



 本文介绍了快手如何在Druid中实现精确去重功能,包括字典编码、bitmap等方案,并探讨了其他性能优化措施,如查询优化、资源管理等,展示了快手在大数据分析领域的技术创新。
本文介绍了快手如何在Druid中实现精确去重功能,包括字典编码、bitmap等方案,并探讨了其他性能优化措施,如查询优化、资源管理等,展示了快手在大数据分析领域的技术创新。

议题简介:
Druid在快手落地近一年时间,支持了公司绝大部分OLAP分析需求。为了保障性能,稳定性,功能性等要求,快手对Druid内核进行大量改进,建设周边系统,以及开发新feature。本次分享主要介绍快手Druid精确去重功能的设计与实现,以及部分实用功能的改进。
讲师简介:
邓钫元,快手大数据架构团队研发工程师,毕业于浙江大学,曾就职于百度、贝壳,目前负责快手Druid平台研发工作,多年底层集群以及OLAP引擎研发、分布式系统的优化经验,热衷开源,为hadoop/kylin/druid等社区贡献代码。
目录:
o快手Druid平台概览
oDruid精确去重功能设计
oDruid其他改进
o快手Druid Roadmap
技术选型需求:

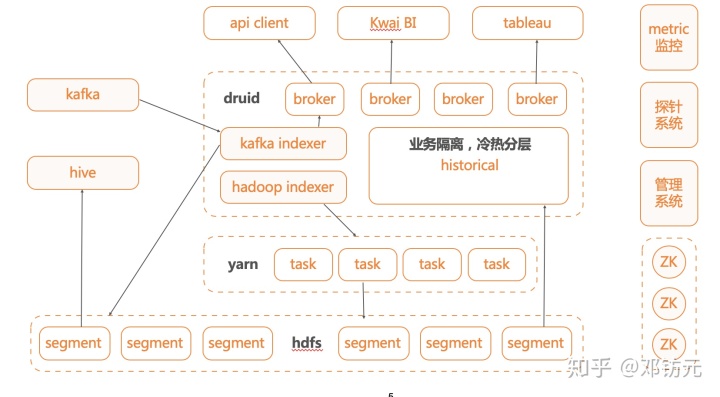
快手Druid平台架构
Druid去重支持情况
维度列
1.cardinality agg, 非精确,基于hll,查询时hash函数比较耗cpu
2.嵌套group by,精确,耗费资源
3.社区DistinctCount插件,精确,但局限很大
仅支持单维度,构建时需要基于该维度做hash partition
不能跨interval进行计算
指标列
1.HyperUniques/Sketch:非精确,基于hll,摄入时做计算,比cardinality agg性能高
结论:缺乏一种预聚合,较低资源占用,通用的精确去重支持。
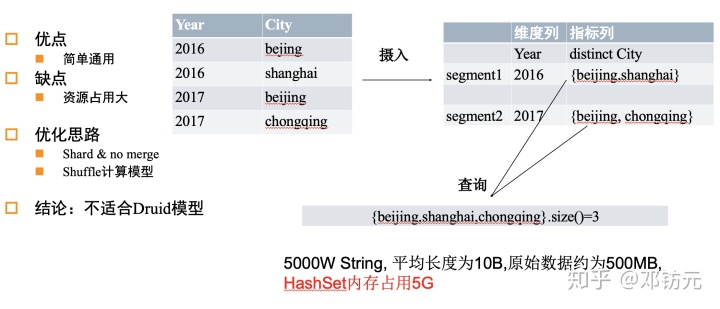
精确去重方案-hashset
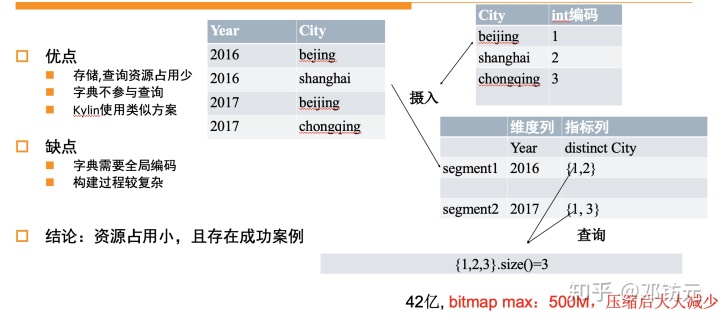
精确去重方案-字典编码+bitmap
字典编码方案-Redis
o优点
能进行实时编码,同时支持离线任务及实时任务
o缺点
Id生成速度有瓶颈,POC: 5w/s
查询上压力也较大(可缓存)
对Redis稳定性要求非常高
字典编码方案-离线MR编码
o优点
编码及查询吞吐高
容错性高
o缺点
仅支持离线导入任务
o结论
离线任务使用离线MR编码,可通过小时级任务解决近实时
实时任务仅支持原始int去重(无需编码)
字典编码方案- AppendTrie树
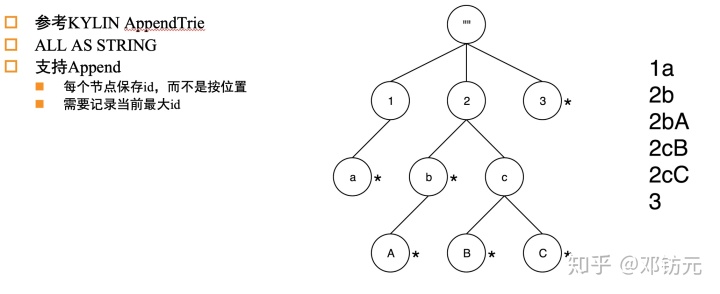
字典编码方案- 可分裂AppendTrie树
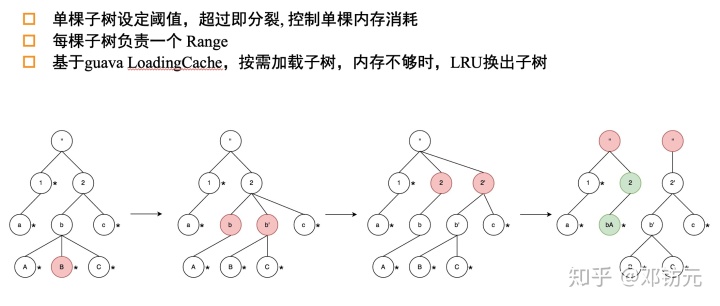
字典编码方案- 字典并发构建

精确去重- 新增unique指标存储

精确去重- 整体流程
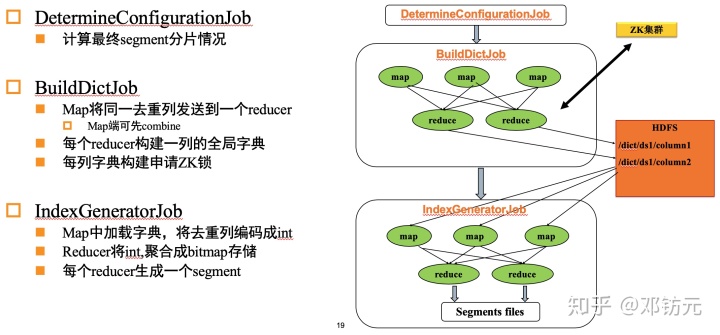
精确去重- 使用方法

优化字典查询
存在一个超高基数列(UHC)的去重指标
在IndexGenerator任务前,增加ClusterBy UHC列任务
保证每个map处理的uhc列数据有序,避免多次换入换出。
存在多个超高基数列的去重指标
拆成多个DataSource
调大IndexGenerator任务的map内存,保证字典能加载到内存
bitmap查询优化
减少targetPartitionSize或调大numShards
增加segment个数,提升并行度
batchOr,而不是逐行or
避免I/O与or计算交替,cache line miss
batchOr选择
手动按顺序依次inplace or,适合结果是较长的连续序列
naive_or 尽量延迟计算,通常较好
priorityqueue_or 使用堆排序,每次合并最小两个bitmap,消耗更多内存,建议benchmark后使用
bitmap查询优化-CroaringJNI
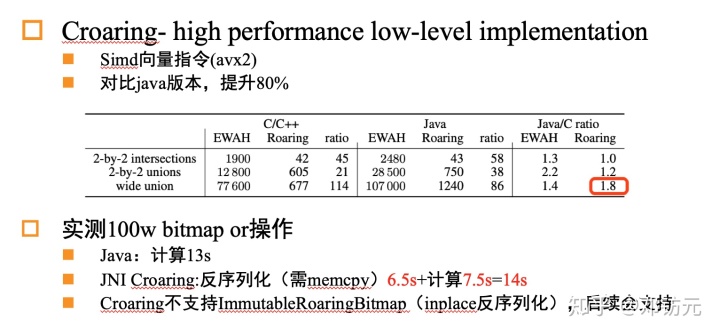
传输层编码
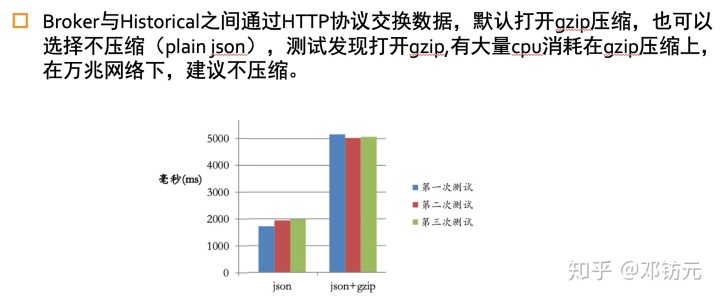
性能测试

Historical快速重启

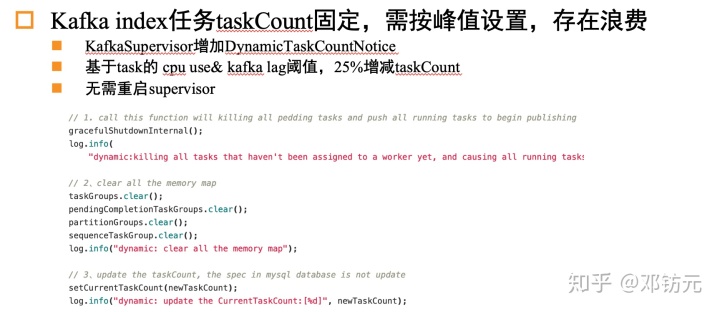
Kafkaindex-taskCount自动伸缩
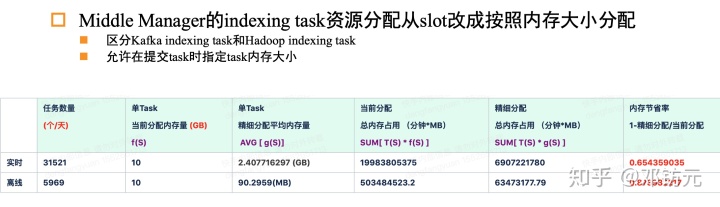
Kafkaindex– 精细化调度
元数据交互加速

Druid 6th Meetup资料下载:链接: https://pan.baidu.com/s/1gfvgtHEFb09_b4J2ef7BXg 提取码: x4av
活动的直播回放视频
链接:https://share.weiyun.com/53fbWo6


















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










