



优化前主要问题
- 吞吐量– 数据量达到1.59M 后 迅速下降
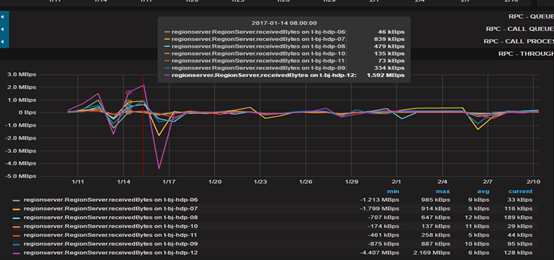
- 虽然创建了13个预分区,但是由于单个请求的量依然很大,所以请求还是分摊在3-4台机器上,分布式集群的能力没有完全发挥出来
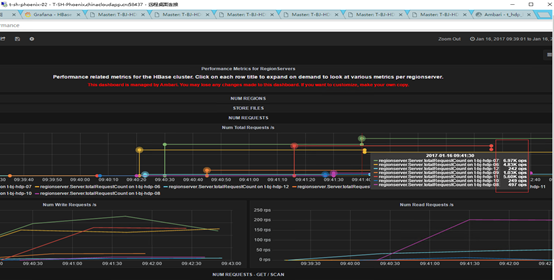
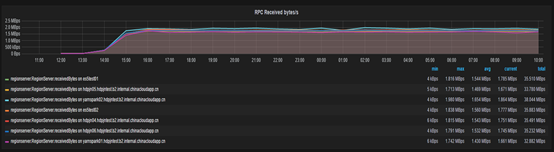
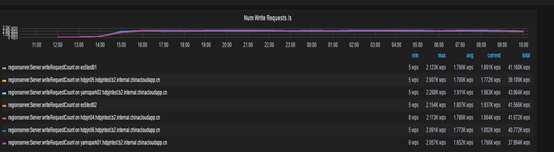
优化后
- 请求达到了64000/s
- 每秒请求平均在>1.5M
- 请求数 下降
- MemberStore 占用提升 -4.1G

写入流程
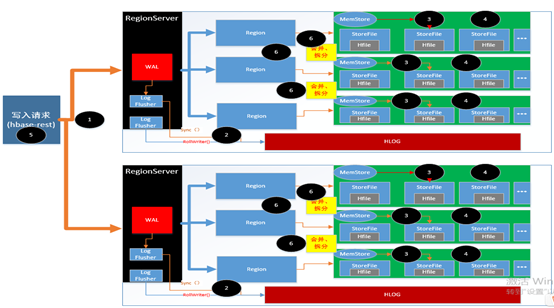
优化
- 利用分布式集群优势,确保请求负载均衡
结合具体数据的RowKey特征创建预分区
create 'Monitor_','d', SPLITS => ['HSF.Response.Receive|', 'HSF.Response.Sent|', 'Teld.SQL|','HSF.Request.Time|']
写入时默认在RowKey 之前增加一位,A-Z
数据读取时,去掉RowKey的第一位
- 集群的RegionServer 在某些情况下会阻止数据的写入,尽量减少这种情况的发生
- 根据数据灵活调整WAL的持久化等级
- WAL默认的等级为同步,会阻塞数据的写入。
- 一般的持久化等级采用异步即可,对于写入量很大的监控数据不在写入wal
alter 'Monitor', METHOD => 'table_att', DURABILITY => 'SKIP_WAL'


- 提高RegionServer 处理外部请求的能力
- 调整 hbase.hstore.blockingStoreFiles 的大小,默认值为7, 生产环境调整到100000
- Memstore 在flush前,会进行storeFile的文件数量校验,如果大于设定值,则阻止这个Memsore的数据写入,等待其他线程将storeFile进行合并,为了建设合并的概率,建设写入的阻塞,提高该参数值
- 由于region split 期间,大量的数据不能读写,防止对大的region进行合并造成数据读写的时间较长,调整对应的参数,如果region 大小大于20G,则region 不在进行split
hbase.hstore.compaction.max.size 调整为20G 默认为 Long.MAX_VALUE(9223372036854775807) - region server在写入时会检查每个region对应的memstore的总大小是否超过了memstore默认大小的2倍(hbase.hregion.memstore.block.multiplier决定),如果超过了则锁住memstore不让新写请求进来并触发flush,避免产生OOM
hbase.hregion.memstore.block.multiplier 生产为8 默认为2
4 增加hlog 同步到磁盘的线程个数
hbase.hlog.asyncer.number 调整大10 默认为5
5 写入数据量比较大的情况下,避免region中过多的待刷新的memstore,增加memstore的刷新线程个数
hbase.hstore.flusher.count 调整到20 默认为1
- 减少客户端和服务端ipc,请求的次数,可以批量写入的采用批量写入
- 针对目前每次写入的数据量变大,调整服务端处理请求的线程数量
- hbase.regionserver.handler.count 默认值为10 调整到400
- 增加hbaserest 端并行执行的能力
- 增加hbrest 并行处理的线程个数
- 'hbase.rest.threads.max 调整到400
- 采用hbase的批量写入
- hbase.client.write.buffer 修改为5M
配置:
默认 修改 描述 zookeeper.session.timeout 180000ms 600000 zk超时时间 hbase.regionserver.thread.compaction.throttle 53687091200 默认为2 * hbase.hstore.compaction.max * hbase.hregion.memstore.flush.size
全部取默认值等于2*10*128MB = 2.5GB hbase.zookeeper.property.tickTime 6000ms 心跳间隔 hbase.regionserver.optionalcacheflushinterval 3600000ms memstore刷新间隔, 防止产生大量小文件 hbase.client.scanner.timeout.period 60000ms 1200000ms 单次scan超时时间 hbase.rpc.timeout 60000ms 1200000ms rpc请求超时时间 hbase.regionserver.lease.period 60000ms 1200000ms 客户端租用HRegion server 期限 phoenix.query.timeoutMs 180000ms hbase.regionserver.handler.count 10 400 regionserver能够处理的请求线程数 hbase.master.namespace.init.timeout 1200000 phoenix.coprocessor.maxServerCacheTimeToLiveMs 30000 1800000 服务器端缓存的最大生存时间 phoenix.coprocessor.maxMetaDataCacheTimeToLiveMs 180000 1800000 服务器端元数据缓存的过期时间 hbase.hstore.blockingStoreFiles 10 1000 storefile数量达到多少时block住update操作 index.writer.threads.max 10 200 index.builder.threads.max 10 200 org.apache.phoenix.regionserver.index.handler.count 30 200 hbase.regionserver.hlog.blocksize 32m 536870912 hlog大小 hbase.regionserver.maxlogs 32 hlog数目 hbase.wal.provider multiwal hbase.wal.regiongrouping.numgroups 16 hbase.regionserver.maxlogs 4 hbase.regionserver.thread.compaction.small 1 1 小合并线程数,影响cpu使用及io hbase.regionserver.thread.compaction.large 1 1 大合并线程数 hbase.hstore.compaction.max.size 4294967296 超过此大小不参与合并 hbase.hstore.flusher.count 2 8 flush线程数 hbase.hlog.asyncer.number 5 10 syncer线程数 hbase.hstore.blockingWaitTime 90000 30000 阻止写等待时间 hbase.server.thread.wakefrequency 10000 2000 检查memostore大小间隔 hbase.rest.threads.max 100 400 rest线程 hbase.regionserver.hlog.splitlog.writer.threads 3 10 hregion启动时日志分割 hbase.client.write.buffer 2m 5242880 客户端写入缓存 hbase.regionserver.optionallogflushinterval 1000ms 10000ms wal刷到hdfs时间间隔 hbase.ipc.server.callqueue.handler.factor 0.1 0.2 hbase.ipc.server.callqueue.read.ratio 0.4 hbase.ipc.server.callqueue.scan.ratio 0.6


















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










