




一、RAG:大模型的外置知识库
1.1 场景
假设你正在开发一款公司内部智能客服系统。用户问:“我们公司今年新入职员工的社保缴纳流程是怎样的?”
你兴冲冲地调用 GPT-5 的 API,结果它一本正经地回答:“根据 2023 年颁布的《社会保险法》,新员工入职后 30 日内,用人单位需向社保经办机构办理登记……”
答对了,但也没完全对。因为它回答的是通用流程,而你公司的内部流程是:先走 OA 系统发起入职申请,然后由 HR 专员在内部 HRM 系统录入,再同步给第三方社保代缴机构——这个信息,模型根本不知道。
这暴露了大模型的一个本质问题:它只见过公开的训练数据,没见公司的私有文档。
1.2 RAG 到底是什么
RAG 的全称是 Retrieval-Augmented Generation,中文叫“检索增强生成”,拆开来看就很好理解:
-
检索:先在你自己的知识库(比如内部文档、数据库)里搜一圈,找到相关的信息
-
增强:把这些信息“塞”给大模型,作为它回答问题的上下文
-
生成:模型基于这些真实信息生成答案
用个不太严谨但很直观的类比:大模型就像一个“知识储备很广但记忆力很差”的专家。训练数据是他的大学教材,但你们公司内部的事,教材上没写。RAG 就是先帮他翻翻公司的文件柜(检索),找到相关的备忘录,再让他看备忘录回答问题。
1.3 RAG 在大模型应用链路中的位置
一个典型的 RAG 应用,流程大概是这样的:
text
1.用户提问
↓
2.[查询改写] ← 可选,优化用户问题
↓
3.[向量检索] ← 去向量数据库里找最相似的文档片段(切片后召回)
↓
4.[上下文增强] ← 把检索结果和原问题拼装成 Prompt
↓
5.[模型调用] ← 发给大模型
↓
6.[答案生成] ← 返回给用户
RAG 占据了从用户输入到模型调用之间的“中间地带”(核心2-3-4)。它不是替代大模型,而是给大模型装上一个“可实时更新的外部知识库”。
1.4 RAG 解决了哪几个核心问题
| 问题 | 没有 RAG | 有 RAG |
|---|---|---|
| 知识滞后 | 模型训练数据截止 2023 年,问 2024 年的事就瞎编 | 只要最新文档入库,就能回答 |
| 私有数据 | 公司内部文档、业务数据,模型一概不知 | 把内部文档喂给 RAG,模型“学会”了 |
| 幻觉问题 | 对不熟悉的问题,模型会编造看似合理但错误的答案 | 答案有检索结果作为依据,大大降低幻觉 |
| 成本控制 | 把全部上下文塞进 Prompt,Token 消耗巨大 | 只检索相关片段,Token 量可控 |
二、为什么选择 Spring AI
Java 生态里做 RAG 的工具不少,LangChain4j 也是一个优秀的选择。但我最终选择 Spring AI 作为这篇文章的主角,原因很简单:
因为大多数 Java 后端项目,本来就在用 Spring Boot,Spring生态的支持可以低学习成本融入项目
Spring AI 的理念是“AI 领域的 Spring Data”——它不搞一套新东西,而是把 AI 能力封装成 Spring 开发者熟悉的模式:
-
用
@Service注入ChatClient -
用
@Bean配置模型和向量库 -
用
application.yml管理配置
可以把它理解成:Spring 团队帮你把 OpenAI、Ollama、智谱这些模型的调用,包装成了熟悉的 Bean。Vector Store(向量数据库)也是一样,PGVector、Milvus、Elasticsearch 都有一致的使用方式。
这种“一致性”对于工程落地很重要。不会因为引入了 AI 能力,就让整个项目的代码风格变得面目全非。
三、动手实战:一个完整的 RAG 应用
3.1 我们要做什么
目标是构建一个“个人知识库助手”——一个简单的问答应用,允许用户上传自己的文档(比如公司制度、技术笔记、会议纪要),然后基于这些文档进行问答。
为了兼顾实用性和可跑通性,技术栈如下:
-
Spring Boot 3.2 + Java 17
-
Spring AI 1.0.0-M3(最新里程碑版)
-
OpenAI 作为大模型(可用国内模型替代,如智谱等)
-
PGVector 作为向量数据库(PostgreSQL 扩展,本地开发很方便)
-
Markdown 文档作为知识源
3.2 项目初始化
先创建一个 Spring Boot 项目,pom.xml 中添加 Spring AI 的 BOM 和核心依赖:
xml

3.3 配置文件
application.yml 中配置 OpenAI(你需要换成自己的 API Key)和 PGVector:
yaml
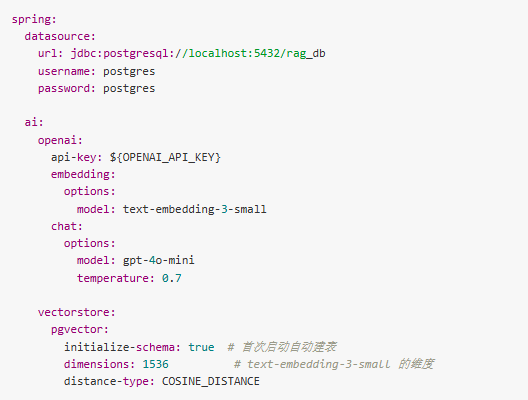
一个小提示:initialize-schema: true 这个配置很贴心,首次启动时 Spring AI 会自动创建 vector_store 表,不用手动写 SQL。生产环境建议关掉,用 Flyway 管理。
3.4 核心代码
3.4.1 文档加载与向量化
这是 RAG 的“入库”环节。我们提供一个接口,接收 Markdown 文本,分块后存入向量库。
java

解释一下:TokenTextSplitter 按 Token 数切分,保证每个片段不超过 500 Token(约 350~400 个汉字)。200 是重叠长度,避免关键信息被截断在片段边界上。
3.4.2 问答接口——RAG 的核心
这是整个应用最核心的部分,只有几行代码,但已经把“检索 + 增强 + 生成”都串起来了。
java

来拆解一下这段代码:
-
similaritySearch(query, topK):把用户的问题向量化,去 PGVector 里找余弦距离最近的前 4 个片段。这 4 个片段就是和问题最相关的知识。 -
context拼接:把检索到的片段用分隔符拼成一个字符串。这里用---隔开,是为了让模型能区分不同来源。 -
chatClient.prompt().system(...):替换 System Prompt 里的占位符。Spring AI 的ChatClient和 Spring 的RestClient设计风格很像,链式调用很顺滑。 -
.stream().content():用流式返回,用户能实时看到模型一个字一个字往外蹦,体验比等半天一次性返回好得多。
3.4.3 一个更优雅的写法(使用 Advisors)
上面手动拼接 context 的方式已经能跑通,但 Spring AI 还提供了一种更“声明式”的写法——用 QuestionAnswerAdvisor:
java
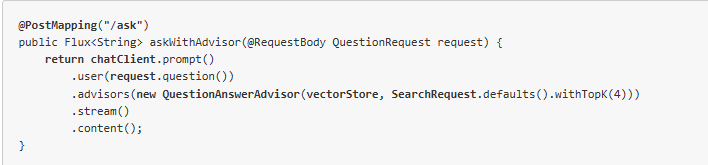
QuestionAnswerAdvisor 会在背后帮你做三件事:
-
用用户问题去检索
-
把检索结果自动拼接到 System Prompt
-
处理一些边界情况(比如检索结果为空时的降级)
这也是 Spring AI 的“RAG 原生”设计——它把 RAG 这个流程做成了一个可以“插拔”的切面。
3.5 一个完整的调用流程
写一个简单的测试脚本,看看效果:
bash
# 先入库一份文档
curl -X POST http://localhost:8080/api/documents \
-H "Content-Type: application/json" \
-d '{
"fileName": "员工手册.md",
"content": "# 新员工社保流程\n\n新员工入职后,请在 3 个工作日内完成以下操作:\n1. 在 OA 系统发起入职申请\n2. HR 在 HRM 系统录入员工信息\n3. 系统自动同步给第三方代缴机构「易社保」\n\n注意:每月 15 日前入职的,当月开始缴纳社保。"
}'
# 提问
curl -X POST http://localhost:8080/api/chat/ask \
-H "Content-Type: application/json" \
-d '{"question": "新员工的社保什么时候开始交?"}'
返回结果大致是:
根据公司规定,每月 15 日前入职的员工,当月开始缴纳社保。具体流程可参考 OA 系统的入职申请模块。
如果问一个知识库里没有的内容,比如“年假有多少天”,模型会老实回答:
找不到相关信息。请查阅公司 HR 系统或联系人力资源部门。
3.6 几个提升检索质量的最佳实践
在实际项目中,上面这个“Hello World”版 RAG 可能不够用。结合我踩过的坑,有几点优化建议:
3.6.1 文档切分策略
不同文档类型,切分方式应该不同:
-
Markdown/技术文档:按标题切分,保证每个片段是语义完整的章节
-
会议纪要:按段落切分,因为会议纪要的段落本身就是独立信息点
-
代码:用代码专用的分割器,按函数/类切分
Spring AI 提供了多种 TextSplitter,你也可以自己实现一个,按 --- 或 # 切分。
3.6.2 元数据过滤
检索时可以加上过滤条件,比如只查某个目录下的文档:
java

这个功能在有多租户、多知识库的场景下非常重要。
3.6.3 检索结果重排序
向量检索出来的 topK 结果,不一定完全符合“相关性”预期。可以加一层重排序(Re-ranking),比如用 Cross-Encoder 模型对结果重新打分。Spring AI 目前不内置重排序,但你可以自己实现一个 RetrievalAugmentor。
四、踩坑与避坑指南
4.1 向量维数不匹配
这是最常见的问题。text-embedding-3-small 是 1536 维,text-embedding-ada-002 也是 1536 维,但有些国产模型可能是 1024 维或 768 维。配置中的 dimensions 必须和模型输出的维度一致,否则插入时报错。
4.2 上下文太长导致 Token 超限
如果检索出来的 4 个片段每个都有 500 Token,加上 System Prompt 和用户问题,轻松超过 8K 甚至 128K 模型的上限(虽然上限高,但费用也高)。可以:
-
调小
topK -
调小每个片段的长度
-
在拼接到 Prompt 之前对检索结果做一次“压缩”(比如提取摘要)
4.3 流式返回的异常处理
流式接口返回 Flux<String>,如果中间模型调用失败,异常不会在 HTTP 响应里体现,而是让连接断开。建议用 onErrorResume 做兜底:
java

五、小结
RAG 的本质,并不是什么高深的技术,而是让大模型学会找私有数据。
Spring AI 的价值在于,它把这个过程封装成了 Java 开发者熟悉的方式:用 VectorStore 管理私有数据,用 ChatClient 和 Advisor 完成问答。提供快速构建一个可用的 RAG 应用的能力。
当然,一个生产级的 RAG 系统还有很多细节要打磨:文档更新怎么办?怎么做权限控制?检索质量怎么评估?这些是后续优化的方向,但第一步——跑通一个完整的流程——我们今天已经完成了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










