在Ubantu上使用VLLM本地部署大模型(实战篇)
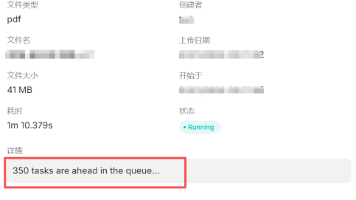
在大模型应用落地的过程中,本地部署不仅能保障数据安全、降低云服务成本,还能实现更低的推理延迟。VLLM(Virtual Large Language Model)作为一款高性能大模型推理引擎,凭借其 PagedAttention 技术,在吞吐量和延迟上表现优异,成为本地部署的优选方案。本文将从环境准备、模型下载、Docker 部署到 RAGFlow 集成,完整演示在 Ubuntu 系统上使用 VLLM 本地部署大模型的全流程,帮助开发者快速搭建属于自己的本地大模型服务。