




 本文深入探讨了哈希表这一高效数据结构的工作原理,包括理想搜索方式、哈希函数设计、冲突解决策略如闭散列与开散列,以及性能分析。详细介绍了开散列链表方式的代码实现,并讨论了负载因子对哈希表性能的影响。
本文深入探讨了哈希表这一高效数据结构的工作原理,包括理想搜索方式、哈希函数设计、冲突解决策略如闭散列与开散列,以及性能分析。详细介绍了开散列链表方式的代码实现,并讨论了负载因子对哈希表性能的影响。
概念
- 理想的搜索方法:可以不经过任何的比较,一次直接从表中得到搜索的元素。
- 哈希表就是一种理想的搜索方式,通过某种函数使得元素的存储位置和他的关键码之间建议一种一一对应的映射关系那么就可以很快的查找到该元素。理想的哈希表时间复杂度是O(1),因为不需要进行多次比较。
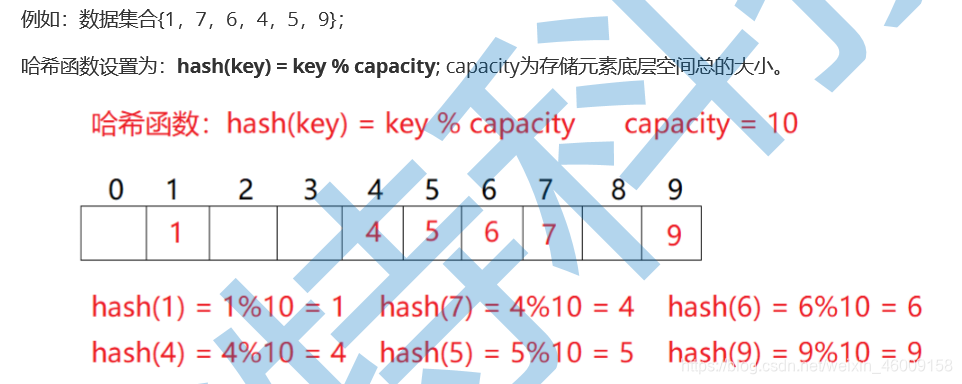
哈希函数是一个复杂的函数,一般可用key%数组长度
通过key的到hash的值,再根据hash的值快速判断key是否存在。
哈希冲突
一:
- 上例在数组元素个数比较少的情况下成立,但当元素为1万,10万时,数组长度为1000时,就会出现关键字重复的情况,也就是存储地址和关键字之间做不到一一对应。就会发生哈希冲突/哈希碰撞。
- 哈希冲突是必然的,我们能做的就是降低冲突率。
二:解决冲突的方法
- 闭散列:此时数组类型应与关键码类型相同,当遇到关键码相同的情况时,从当前存储地址依次往后,查找空白位置存储这个冲突值(线性探测)。
-
当查找该值时,先根据哈希函数找到关键码,依次向后比对关键码,看该元素是否存在。

2.开散列:在数组中存储的不再只是key,而是存一个key的顺序表或链表(常用)。还是按照哈希函数求出关键码,若遇到码冲突的情况,则将冲突值依次存入到以key为头结点的链表中去。 -
当查找该值时,根据哈希函数找到关键码,依次对比链表中的元素,是否为要查找的值。
-
当冲突十分严重时,我们可以将这个问题继续转化,如每个哈希地址的背后都是另一个哈希表,或每个哈希地址后面都是一颗红黑树。

3.其他解决方法:1).数组长度选择方式:
-
选择hash表长度时一般要选择一个较大的值。但是若数组长度较大时,时间复杂度就会变高,冲突概率降低,但浪费空间变多。
-
可以选择将数组元素个数选定为一个素数,这样冲突概率会降低(数学原因)。
2).哈希函数设置方式
-
除留余数法(常用):
设哈希表中允许的地址数为m,取一个不大于m,但接近m的质数作为除数,按照哈希函数,hash(key)=key%p,将关键码转化为哈希地址。
4.负载因子调节
- 负载因子就是衡量元素冲突的概率。决定是否需要对hash表扩容的关键。
- 负载因子< 当hash表中实际元素个数/数组长度时,需要扩容
- 闭散列中:负载因子一定小于1
- 开散列中:负载因子可以大于1
性能分析
- 哈希表的插入,查找,删除操作的时间复杂度都近似为O(1),最终的时间复杂度取决于hash冲突的严重程度。
标准库中的HashMap就是通过开散列的方式处理哈希冲突的,如果发现链表的结构过长就会把链表结构调整为红黑树的结构。
开散列链表方式代码练习
package container;
public class MyHashMap {
//开散列,链表,除留余数法
public static class Node{
//创建一个链表的节点静态内部类,因为哈希表是hashmap的一个实例,所以是key—value
private int key;
private int value;
public Node next;
public Node(int key, int value) {
this.key = key;
this.value = value;
}
public int getKey() {
return key;
}
public void setKey(int key) {
this.key = key;
}
public int getValue() {
return value;
}
public void setValue(int value) {
this.value = value;
}
}
//哈希表的本体,每个元素又是一个链表的头结点,所以是Node类型的
public Node[] array = new Node[101];
public int size = 0;//当前的数组元素个数
private static final double LOAD_FACTOR=0.78;//负载因子,不可变对象。
//插入操作,在链表中如果key存在就修改当前value的值
//如果key不存在就插入新的键值对
public void put(int key,int value){
//1.通过哈希函数确定关键码,把key映射成数组下标
int index = hashFunc(key);
//2.根据下标找到对应的链表头结点
Node list = array[index];
//3.遍历链表查找key是否存在
for (Node cur = list;cur != null;cur = cur.next){
if (cur.key==key){
//说明key值存在,更新value
cur.value=value;
return;
}
}
//当循环结束,也没有找到,key值不存在,插入新的键值对
//此处选择头插,头插简单
Node newhead = new Node(key,value);
newhead.next = list;
array[index] = newhead;
size++;
if (loadFactor()>LOAD_FACTOR){
resize();
}
return;
}
//扩容操作,把原来hash表中的所有元素搬运到新的数组中
private void resize() {
Node [] newarray = new Node [array.length*2];//原来数组的二倍
for ( int i=0;i<array.length;i++){
for (Node cur=array[i];cur!=null;cur=cur.next){
int index = cur.key/newarray.length;
Node newnode = new Node(cur.key,cur.value);
newnode.next = newarray[index];
newarray[index]=newnode;
}
}
//释放原来数组
array=newarray;
}
//查找操作,找到key的值则返回对应的value,没有找到k值则返回-1
public int get(int key){
//1.通过哈希函数确定关键码
int index = hashFunc(key);
//2.找到对应的链表
Node list = array[index];
//3.遍历链表查找是否存在key值
for (Node cur = list;cur != null;cur = cur.next){
if (cur.key==key){
return cur.value;
}
}
//循环结束还没有找到key的值
return -1;
}
//扩容操作,扩容根据负载因子来判断
private double loadFactor(){
return size*1.0/array.length;
}
//哈希函数,实际工作中会更加复杂
private int hashFunc(int key) {
//简单的除留余数法
return key%array.length;
}
}

















&spm=1001.2101.3001.5002&articleId=105642027&d=1&t=3&u=eb084b2aa31e4d3d916aaf4aa1a21c77)
 5790
5790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










