



 本文介绍了在pandas 0.23.3版本中,如何利用PyArrow在PySpark 3.0上实现新Pandas UDF的分布式处理,从而提高数据处理效率。
本文介绍了在pandas 0.23.3版本中,如何利用PyArrow在PySpark 3.0上实现新Pandas UDF的分布式处理,从而提高数据处理效率。
pandas 0.23.3
Data processing time is so valuable as each minute-spent costs back to users in financial terms. This article is mainly for data scientists and data engineers looking to use the newest enhancements of Apache Spark since, in a noticeably short amount of time, Apache Spark has emerged as the next generation big data processing engine, and is highly being practiced throughout the industry faster than ever.
数据处理时间非常宝贵,因为每分钟花费的费用都会从财务角度回馈给用户。 本文主要针对希望使用Apache Spark的最新增强功能的数据科学家和数据工程师,因为在很短的时间内,Apache Spark已经成为下一代大数据处理引擎,并且在整个行业中得到了广泛的实践。比以往更快。
Spark’s consolidated structure supports both compatible and constructible APIs that are formed to empower high performance by optimizing across the various libraries and functions built together in programs enabling users to build applications beyond existing libraries. It gives the opportunity for users to write their own analytical libraries on top as well.
Spark的统一结构支持兼容的API和可构造的API ,它们通过优化跨各种库和程序中共同构建的功能来支持高性能,从而使用户能够在现有库之外构建应用程序。 它还为用户提供了在其顶部编写自己的分析库的机会。
Data is costly to migrate so Spark concentrates on performing computations over the data, regardless of where it locates. In user-interacting APIs, Spark strives to manage these storage systems seem broadly related in case applications do not require to concern where their data is.
数据迁移成本很高,因此,Spark专注于对数据进行计算,无论其位于何处。 在用户交互API中 ,Spark努力管理似乎与这些存储系统密切相关的存储,以防应用程序不需要担心其数据在哪里。
When the data is too big to fit on a single machine with a long time to execute that computation on one machine drives it to place the data on more than one server or computer. This logic requires to process the data in a distributed manner. Spark DataFrame is the ultimate Structured API that serves a table of data with rows and columns. With its column-and-column-type schema, it can span large numbers of data sources.
如果数据太大而无法长时间容纳在一台计算机上,则无法在一台计算机上执行该计算,则驱动该数据将数据放置在多台服务器或计算机上。 此逻辑要求以分布式方式处理数据。 Spark DataFrame是最终的结构化API,可提供具有行和列的数据表。 凭借其列和列类型的架构,它可以跨越大量数据源。
The purpose of this article is to introduce the benefits of one of the currently released features of Spark 3.0 that is related to Pandas with Apache Arrow usage with PySpark in order to be able to execute a pandas-like UDFs in a parallel manner. In the following headings, PyArrow’s crucial usage with PySpark session configurations, PySpark enabled Pandas UDFs will be explained in a detailed way by providing code snippets for corresponding topics. At the end of the article, references and additional resources are added for further research.
本文的目的是介绍Spark 3.0当前发布的功能的好处,该功能与将PySpark与Apache Arrow配合使用的熊猫相关,以便能够以并行方式执行类似熊猫的UDF。 在以下标题中,将通过提供相应主题的代码段详细说明PyArrow在PySpark会话配置中的关键用法(启用PySpark的Pandas UDF)。 在本文的结尾,添加了参考资料和其他资源以进行进一步的研究。
1. PyArrow与PySpark (1. PyArrow with PySpark)
In the previous versions of Spark, there were inefficient steps for converting DataFrame to Pandas in PySpark as collecting all rows to the Spark driver, serializing each row into Python’s pickle format (row by row) and sending them to a Python worker process. At the end of this converting procedure, it unpickles each row into a massive list of tuples. In order to be able to overcome these ineffective operations, Apache Arrow that is integrated with Apache Spark can be used to empower faster columnar data transfer and conversion.
在早期版本的Spark中,在将所有数据行收集到Spark驱动程序,将每一行序列化为Python的pickle格式(逐行)并将其发送到Python工作进程时,没有效率低下的步骤将DataFrame转换为PySpark中的Pandas。 在此转换过程结束时,它将每一行解开为大量的元组列表。 为了能够克服这些无效的操作,可以使用与Apache Spark集成的Apache Arrow来实现更快的列式数据传输和转换。
1.1。 为什么将PyArrow与PySpark一起使用 (1.1. Why Use PyArrow with PySpark)
Apache Arrow helps to accelerate converting to pandas objects from traditional columnar memory providing the high-performance in-memory columnar data structures.
Apache Arrow帮助加速从传统列式内存转换为pandas对象的过程,从而提供了高性能的内存中列式数据结构。
Previously, Spark reveals a row-based interface for interpreting and running user-defined functions (UDFs). This introduces high overhead in serialization and deserialization and makes it difficult to work with Python libraries such as NumPy, Pandas which are coded in native Python that enables them to compile faster to machine code.
以前,Spark揭示了基于行的界面,用于解释和运行用户定义的函数(UDF)。 这在序列化和反序列化方面带来了高昂的开销,并使其难以使用Python库(例如NumPy和Pandas)进行编码,这些库使用本机Python进行编码,从而使它们能够更快地编译为机器代码。
With the newly proposed UDFs, it advocates introducing new APIs to support vectorized UDFs in Python, in which a block of data is transferred over to Python in some columnar format for execution by serializing block by block instead of row by row.
借助新提出的UDF,它提倡引入新的API以支持Python中的矢量化UDF,其中,将数据块以某种列格式传输到Python,以便通过逐块序列化来执行 而不是逐行 。
Pandas package is recognized by machine learning and data science specialists since it has coherent integrations with plenty of Python libraries and packages including scikit-learn, matplotlib, and NumPy.
Pandas软件包已与许多Python库和软件包(包括scikit-learn , matplotlib和NumPy)进行了紧密集成,因此受到了机器学习和数据科学专家的认可。
Also, Pandas UDFs support users both to distribute their data loads and to use the Pandas APIs in Apache Spark.
此外,Pandas UDF支持用户分发其数据负载并在Apache Spark中使用Pandas API。
The user-defined functions can be executed by:
用户定义的函数可以通过以下方式执行:
Apache Arrow enables to transfer of data precisely between Java Virtual Machine and executors of Python with zero serialization cost by leveraging the Arrow columnar memory layout to fasten up the processing of string data.
通过利用Arrow列式内存布局来加快字符串数据的处理速度, Apache Arrow可以在Java虚拟机和Python执行程序之间精确地传输数据,而序列化成本为零。
Pandas libraries to work with its instances and APIs.
熊猫库可使用其实例和API。
1.2。 Spark会话配置 (1.2. Spark Session Configurations)
For better performance, while executing jobs, the following configurations shall be set as follows.
为了获得更好的性能,在执行作业时,以下配置应设置如下。
To be able to benefit from PyArrow optimizations, the following configuration can be enabled by setting this config to true which is disabled by default : spark.sql.execution.arrow.pyspark.enabled
为了能够从PyArrow优化中受益,可以通过将该配置设置为true来启用以下配置 默认情况下是禁用的: spark.sql.execution.arrow.pyspark.enabled
The upper enabled optimization may fallback to the non-Arrow optimization implementation situation in case of an error. To cope with this issue that occurs the actual computation within Spark,fallback.enabled shall be set to true : spark.sql.execution.arrow.pyspark.fallback.enabled
在发生错误的情况下,启用上限的优化可能会退回到非箭头优化实现情况。 为了解决在Spark中发生实际计算的问题, fallback.enabled必须设置为true : spark.sql.execution.arrow.pyspark.fallback.enabled
Parquet-summary-metadata is not efficient to enable the following configurations for the below reasons:
由于以下原因,Parquet-summary-metadata 无法有效启用以下配置:
mergeSchema = false: It is assumed that the schema of all Parquet part-files is identical, for this reason, the footer can be read from any part-files.
mergeSchema = false:假定所有Parquet零件文件的模式都相同,因此,可以从任何零件文件中读取页脚。
mergeSchema = true: The footers are required to be read for all files to actualize the merge process.
mergeSchema = true :需要读取所有文件的页脚以实现合并过程。
spark.sql.parquet.mergeSchema false
spark.hadoop.parquet.enable.summary-metadata falseTo sum up, the final recommended list of Arrow optimized configurations are as follows:
总结起来,最终的建议箭头优化配置列表如下:
"spark.sql.execution.arrow.pyspark.enabled", "true""spark.sql.execution.arrow.pyspark.fallback.enabled", "true"
"spark.sql.parquet.mergeSchema", "false"
"spark.hadoop.parquet.enable.summary-metadata", "false"1.3。 要升级的软件包 (1.3. Packages to be Upgraded)
Proper usage of PyArrow and PandasUDF requires some packages to be upgraded in the PySpark development platform.
正确使用PyArrow和PandasUDF需要在PySpark开发平台中升级某些软件包。
The following list of packages is needed to be updated in order to be able to use the latest version of PandasUDF with Spark 3.0 in a proper way.
需要更新以下软件包列表,以便能够以适当的方式将最新版本的PandasUDF与Spark 3.0配合使用。
# Install with Conda
conda install -c conda-forge pyarrow# Install PyArrow with Python
pip install pyarrow==0.15.0# Install Py4j with Python
pip install py4j==0.10.9# Install pyspark with Python
pip install pyspark==3.0.0Also, you may need to assign a new environment variable in order not to face any issues with PyArrow upgrade of 0.15.1 when running Pandas UDFs.
另外,您可能需要分配一个新的环境变量,以免在运行Pandas UDF时遇到PyArrow 0.15.1升级的任何问题。
# Environment Variable Setting for PyArrow Version Upgrade
import os
os.environ["ARROW_PRE_0_15_IPC_FORMAT"] = "1"2.使用Python的PyArrow (2. PyArrow with Python)
2.1。 实木复合地板格式化文件的处理更快 (2.1. Faster Processing of Parquet Formatted Files)
PyArrow has a greater performance gap when it reads parquet files instead of other file formats. In this blog, you can find a benchmark study regarding different file format reads.
PyArrow 读取镶木地板文件而不是其他文件格式时,性能差距更大。 在此博客中,您可以找到有关不同文件格式读取的基准研究。
It can be used with different kinds of packages with varying processing times with Python:
它可以与不同种类的程序包一起使用,这些程序包在Python中具有不同的处理时间:
Parquet to Arrow :
pyarrow.parquet实木
pyarrow.parquet地板到箭头:pyarrow.parquet
# Importing PyArrow
import pyarrow.parquet as pqpath = "dataset/dimension"data_frame = pq.read_table(path).to_pandas()Parquet to Arrow with Pandas Dataframe :
pyarrow.parquetthen convert topandas.DataFrame使用Pandas Dataframe将木地板拼成箭头:
pyarrow.parquet然后转换为pandas.DataFrame
import pandas as pd
import pyarrow as pa
import pyarrow.parquet as pqpandas_df = pd.DataFrame(data={'column_1': [1, 2], 'column_2': [3, 4], 'column_3': [5, 6]})table = pa.Table.from_pandas(pandas_df, preserve_index=True)pq.write_table(table, 'pandas_dataframe.parquet')2.2。 计算脚本处理时间 (2.2. Calculating Script Processing Time)
As long as we are concerned with the performance and processing speed of written scripts, it is beneficial to be aware of how to measure their processing times.
只要我们关注书面脚本的性能和处理速度,了解如何衡量其处理时间将是有益的。
There exist two types of time-passed processing calculation when a Python script is executed.
执行Python脚本时,存在两种类型的经过时间的处理计算。
Processor Time: It measures how long a specific process actively being executed on the CPU. Sleep, waiting for a web request, or time are not included.
time.process_time()处理器时间 :它衡量特定进程在CPU上有效执行的时间。 不包括睡眠,等待Web请求或时间。
time.process_time()Wall-Clock Time: It calculates how much time has passed “on a clock hanging on the wall”, i.e. outside real time.
time.perf_counter()Wall-Clock Time :计算“挂在墙上的时钟上”经过的时间,即实时时间。
time.perf_counter()
There are additional ways to compute the amount of time spent on a running script.
还有其他方法可以计算运行脚本所花费的时间。
time.time()function is also quantifes time-passed as a wall-clock time; however it can be calibrated. For this reason, it is needed to go back in time to reset it.
time.time()函数也经过时间作为挂钟时间; 但是它可以被校准。 因此,需要及时返回以进行重置。
time.monotonic()function is monotonic that simply goes forward; however it has reduced precision performance thantime.perf_counter()
time.monotonic()函数是单调的,只会向前移动; 但是它比time.perf_counter()降低了精度性能time.perf_counter()
3. PySpark与熊猫UDF (3. PySpark with Pandas UDFs)
Pandas User-Defined Functions can be identified as vectorized UDF that is powered by Apache Arrow permits vectorized operations that serve much higher performance compared to row-at-a-time Python UDFs. They can be accepted as the most impactful improvements in Apache Spark by means of distributed processing of customized functions. They bring countless benefits, including empowering users to use Pandas APIs and improving performance.
熊猫用户定义的功能 可以识别为由Apache Arrow提供支持的矢量化UDF,它允许矢量化操作的性能要比一次性Python UDF高得多。 通过自定义函数的分布式处理,它们可以被接受为Apache Spark中最具影响力的改进。 它们带来了无数的好处,包括授权用户使用Pandas API和改善性能。
Ingesting Spark customized function structures in Python reveals its advanced functionality to SQL users by allowing them to call in the functions without generating the extra scripting effort to connect their functionalities.
通过在Python中摄取Spark自定义函数结构 ,SQL用户可以允许他们调用函数而无需产生额外的脚本工作来连接其功能,从而向SQL用户展示了其高级功能。
Functions can be executed by means of Row, Group, and Window while data formats can be used as Series for column and DataFrame for table structures.
功能可以通过的装置执行行 , 组 ,和窗口而数据格式可以为柱和数据帧被用作系列 用于表结构。
3.1。 标量熊猫UDF (3.1. SCALAR Pandas UDF)
Scalar type of Pandas UDF can be described as the conversion of one or more Pandas Series into one Pandas Series. The final returning data series size is expected to be the same as the input data series.
标量类型的熊猫UDF可描述为将一个或多个熊猫系列转换为一个熊猫系列 。 最终返回的数据系列大小应与输入数据系列相同。
import pandas as pdfrom pyspark.sql.functions import pandas_udf
from pyspark.sql import Windowdataframe = spark.createDataFrame(
[(1, 5), (2, 7), (2, 8), (2, 10), (3, 18), (3, 22), (4, 36)],
(“index”, “weight”))# The function definition and the UDF creation
@pandas_udf(“int”)
def weight_avg_udf(weight: pd.Series) -> float:
return weight.mean()dataframe.select(weight_avg_udf(dataframe[‘weight’])).show()
3.2。 GROUPED_AGG熊猫UDF (3.2. GROUPED_AGG Pandas UDF)
Grouped Agg of Pandas UDF can be defined as the conversion of one or more Pandas Series into one Scalar. The final returned data value type is required to be primitive (boolean, byte, char, short, int, long, float, and double) data type.
熊猫UDF的分组Agg可定义为将一个或多个熊猫系列转换为一个标量 。 最终返回的数据值类型必须是原始(布尔,字节,字符,short,int,long,float和double)数据类型。
# Aggregation Process on Pandas UDFdataframe.groupby("index").agg(weight_avg_udf(dataframe['weight'])).show()w = Window \
.partitionBy('index') \
.rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)
# Print the windowed resultsdataframe.withColumn('avg_weight', weight_avg_udf(dataframe['weight']).over(w)).show()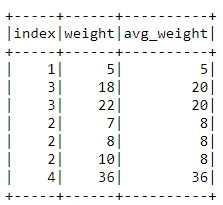
3.2。 GROUPED_MAP熊猫UDF (3.2. GROUPED_MAP Pandas UDF)
Grouped Map of Pandas UDF can be identified as the conversion of one or more Pandas DataFrame into one Pandas DataFrame. The final returned data size can be arbitrary.
熊猫UDF分 组图可以标识为将一个或多个熊猫数据框转换为一个熊猫数据框 。 最终返回的数据大小可以是任意的。
import numpy as np# Pandas DataFrame generation
pandas_dataframe = pd.DataFrame(np.random.rand(200, 4))def weight_map_udf(pandas_dataframe):
weight = pandas_dataframe.weight
return pandas_dataframe.assign(weight=weight - weight.mean())dataframe.groupby("index").applyInPandas(weight_map_udf, schema="index int, weight int").show()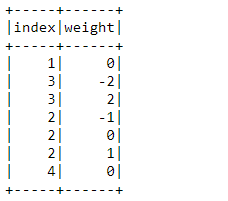
According to the specifications of your input and output data, you can switch between these vectorized UDFs by adding more complex functions to them.
根据输入和输出数据的规范,可以通过向这些矢量化的UDF添加更复杂的功能来进行切换。
The full implementation code and Jupyter Notebook is available on my GitHub.
完整的实现代码和Jupyter Notebook可在我的GitHub上找到 。
Questions and comments are highly appreciated!
问题和评论深表感谢!
4.参考 (4. References)
5.其他资源 (5. Additional Resources)
pandas 0.23.3


















 8730
8730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










