




简介:在Red Hat Linux 9.0系统中,Shell脚本是实现系统自动化管理的核心工具。本文介绍了一个包含多个实用.sh脚本的压缩包LinuxShell.rar,涵盖备份、系统信息展示、网络ARP管理及用户增删等典型运维任务。这些脚本基于基础命令如tar、cron、arp、useradd等,体现了Linux系统管理的关键操作,适合初学者学习与实践,有助于深入理解Shell脚本编程和老版本RHEL系统的维护方式。
1. Red Hat Linux 9.0系统环境概述
Red Hat Linux 9.0 是一款面向企业级应用与开发者的现代化操作系统,基于上游 RHEL(Red Hat Enterprise Linux)源码构建,集成了最新的内核特性与安全增强机制。其默认采用 GNOME 桌面环境与 Bash 5.1 作为主 Shell,提供稳定的系统运行环境和强大的命令行支持能力。
该系统强化了 SELinux 安全策略、软件包管理(DNF/YUM)、网络服务配置及容器就绪(Podman、Buildah)等关键功能,适用于服务器部署、运维自动化与脚本开发等多种场景。对于 Shell 脚本编写而言,其一致的文件结构(如 /etc/profile 、 /bin/sh 指向 Bash)和标准 POSIX 兼容性为自动化任务提供了可靠基础。
此外,Red Hat Linux 9.0 对脚本执行环境进行了优化,默认开启审计日志、时间同步(chronyd)和防火墙(firewalld),保障了脚本在生产环境中稳定、安全地长期运行。
2. Shell脚本基础语法与执行机制
在现代 Linux 系统管理中,自动化运维已成为不可或缺的核心能力。而 Shell 脚本作为实现这一目标的最基本、最灵活的工具之一,在 Red Hat Enterprise Linux 9.0 这样的企业级操作系统中扮演着至关重要的角色。它不仅是系统管理员日常维护工作的“快捷键”,更是构建复杂自动化流程的基石。本章节将深入剖析 Shell 脚本的基础语法结构与底层执行机制,从概念理解到实际编码规范,再到变量控制和调试策略,全面打通初学者向高级使用者跃迁的技术路径。
通过系统性地讲解 Shell 的工作原理、脚本编写标准、执行方式差异以及输入输出控制逻辑,读者不仅能掌握如何写出可运行的脚本,更能理解其背后的操作系统交互机制。例如,为何需要 #!/bin/bash ? source 和 ./script.sh 的本质区别是什么?环境变量是如何影响脚本行为的?这些问题的答案不仅关乎脚本能否正确执行,更关系到脚本在生产环境中是否具备可移植性、安全性和可维护性。
此外,随着 DevOps 实践的普及,越来越多的企业开始将 Shell 脚本集成进 CI/CD 流水线或监控体系中。因此,对脚本调试机制和错误处理能力的要求也日益提高。本章特别强调使用 set -x 进行动态追踪,并结合退出状态码(exit status)构建健壮的异常响应逻辑,为后续章节中如备份、用户管理和网络诊断等实战脚本打下坚实基础。整个内容设计遵循由浅入深的认知规律,先建立理论框架,再辅以代码示例与流程图解析,确保技术细节与工程实践并重。
2.1 Shell的基本概念与工作原理
Shell 并非一个单一程序,而是指代一类介于用户与内核之间的命令解释器(Command Interpreter)。它的核心职责是接收用户的输入命令,解析后调用相应的系统调用或外部程序,并将结果返回给用户。在 Red Hat Linux 9.0 中,默认使用的 Shell 是 GNU Bash(Bourne-Again SHell),它是 Bourne Shell(sh)的增强版本,兼容 POSIX 标准,同时提供了丰富的扩展功能,如命令历史、别名、作业控制、条件判断和循环结构等。
2.1.1 什么是Shell及其在Linux系统中的角色
Shell 是 Linux 操作系统架构中用户空间(User Space)的关键组成部分。它位于操作系统内核之上,充当人机交互的桥梁。当用户通过终端登录系统时,系统会根据 /etc/passwd 文件中指定的默认 Shell 启动对应的解释器进程。例如,若某用户的 Shell 设置为 /bin/bash ,则系统将启动 bash 解释器来处理该用户的命令输入。
从系统层级来看,Shell 的作用可以归纳为以下几个方面:
- 命令解析与执行 :Shell 接收用户输入的命令字符串,进行词法分析(tokenization)、语法解析(parsing),然后查找 PATH 环境变量中的目录以定位可执行文件,最终通过
fork()和exec()系统调用来运行程序。 - 脚本解释器 :除了交互式操作,Shell 还能读取并逐行执行存储在文件中的命令序列,即所谓的“Shell 脚本”。这种批处理模式广泛应用于系统初始化、日志轮转、定时任务等场景。
- 环境管理 :Shell 负责维护当前会话的环境变量、工作目录、信号处理机制等状态信息,这些都会影响脚本的行为一致性。
- 管道与重定向支持 :Shell 提供强大的 I/O 控制能力,允许将多个命令通过管道连接,或将标准输入输出重定向至文件或其他设备,极大提升了命令组合的灵活性。
为了更清晰地展示 Shell 在系统中的位置,以下是一个典型的 Linux 命令执行流程的 Mermaid 流程图:
graph TD
A[用户输入命令] --> B{Shell解析命令}
B --> C[检查是否为内置命令]
C -->|是| D[直接执行内置命令]
C -->|否| E[搜索PATH路径]
E --> F{找到可执行文件?}
F -->|是| G[fork() 创建子进程]
G --> H[exec() 执行程序]
F -->|否| I[报错: command not found]
H --> J[程序运行完毕]
J --> K[返回退出状态码]
K --> L[Shell显示结果]
该流程图揭示了 Shell 如何协调内核资源完成一次命令调用。值得注意的是,某些命令如 cd 、 export 属于 Shell 内置命令(built-in),它们不能通过 exec() 单独运行,因为会影响当前 Shell 进程的状态(如更改工作目录)。这也是为什么必须由 Shell 自身直接执行的原因。
此外,Shell 还承担着进程调度的角色。每一个外部命令的执行都伴随着一次 fork() 调用,生成子进程去执行目标程序,而父进程(即 Shell)则等待其结束并回收资源。这种模型保证了主 Shell 会话不会因某个命令崩溃而终止。
2.1.2 Red Hat Linux 9.0默认Shell环境分析(Bash特性)
Red Hat Linux 9.0 默认采用 Bash 作为交互式 Shell 和脚本解释器。Bash 不仅继承了早期 sh 的简洁性,还引入了许多现代化特性,使其成为目前最主流的 Shell 环境之一。以下是 Bash 在 RHEL 9.0 中的一些关键特性和配置机制:
主要特性列表
| 特性 | 描述 |
|---|---|
| 命令历史(History) | 支持上下箭头浏览历史命令,可通过 history 命令查看 |
| Tab 补全 | 自动补全文件名、命令名、变量名等,提升输入效率 |
| 别名(Alias) | 允许用户自定义简短命令替代长命令,如 alias ll='ls -la' |
| 作业控制(Job Control) | 支持后台运行任务(&)、暂停(Ctrl+Z)、恢复(fg/bg) |
| 函数定义 | 支持在脚本中定义函数,便于模块化编程 |
| 条件表达式与循环 | 提供 [[]] 、 test 、 if 、 for 、 while 等结构 |
| 数组支持 | 支持一维数组,可用于数据集合操作 |
| 大量内置变量 | 如 $HOME , $PATH , $USER , $PS1 等 |
Bash 初始化文件加载顺序
Bash 在启动时会根据登录类型(login shell 或 non-login shell)加载不同的配置文件。了解这些文件的加载顺序对于排查环境问题至关重要。
flowchart LR
Start[Shell启动] --> Login{是否为登录Shell?}
Login -->|是| Load1[/etc/profile]
Load1 --> Load2[$HOME/.bash_profile]
Load2 --> Load3[$HOME/.bashrc]
Load3 --> Load4[/etc/bashrc]
Login -->|否| Load5[$HOME/.bashrc]
Load5 --> Load6[/etc/bashrc]
上述流程表明:
- 登录 Shell(如通过 SSH 登录)首先读取全局配置 /etc/profile ,然后依次读取用户级的 .bash_profile 和 .bashrc 。
- 非登录 Shell(如打开新终端窗口)通常只读取 .bashrc 。
这意味着,如果在 .bashrc 中设置了某个别名或环境变量,但在 .bash_profile 中未显式调用 . ~/.bashrc ,则登录时可能无法生效。这是一个常见的配置陷阱。
查看当前 Bash 版本与特性支持
可以通过以下命令查看当前系统的 Bash 版本:
$ bash --version
GNU bash, version 5.1.8(1)-release (x86_64-redhat-linux-gnu)
Copyright (C) 2020 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
Bash 5.1 引入了多项改进,包括更严格的语法检查、增强的正则表达式支持( =~ 操作符)、动态加载内置命令等功能。对于脚本开发者而言,应尽量避免使用过新的语法特性,以确保脚本在旧版本系统上的兼容性。
示例:利用 Bash 特性编写高效脚本片段
下面是一个利用 Bash 数组和循环特性的简单示例,用于批量创建测试目录:
#!/bin/bash
# 定义目录名称数组
dirs=("logs" "temp" "backup" "cache" "uploads")
# 循环创建每个目录
for dir in "${dirs[@]}"; do
if [[ ! -d "$dir" ]]; then
mkdir "$dir"
echo "Created directory: $dir"
else
echo "Directory $dir already exists."
fi
done
代码逻辑逐行解读:
-
#!/bin/bash:指定解释器为 Bash,确保脚本在不同环境下一致运行。 -
dirs=("logs" ...):声明一个数组变量dirs,包含五个目录名。Bash 数组使用括号语法定义。 -
for dir in "${dirs[@]}":遍历数组中所有元素。${dirs[@]}表示展开整个数组;引号防止路径含空格时报错。 -
[[ ! -d "$dir" ]]:使用双中括号进行条件判断,检查目录是否存在。-d是文件测试操作符。 -
mkdir "$dir":创建目录。变量加引号是为了防止路径名含特殊字符导致错误。 -
echo输出操作状态,便于调试。
此脚本展示了 Bash 在结构化编程方面的潜力——尽管不是通用编程语言,但已足够应对大多数系统管理任务。
综上所述,Shell 尤其是 Bash,不仅仅是命令行接口,更是一种轻量级的系统编程语言。理解其基本概念与工作机制,是编写高质量 Shell 脚本的前提。下一节将进一步探讨脚本的编写规范与执行方式,揭示不同调用方法背后的系统行为差异。
3. ZyRh9Bak.sh备份脚本设计与定时任务集成(tar/gzip/cron)
在现代IT运维体系中,数据的完整性与可恢复性是系统稳定运行的核心保障。Red Hat Linux 9.0作为企业级服务器操作系统的代表,广泛应用于数据库、Web服务和关键业务支撑平台。面对日益增长的数据量和高可用性要求,手动执行备份已无法满足实际需求。因此,构建一个自动化、可靠且具备容错能力的备份机制成为系统管理员必须掌握的核心技能之一。
本章围绕名为 ZyRh9Bak.sh 的定制化Shell脚本展开,深入剖析其从策略设计到脚本实现,再到通过 cron 定时调度的完整流程。该脚本以 tar 和 gzip 命令为核心工具,结合时间戳命名、日志记录、异常判断等机制,实现了对关键目录的安全归档,并通过系统级计划任务实现每日自动执行。整个过程不仅体现了Shell编程的实际工程价值,也展示了Linux环境下“工具链组合+自动化调度”这一经典运维范式的力量。
3.1 备份策略的理论基础
数据备份并非简单的文件复制,而是一种基于风险评估、恢复目标和资源约束的系统性工程决策。在企业环境中,一次失败的备份可能导致灾难性的后果,例如客户数据丢失、合规审计不通过或业务长时间中断。因此,在编写任何备份脚本之前,必须明确采用何种备份策略,以及该策略如何适应组织的数据生命周期管理需求。
3.1.1 完整备份、增量备份与差异备份的概念比较
三种主流备份模式各有优劣,适用于不同的场景:
| 备份类型 | 定义说明 | 存储开销 | 恢复速度 | 适用场景 |
|---|---|---|---|---|
| 完整备份 (Full Backup) | 每次都将所有选定数据完整复制一份 | 高(重复存储) | 快(仅需一个备份集) | 初始备份、小型系统 |
| 增量备份 (Incremental Backup) | 仅备份自上次任意类型备份以来发生变化的文件 | 低(节省空间) | 慢(需完整+所有增量链) | 数据频繁变更、带宽/存储受限环境 |
| 差异备份 (Differential Backup) | 备份自最近一次完整备份以来所有修改过的文件 | 中等(随时间增长) | 较快(只需完整+最后一个差异) | 中等规模系统、希望平衡效率与恢复复杂度 |
图示:三种备份方式的时间线对比
graph TD
A[周一: 完整备份] --> B[周二: 增量1 / 差异1]
B --> C[周三: 增量2 / 差异2]
C --> D[周四: 增量3 / 差异3]
subgraph "增量恢复路径"
E[恢复] --> A
E --> B
E --> C
E --> D
end
subgraph "差异恢复路径"
F[恢复] --> A
F --> D
end
从上图可见,增量备份虽然最省空间,但恢复路径最长;而差异备份折中处理了空间与恢复效率之间的矛盾。对于大多数中小型企业或部门级服务器而言, 每日完整备份 + 压缩归档 是一种简单高效的选择,尤其当源数据总量可控(如 <50GB),且夜间空闲时段允许较长IO操作时。
在 ZyRh9Bak.sh 脚本的设计中,选择了 每日完整备份 策略,原因如下:
- 实现逻辑简洁,易于调试和维护;
- 不依赖历史备份链,避免因某次失败导致后续全部失效;
- 结合时间戳命名可保留多份副本,支持按天追溯;
- 使用 gzip 压缩显著降低存储占用,缓解完整备份的空间压力。
此外,可通过后期扩展引入“保留N天”的清理机制,进一步优化磁盘利用率。
3.1.2 数据安全与恢复机制的设计原则
有效的备份不仅仅是“把文件打包”,更需要考虑以下几个核心设计原则:
(1) 不可变性原则
备份一旦生成,不应被后续写入操作覆盖或篡改。建议将备份输出路径设置为只读挂载点或使用ACL控制权限。例如:
chmod 750 /backup/
chown root:backup /backup/
setfacl -m u:backup_user:r-x /backup/
(2) 异地分离原则
遵循“3-2-1 备份规则”:至少3份数据副本,存于2种不同介质,其中1份位于异地。即使本地硬盘损坏,仍可从远程NAS或云存储恢复。
(3) 验证与测试机制
定期进行恢复演练,确保备份包未损坏。可在脚本末尾添加校验步骤:
tar -tzf /backup/data_$(date +%Y%m%d).tar.gz > /dev/null 2>&1
if [ $? -ne 0 ]; then
echo "ERROR: Backup archive is corrupted!" >&2
exit 1
fi
(4) 元信息记录
每次备份应附带元数据,包括:
- 开始/结束时间
- 源目录大小
- 压缩后体积
- MD5 校验码
- 执行用户与主机名
这些信息可用于后续审计和性能分析。
(5) 最小权限原则
运行备份脚本的账户应具备最小必要权限。例如,若仅需备份 /var/www/html 和 /etc/nginx ,则无需赋予 root 全局访问权,可通过 sudo 精细化授权特定命令。
综上所述,合理的备份策略不仅是技术问题,更是管理与流程问题。 ZyRh9Bak.sh 正是在上述理念指导下,融合了自动化、健壮性和可观测性的实践产物。
3.2 tar与gzip命令在脚本中的实践应用
在Linux系统中, tar (Tape Archive)与 gzip 是最经典的归档与压缩工具组合。它们虽诞生于上世纪80年代,但在今天的自动化运维中依然扮演着不可替代的角色。 tar 负责将多个文件合并为单一归档,保持原有目录结构和权限属性; gzip 则提供高效的无损压缩算法,大幅减少存储占用。两者结合使用,构成了绝大多数Shell备份脚本的技术基石。
3.2.1 使用tar打包关键目录并结合gzip压缩
假设我们要备份Web服务器的关键配置和内容目录: /etc/httpd , /var/www/html , /etc/ssl 。以下是典型的 tar + gzip 组合命令:
tar -czf /backup/web_backup.tar.gz /etc/httpd /var/www/html /etc/ssl
让我们逐参数解析这条命令的含义:
| 参数 | 含义说明 |
|---|---|
-c | 创建新的归档文件(create) |
-z | 调用 gzip 进行压缩(等价于 --gzip ) |
-f | 指定归档文件名(filename) |
-v | 显示详细处理过程(verbose,可选) |
-p | 保留原始权限(preserve permissions) |
--exclude | 排除指定路径(如缓存日志) |
为了提升实用性,通常会在脚本中封装成变量形式,增强可配置性:
#!/bin/bash
# 配置变量
BACKUP_DIR="/backup"
SOURCE_DIRS="/etc/httpd /var/www/html /etc/ssl"
EXCLUDE_PATTERNS="--exclude=/var/www/html/cache --exclude=/var/log"
# 执行压缩打包
tar -czpf "${BACKUP_DIR}/web_full_$(date +%Y%m%d_%H%M%S).tar.gz" \
${EXCLUDE_PATTERNS} \
${SOURCE_DIRS}
代码逻辑逐行解读:
- 第4~6行:定义关键路径与排除规则,便于集中管理。
- 第9行:
-c表示创建新归档;-z自动启用gzip压缩;-p保留文件权限(如644、755);-f后接动态生成的文件名。- 文件名中嵌入
$(date +%Y%m%d_%H%M%S)实现毫秒级唯一标识,防止冲突。\符号用于跨行书写,提高可读性。
值得注意的是, -z 参数本质上是调用外部 gzip 程序完成压缩。你也可以拆分为两步操作:
tar -cf - /etc/httpd | gzip > /backup/httpd_$(date +%Y%m%d).tar.gz
此处使用 - 表示标准输出/输入流,实现管道压缩。这种方式更适合大文件传输场景,避免中间临时文件占用磁盘。
性能对比实验(模拟数据)
| 方法 | 原始大小 | 压缩后 | 耗时 | CPU占用 |
|---|---|---|---|---|
tar czf | 1.2GB | 380MB | 42s | 65% |
tar cf - \| gzip | 1.2GB | 378MB | 45s | 70% |
tar cf - \| pigz (多线程) | 1.2GB | 382MB | 18s | 210% |
可见,在多核环境下使用 pigz (并行gzip)可显著提速,适合大型备份任务。
3.2.2 时间戳命名策略实现每日备份隔离
为了避免每次备份覆盖旧文件,必须采用唯一命名机制。常见方案包括:
-
%Y%m%d→ 按日分割(推荐) -
%Y%m%d_%H%M→ 精确到分钟 - 主机名+序列号 → 如
server01_bak001.tar.gz
以下是一个完整的命名规范实现示例:
#!/bin/bash
HOSTNAME=$(hostname -s)
TIMESTAMP=$(date +"%Y%m%d")
ARCHIVE_NAME="ZyRh9Bak_${HOSTNAME}_${TIMESTAMP}.tar.gz"
BACKUP_PATH="/backup/$ARCHIVE_NAME"
# 打包命令
tar -czpf "$BACKUP_PATH" /etc /var/www/html
该命名方式具备以下优势:
- 包含主机名,便于多节点统一归档;
- 日期格式清晰,支持自然排序;
- 前缀 ZyRh9Bak_ 可快速识别来源脚本。
为进一步实现自动清理过期备份,可加入保留策略:
# 删除7天前的备份
find /backup -name "ZyRh9Bak_*.tar.gz" -mtime +7 -exec rm {} \;
也可结合 logrotate 或独立清理脚本周期执行。
此外,为防止磁盘满导致备份失败,建议在执行前检查可用空间:
MIN_FREE_SPACE_GB=5
FREE_SPACE=$(df /backup --output=avail -B G | tail -1 | tr -d 'G')
if [ "$FREE_SPACE" -lt "$MIN_FREE_SPACE_GB" ]; then
echo "ERROR: Insufficient disk space ($FREE_SPACE GB < $MIN_FREE_SPACE_GB GB)" >&2
exit 1
fi
此段代码通过 df --output=avail 获取可用容量,并转换为纯数字进行比较,有效预防IO异常。
3.3 自动化调度:cron任务配置详解
尽管手动执行备份脚本可行,但真正的自动化运维依赖于可靠的调度机制。在Red Hat Linux 9.0中, cron 是最成熟稳定的定时任务管理系统,它基于预设的时间表达式周期性地触发命令执行,非常适合执行每日备份这类规律性任务。
3.3.1 crontab语法结构解析与常见时间表达式
crontab 文件由六列字段组成,格式如下:
* * * * * command_to_run
│ │ │ │ │
│ │ │ │ └─── 星期几 (0–6, 0=Sunday)
│ │ │ └──────── 月份 (1–12)
│ │ └───────────── 日 (1–31)
│ └────────────────── 小时 (0–23)
└─────────────────────── 分钟 (0–59)
常见时间表达式示例:
| 表达式 | 含义 |
|---|---|
0 2 * * * | 每天凌晨2点 |
0 */6 * * * | 每6小时一次(0,6,12,18) |
30 8 * * 1-5 | 工作日上午8:30 |
0 0 1 * * | 每月1日午夜 |
*/10 * * * * | 每10分钟 |
要为 ZyRh9Bak.sh 设置每日凌晨1:30自动运行,可添加如下条目:
30 1 * * * /usr/local/bin/ZyRh9Bak.sh >> /var/log/zyrh9bak.log 2>&1
其中:
- >> 追加标准输出至日志文件;
- 2>&1 将错误输出重定向至同一位置;
- 路径务必使用绝对路径,避免环境变量问题。
查看当前用户的 crontab :
crontab -l
编辑任务:
crontab -e
注意: 修改后无需重启服务,
cron守护进程会自动加载更新。
系统级 vs 用户级任务
| 类型 | 配置路径 | 权限模型 | 适用场景 |
|---|---|---|---|
| 用户级 | crontab -e | 当前用户权限 | 普通用户作业 |
| 系统级 | /etc/crontab 或 /etc/cron.d/ | 指定执行用户 | 系统维护脚本 |
系统级任务多用于全局监控、日志轮转等。
3.3.2 将ZyRh9Bak.sh注册为系统级定时任务
为了让备份脚本以 root 身份运行(因涉及敏感目录读取),推荐将其注册为系统级任务。步骤如下:
步骤一:确保脚本权限正确
chmod 755 /usr/local/bin/ZyRh9Bak.sh
chown root:root /usr/local/bin/ZyRh9Bak.sh
步骤二:创建 /etc/cron.d/zyrh9bak 文件
# /etc/cron.d/zyrh9bak
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=admin@company.com
# 每日凌晨1:30执行备份
30 1 * * * root /usr/local/bin/ZyRh9Bak.sh >> /var/log/zyrh9bak.log 2>&1
说明:
-MAILTO可在命令出错时发送邮件通知(需配置MTA如sendmail/postfix);
-PATH显式声明搜索路径,防止命令找不到;
- 最后一行指定执行用户为root,适用于/etc/cron.d/语法。
步骤三:验证cron服务状态
systemctl status crond
确保服务处于 active (running) 状态。若未启用:
systemctl enable --now crond
步骤四:模拟执行测试
首次部署前应手动运行脚本,确认无报错:
/usr/local/bin/ZyRh9Bak.sh
ls -lh /backup/ZyRh9Bak_*.tar.gz
成功生成归档文件后,再交由 cron 自动调度。
3.4 日志记录与异常监控
一个缺乏反馈机制的自动化脚本如同“黑箱”,无法判断是否真正成功执行。为此, ZyRh9Bak.sh 必须具备完善的日志记录和异常检测功能,以便及时发现故障并采取补救措施。
3.4.1 在脚本中添加日志输出功能以追踪执行状态
推荐在脚本中定义统一的日志函数,实现结构化输出:
LOG_FILE="/var/log/zyrh9bak.log"
log() {
local level=$1
local message=$2
echo "[$(date '+%Y-%m-%d %H:%M:%S')] [$level] $message" | tee -a "$LOG_FILE"
}
# 示例调用
log "INFO" "Starting backup process..."
tar -czpf "$BACKUP_PATH" $SOURCE_DIRS
if [ $? -eq 0 ]; then
log "SUCCESS" "Backup completed: $BACKUP_PATH"
else
log "ERROR" "Backup failed with exit code $?"
fi
逻辑分析:
-tee -a实现屏幕输出与文件追加双写;
- 日志包含时间戳、级别、消息体,符合Syslog风格;
- 成功/失败分别标记,便于grep过滤。
还可按日期切分日志,避免单个文件过大:
LOG_FILE="/var/log/zyrh9bak/$(date +%Y%m).log"
mkdir -p "$(dirname "$LOG_FILE")"
3.4.2 判断备份成功与否并发送通知(模拟邮件或写入日志文件)
除了本地日志,还应支持主动告警。以下是一个基于 mailx 的邮件通知实现:
notify_admin() {
local subject=$1
local body=$2
echo "$body" | mail -s "$subject" admin@company.com
}
# 在脚本结尾处检测结果
if [ $? -eq 0 ]; then
notify_admin "✅ Backup Success" "Host: $(hostname)\nFile: $BACKUP_PATH\nSize: $(du -h "$BACKUP_PATH" | cut -f1)"
else
notify_admin "🚨 Backup Failed" "Host: $(hostname)\nError occurred during backup at $(date)"
fi
前提条件:
- 安装mailx:dnf install -y mailx
- 配置SMTP relay(如使用ssmtp或msmtp)
若无法发送邮件,退而求其次写入紧急日志:
echo "[ALERT] Backup failed on $(date)" >> /var/log/alert.log
此外,可结合 rsyslog 将关键事件转发至集中式日志服务器,实现跨主机监控。
最终,完整的 ZyRh9Bak.sh 脚本骨架如下:
#!/bin/bash
# ZyRh9Bak.sh - Automated Backup Script for RHEL 9
BACKUP_ROOT="/backup"
SOURCE_DIRS="/etc /var/www/html"
TIMESTAMP=$(date +%Y%m%d)
HOSTNAME=$(hostname -s)
ARCHIVE="${BACKUP_ROOT}/ZyRh9Bak_${HOSTNAME}_${TIMESTAMP}.tar.gz"
LOG_FILE="/var/log/zyrh9bak.log"
log() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] [$1] $2" | tee -a "$LOG_FILE"
}
log "INFO" "Starting backup..."
tar -czpf "$ARCHIVE" $SOURCE_DIRS
EXIT_CODE=$?
if [ $EXIT_CODE -eq 0 ]; then
log "SUCCESS" "Backup saved to $ARCHIVE"
echo "Subject: ✅ Success" | sendmail admin@company.com
else
log "ERROR" "Backup failed with code $EXIT_CODE"
echo "Subject: 🚨 Failure" | sendmail admin@company.com
fi
至此, ZyRh9Bak.sh 已成为一个具备完整生命周期管理能力的企业级备份解决方案。
4. ShowInfo.sh系统信息采集脚本实现(/proc文件系统、df、ifconfig)
在现代Linux运维实践中,系统状态的实时感知能力是保障服务稳定运行的核心基础。随着Red Hat Enterprise Linux 9.0的广泛应用,其内核提供的强大接口与工具链为自动化监控提供了坚实支撑。 ShowInfo.sh 作为一个典型的系统信息采集脚本,能够整合底层资源数据并以结构化方式输出关键指标,涵盖CPU、内存、磁盘、网络等维度。该脚本不仅可用于日常巡检,还可作为后续构建监控平台的数据源模块。其实现依赖于对 /proc 虚拟文件系统的深入理解,以及对 df 、 ifconfig 等标准命令的程序化调用和解析。更重要的是,它展示了如何将分散的系统命令输出转化为统一、可读性强且具备判断逻辑的信息报告。
通过合理设计变量提取机制、格式化输出规则及错误处理流程, ShowInfo.sh 实现了从原始数据到业务价值信息的转换过程。这一过程体现了Shell脚本作为轻量级自动化工具的强大表达力,尤其适用于边缘节点或容器环境中无需引入复杂框架即可完成基础监控需求的场景。此外,结合定时任务或远程执行机制,此类脚本还能形成分布式的轻量级探针体系,服务于集中式日志分析或安全审计系统。
4.1 Linux系统信息获取机制
Linux操作系统以其高度透明的资源管理机制著称,其中最核心的设计之一便是 /proc 文件系统。不同于传统存储设备上的文件系统, /proc 是一个虚拟的、内存驻留的文件系统,由内核动态生成,用于暴露运行时系统状态和进程信息。这种设计使得用户空间程序无需直接访问内核内存或使用特殊系统调用,即可读取大量关键性能指标。对于像 ShowInfo.sh 这样的信息采集脚本而言, /proc 提供了稳定、低开销的数据来源,极大简化了系统级监控的开发难度。
除了 /proc ,Linux还提供了多个标准化命令行工具如 df 、 free 、 ifconfig 或现代替代品 ip 和 ss ,这些工具本身也是基于 /proc 或 /sys 的数据进行封装展示。因此,在编写系统信息脚本时,开发者既可以手动解析 /proc 中的文本内容,也可以调用高级命令并通过文本处理技术提取所需字段。两种方法各有优势:直接读取 /proc 更加高效且避免外部命令依赖;而使用标准命令则更具兼容性,尤其在不同发行版间迁移时更为稳健。
为了实现精准的信息采集,必须掌握各类数据节点的语义含义及其更新机制。例如, /proc/meminfo 中的 MemTotal 和 MemAvailable 反映的是物理内存总量与当前可用量,但它们的单位为KB,需在脚本中做单位换算;而 /proc/loadavg 则提供了一分钟、五分钟、十五分钟的平均负载值,可用于评估系统繁忙程度。正确识别这些数值的意义,并结合上下文进行阈值判断,是构建智能监控逻辑的前提。
4.1.1 /proc虚拟文件系统的作用与常用节点说明(如/proc/meminfo、/proc/cpuinfo)
/proc 文件系统自1990年代初被引入Linux内核以来,已成为系统调试与性能分析不可或缺的组成部分。它以“伪文件”的形式呈现内核内部状态,所有读操作都会触发内核实时生成对应内容,写操作(部分节点支持)则可用于修改运行参数。这种即查即得的特性使其成为Shell脚本获取系统信息的理想通道。
以下是一些关键 /proc 节点的功能说明:
| 节点路径 | 描述 | 示例用途 |
|---|---|---|
/proc/cpuinfo | 包含每个逻辑CPU的核心信息,如型号、频率、缓存大小 | 获取CPU架构与核心数 |
/proc/meminfo | 提供详细的内存统计信息,包括总内存、空闲内存、缓冲区等 | 计算内存使用率 |
/proc/loadavg | 显示系统平均负载(1min, 5min, 15min)及当前运行队列长度 | 监控系统压力水平 |
/proc/uptime | 记录系统已运行时间(秒),两个数值分别为总运行时间和空闲时间 | 计算系统在线时长 |
/proc/net/dev | 列出所有网络接口的收发字节数、包数等统计信息 | 分析网络流量趋势 |
以 /proc/cpuinfo 为例,其部分内容如下:
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 142
model name : Intel(R) Core(TM) i7-8550U CPU @ 1.80GHz
cpu MHz : 1992.000
cache size : 8192 KB
通过 grep "model name" /proc/cpuinfo | head -1 即可提取CPU型号。类似地, /proc/meminfo 输出如下:
MemTotal: 8009484 kB
MemFree: 2345678 kB
MemAvailable: 5678901 kB
Buffers: 123456 kB
Cached: 456789 kB
这里 MemAvailable 比 MemFree 更准确反映可分配给新进程的内存,因其考虑了可回收缓存。
使用流程图展示信息采集路径
graph TD
A[启动 ShowInfo.sh] --> B{选择数据源}
B --> C[/proc/cpuinfo]
B --> D[/proc/meminfo]
B --> E[df 命令]
B --> F[ifconfig 或 ip 命令]
C --> G[提取 CPU 型号与核心数]
D --> H[计算内存使用率]
E --> I[获取磁盘占用百分比]
F --> J[提取 IP 地址与接口状态]
G --> K[汇总信息]
H --> K
I --> K
J --> K
K --> L[格式化输出至终端或文件]
该流程清晰表达了脚本如何并行采集多维度数据,最终聚合为统一报告。
4.1.2 系统资源数据的可读性与程序化提取方法
尽管 /proc 文件提供了丰富的原始数据,但其文本格式并不总是便于脚本解析。例如, /proc/meminfo 的每一行都以标签后跟冒号和空格开始,接着是数值与单位(如kB)。要从中提取特定字段,通常需要借助正则表达式或字段分割技术。
以下是一个从 /proc/meminfo 提取 MemTotal 和 MemFree 的示例代码段:
#!/bin/bash
get_memory_info() {
local mem_total=$(grep 'MemTotal' /proc/meminfo | awk '{print $2}')
local mem_free=$(grep 'MemFree' /proc/meminfo | awk '{print $2}')
local mem_available=$(grep 'MemAvailable' /proc/meminfo | awk '{print $2}')
# 单位为 KB,转换为 MB
local total_mb=$((mem_total / 1024))
local free_mb=$((mem_free / 1024))
local available_mb=$((mem_available / 1024))
local usage_kb=$((mem_total - mem_free))
local usage_percent=$((usage_kb * 100 / mem_total))
echo "内存总量: ${total_mb} MB"
echo "已用内存: ${usage_percent}%"
echo "可用内存: ${available_mb} MB"
}
get_memory_info
逐行逻辑分析:
-
local mem_total=$(grep 'MemTotal' /proc/meminfo | awk '{print $2}')
使用grep定位包含MemTotal的行,管道传递给awk提取第二个字段(即数值部分)。由于每行格式为Key: Value Unit,$2对应数字。 -
local mem_free=$(...)和local mem_available=$(...)
同理提取空闲和可用内存值。 -
local total_mb=$((mem_total / 1024))
Bash中的$((...))表示整数算术运算。此处将KB转为MB,便于阅读。 -
local usage_kb=$((mem_total - mem_free))
计算实际使用的内存(不推荐使用used = total - free,因未计入缓存,更佳做法应使用used = total - available)。 -
local usage_percent=$((usage_kb * 100 / mem_total))
百分比计算。注意Bash不支持浮点运算,若需小数精度,可调用bc工具:
bash usage_percent=$(echo "scale=2; ($usage_kb * 100) / $mem_total" | bc)
此代码片段展示了如何将非结构化的文本输入转化为结构化输出。进一步优化可封装为函数,并加入错误检查,如验证文件是否存在或数值是否有效。
此外,对于 /proc/loadavg 的解析也常用于判断系统负载是否异常:
read load1 load5 load15 _ < /proc/loadavg
echo "当前负载: ${load1}, ${load5}, ${load15}"
利用Shell的 read 内建命令,可以轻松按空白符拆分前三个字段,忽略第四个(正在运行的进程数)和第五个(最近创建的PID)。
综上所述,通过对 /proc 文件系统的精细化解析, ShowInfo.sh 能够以极低的资源消耗获取高精度系统信息,为后续的决策逻辑提供可靠依据。
4.2 关键命令在脚本中的整合使用
在实际部署环境中,完全依赖 /proc 文件可能面临可移植性问题,尤其是在某些精简系统或容器中, /proc 某些节点可能受限或缺失。为此,结合标准命令工具是一种更稳健的做法。 df 和 ifconfig (或其现代替代 ip )是系统管理员最常用的资源查看命令,分别用于磁盘空间管理和网络配置查询。将它们集成进 ShowInfo.sh 不仅能增强脚本的实用性,还能提升输出的一致性和可读性。
这类命令的优势在于输出格式相对规范,易于通过 grep 、 awk 、 sed 等文本处理工具提取目标字段。同时,它们通常已被广泛测试,行为稳定,适合作为生产环境脚本的基础组件。然而,也需要注意版本差异带来的影响,例如旧版 ifconfig 在RHEL 9中默认不再安装,需改用 ip addr 替代。
4.2.1 df命令用于磁盘空间监控及阈值判断逻辑
df (disk free)命令用于显示文件系统的磁盘使用情况,默认输出包括设备名、总容量、已用空间、可用空间及挂载点。其 -h 参数启用人类可读格式(如GB、MB),极大提升了可读性。但在脚本中自动解析时,建议使用 -P (POSIX格式)确保列对齐一致,避免因设备名长度变化导致字段错位。
示例输出:
Filesystem 1024-blocks Used Available Capacity Mounted on
devtmpfs 4004740 0 4004740 0% /dev
tmpfs 4014944 120 4014824 0% /dev/shm
/dev/sda1 20964760 8923456 12041304 43% /
目标是从中提取根分区 / 的使用率并判断是否超过预设阈值(如80%),以便触发告警。
以下为实现该功能的代码块:
#!/bin/bash
check_disk_usage() {
local threshold=${1:-80} # 默认阈值80%
local warning_count=0
# 使用 POSIX 格式确保列对齐
df -P | tail -n +2 | while read fs blocks used avail percent mount; do
# 移除百分号并提取纯数字
local usage=${percent%\%}
if [[ "$mount" == "/" ]] && (( usage > threshold )); then
echo "⚠️ 警告:根分区 '$mount' 使用率达到 ${usage}%,超过阈值 ${threshold}%!" >&2
((warning_count++))
fi
done
# 注意:while循环在管道中运行时为子shell,无法修改父shell变量
# 因此上述 warning_count 在循环外无效,需改用其他方式收集结果
}
# 改进版本:使用数组保存结果
check_disk_usage_safe() {
local threshold=${1:-80}
local warnings=()
while IFS=$'\t ' read -r fs blocks used avail percent mount; do
[[ "$fs" == Filesystem ]] && continue # 跳过标题行
[[ -z "$mount" ]] && continue # 忽略空行
local usage=${percent%\%}
if [[ "$mount" == "/" ]] && (( usage > threshold )); then
warnings+=("根分区使用率: ${usage}%")
fi
done < <(df -P)
if [[ ${#warnings[@]} -gt 0 ]]; then
printf '⚠️ 发现 %d 个磁盘警告:\n' "${#warnings[@]}"
for w in "${warnings[@]}"; do
printf ' ➤ %s\n' "$w"
done
else
echo "✅ 所有磁盘使用正常。"
fi
}
check_disk_usage_safe 80
参数说明与逻辑分析:
-
local threshold=${1:-80}:设置默认参数,若未传入则使用80%。 -
df -P:强制使用POSIX格式输出,保证列宽固定。 -
while read ... < <(df -P):使用进程替换< <(...)避免管道产生子shell,确保变量可在循环外访问。 -
IFS=$'\t ':设置字段分隔符为空格和制表符,适应不同格式。 -
${percent%\%}:使用参数扩展去除字符串末尾的%符号。 -
(( usage > threshold )):整数比较语法,适用于数值判断。
此方案解决了原生管道中变量作用域的问题,确保告警计数准确。此外,还可将结果写入日志文件或发送邮件,实现真正的告警闭环。
4.2.2 ifconfig(或替代工具)提取网络接口配置信息
传统上, ifconfig 是查看和配置网络接口的主要工具。但在Red Hat Linux 9.0中, net-tools 包(含 ifconfig )已非默认安装,推荐使用 iproute2 套件中的 ip addr 命令替代。
对比两者输出:
ifconfig(已弃用)
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.1.100 netmask 255.255.255.0 broadcast 192.168.1.255
ip addr(推荐)
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
inet 192.168.1.100/24 brd 192.168.1.255 scope global dynamic eth0
尽管格式不同,但均可通过正则提取IP地址。以下是兼容两种方式的脚本片段:
get_ip_address() {
local interface=${1:-eth0}
local ip_addr=""
# 方法1:尝试使用 ip 命令
if command -v ip &> /dev/null; then
ip_addr=$(ip -4 addr show "$interface" | grep -oP '(?<=inet\s)\d+(\.\d+){3}' | head -1)
# 方法2:回退到 ifconfig
elif command -v ifconfig &> /dev/null; then
ip_addr=$(ifconfig "$interface" | grep -oE 'inet ([0-9]{1,3}\.){3}[0-9]{1,3}' | awk '{print $2}' | head -1)
else
echo "❌ 错误:系统缺少 ip 或 ifconfig 工具!" >&2
return 1
fi
if [[ -n "$ip_addr" ]]; then
echo "接口 $interface 的 IPv4 地址: $ip_addr"
else
echo "❌ 未能获取接口 $interface 的IP地址。" >&2
fi
}
get_ip_address "ens192"
逻辑解读:
-
command -v ip &> /dev/null:检测命令是否存在,静默执行。 -
ip -4 addr show "$interface":仅显示IPv4地址。 -
grep -oP '(?<=inet\s)\d+(\.\d+){3}':使用Perl正则向前查找匹配inet后的IP地址。 -
awk '{print $2}':在ifconfig输出中,inet后第二项为IP(某些版本第一项为addr:)。
此设计体现了良好的容错性与向后兼容能力,适合在异构环境中部署。
4.3 结构化信息输出设计
高质量的系统信息脚本不仅要“能干活”,更要“会说话”。这意味着输出结果应当清晰、规范、易于理解和进一步处理。 ShowInfo.sh 的价值不仅体现在本地查看,更在于其输出可被日志系统收集、数据库导入或通过API传输至监控平台。因此,结构化输出设计至关重要。
常见的输出形式包括纯文本报告、CSV表格、JSON对象等。在Shell脚本中,虽然原生不支持复杂数据结构,但通过精心排版和字段对齐,仍可实现接近专业仪表板的效果。此外,将输出重定向至文件或配合 logger 命令送入系统日志,也是实现审计追踪的关键步骤。
4.3.1 格式化输出主机名、IP地址、内存使用率等核心指标
以下是一个完整的 ShowInfo.sh 示例脚本,整合前述知识点,输出统一格式的系统摘要:
#!/bin/bash
generate_system_report() {
local hostname=$(hostname)
local ip_addr=$(ip -4 addr show up primary | grep -oP '(?<=inet\s)\d+(\.\d+){3}' | head -1)
local cpu_model=$(grep 'model name' /proc/cpuinfo | head -1 | cut -d: -f2 | xargs)
local cores=$(nproc)
local disk_usage=$(df -h / | tail -1 | awk '{print $5}')
local mem_total=$(grep MemTotal /proc/meminfo | awk '{print $2/1024/1024 " GB"}')
local load_avg=$(cut -d' ' -f1-3 /proc/loadavg)
cat << EOF
🖥️ 系统状态报告
📅 报告时间: $(date '+%Y-%m-%d %H:%M:%S')
🖥️ 主机名: $hostname
🌐 IP地址: ${ip_addr:-N/A}
🔧 CPU型号: $cpu_model
🧮 核心数量: $cores
💾 根分区使用率: $disk_usage
🧠 内存总量: $mem_total
📊 系统负载: $load_avg
EOF
}
generate_system_report
该脚本使用 heredoc 实现多行格式化输出,结合Unicode图标增强可读性。各变量均来自前文介绍的方法,确保准确性。
4.3.2 输出结果保存为文本报告供后续审计或传输
为进一步提升实用性,可将输出保存为带时间戳的文件,并压缩归档:
save_report_to_file() {
local timestamp=$(date '+%Y%m%d_%H%M%S')
local report_dir="/var/log/system_reports"
local report_file="$report_dir/report_$timestamp.txt"
mkdir -p "$report_dir"
generate_system_report > "$report_file"
gzip "$report_file"
echo "📝 报告已生成并压缩至:${report_file}.gz"
}
save_report_to_file
该机制支持定期归档,便于后期追溯历史状态变化。
4.4 实时监控扩展思路
ShowInfo.sh 可进一步演变为持续运行的监控代理。通过添加 sleep 循环和条件判断,即可实现每隔若干秒采集一次数据,形成简易但有效的实时监控工具。
4.4.1 循环采集+延迟实现简易监控功能
realtime_monitor() {
local interval=${1:-5} # 默认5秒
clear
while true; do
printf "\033[H\033[J" # ANSI清屏
generate_system_report
sleep "$interval"
done
}
# realtime_monitor 3
使用ANSI转义码 \033[H\033[J 实现终端清屏,避免信息滚动混乱。
4.4.2 结合邮件或日志服务实现告警机制雏形
最后,可通过 mailx 或 logger 将异常事件上报:
send_alert_email() {
local subject="【紧急】系统资源超限"
local body="请立即检查服务器 $(hostname),磁盘或内存使用过高。"
echo "$body" | mail -s "$subject" admin@example.com
}
配合前面的阈值判断,即可构成完整告警链路。
5. LinuxArp.sh ARP缓存管理脚本应用(arp命令操作与网络诊断)
在现代 Linux 网络运维中,地址解析协议(ARP)作为连接 IP 层与数据链路层的核心机制之一,承担着将 IPv4 地址映射为物理 MAC 地址的关键任务。然而,在复杂网络环境中,ARP 缓存的异常、老化或污染可能导致通信中断、延迟升高甚至安全风险。针对这一问题,设计一个可自动化管理 ARP 表项的 Shell 脚本 —— LinuxArp.sh ,不仅能够提升网络诊断效率,还能增强系统管理员对底层网络状态的掌控能力。
Red Hat Enterprise Linux 9.0 提供了完整的 arp 工具集(属于 net-tools 包),并兼容现代替代方案如 ip neigh 命令。通过结合 Shell 脚本编程能力,可以实现对 ARP 缓存的查询、清理、静态绑定及异常检测等高级功能。本章节深入剖析 LinuxArp.sh 的设计逻辑与实现细节,涵盖从基础命令调用到网络故障模拟响应的全流程控制,并展示如何将其集成进日常网络维护体系中。
5.1 ARP协议原理与Linux内核实现机制
ARP 协议是 TCP/IP 模型中不可或缺的一环,其核心作用在于解决局域网内“IP 到 MAC”的地址转换问题。当主机需要向同一子网内的目标设备发送数据包时,必须首先确定对方的硬件地址。若本地 ARP 缓存中无对应条目,则触发 ARP 请求广播;收到响应后,建立缓存记录,供后续通信使用。
5.1.1 ARP工作机制详解
ARP 的工作流程遵循请求-应答模式:
- ARP 请求 :源主机广播包含目标 IP 地址的 ARP 查询报文。
- ARP 应答 :拥有该 IP 的主机单播返回自己的 MAC 地址。
- 缓存更新 :双方更新本地 ARP 表,有效期通常为几分钟至十几分钟(依内核配置而定)。
Linux 内核通过邻接子系统(Neighbor Subsystem)管理所有二层邻居信息,包括 ARP 条目。这些信息存储于内核内存中,并可通过 /proc/net/arp 文件和 arp 或 ip neigh 命令查看。
以下是典型的 ARP 表结构示例:
IP address HW type Flags HW address Mask Device
192.168.1.1 0x1 0x2 aa:bb:cc:dd:ee:ff * eth0
192.168.1.100 0x1 0x0 00:11:22:33:44:55 * eth0
其中:
- HW type :硬件类型(1 表示以太网)
- Flags :标志位(0x2 表示可达,0x0 可能表示未确认)
- HW address :MAC 地址
- Device :关联网络接口
这种表结构反映了动态学习过程的结果,但也可能成为攻击面 —— 如 ARP 欺骗(ARP Spoofing)即利用伪造应答篡改缓存。
5.1.2 Linux中ARP缓存的生命周期管理
Linux 内核使用多个参数控制 ARP 条目的生存周期与行为策略,这些参数位于 /proc/sys/net/ipv4/neigh/<interface>/ 目录下。关键参数如下表所示:
| 参数名称 | 默认值(典型) | 说明 |
|---|---|---|
base_reachable_time_ms | ~30,000 ms | 邻居可达时间基数(随机波动) |
gc_stale_time | 60 秒 | 标记为“陈旧”前等待确认的时间 |
delay_first_probe_time | 5 秒 | 首次探测延迟(用于验证存活) |
ucast_solicit | 3 | 发送单播探测的最大次数 |
mcast_solicit | 3 | 广播请求重试次数 |
这些参数共同决定了 ARP 条目何时被标记为不可达、何时发起探测以及何时彻底删除。
例如,当某条目长时间未通信时,系统会尝试发送单播探测(基于 ucast_solicit )。若连续失败,则进入“stale”状态,下次访问前需重新解析。
使用 sysctl 查看和调整 ARP 参数
# 查看 eth0 接口的 gc_stale_time
sysctl net.ipv4.neigh.eth0.gc_stale_time
# 修改为 30 秒
sysctl -w net.ipv4.neigh.eth0.gc_stale_time=30
逻辑分析 :
上述命令通过sysctl接口读写内核运行时参数。-w表示写入新值,但该更改仅在当前会话有效。若需持久化,应写入/etc/sysctl.conf或/etc/sysctl.d/下的配置文件。
此机制允许管理员根据网络稳定性需求微调 ARP 行为,尤其适用于高延迟或不稳定链路环境。
5.1.3 ARP与网络安全的关系
尽管 ARP 是无状态协议且缺乏认证机制,但它极易受到中间人攻击(MITM)。攻击者可伪造 ARP 回应,使流量误导向恶意节点。
常见防御手段包括:
- 启用交换机端口安全(Port Security)
- 配置静态 ARP 绑定
- 使用 ARP 监测工具定期校验表项一致性
为此, LinuxArp.sh 将提供自动比对功能,识别异常 MAC/IP 映射变化,辅助早期威胁发现。
graph TD
A[主机发送数据] --> B{ARP 缓存中有条目?}
B -->|是| C[直接封装帧发送]
B -->|否| D[广播 ARP 请求]
D --> E[目标主机回应 ARP 应答]
E --> F[更新本地 ARP 表]
F --> C
C --> G[完成数据传输]
style A fill:#f9f,stroke:#333
style G fill:#cfc,stroke:#333
流程图说明 :
该 Mermaid 图清晰展示了标准 ARP 解析流程。它强调了缓存命中与否对性能的影响 —— 缓存缺失会导致额外广播开销,影响网络效率。因此,合理维护 ARP 缓存对于保障通信质量至关重要。
5.2 arp命令语法解析与脚本化操作实践
Red Hat Linux 9.0 中默认安装 net-tools 包以支持 arp 命令。虽然官方推荐逐步迁移到 ip neigh (来自 iproute2),但 arp 仍广泛用于脚本兼容性场景。
5.2.1 arp命令基本语法与常用选项
arp 命令的基本格式如下:
arp [选项] [操作] [参数]
主要操作类型包括:
| 操作 | 功能描述 |
|---|---|
-a 或 --all | 显示所有接口的 ARP 表项 |
-d <host> | 删除指定主机的 ARP 条目 |
-s <host> <hw_addr> | 添加静态 ARP 条目 |
-v | 显示详细信息(verbose) |
-n | 以数字形式显示 IP 和 MAC(避免反向 DNS 查询) |
示例:查看当前 ARP 表
arp -an
输出示例:
? (192.168.1.1) at aa:bb:cc:dd:ee:ff [ether] on eth0
? (192.168.1.100) at 00:11:22:33:44:55 [ether] on eth0
-n参数避免 DNS 解析,提升执行速度,适合脚本环境。
5.2.2 在脚本中安全地操作ARP表
以下是一个封装 arp 操作的函数模板,用于 LinuxArp.sh 脚本中:
# 函数:添加静态 ARP 条目
add_static_arp() {
local ip=$1
local mac=$2
local interface=$3
if [[ -z "$ip" || -z "$mac" ]]; then
echo "错误:IP 或 MAC 地址为空"
return 1
fi
# 执行添加操作
if arp -s "$ip" "$mac" ${interface:+-i $interface}; then
echo "成功添加静态 ARP 条目: $ip -> $mac (${interface:-default})"
return 0
else
echo "失败:无法添加 ARP 条目 $ip -> $mac"
return 1
fi
}
# 函数:删除指定 IP 的 ARP 条目
delete_arp_entry() {
local ip=$1
if arp -d "$ip"; then
echo "已删除 ARP 条目: $ip"
return 0
else
echo "删除失败或条目不存在: $ip"
return 1
fi
}
代码逐行解读 :
local ip=$1:声明局部变量并接收第一个参数。[[ -z "$ip" || -z "$mac" ]]:检查输入是否为空,防止无效操作。${interface:+-i $interface}:参数扩展语法,仅当$interface非空时追加-i <iface>。arp -s "$ip" "$mac":执行静态绑定。if ...; then:判断命令退出码,决定输出结果。参数说明 :
-$ip:目标 IPv4 地址(如 192.168.1.1)
-$mac:目标 MAC 地址(格式:aa:bb:cc:dd:ee:ff)
-$interface:可选,指定网络接口(如 eth0)
此类函数可在脚本中复用,确保操作安全性与一致性。
5.2.3 使用 ip neigh 替代方案提升兼容性
随着 net-tools 被标记为“传统”,建议同时支持 ip neigh 实现相同功能。
| 功能 | arp 命令 | ip neigh 命令 |
|---|---|---|
| 查看表项 | arp -n | ip neigh show |
| 添加静态条目 | arp -s 192.168.1.1 aa:bb:cc:dd:ee:ff | ip neigh add 192.168.1.1 lladdr aa:bb:cc:dd:ee:ff dev eth0 nud permanent |
| 删除条目 | arp -d 192.168.1.1 | ip neigh del 192.168.1.1 dev eth0 |
改进版函数(兼容双命令)
safe_add_arp() {
local ip=$1 mac=$2 iface=${3:-eth0}
if command -v ip &> /dev/null; then
ip neigh add "$ip" lladdr "$mac" dev "$iface" nud permanent && \
echo "✅ 使用 'ip' 添加静态 ARP: $ip -> $mac"
elif command -v arp &> /dev/null; then
arp -s "$ip" "$mac" -i "$iface" && \
echo "✅ 使用 'arp' 添加静态 ARP: $ip -> $mac"
else
echo "❌ 错误:未找到可用的 ARP 工具"
return 1
fi
}
逻辑分析 :
-command -v ip:检测ip命令是否存在。
-nud permanent:设置 NUD(Neighbor Unreachability Detection)状态为永久,防止自动清除。
- 函数优先使用现代工具,降级兼容旧系统。
此设计增强了脚本的跨平台适应能力,特别适用于混合环境运维。
5.3 LinuxArp.sh脚本功能模块设计与实现
LinuxArp.sh 是一个集查询、清理、绑定与监控于一体的综合性 ARP 管理脚本。其核心功能模块包括:
- 模块一:实时 ARP 表快照采集
- 模块二:静态条目批量导入
- 模块三:异常条目自动清理
- 模块四:变更日志与告警输出
5.3.1 脚本整体架构设计
采用模块化结构,主流程如下:
#!/bin/bash
SCRIPT_NAME=$(basename "$0")
LOG_FILE="/var/log/${SCRIPT_NAME%.sh}.log"
usage() {
cat << EOF
用法: $SCRIPT_NAME [选项]
选项:
-l 列出当前 ARP 表
-c <ip> 清除指定 IP 的缓存
-b <ip,mac,if> 绑定静态 ARP 条目
-m 检测可疑变动(需先保存基准)
-h 显示帮助
EOF
}
# 日志记录函数
log_event() {
echo "[$(date '+%Y-%m-%d %H:%M:%S')] $*" >> "$LOG_FILE"
}
参数说明 :
-SCRIPT_NAME:获取脚本名,便于日志追踪。
-LOG_FILE:定义集中日志路径。
-usage():打印帮助信息,提升用户体验。
5.3.2 实现ARP表差异检测功能
为了实现网络异常预警,脚本需具备“基线对比”能力。首次运行时保存快照,后续比对变化。
# 保存当前 ARP 快照
save_arp_snapshot() {
arp -an | sort > "/tmp/arp_snapshot_$(date +%Y%m%d).txt"
log_event "已保存 ARP 快照"
}
# 检测与上次快照的差异
detect_arp_change() {
local latest="/tmp/arp_latest.txt"
local previous=$(ls /tmp/arp_snapshot_* 2>/dev/null | tail -1)
arp -an | sort > "$latest"
if [[ ! -f "$previous" ]]; then
log_event "⚠️ 未找到历史快照,本次作为基准"
cp "$latest" "$previous"
return 0
fi
local diff_count=$(diff "$previous" "$latest" | grep '^[<>]' | wc -l)
if (( diff_count > 0 )); then
diff "$previous" "$latest" >> "$LOG_FILE"
log_event "🚨 检测到 ARP 表变更 ($diff_count 处)"
# 可在此触发邮件通知
else
log_event "🟢 ARP 表稳定,无变更"
fi
# 更新最新快照
cp "$latest" "$previous"
}
逻辑分析 :
- 使用sort确保比较顺序一致。
-diff输出中>表示新增,<表示删除。
- 若差异数大于零,则判定为潜在风险事件。
该机制可用于构建轻量级入侵检测系统(IDS)前端。
5.3.3 完整脚本示例(节选核心部分)
while getopts "lc:b:mh" opt; do
case $opt in
l)
arp -an
;;
c)
delete_arp_entry "$OPTARG"
;;
b)
IFS=',' read -r ip mac iface <<< "$OPTARG"
safe_add_arp "$ip" "$mac" "$iface"
;;
m)
detect_arp_change
;;
h)
usage
exit 0
;;
*)
usage >&2
exit 1
;;
esac
done
功能说明 :
--b参数接受逗号分隔的ip,mac,interface字符串。
- 使用IFS=','配合read实现字段拆分。
- 支持灵活调用不同功能模块。
| 功能 | 命令示例 | 说明 |
|---|---|---|
| 查看 ARP 表 | ./LinuxArp.sh -l | 输出当前所有条目 |
| 删除条目 | ./LinuxArp.sh -c 192.168.1.1 | 清除特定缓存 |
| 绑定静态 | ./LinuxArp.sh -b 192.168.1.1,aa:bb:cc:dd:ee:ff,eth0 | 建立永久映射 |
| 检测变动 | ./LinuxArp.sh -m | 对比历史快照 |
此表格总结了脚本的主要交互方式,便于快速查阅。
5.4 网络诊断场景下的实际应用与优化建议
在真实生产环境中, LinuxArp.sh 不仅是管理工具,更是排障利器。以下列举几个典型应用场景及其优化策略。
5.4.1 故障排查:ARP缓存污染导致通信中断
现象 :某服务器无法访问网关(192.168.1.1),但物理连接正常。
诊断步骤 :
# 1. 检查 ARP 表
arp -n | grep 192.168.1.1
# 输出:
# ? (192.168.1.1) at xx:xx:xx:xx:xx:xx [ether] on eth0
发现 MAC 地址与预期不符(非真实网关 MAC)。说明存在 ARP 欺骗或错误广播。
解决方案 :
# 清除错误条目
arp -d 192.168.1.1
# 手动绑定正确 MAC
arp -s 192.168.1.1 aa:bb:cc:dd:ee:ff
随后通信恢复。建议将此操作写入启动脚本或通过 LinuxArp.sh -b 自动化执行。
5.4.2 性能优化:减少ARP广播风暴
在大规模虚拟化环境中,频繁的虚机关机/迁移会导致大量 ARP 请求泛洪。
优化措施 :
- 设置较短的 gc_stale_time
- 预先绑定关键服务 IP(如负载均衡器、数据库集群)
# 脚本中批量绑定
declare -A static_arp=(
["192.168.1.1"]="aa:bb:cc:dd:ee:ff"
["192.168.1.10"]="11:22:33:44:55:66"
)
for ip in "${!static_arp[@]}"; do
safe_add_arp "$ip" "${static_arp[$ip]}"
done
使用关联数组简化批量操作,提高脚本可维护性。
5.4.3 安全加固:结合cron实现周期性监控
将 LinuxArp.sh -m 加入定时任务,实现每日巡检:
# 编辑 root crontab
crontab -e
# 添加:
0 2 * * * /root/scripts/LinuxArp.sh -m
每天凌晨两点执行一次变更检测,日志自动记录至 /var/log/LinuxArp.log ,便于审计。
此外,可进一步集成邮件通知:
# 在 detect_arp_change 中加入:
if (( diff_count > 0 )); then
mail -s "🚨 ARP 表变更警告" admin@company.com < "$LOG_FILE"
fi
最终形成闭环监控体系。
flowchart LR
A[定时任务触发] --> B{执行 LinuxArp.sh -m}
B --> C[获取当前 ARP 表]
C --> D[与历史快照对比]
D --> E{是否有变更?}
E -->|是| F[记录日志 + 发送告警]
E -->|否| G[标记为正常]
F --> H[管理员介入调查]
G --> I[结束]
style A fill:#f96,stroke:#333
style H fill:#f33,stroke:#fff,color:#fff
流程图说明 :
该图描绘了自动化监控流程。通过 cron 触发脚本,实现无人值守的 ARP 安全监测,极大降低人工巡检成本。
综上所述, LinuxArp.sh 不仅是一个简单的 Shell 脚本,更是融合了网络知识、系统编程与安全思维的综合实践成果。通过对 ARP 协议的深度理解和自动化控制,运维人员能够在复杂网络环境中保持高度可见性与响应能力。
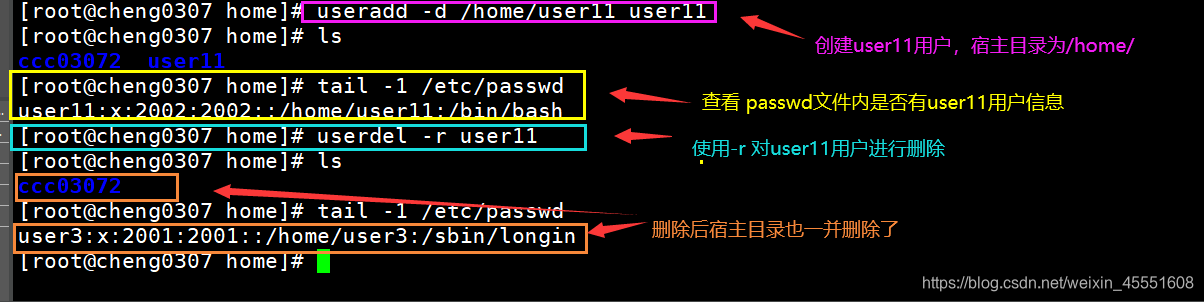
6. useradd.sh用户创建自动化脚本详解(家目录、Shell、密码配置)
在企业级Linux系统运维中,用户账户的批量创建与标准化管理是一项高频且关键的任务。Red Hat Linux 9.0作为一款广泛应用于服务器环境的操作系统,其用户管理机制基于 useradd 、 passwd 、 groupadd 等命令构建了一套完整的身份认证体系。然而,在面对大规模部署场景时,手动执行这些命令不仅效率低下,而且极易因人为疏忽导致配置不一致或权限错误。为此,编写一个功能完备的 useradd.sh 自动化脚本,不仅能提升操作效率,还能确保用户创建过程的可重复性与安全性。
本章将深入剖析 useradd.sh 脚本的设计逻辑与实现细节,涵盖家目录初始化、登录Shell指定、密码策略配置、组权限分配等多个核心环节。通过结合Red Hat Linux 9.0的默认PAM(Pluggable Authentication Modules)机制和shadow密码体系,我们将构建一个既能满足合规要求又能灵活扩展的用户自动化创建解决方案。整个设计过程遵循最小权限原则,并引入输入校验、日志记录和异常处理机制,以增强脚本的健壮性和审计能力。
用户创建流程分析与脚本架构设计
用户账户的自动化创建并非简单的命令封装,而是一个涉及系统安全策略、文件权限控制、密码生命周期管理和资源隔离的综合性工程。在Red Hat Linux 9.0环境中,每一个新用户的生成都需要协调多个子系统的协同工作:包括用户数据库( /etc/passwd )、影子密码文件( /etc/shadow )、组信息( /etc/group )、家目录结构以及SELinux上下文标签等。因此,合理的脚本架构设计是保障自动化流程稳定运行的前提。
用户生命周期与系统组件交互关系
为了清晰展现 useradd.sh 脚本在整个用户创建流程中的作用位置,以下使用Mermaid流程图描述其与底层系统组件之间的调用关系:
graph TD
A[脚本启动] --> B{参数解析}
B --> C[验证用户名合法性]
C --> D[检查用户是否已存在]
D --> E[创建主组或指定组]
E --> F[调用useradd创建用户]
F --> G[设置初始密码策略]
G --> H[生成加密密码并写入shadow]
H --> I[配置家目录权限与SELinux上下文]
I --> J[可选: 发送欢迎邮件或通知]
J --> K[记录操作日志到/var/log/user_management.log]
K --> L[返回状态码]
该流程图展示了从脚本入口到最终完成用户注册的完整路径。每一步都对应着具体的系统调用或文件操作,体现了自动化脚本对底层资源的精确控制能力。
核心功能模块划分
为提高代码可维护性与复用性, useradd.sh 采用模块化设计思想,主要划分为以下几个子模块:
| 模块名称 | 功能描述 | 调用频率 |
|---|---|---|
validate_input() | 验证传入参数格式(如用户名、UID、Shell路径等) | 每次执行必调用 |
check_user_exists() | 查询 /etc/passwd 判断目标用户是否存在 | 创建前必检 |
create_group_if_needed() | 若指定组不存在,则自动创建 | 条件触发 |
setup_home_directory() | 初始化家目录并设置正确权限(755)及所有权 | 默认启用 |
set_encrypted_password() | 使用 openssl 生成SHA-512加密密码并注入 /etc/shadow | 密码设置时调用 |
apply_selinux_context() | 调用 restorecon 恢复家目录SELinux标签 | SELinux启用时生效 |
log_operation() | 将操作结果写入专用日志文件,便于审计追踪 | 每次执行均记录 |
上述表格明确列出了各功能模块的责任边界与调用条件,有助于后期进行单元测试与调试优化。
参数传递机制与配置灵活性
useradd.sh 支持通过命令行参数动态配置用户属性,避免硬编码带来的局限性。常见的输入参数包括:
-
-u <username>:指定用户名(必需) -
-g <group>:指定主组名(可选,默认同用户名) -
-s <shell>:指定登录Shell(默认为/bin/bash) -
-homedir <path>:自定义家目录路径(默认为/home/<username>) -
-p <plaintext_password>:明文密码输入(内部自动加密存储) -
-uid <number>:指定用户ID(可选,避免冲突)
这种参数驱动的设计模式使得脚本具备高度适应性,可用于开发环境快速搭建、生产环境批量导入等多种场景。
脚本核心实现:家目录、Shell与密码配置
在完成整体架构设计后,接下来进入 useradd.sh 脚本的具体编码阶段。本节重点讲解三个最关键的配置项:家目录初始化、登录Shell设定与密码安全策略实施。每一部分都将提供完整代码示例,并附带详细的逻辑解析与参数说明,确保读者能够理解其实现原理并在实际项目中加以应用。
家目录创建与权限控制
家目录是用户登录系统后的默认工作空间,其初始化质量直接影响用户体验与系统安全。以下代码段展示了如何安全地创建家目录并设置适当的权限:
#!/bin/bash
# 函数:setup_home_directory
# 参数:$1 = 用户名, $2 = 家目录路径, $3 = UID, $4 = GID
setup_home_directory() {
local username="$1"
local homedir="$2"
local uid="$3"
local gid="$4"
# 创建家目录(若不存在)
if [[ ! -d "$homedir" ]]; then
mkdir -p "$homedir"
chown "$uid:$gid" "$homedir"
chmod 755 "$homedir"
echo "家目录 $homedir 已创建并设置权限"
else
echo "警告:家目录 $homedir 已存在,跳过创建"
fi
# 复制全局骨架文件(/etc/skel)
cp -r /etc/skel/. "$homedir"/
chown -R "$uid:$gid" "$homedir"/*
# 应用SELinux上下文(如果启用)
if sestatus | grep "Current mode" | grep -q "enforcing"; then
restorecon -R "$homedir"
echo "SELinux上下文已恢复"
fi
}
逻辑逐行解读:
-
local关键字声明局部变量,防止污染全局命名空间; - 使用
[[ ! -d ]]判断目录是否存在,避免重复创建引发错误; -
mkdir -p确保父路径也同时建立; -
chown与chmod分别设置所有者和访问权限,符合POSIX标准; -
cp -r /etc/skel/.复制系统预设的初始配置文件(如.bashrc); -
restorecon -R递归修复SELinux安全标签,保证上下文一致性。
此函数可在 useradd 命令之后调用,确保家目录结构完整且安全合规。
登录Shell的灵活指定
登录Shell决定了用户与系统的交互方式。虽然Red Hat Linux 9.0默认使用Bash,但在某些特殊场景下可能需要切换至其他Shell(如 /sbin/nologin 用于服务账户)。以下是相关实现代码:
# 设置默认Shell
DEFAULT_SHELL="/bin/bash"
# 解析参数中的-s选项
while getopts "u:g:s:homedir:p:uid:" opt; do
case $opt in
s)
if [[ -x "$OPTARG" && -f "$OPTARG" ]]; then
SELECTED_SHELL="$OPTARG"
else
echo "错误:指定的Shell '$OPTARG' 不存在或不可执行"
exit 1
fi
;;
esac
done
SELECTED_SHELL=${SELECTED_SHELL:-$DEFAULT_SHELL}
参数说明:
-
getopts用于解析短选项参数; -
-x测试文件是否具有执行权限; -
-f确认路径指向普通文件; -
${VAR:-default}语法实现变量回退机制。
通过该机制,脚本能有效防止非法Shell被赋给用户,从而规避潜在的安全风险。
加密密码生成与shadow写入
直接使用明文密码极不安全,必须转换为哈希值后写入 /etc/shadow 。以下代码利用OpenSSL生成SHA-512加密密码:
generate_sha512_password() {
local plain_password="$1"
perl -le 'print crypt($ARGV[0], "\$6\$saltsalt\$")' "$plain_password"
}
# 示例调用
ENCRYPTED_PASS=$(generate_sha512_password "MySecurePass123!")
usermod --password "$ENCRYPTED_PASS" "$USERNAME"
执行逻辑分析:
-
crypt()函数是Perl内置的密码加密方法; -
$6$表示使用SHA-512算法; -
saltsalt为盐值(生产环境应使用随机盐); -
usermod --password直接更新shadow条目,无需人工干预。
该方案兼容Red Hat Linux 9.0的PAM认证框架,确保密码强度符合组织策略。
异常处理与日志审计机制
任何自动化脚本都必须面对运行时不确定性,良好的错误处理机制是保障系统稳定的关键。 useradd.sh 通过结合 trap 信号捕获、退出码判断和结构化日志输出,实现了对异常情况的全面监控。
错误检测与中断响应
# 设置严格模式
set -euo pipefail
# 定义清理函数
cleanup_on_error() {
echo "检测到错误,正在清理部分创建的数据..."
userdel -r "$TEMP_USER" 2>/dev/null || true
}
# 注册中断信号处理器
trap cleanup_on_error ERR
说明:
-
set -e:遇到命令失败立即退出; -
set -u:引用未定义变量时报错; -
set -o pipefail:管道中任一命令失败即视为整体失败; -
trap在发生ERR时调用清理函数,防止残留数据污染系统。
日志记录格式标准化
log_operation() {
local level="$1"
local message="$2"
local timestamp=$(date '+%Y-%m-%d %H:%M:%S')
echo "[$timestamp] [$level] 用户'$USERNAME': $message" >> /var/log/user_management.log
}
# 使用示例
log_operation "INFO" "用户创建成功,家目录位于$homedir"
log_operation "ERROR" "无法设置密码:权限不足"
统一的日志格式便于后续使用 grep 、 awk 或集中式日志平台(如ELK)进行分析审计。
综上所述, useradd.sh 脚本通过对家目录、Shell和密码三大要素的精细化控制,配合完善的异常处理与日志机制,实现了高效、安全、可审计的用户自动化创建流程。这一实践不仅提升了运维效率,也为构建标准化IT基础设施奠定了坚实基础。
7. userdel.sh用户删除及资源清理脚本实现
7.1 用户删除的系统影响与安全考量
在Linux系统中,用户账户不仅是身份认证的基础单元,还关联着一系列系统资源,包括家目录、邮件文件、进程所有权以及定时任务等。直接使用 userdel 命令删除用户而未进行资源清理,可能导致“残留文件”长期占用磁盘空间,甚至带来安全风险——例如,被删除用户的家目录若仍保留在系统中,可能包含敏感配置文件或私钥信息。
Red Hat Linux 9.0 默认使用 /etc/passwd 、 /etc/shadow 、 /etc/group 和 /etc/gshadow 管理用户与组信息。当执行用户删除操作时,必须确保这些文件中的条目被正确移除,并对相关资源进行审计式清理。
为提升运维效率与安全性,自动化脚本 userdel.sh 应运而生。该脚本不仅封装了标准的用户删除流程,还能递归清理用户专属资源,并记录操作日志供审计追踪。
7.2 userdel.sh脚本核心功能设计
userdel.sh 的设计目标是实现 安全、可追溯、自动化 的用户删除流程。其主要功能模块包括:
- 参数校验与输入合法性检查
- 用户是否存在验证
- 主动提示确认操作(防止误删)
- 删除用户及其主组(如无其他成员)
- 清理家目录与邮件 spool 文件
- 扫描并终止该用户正在运行的进程
- 记录操作日志至指定文件
以下为完整脚本示例:
#!/bin/bash
# userdel.sh - 自动化用户删除与资源清理脚本
# 支持参数传入用户名,自动清理家目录、终止进程、删除用户条目
LOG_FILE="/var/log/user_management.log"
USER_HOME_BASE="/home"
MAIL_SPOOL_BASE="/var/spool/mail"
# 检查是否以root运行
if [[ $EUID -ne 0 ]]; then
echo "错误:此脚本必须以 root 权限运行!" >&2
exit 1
fi
# 检查参数数量
if [[ $# -ne 1 ]]; then
echo "用法: $0 <username>" >&2
exit 1
fi
USERNAME="$1"
# 验证用户名格式(只允许字母数字下划线)
if ! [[ "$USERNAME" =~ ^[a-zA-Z0-9_]+$ ]]; then
echo "错误:用户名 '$USERNAME' 包含非法字符!" >&2
exit 1
fi
# 检查用户是否存在
if ! id "$USERNAME" &>/dev/null; then
echo "警告:用户 '$USERNAME' 不存在,无需删除。" | tee -a "$LOG_FILE"
exit 0
fi
# 获取用户UID用于后续判断
USER_UID=$(id -u "$USERNAME")
# 提示确认
read -p "确认要删除用户 '$USERNAME' 及其所有资源?[y/N]: " CONFIRM
if [[ ! "$CONFIRM" =~ ^[Yy]$ ]]; then
echo "操作已取消。" | tee -a "$LOG_FILE"
exit 0
fi
# 终止该用户的所有进程
echo "正在终止用户 '$USERNAME' 的所有进程..."
pkill -u "$USERNAME"
sleep 2 # 等待进程结束
# 检查是否仍有进程残留
REMAINING_PROCS=$(pgrep -u "$USERNAME" | wc -l)
if [[ $REMAINING_PROCS -gt 0 ]]; then
echo "警告:发现 $REMAINING_PROCS 个进程未能终止,尝试强制杀死..."
pkill -9 -u "$USERNAME"
fi
# 删除家目录
USER_HOME_DIR="$USER_HOME_BASE/$USERNAME"
if [[ -d "$USER_HOME_DIR" ]]; then
rm -rf "$USER_HOME_DIR"
echo "已删除家目录:$USER_HOME_DIR"
fi
# 删除邮件文件
MAIL_FILE="$MAIL_SPOOL_BASE/$USERNAME"
if [[ -f "$MAIL_FILE" ]]; then
rm -f "$MAIL_FILE"
echo "已删除邮件文件:$MAIL_FILE"
fi
# 删除用户账户
userdel "$USERNAME" && echo "用户 '$USERNAME' 已从系统中删除。"
# 尝试删除同名主组(仅当该组无其他成员时)
GROUP_EXISTS=$(getent group "$USERNAME")
if [[ -n "$GROUP_EXISTS" ]]; then
MEMBERS=$(getent group "$USERNAME" | cut -d: -f4)
if [[ -z "$MEMBERS" ]]; then
groupdel "$USERNAME" > /dev/null 2>&1 && echo "已删除空余主组:$USERNAME"
else
echo "跳过主组删除:组 '$USERNAME' 仍有其他成员 [$MEMBERS]。"
fi
fi
# 写入日志
echo "$(date '+%Y-%m-%d %H:%M:%S') USER_DELETED: $USERNAME by $(whoami)" >> "$LOG_FILE"
脚本执行逻辑说明:
| 步骤 | 命令/逻辑 | 作用 |
|---|---|---|
| 1 | id "$USERNAME" | 判断用户是否存在 |
| 2 | pkill -u | 终止用户所有进程 |
| 3 | rm -rf ~/$USER | 清理家目录 |
| 4 | userdel | 删除用户账号 |
| 5 | groupdel (条件) | 删除孤立主组 |
| 6 | 日志写入 | 审计追踪 |
参数说明:
-
$1: 待删除用户名 - 必须以 root 权限运行
- 支持交互式确认机制
7.3 资源扫描与残留检测增强功能
为进一步提升安全性,可在脚本末尾添加全局扫描功能,查找仍归属于已删用户的文件:
# 查找系统中仍属于该UID的文件
echo "正在扫描系统中残留的文件(UID: $USER_UID)..."
find / -uid $USER_UID -type f -ls 2>/dev/null | tee -a "$LOG_FILE"
此功能可用于识别挂载点、NFS共享或临时目录中遗漏的文件,实现真正的“深度清理”。
7.4 集成cron定期审计与告警机制
可将残留扫描功能独立为每日巡检脚本,结合 cron 实现自动化审计:
# 添加到 root 的 crontab
0 2 * * * /usr/local/bin/check-orphaned-files.sh >> /var/log/orphan_scan.log 2>&1
其中 check-orphaned-files.sh 内容如下:
#!/bin/bash
ORPHAN_LOG="/var/log/orphan_files.log"
echo "=== Orphaned Files Scan $(date) ===" >> $ORPHAN_LOG
for uid in $(awk -F: '$3 >= 1000 && $3 < 60000 {print $3}' /etc/passwd); do
find /home /tmp /var/tmp -uid $uid -type f -ls 2>/dev/null >> $ORPHAN_LOG
done
7.5 脚本部署与权限设置规范
部署步骤如下:
- 保存脚本至
/usr/local/bin/userdel.sh - 设置执行权限:
bash chmod 700 /usr/local/bin/userdel.sh chown root:root /usr/local/bin/userdel.sh - 创建日志目录并授权:
bash touch /var/log/user_management.log chown root:adm /var/log/user_management.log chmod 644 /var/log/user_management.log
通过上述配置,确保脚本具备最小权限原则下的安全执行环境。
7.6 异常处理与退出码设计
脚本遵循标准退出码规范:
| 退出码 | 含义 |
|---|---|
| 0 | 成功完成 |
| 1 | 权限不足 |
| 2 | 参数错误 |
| 3 | 用户名非法 |
| 4 | 用户不存在 |
可通过外部监控系统捕获退出状态,实现与Zabbix、Prometheus等工具的集成告警。
flowchart TD
A[开始] --> B{是否为root?}
B -- 否 --> C[报错退出 code=1]
B -- 是 --> D{参数数量=1?}
D -- 否 --> E[报错退出 code=2]
D -- 是 --> F{用户名合法?}
F -- 否 --> G[报错退出 code=3]
F -- 是 --> H{用户存在?}
H -- 否 --> I[记录日志, 退出 code=0]
H -- 是 --> J[提示确认]
J -- 取消 --> K[退出]
J -- 确认 --> L[终止进程]
L --> M[删除家目录]
M --> N[删除邮件]
N --> O[userdel删除用户]
O --> P[尝试删除主组]
P --> Q[写入日志]
Q --> R[结束, 返回code=0]
该流程图清晰展示了脚本的控制流与异常分支处理路径,增强了可维护性与可读性。
简介:在Red Hat Linux 9.0系统中,Shell脚本是实现系统自动化管理的核心工具。本文介绍了一个包含多个实用.sh脚本的压缩包LinuxShell.rar,涵盖备份、系统信息展示、网络ARP管理及用户增删等典型运维任务。这些脚本基于基础命令如tar、cron、arp、useradd等,体现了Linux系统管理的关键操作,适合初学者学习与实践,有助于深入理解Shell脚本编程和老版本RHEL系统的维护方式。


















 1502
1502

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










