=1。
是一个决策边界,如下图所示:
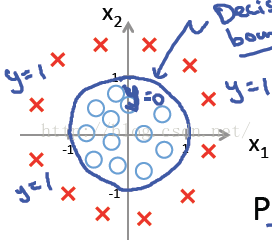
理论上说,只要设计的足够合理,准确的说是
中的
足够复杂,我们就能在不同的情形下,拟合出不同的判定边界,从而把不同的样本点分隔开来。
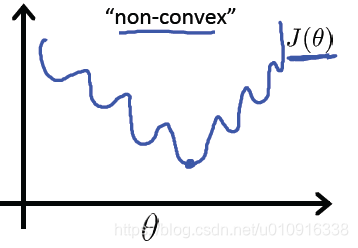
4.2 线性回归代价函数
如果逻辑回归也用这个代价函数的话,会引发代价函数非凸的问题,简单点说就是有局部最小值,如下图所示:
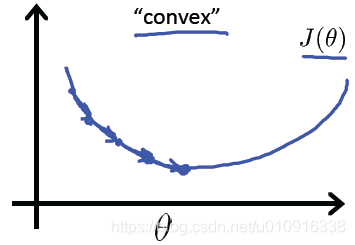
我们想要的是凸函数,如下图所示:
4.3 逻辑回归代价函数
下面解释这个代价函数的合理性:
(1)当y=1时,代价函数如下图所示:
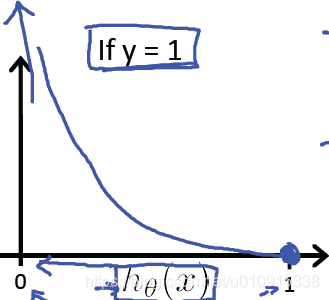
此时真实类别为y=1。
如果则cost = 0,此时预测值和真实值完全相等,代价函数为0非常合理。
而如果则
,此时预测值和真实值偏差越来越大,相应的代价函数也越来越大,这很好地惩罚了最后的结果。
(2)当y=0时,代价函数如下图所示:
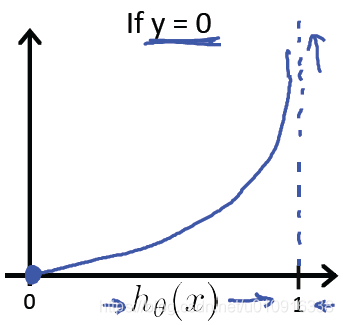
此时真实类别为y=0。
如果则cost = 0,此时预测值和真实值完全相等,代价函数为0非常合理。
而如果则
,此时预测值和真实值偏差越来越大,相应的代价函数也越来越大,这很好地惩罚了最后的结果。
4.3.1 合并逻辑回归代价函数
参考资料中 会用如下代价函数:
但是本文采用如下代价函数,目的是为了和最大似然估计做对比。
(注:只是少求了误差和的平均值,误差和大误差和的均值也就大,所以并不影响结果!!!)
(注:表示所有样本误差和,
是真实值,要么等于1,要么等于0)
4.3.2 求逻辑回归代价函数最小值
上面合并后的逻辑回归代价函数有没有很眼熟,是的,和3.5中的最大似然估计中求导的部分如出一辙。
引用3.5中的公式:
则:
4.3.3 梯度下降
这里代价函数是要求其最小值,代价函数越小,模型越准确。所以要用到梯度下降。
(注:是学习率,即步长。
只是代表了
θ向量的一个分量变化的情况,实际上n个θ分量都是这样变化的)
如上式所示,和3.7的结果一模一样!!!
=======================================================================
参考博文:


















 725
725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










