




LoRA
局部参数微调,比传统微调,可训练参数更少
LoRA 中 ΔW 的核心原理
LoRA 的核心思想:用低秩矩阵分解来近似原本高秩的权重更新矩阵,从而大幅减少可训练参数的数量
数学定义
假设原模型中有一个权重矩阵 (比如大语言模型中的注意力层权重),LoRA 不直接更新 W
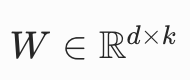
而是引入两个低秩矩阵:

r 是秩(rank),通常远小于 d 和 k(比如 r=8,16,32)
权重更新矩阵:ΔW=A⋅B
最终训练时,模型的实际权重为:
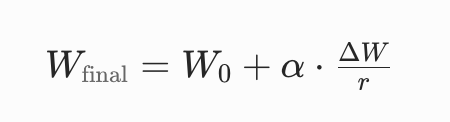
W0:预训练模型的原始权重(冻结不更新,两个权重单独存储,分开存储,扩展性更高)
α:缩放系数(平衡低秩更新的幅度,通常设为 r)
应用Lora之前,为什么要冻结原始模型参数?
防止LoRA微调过程中不被更新,确保只训练规模较小的LoRA矩阵
α 超参作用
低秩自适应矩阵的输出缩放因子
α/r 是为了让 ΔW 的幅度不随秩 r 变化,比如 r=8 和 r=32 时,调整 α 可保持更新强度一致,方便超参数迁移
r 超参作用
rank,秩,决定矩阵A和B的内部维度,控制LoRA微调时引入的额外参数量
什么是超参数迁移
把为某一组超参数(比如 r=8,α=8)调好的训练策略 / 参数,复用到另一组超参数(比如 r=16,α=16)上,且能保证模型效果基本一致


为什么这样近似?
高秩矩阵 ΔW 原本需要 d×k 个参数,而分解为 A 和 B 后仅需 d×r+r×k=r(d+k) 个参数
比如 d=k=4096、r=16 时:
原更新矩阵:4096×4096=16,777,216 个参数
LoRA 分解后:16×(4096+4096)=131,072 个参数(仅为原参数的 0.78%)
ΔW 的代码实现(PyTorch 示例)
代码展示 LoRA 中 ΔW 的计算和权重融合过程:
import torch
import torch.nn as nn
class LoRALayer(nn.Module):
def __init__(self, in_dim, out_dim, rank=8, alpha=8):
super().__init__()
# 冻结的预训练权重(模拟)
self.W0 = nn.Parameter(torch.randn(in_dim, out_dim), requires_grad=False)
# LoRA 低秩矩阵(仅这两个矩阵参与训练)
self.A = nn.Parameter(torch.randn(in_dim, rank)) # 输入投影,随机初始化
self.B = nn.Parameter(torch.zeros(rank, out_dim)) # 输出投影,初始化为0
# 缩放系数
self.alpha = alpha
self.rank = rank
def forward(self, x):
# 1. 计算低秩近似的权重更新矩阵 ΔW
# lora_layer.A @ lora_layer.B 是 PyTorch 中矩阵乘法的简洁写法,核心是计算 LoRA 的权重更新矩阵 ΔW
delta_W = self.A @ self.B # 矩阵乘法,得到 ΔW ∈ R^(in_dim × out_dim)
# 2. 带缩放的最终权重
W_final = self.W0 + self.alpha * delta_W / self.rank
# 3. 前向计算(等价于 x @ W_final)
return x @ W_final
# 测试
if __name__ == "__main__":
# 初始化:in_dim=1024, out_dim=1024, rank=16(典型的低秩设置)
lora_layer = LoRALayer(1024, 1024, rank=16)
# 输入(batch_size=8, 维度=1024)
x = torch.randn(8, 1024)
# 前向传播,自动计算 ΔW 并更新
output = lora_layer(x)
print(f"ΔW 的形状: {lora_layer.A @ lora_layer.B}")
print(f"输出形状: {output.shape}") # 应为 (8, 1024)
ΔW 的关键细节
初始化策略:
A 通常用正态分布随机初始化(保证初始更新幅度小)
B 初始化为全 0(保证训练初期 ΔW≈0,模型从预训练状态平滑更新,零矩阵加入使原始权重保持不变,初始化Lora不会改变预训练权重)
缩放系数的作用:
α/r 是为了让 ΔW 的幅度不随秩 r 变化,比如 r=8 和 r=32 时,调整 α 可保持更新强度一致,方便超参数迁移
推理阶段的融合:
训练完成后,可将 ΔW 直接加到 W0 上得到 Wfinal,推理时无需保留 A 和 B,和原模型结构完全一致,无额外计算开销
总结
LoRA 的 ΔW 是低秩矩阵 A(输入投影)和 B(输出投影)的矩阵乘积,核心是用低秩分解近似高秩权重更新
ΔW 的参数规模仅为 r(d+k),远小于原权重矩阵的 d×k,实现高效微调
最终权重为 W0 +α⋅ΔW/r,缩放系数保证更新幅度的稳定性,训练后可融合 ΔW 到原权重中


















中近似权重更新矩阵 ΔW(DW)的计算原理&spm=1001.2101.3001.5002&articleId=158540544&d=1&t=3&u=18842cd8e16a494187e03d75f87b0762)
 1723
1723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










