



 本文介绍了一种使用Python统计数据集中特定字段重复次数的方法,并针对不同ID分组的需求提供了实现方案。
本文介绍了一种使用Python统计数据集中特定字段重复次数的方法,并针对不同ID分组的需求提供了实现方案。
问题
群友提问:求每组数据中每个元素重复的个数,用什么函数?
严小样儿:安排!
 咋一看,我觉得他问的我很懵B~于是,和他要了份数据,瞬间清楚了很多!
咋一看,我觉得他问的我很懵B~于是,和他要了份数据,瞬间清楚了很多!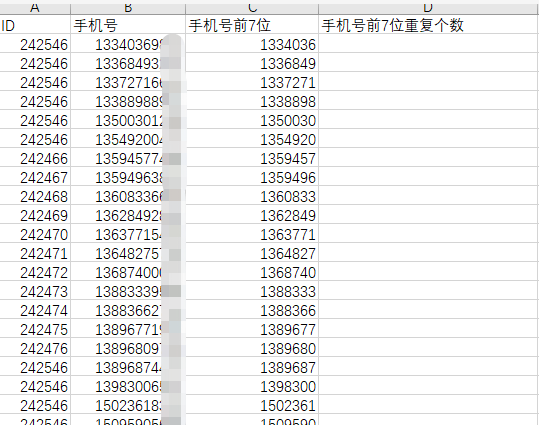
所以,需求就是求手机号前7位重复个数,安排!
安排
一、预览数据
df = pd.read_excel(r'C:/Users/Administrator/Desktop/新建 Microsoft Excel 工作表(3).xlsx')print(df.head(),end = '\n\n')df.info()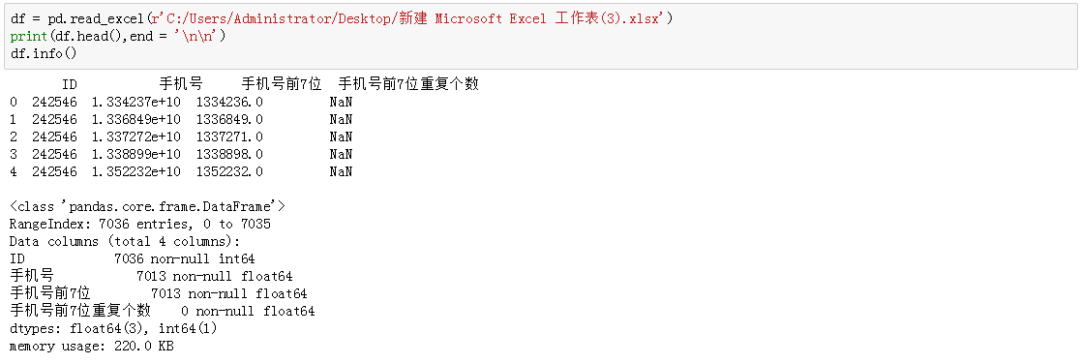
预览数据发现,数据格式不正确,需要先进行格式转换,以及防止隐私泄露,我们用一定的方法进行脱敏处理。
df = df.iloc[:,:3].astype(str)print(df.head(),end = '\n\n')df.info()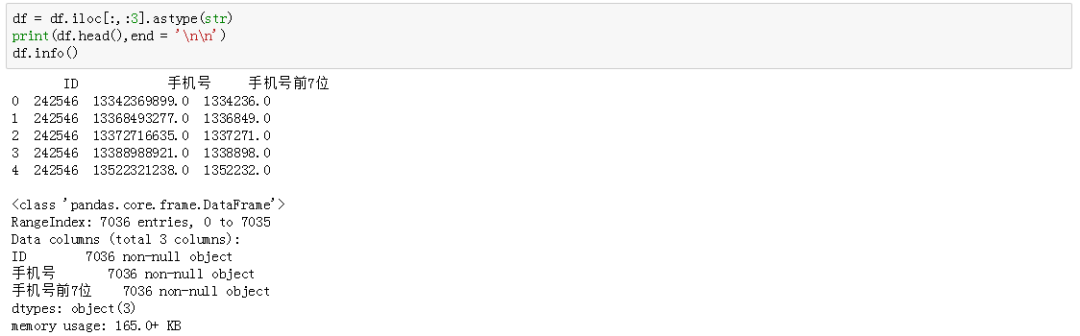
# 方法一df['手机号'] = df['手机号'].str.split('.',expand = True)[0]df['手机号'] = df['手机号'].apply(lambda x:x[:-3]+'***')# 方法二df['手机号前7位'] = df['手机号前7位'].str.replace('.0','')df.tail()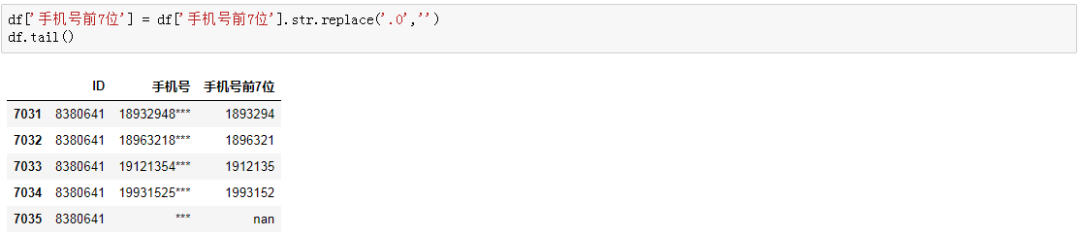
二、删除无效值
idx = df[df['手机号']=='***'].indexdf.drop(idx,inplace = True)df.head()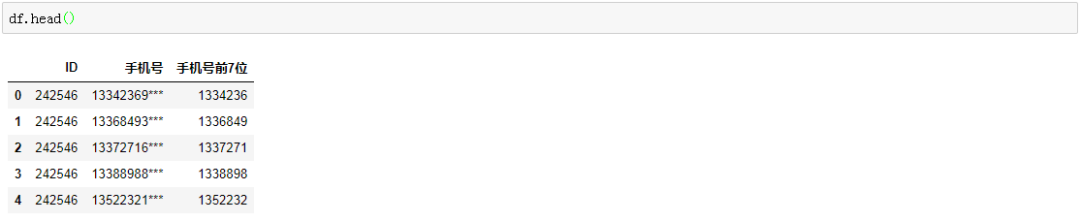
接下来,进行统计手机号前7位重复个数。
n = df['手机号前7位'].value_counts()df['手机号前7位重复个数'] = df['手机号前7位'].map(n)df.tail()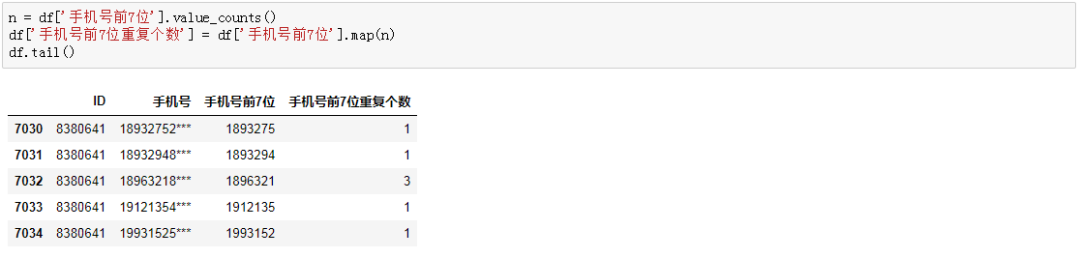 当我满心欢喜地告诉他答案时候,他说不对啊!!!不同ID下,要分别统计,也就是说要看每一个ID下手机号前7位重复个数。于是,接着修改。
当我满心欢喜地告诉他答案时候,他说不对啊!!!不同ID下,要分别统计,也就是说要看每一个ID下手机号前7位重复个数。于是,接着修改。三、正确答案
# 化整为零ID = df['ID'].unique()result = []for i in ID: df1 = df[df['ID']==i].copy() n = df1['手机号前7位'].value_counts() df1['手机号前7位重复个数'] = df1['手机号前7位'].map(n) result.append(df1)r = pd.concat(result)r.sample(10)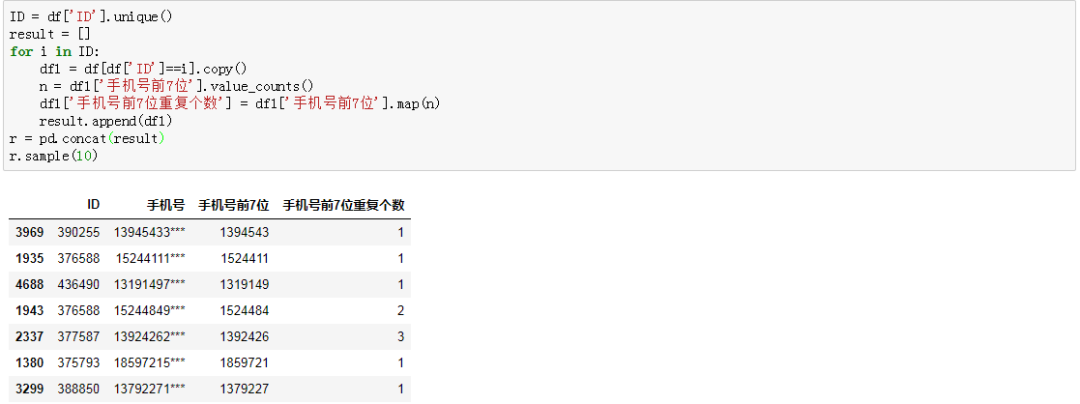
这一次,他没有再说什么!!嘻嘻嘻,为我的机智点赞~
不过,我觉得这个方法也许不是太好吧。但是,有没有更好的方法呢?
欢迎大家和我交流一下,感谢~
更多精彩
传送门1:日常答疑|Python向量化操作、矩阵运算
传送门2:日常答疑|Python处理时间格式并计算时间差值
传送门3:从报错开始梳理用Python连接MySQL数据库
传送门4:系列|七天PYTHON养成记之初识
传送门5:系列|七天PYTHON养成记之函数
传送门6:日常答疑|MySQL删除重复数据踩过得坑
传送门7:系列|七天PYTHON养成记之序列


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










