






1.背景介绍
为了看小说不看广告,自己用Python实现从一个小说网站抓取小说,小工具功能简单,但还不完善,目前只能在线阅读,可以把已经加载的章节保存到本地,实现本地阅读。初步完成全部下载和导出纯文本文件,这样就可以导入到手机中阅读了。
2.使用说明
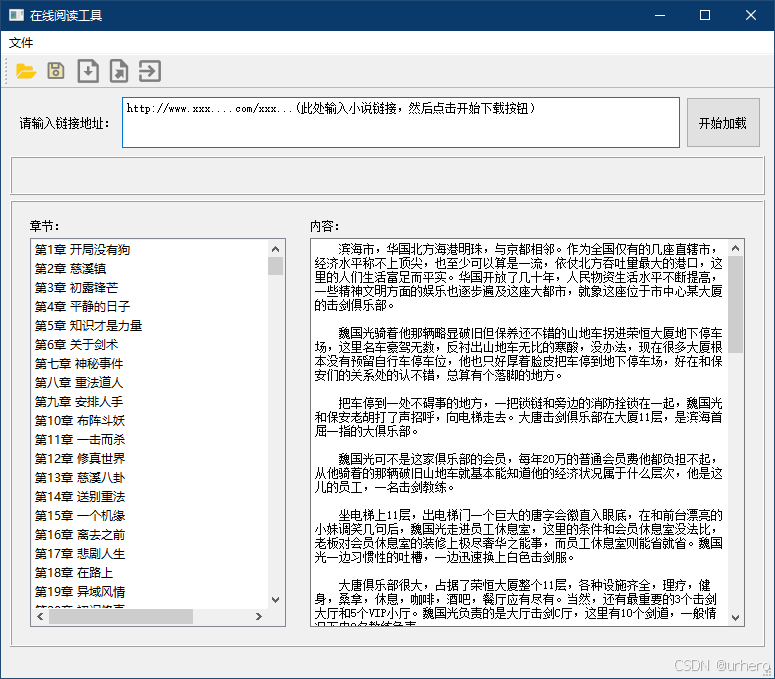
2.1加载小说
输入某部小说首页网址,单击开始加载,可刷出小说所有章节,并在右侧显示第一章的小说文本。
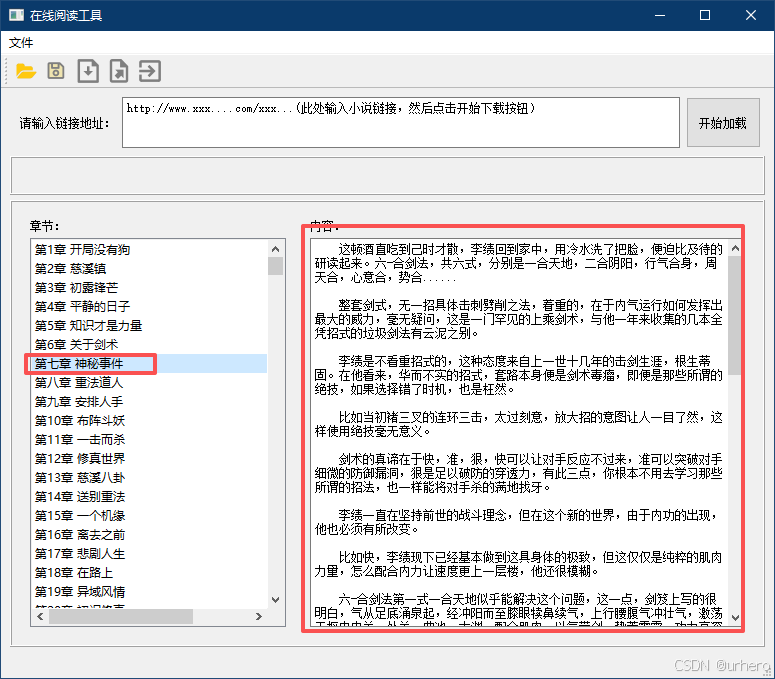
2.2.保存文件
单周左侧列表中的章节,可在右侧显示相应章节内容。点击保存按钮可以将已经打开浏览过的章节保存到本地文件,可以脱机阅读。
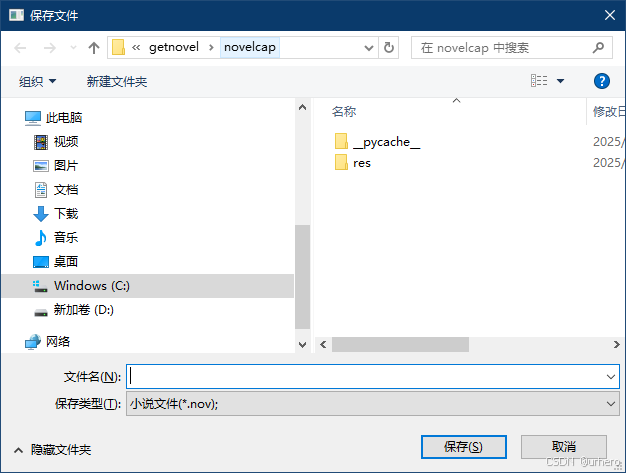
2.3 打开本地文件阅读
单击工具栏中的打开按钮,选择已保存在本地的小说文件,可加载本地小说阅读。
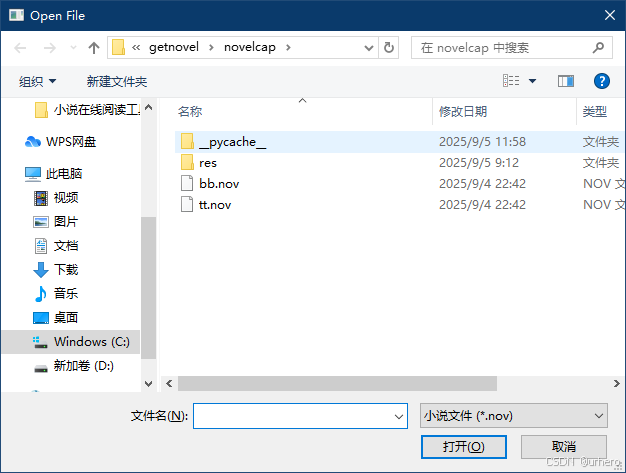
点击打开按钮,加载本地小说阅读。
2.4 窗口阅读区自适应窗口
点击列表中的章节可继续本地阅读。在电脑上阅读小说可以选择最大化窗口,或者根据需要调节窗口到合适的大小阅读。
2.5 下载和导出
已实现下载全部章节功能,可导出txt纯文本文件,但还有些小Bug(字符编码、网站防爬策略导致部分章节下载失败),还在测试中……将来有可能成为小说爱好者的福音。
3.关键代码分享
以下是下载章节数据关键代码,根据不同网站可能需要做相应的调整,或者进行代码完善,对不同网站的解析规则兼容,实现可以下载不同网站的小说。
import requests
from bs4 import BeautifulSoup
import os
def download_novel_chapters(url, output_file, chapter_count=3):
try:
# 获取小说目录页
response = requests.get(url)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
# 查找章节链接
chapters = []
for link in soup.find_all('a'):
href = link.get('href')
print(href)
if href and 'chapter' in href.lower():
chapters.append(href)
# 默认只取前三章
chapters = chapters[:chapter_count]
# 下载每章内容
content = ""
for i, chapter_url in enumerate(chapters, 1):
if not chapter_url.startswith('http'):
chapter_url = url + chapter_url
chapter_response = requests.get(chapter_url)
chapter_response.encoding = 'utf-8'
chapter_soup = BeautifulSoup(chapter_response.text, 'html.parser')
# 提取章节标题和内容
title = chapter_soup.find('h1').text if chapter_soup.find('h1') else f"第{i}章"
content += f"\n\n{title}\n\n"
# 提取正文内容
for p in chapter_soup.find_all('p'):
content += p.text + '\n'
print(f"已下载: {title}")
# 保存到文件
with open(output_file, 'w', encoding='utf-8') as f:
f.write(content)
print(f"\n{chapter_count}章内容已成功保存到: {output_file}")
except Exception as e:
print(f"下载过程中出错: {e}")
4. 感谢支持
喜欢看小说的朋友可以交流一下心得,以便软件功能更加好用,感谢大家支持!!!
目前只实现了基本的功能,还有很多功能有待完善。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












