




SQL客户端
Flink SQL客户端是一款便捷工具,旨在降低使用Flink进行数据分析的门槛。它为那些不熟悉Java和Scala编程,却熟悉SQL查询语句的人员提供了简单易用的方式。通过Flink SQL客户端,你可以像使用MySQL一样,在命令行交互界面中编写、调试和提交SQL查询到集群中,而无需编写任何Java或Scala代码。这个工具使整个Flink应用的编写、测试和提交过程变得异常简单,从而将数据分析任务的复杂性最小化,让更多的专注于SQL的工程师能够轻松地进行流处理任务。
SQL Client基本使用
Flink SQL客户端被集成在Flink发行版中,可以直接在任意Flink的客户端运行。运行FlinkSQL 客户端默认执行SQL所在的集群是Standalone集群,所以这里首先需要启动Flink Standalone集群:
[root@node1 ~]# cd $FLINK_HOME/bin [root@node1 bin]# start-cluster.sh Starting cluster...
当Standalone集群启动后,我们在Flink任意的客户端中可以执行如下命令进入到SQL 客户端:
[root@node4 ~]# cd $FLINK_HOME/bin [root@node4 bin]# ./sql-client.sh
注意:Flink客户端中执行SQL 时是通过客户端$FLINK_HOME/conf/flink-conf.yaml配置文件找到的,所以这里需要在改文件中配置“rest.address”和“rest.bind-address”配置项。
进入Flink SQL客户端后,可以执行如下语句并按Enter键执行,查看是否能正常使用Flink SQL:
#执行SQL验证是否能正常使用SQL客户端
SELECT 'Hello World';
#回车后可以看到进入到结果视图,退出结果视图可以按Q
EXPR$0
Hello World
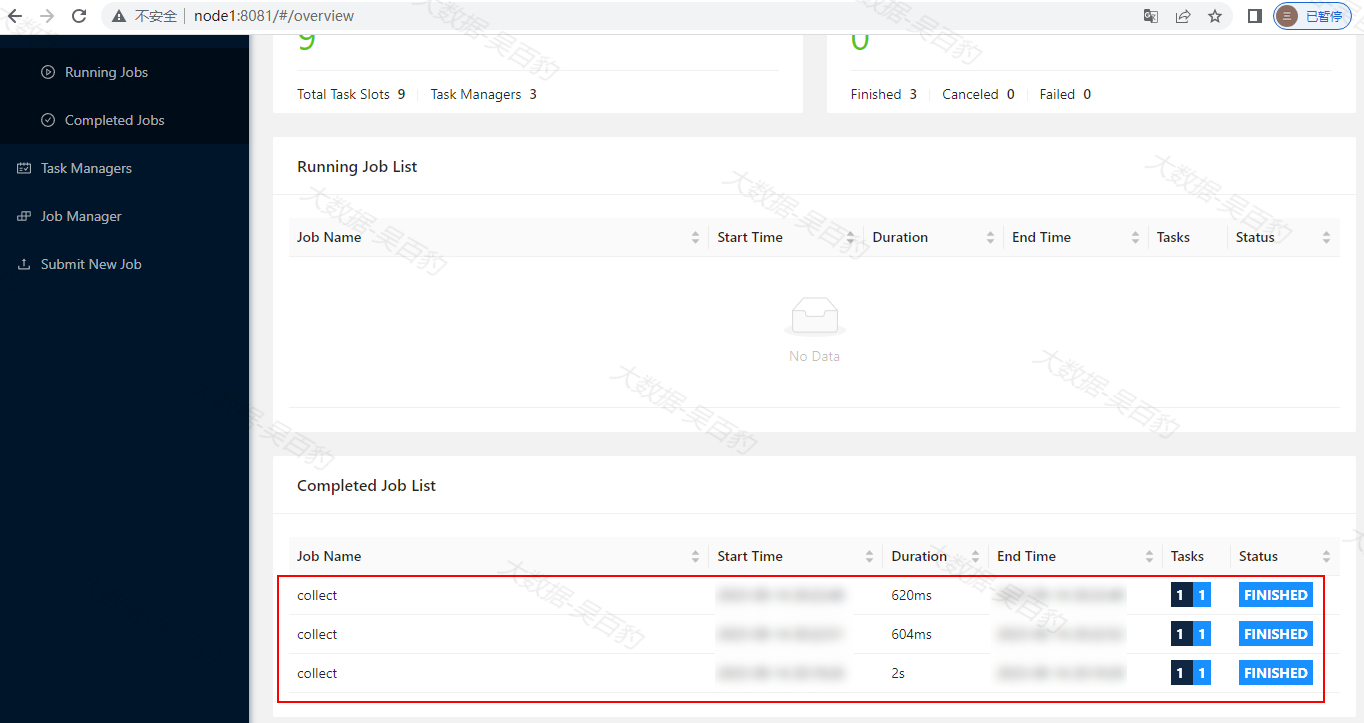
打开Flink WebUI可以看到每当提交一个SQL都会生成一个Flink Job。
退出Flink SQL客户端时,可以在交互式界面中执行quit()或者exit()命令。
Flink SQL客户端提供了三种可视化结果模式:表格模式(Table Mode)、变更日志模式(Changelog Mode)、Tableau模式(Tableau Mode)。
-
表格模式(Table Mode)
表格模式会将结果用规则的分页表格可视化展示出来,进入Flink SQL客户端默认使用的就是这种模式,执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'table';
-
变更日志模式(Changelog Mode)
变更日志模式不会实体化和可视化结果,而是由插入(+)和撤销(-)组成持续查询产生的结果流,执行如下命令启用:
SET 'sql-client.execution.result-mode' = 'changelog';
-
Tableau模式(Tableau Mode)
Tableau模式更接近传统的数据库,会将执行的结果以制表的形式直接展示在屏幕上,使用这种模式进行流式查询时,如果流是有限的数据集,那么Flink处理完所有数据之后会自动停止作业,同时屏幕上的打印结果也会相应停止;如果是无界流可以通过ctrl+c来终止屏幕上的输出。执行如下命令启动:
SET 'sql-client.execution.result-mode' = 'tableau';
以上几种结果可视化模式在SQL查询时都非常有用,在批处理环境下执行的查询只能使用表格模式和Tableau模式,此外涉及到SQL中的一些配置项也都可以通过SET方式进行设置。关于以上三种可视化结果模式可以通过如下示例来观察:
#设置表格模式并执行sql
Flink SQL> SET 'sql-client.execution.result-mode' = 'table';
Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('zs'), ('ls'), ('ww'), ('zs')) AS NameTable(name) GROUP BY name;
name cnt
——————————————————————————————
ls 1
ww 1
zs 2
#设置变更日志模式并执行sql
Flink SQL> SET 'sql-client.execution.result-mode' = 'changelog';
Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('zs'), ('ls'), ('ww'), ('zs')) AS NameTable(name) GROUP BY name;
op name cnt
———————————————
+I zs 1
+I ls 1
+I ww 1
-U zs 1
+U zs 2
#设置Tableau模式并执行sql
Flink SQL> SET 'sql-client.execution.result-mode' = 'tableau';
Flink SQL> SELECT name, COUNT(*) AS cnt FROM (VALUES ('zs'), ('ls'), ('ww'), ('zs')) AS NameTable(name) GROUP BY name;
+----+-----+----+
| op |name |cnt |
+----+-----+----+
| +I | zs | 1 |
| +I | ls | 1 |
| +I | ww | 1 |
| -U | zs | 1 |
| +U | zs | 2 |
+----+-----+----+
基于Standalone提交SQL任务
默认启动Flink SQL是基于Standalone -Session集群进行任务提交,下面通过一个案例进行演示,该案例通过执行SQL语句实时读取socket基站日志数据并实时统计每个基站通话时长。
在SQL客户端执行SQL命令之前需要做一些准备工作,由于需求中使用SQL通过Kafka Connecotr连接到Kafka集群所以这里需要将如下两个依赖上传至Standalone各个节点$FLINK_HOME/lib路径中,包括Flink客户端也要上传:
flink-connector-kafka-1.17.1.jar kafka-clients-3.3.1.jar
上传好以上依赖的jar包后重新启动Flink Standalone集群。然后启动Kafka集群和FlinkSQL客户端,并向SQL 客户端提交如下SQL:
#创建读取Kafka Table
create table stationlog_tbl (
sid string,
call_out string,
call_in string,
call_type string,
call_time bigint,
duration bigint,
time_ltz AS TO_TIMESTAMP_LTZ(call_time,3),
WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND) with ('connector' = 'kafka',
'topic' = 'stationlog-topic',
'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv'
);
#执行SQL查询
SELECT sid ,sum(duration) as total_duration
FROM stationlog_tbl
GROUP BY sid;
执行完以上SQL后,可以在Flink Standalone集群中看到启动的Job:
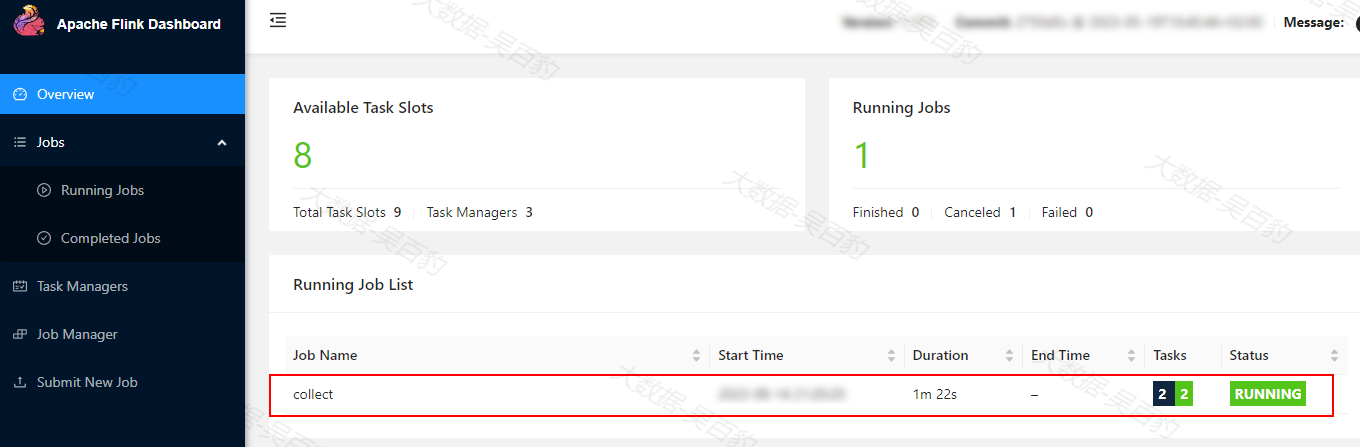
向Kafka中stationlog-topic中输入如下数据,可以实时看到FlinkSQL 客户端有结果输出。
#向kafka stationlog-topic中输入如下数据 001,181,182,busy,1000,10 002,182,183,fail,3000,20 001,183,184,busy,2000,30 002,184,185,busy,6000,40 001,181,183,busy,5000,50 #在SQL 客户端实时统计结果如下 sid total_duration ——————————— 002 60 001 90
注意:以上SQL执行中退出实时结果页面后,对应Flink Job也会停止,可以在SQL 客户端中执行如下命令查看执行的Flink任务:
#查询Flink jobs Flink SQL> show jobs; +----------------------------------+----------+----------+ | job id | job name | status | +----------------------------------+----------+----------+ | 0d35a069f08555c7bf71373b873c7db0 | collect | CANCELED | | 8ddf18bffac8ba64266bced2b4958c1e | collect | CANCELED | | 1204e2b4b9dc186eb39d034c18f521b5 | collect | CANCELED | +----------------------------------+----------+----------+
基于Yarn提交SQL任务
Flink SQL也可以将任务提交到Yarn-session集群中,首先需要启动Yarn Session集群:
#启动HDFS [root@node1 ~]# start-all.sh #在node5启动Flink Yarn Session集群 [root@node5 ~]# cd $FLINK_HOME/bin [root@node5 bin]# ./yarn-session.sh -nm yarn-session -tm 1024m -s 3 -d
创建出Yarn Session集群后会在node5节点/tmp/下创建一个隐藏的”.yarn-properties-<用户名>” Yarn属性文件,有了该文件后,在当前节点启动SQL客户端指定连接模式为“yarn-session”后,默认会通过该文件找到Yarn Session集群并将SQL任务提交到Yarn Session集群中。
#启动SQL 客户端并指定yarn-session模式
[root@node5 bin]# ./sql-client.sh -s yarn-session
#向Flink SQL中执行如下SQL
create table stationlog_tbl (
sid string,
call_out string,
call_in string,
call_type string,
call_time bigint,
duration bigint,
time_ltz AS TO_TIMESTAMP_LTZ(call_time,3),
WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND) with ('connector' = 'kafka',
'topic' = 'stationlog-topic',
'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'latest-offset',
'format' = 'csv'
);
#查询数据
SELECT sid ,sum(duration) as total_duration
FROM stationlog_tbl
GROUP BY sid;
需要注意的是node5节点FLINK_HOME/lib下也需要包含”flink-connector-kafka-x.jar”和“kafka-clients-x.jar”两个jar包。SQL执行后,可以通过Yarn-Session集群观察到启动的Flink任务:
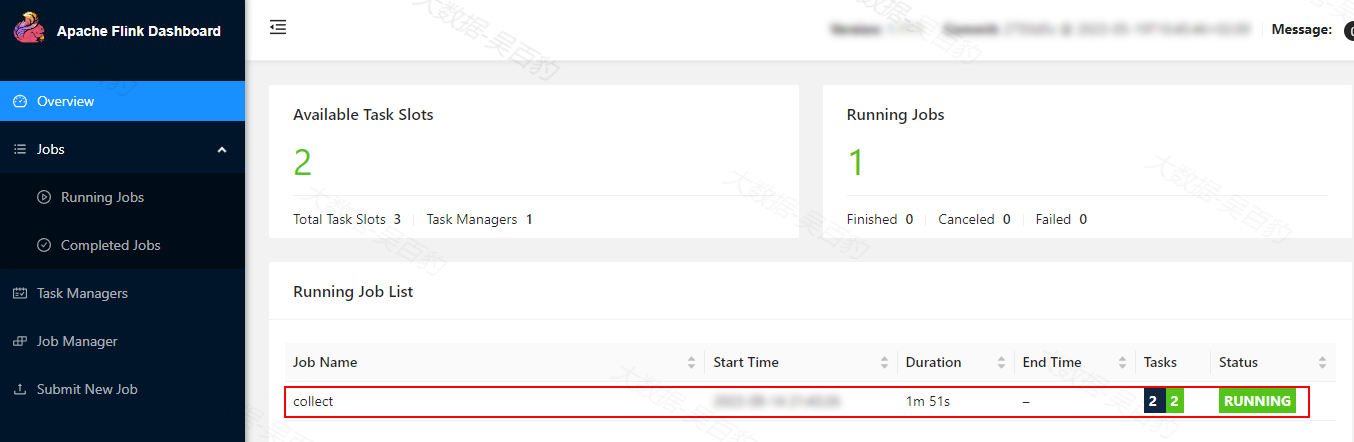
向Kafka stationlog-topic中输入如下数据,可以看到输出对应的结果:
#向kafka stationlog-topic中输入如下数据 001,181,182,busy,1000,10 002,182,183,fail,3000,20 001,183,184,busy,2000,30 002,184,185,busy,6000,40 001,181,183,busy,5000,50 #在SQL 客户端实时统计结果如下 sid total_duration ——————————— 002 60 001 90
Table Connector
Flink Table API和SQL编程中可以通过Table Connector连接到外部系统(数据库、KV存储、消息队列、文件系统等)用于读取和写出批数据或流数据。在Flink1.13版本之前可以通过定义Table Souce 和Table Sink来读写外部系统,Table Source负责读取外部系统数据,Table Sink 负责向外部系统写出数据。在Flink 1.13版本后,Flink推出Table Connector,不需再单独定义区分Table Source和Table Sink,只要定义了连接外部系统的Connector,都可以通过该Connector向外部系统进行读或写操作。
在FlinkTable API和SQL编程中,可以通过“CREATE TABLE ...WITH....”语句的方式来定义Table Connector,在该语句中可以非常方便的定义表名称、指定主键、定义时间属性、数据类型(CSV、Avro、Parquet、ORC等)及连接外部系统的配置项,通过Table Connector来操作外部系统也是Flink新版本推荐使用的方式。下面对常用的Table Connector使用方式一一进行介绍。
Filesystem Connector
Filesystem Connector用于连接外部文件系统进行读取和写出操作。使用之前需要在项目中导入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
Filesystem Connector使用方式如下:
CREATE TABLE MyUserTable ( column_name1 INT, column_name2 STRING, ... part_name1 INT, part_name2 STRING ) PARTITIONED BY (part_name1, part_name2) WITH ( 'connector' = 'filesystem', -- 必须项:指定connector 'path' = 'file:///path/to/whatever', -- 必须项:指定路径 'format' = '...', -- 必须项:执行文件格式 ... )
Filesystem Connector支持对分区文件的访问,以上“PARTITIONED BY...”是指定了按照哪些列对数据进行了分区操作;配置参数中path可以指定本地文件系统或者分布式文件系统;format指定读取或者写出文件的格式,支持csv、json、avro、parquet、orc等常见格式。
当使用Filesystem Connector作为Source读取外部系统数据时默认情况是取有界数据,可以读取单个文件或者整个目录中的文件数据,读取完数据后就会停止。也可以通过设置“source.monitor-interval”属性来开启目录监控,当目录中有新文件时做到实时读取数据文件。Filesystem Connector作为Sink将数据写出到外部系统时支持实时写出。
下面通过一个案例来学习Filesystem Connector的使用,该案例通过Table Connector读取文件系统数据并写出到文件系统。由于Java代码和Scala类似,这里只给出Java代码。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//将Table写出文件中必须设置checkpoint,Flink SQL 中设置checkpoint的间隔
tableEnv.getConfig().getConfiguration().setLong("execution.checkpointing.interval", 5000L);
//读取文件系统日志数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table CsvSourceTable (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'filesystem'," +
" 'path' = 'file:///D:/data/flinksource'," +
" 'format' = 'csv'," +
" 'csv.field-delimiter' = ','" +
")");
//通过SQL DDL方式定义文件系统表
tableEnv.executeSql("" +
"create table CsvSinkTable (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" rowtime TIMESTAMP_LTZ(3)" +
") with (" +
" 'connector' = 'filesystem'," +
" 'path' = 'file:///D:/data/flinksink'," +
" 'sink.rolling-policy.check-interval' = '2s'," +
" 'sink.rolling-policy.rollover-interval' = '10s'," +
" 'format' = 'csv'," +
" 'csv.field-delimiter' = '|'" +
")");
//SQL方式将数据写入文件系统
tableEnv.executeSql("" +
"insert into CsvSinkTable " +
"select sid,call_out,call_in,call_type,call_time,duration,rowtime " +
"from CsvSourceTable ");
以上代码中定义“CsvSinkTable”时指定了文件滚动策略,如果Source是实时读取外部系统数据写入到文件系统时,通过该策略可以看到数据文件会周期生成,并且还需设置checkpoint。
代码运行之前首先在“D:/data/filesource”目录中创建文件并写入如下数据:
001,181,182,busy,1000,10 002,182,183,fail,3000,20 001,183,184,busy,2000,30 002,184,185,busy,6000,40 001,181,183,busy,5000,50 003,181,182,busy,7000,10 002,182,183,fail,9000,20 001,183,184,busy,11000,30
然后启动代码执行,可以看到在“D:/data/filesink”目录中生成结果文件,内容如下:
"001"|"181"|"182"|"busy"|1000|10|"1970-01-01 00:00:01Z" "002"|"182"|"183"|"fail"|3000|20|"1970-01-01 00:00:03Z" "001"|"183"|"184"|"busy"|2000|30|"1970-01-01 00:00:02Z" "002"|"184"|"185"|"busy"|6000|40|"1970-01-01 00:00:06Z" "001"|"181"|"183"|"busy"|5000|50|"1970-01-01 00:00:05Z" "003"|"181"|"182"|"busy"|7000|10|"1970-01-01 00:00:07Z" "002"|"182"|"183"|"fail"|9000|20|"1970-01-01 00:00:09Z" "001"|"183"|"184"|"busy"|11000|30|"1970-01-01 00:00:11Z"
Kafka Connector
Kafka Connector支持从Kafka topic中实时消费和写入数据。使用之前需要在项目中导入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
Kafka Connector使用通用方式如下:
CREATE TABLE KafkaTable ( `user_id` BIGINT, `item_id` BIGINT, `behavior` STRING, `ts` TIMESTAMP(3) METADATA FROM 'timestamp' ) WITH ( 'connector' = 'kafka', 'topic' = 'user_behavior', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv' )
还可以通过Kafka Connector获取元数据列(topic、partition、offset、timestamp等)使用方式如下:
CREATE TABLE KafkaTable ( `event_time` TIMESTAMP(3) METADATA FROM 'timestamp', `partition` BIGINT METADATA VIRTUAL, `offset` BIGINT METADATA VIRTUAL, `user_id` BIGINT, `item_id` BIGINT, `behavior` STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'user_behavior', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'earliest-offset', 'sink.semantic' = 'exactly-once', 'key.format' = 'csv', 'key.fields' = 'item_id', 'value.fields-include' = 'EXCEPT_KEY', 'value.format' = 'csv' );
注意以上Kafka Connector中指定的配置项只是为了引出每个配置项的作用,在实际开发中有些配置项只适合配置在Kafka Source或者Kafka Sink中,特此说明。对以上Kafka Connector的解释如下:
-
关于元数据
“`event_time` TIMESTAMP(3) METADATA FROM 'timestamp'”表示event_time列是从元数据列“timestamp”中转换生成;”...METADATA VIRTUAL”表示该元数据列为只读列,一些元数据列,如timestamp在Kafka Connector中是可读可写的 ,通过VIRTUAL关键字指定某些列为只读列不可写。
-
topic
指定读取或者写出topic的名称,topic可以指定为分号间隔的topic列表,如:topic-1;topic-2,表示可以从多个topic中读取数据;还可以将topic配置改成“topic-pattern”支持正则方式来匹配topic,例如 topic-pattern 设置为 test-topic-[0-9],则在Flink作业启动时,所有匹配该正则表达式的 topic(以 test-topic- 开头,以一位数字结尾)都将被 consumer 订阅。
对于topic列表和topic正则匹配目前只支持Kafka Source,不支持Kafka Sink,Sink只支持单一topic。
-
scan.startup.mode
该参数决定了Kafka consumer启动模式,可以配置如下几种方式:
-
group-offsets:默认值,从 Zookeeper/Kafka 中某个指定的消费组已提交的偏移量开始。
-
earliest-offset:从可能的最早偏移量开始。
-
latest-offset:从最末尾偏移量开始。
-
timestamp:从用户为每个 partition 指定的时间戳开始。
-
specific-offsets:从用户为每个 partition 指定的偏移量开始。
如果使用了 timestamp,必须使用另外一个配置项 scan.startup.timestamp-millis 来指定一个毫秒单位时间戳作为起始时间。
如果使用了 specific-offsets,必须使用另外一个配置项 scan.startup.specific-offsets 来为每个 partition 指定起始偏移量, 例如,选项值 partition:0,offset:42;partition:1,offset:300 表示 partition 0 从偏移量 42 开始读取数据,partition 1 从偏移量 300 开始读取数据。
-
sink.semantic
指定写出语义,需要设置checkpoint来保存状态,默认情况下该值为at-least-once语义。
-
key.format
指定读取topic或者写出topic key的格式,如果不配置则默认key为null。
-
key.fields
作为Kafka Source 读取Kafka topic 配置时,可以指定DDL语句中某列为Key列,此时需要设置value.fields-include的值为EXCEPT_KEY,否则Flink自定将该字段作为普通字段处理;作为Kafka Sink将数据写出到Kafka topic时,该值可以指定 DDL语句中某列为key值,会作为写出topic中的key写出。
-
value.fields-include
可配置ALL和EXCEPT_KEY两个配置,默认为ALL。作为KafkaSource 读取Kafka topic配置时必须将该值设置为EXCEPT_KEY;作为Kafka Sink 将数据写出到Kafka topic时,该值二选其一,表示value中是否包含key字段。
-
value.format
指定读取和写出的数据格式,也可以配置为“format”,支持csv、json、avro、parquet等常见格式。还支持debezium-json格式,这种格式支持Flink SQL 从Kafka中读取数据时读取 INSERT / UPDATE / DELETE 消息,以支持Kafka Connector表的主键。如果Kafka Connector中定义了主键,必须使用这种格式。
下面通过一个案例来学习Kafka Connector的使用,该案例通过Kafka Connector读取Kafka中数据并写出Kafka消息队列中。由于Java代码和Scala类似,这里只给出Java代码。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//Kafka Source,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table KafkaSourceTbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" key_str STRING, " + // 添加key列
" rowtime AS TO_TIMESTAMP_LTZ(call_time, 3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 't1;t2'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'key.format'='csv'," +
" 'key.fields' = 'key_str'," + // 指定key列
" 'value.fields-include' = 'EXCEPT_KEY'," +
" 'value.format' = 'csv'" +
")"
);
//定义 Kafka Sink,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table KafkaSinkTbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 't3'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'key.format' = 'csv'," +
" 'key.fields' = 'sid'," +
" 'value.format' = 'csv'," +
" 'value.fields-include' = 'ALL'" +
")");
//SQL方式将数据写入文件系统
tableEnv.executeSql("" +
"insert into KafkaSinkTbl " +
"select sid,call_out,call_in,call_type,call_time,duration " +
"from KafkaSourceTbl ");
以上代码中定义Kafka Source时指定了读取t1和t2中的数据,并在DDL语句中指定了key_str作为Kafka topic中的每条数据的key,代表输入到topic中的数据是有key的,同时在Kafka Source DDL中定义了“key.format”、“key.fields”并指定了“value.fields-include”为“EXCEPT_KEY”。代码中定义Kafka Sink ,将数据写出到t3 topic,指定数据列sid为key,并设置value包含所有列。
运行代码之前,首先创建对应的Kafka Topic:
kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic t1 --partitions 3 --replication-factor 3 kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic t2 --partitions 3 --replication-factor 3 kafka-topics.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --create --topic t3 --partitions 3 --replication-factor 3
运行代码后,向t1和t2两个topic中输入如下数据:
#向Kafka Topic t1中输入如下数据 #kafka-console-producer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic t1 --property "parse.key=true" --property "key.separator=:" key1:001,181,182,busy,1000,10 key2:002,182,183,fail,3000,20 key3:001,183,184,busy,2000,30 #向Kafka Topic t2中输入如下数据 #kafka-console-producer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic t2 --property "parse.key=true" --property "key.separator=:" key4:002,184,185,busy,6000,40 key5:001,181,183,busy,5000,50 key6:003,181,182,busy,7000,10
输入以上数据后,可以看到Kafka t3中数据如下:
#消费Kafka Topic t3中的数据 #kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic t3 --property print.key=true --property key.separator="|" 001|001,181,182,busy,1000,10 002|002,182,183,fail,3000,20 001|001,183,184,busy,2000,30 002|002,184,185,busy,6000,40 003|003,181,182,busy,7000,10 001|001,181,183,busy,5000,50
Upsert Kafka Connector
Kafka Connector 作为Kafka Source时仅支持Append 方式追加写入数据,对于变更日志流不支持写入,这时就可以使用Upsert Kafka Connector解决这一问题。Upsert kafka Connector支持以upsert的方式从Kafka topic中读取数据或者写出数据到Kafka topic。
使用UpsertKafka Connector需要在项目中导入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
定义UpsertKafka Connector时需要指定一个Primay Key主键,该主键用来判断KafkaTopic中是否存在相同主键key数据,从而决定以INSERT/UPDATE/DELETE三种模式中的哪种模式读取或者写出数据,UpsertKafka Connector使用方式如下:
CREATE TABLE pageviews_per_region ( user_region STRING, pv BIGINT, uv BIGINT, PRIMARY KEY (user_region) NOT ENFORCED ) WITH ( 'connector' = 'upsert-kafka', 'topic' = 'pageviews_per_region', 'properties.bootstrap.servers' = '...', 'key.format' = 'avro', 'value.format' = 'avro' );
如果UpsertKafka Connector作为Source时,表示对应Kafka topic中的数据流是变更日志流(Changelog Stream),每来一条数据都有指定的主键key,根据topic中是否存在该key相同的数据来决定如何处理数据,如果topic中没有该key对应的数据,该条数据就表示插入(INSERT),如果存在该key对应的数据表示覆盖相同Key对应的value数据(UPDATE),如果新数据的value为空,表示删除该条数据(DELETE)。
如果UpsertKafka Connector作为Sink时,可以将变更日志流写入到该topic中,如果遇到插入(INSERT,+I)或者更新后(UPDATE_AFTER,+U)的数据,就会直接写入到topic中,如果遇到更新前(UPDATE_BEFORE,-U)或者删除(DELETE,-D)的数据,就会撤回(Retract)消息,向Kafka中写入value为空的消息,表示对应的key的消息被删除。Flink会根据指定的主键Key对Kafka中的数据进行分区,从而保证主键key上的消息有序,相同主键key消息的更新和删除都会落在同一分区中。
在使用Upsertkafka Connector时,我们经常会将处理分析的聚合结果流(变更日志流)写入到该Connector对应的topic中,将Upsertkafka Connector作为Sink使用。当该Connector作为Source读取时,Flink会确保具有相同主键key下仅最后一条消息生效。无论作为Source或者Sink都需要指定主键key,并且在配置中必须指定“key.format”和“value.format”。
下面通过案例来演示UpsertKafka Connector作为Sink的情况。由于Java代码和Scala类似,这里只给出Java代码。在该案例中我们通过Table Connector读取Kafka数据并聚合后将结果写出到Kafka,定义Sink为UpsertKafka Connector。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//Kafka Source,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table KafkaSourceTbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(call_time, 3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 't1'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")"
);
//定义 Kafka Sink,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table KafkaSinkTbl (" +
" sid string," +
" sum_duration bigint," +
" PRIMARY KEY (sid) NOT ENFORCED" +
") with (" +
" 'connector' = 'upsert-kafka'," +
" 'topic' = 't3'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'key.format' = 'csv'," +
" 'value.format' = 'csv'" +
")");
//SQL方式将数据写入文件系统
tableEnv.executeSql("" +
"insert into KafkaSinkTbl " +
"select sid,sum(duration) as sum_duration " +
"from KafkaSourceTbl " +
"group by sid");
以上代码读取Kafka Topic t1中的数据,对数据进行聚合,将结果写出到Kafka Topic 3中。代码运行后,向Kafka Topic t1中输入如下数据:
#kafka-console-producer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic t1 001,181,182,busy,1000,10 002,182,183,fail,3000,20 001,183,184,busy,2000,30 002,184,185,busy,6000,40 001,181,183,busy,5000,50
可以看到Kafka Topic t3中结果如下,可以看到针对写入的变更日志流,结果中只有插入和更新后的数据。
#kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic t3 001,10 002,20 001,40 002,60 001,90
JDBC Connector
JDBC Connector 允许使用JDBC驱动向任意类型的关系型数据库读取或者写入数据,例如:MySQL、Oracle、PostgreSQL、Derby、SQL Server。JDBC Connector可以作为Source或者Sink读写关系型数据库。使用JDBC Connector时,需要在项目中导入如下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>${flink-connector-jdbc.version}</version>
</dependency>
根据读取或者写出的关系型数据库不同还需要在项目中导入对应的数据库驱动依赖,这里以MySQL驱动为例,导入依赖如下:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
使用JDBC Connector的形式及使用方式如下:
-- 在 Flink SQL 中注册一张 MySQL 表 'users' CREATE TABLE MyUserTable ( id BIGINT, name STRING, age INT, status BOOLEAN, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://localhost:3306/mydatabase', 'table-name' = 'users' ); -- 从另一张表 "T" 将数据写入到 JDBC 表中 INSERT INTO MyUserTableSELECT id, name, age, status FROM T; -- 查看 JDBC 表中的数据 SELECT id, name, age, status FROM MyUserTable; -- JDBC 表在时态表关联中作为维表 SELECT * FROM myTopic LEFT JOIN MyUserTable FOR SYSTEM_TIME AS OF myTopic.proctime ON myTopic.key = MyUserTable.id;
JDBC Connector当作为Source时只能以有界流方式读取数据,作为Sink时可以支持批量或者实时Append/upsert方式写出数据。如果在DDL中定义了主键key,JDBC Sink将以upsert模式与外部数据库交换UPDATE/DELETE消息,否则它将以append模式与外部数据库交换消息且不支持UPDATE/DELETE消息。此外,JDBC Connector也可以作为时态表与其他表进行关联,具体参考时态表小节,这里不再过多介绍。
下面通过两个案例来演示批量和实时向JDBC Connector中写入数据案例。由于Java代码和Scala类似,这里只给出Java代码。
案例一:通过JDBC Connector读取MySQL数据并将结果写入到JDBC Connector创建的表中。
该案例中通过JDBC Connector创建读取MySQL t1和t2表形成MysqlSourceTbl和MysqlSinkTbl表,并且MysqlSourceTbl表没有指定主键,MysqlSinkTbl表指定了主键,最终读取MysqlSourceTbl表数据写出到MysqlSinkTbl表中,相同主键的数据会在MysqlSinkTbl表中自动进行upsert操作。
首先在MySQL中创建t1和t2表,并向t1表中插入如下数据:
#mysql中创建t1和t2表 create table t1 (id int ,name varchar(255),age int) ; create table t2 (id int primary key ,name varchar(255),age int ); #向表t1中插入数据 insert into t1 values (1,'zs',18),(2,'ls',19),(3,'ww',20),(1,'zs',30),(3,'ww',31);
编写代码如下:
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//MySQL Source,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table MysqlSourceTbl (" +
" id int," +
" name string," +
" age int" +
") with (" +
" 'connector' = 'jdbc'," +
" 'url' = 'jdbc:mysql://node2:3306/mydb?useSSL=false'," +
" 'table-name' = 't1'," +
" 'username' = 'root'," +
" 'password' = '123456'" +
")"
);
//MySQL Sink ,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table MysqlSinkTbl (" +
" id int," +
" name string," +
" age int," +
" PRIMARY KEY(id) NOT ENFORCED " +
") with (" +
" 'connector' = 'jdbc'," +
" 'url' = 'jdbc:mysql://node2:3306/mydb?useSSL=false'," +
" 'table-name' = 't2'," +
" 'username' = 'root'," +
" 'password' = '123456'" +
")"
);
//SQL方式将数据写入sink表中
tableEnv.executeSql("" +
"insert into MysqlSinkTbl " +
"select id,name,age " +
"from MysqlSourceTbl"
);
以上代码执行后,读取MySQL中数据是以有界方式进行,所以读取完数据后会自动停止。代码执行完成后,查看MySQL t2表中数据如下,可以看到相同主键数据进行了替换。
#select * from t2 +----+------+------+ | id | name | age | +----+------+------+ | 1 | zs | 30 | | 2 | ls | 19 | | 3 | ww | 31 | +----+------+------+
案例二:通过Kafka Connecotr读取Kafka变更日志流数据并将结果写入到JDBC Connector创建的表中。
该案例中通过Kafka Connector创建KafkaSourceTbl表,通过JDBC Connector读取mysql t2表形成MysqlSinkTbl表并指定主键。读取KafkaSourceTbl表数据写出到MysqlSinkTbl表中,后续会向Kafka中写入变更日志流,包括更新和删除数据,可以看到MysqlSinkTbl表相同主键的数据会upsert/delete操作。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//读取Kafka 数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table KafkaSourceTbl (" +
" id int," +
" name string," +
" age int," +
" PRIMARY KEY(id) NOT ENFORCED" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 't1'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'debezium-json'" +
")");
//MySQL Sink ,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table MysqlSinkTbl (" +
" id int," +
" name string," +
" age int," +
" PRIMARY KEY(id) NOT ENFORCED " +
") with (" +
" 'connector' = 'jdbc'," +
" 'url' = 'jdbc:mysql://node2:3306/mydb?useSSL=false'," +
" 'table-name' = 't2'," +
" 'username' = 'root'," +
" 'password' = '123456'" +
")"
);
//SQL方式将数据写入sink表中
tableEnv.executeSql("" +
"insert into MysqlSinkTbl " +
"select id,name,age " +
"from KafkaSourceTbl"
);
代码编写完成启动前,首先在MySQL中清空t2表中数据,代码启动后向Kafka Topic t1中输入如下数据:
#清空mysql t2表数据
mysql> delete from t2 where id is not null;
#向Kafka t1中输入如下debezium-json格式数据
{"before": null,"after": {"id": 1,"name": "zs","age": 18},"op": "c"}
{"before": null,"after": {"id": 2,"name": "ls","age": 19},"op": "c"}
{"before": null,"after": {"id": 3,"name": "ww","age": 20},"op": "c"}
{"before": {"id": 1,"name": "zs","age": 18},"after": {"id": 1,"name": "zs","age": 30},"op": "u"}
{"before": {"id": 2,"name": "ls","age": 19},"after": {"id": 2,"name": "ls","age": 31},"op": "u"}
{"before": {"id": 3,"name": "ww","age": 20},"after": null,"op": "d"}
可以看到代码执行程序会读取Kafka中数据实时写入到MySQL中,输入以上数据后可以查询MySQL表t2中的结果如下,可以看到针对变更日志数据,有主键的t2表进行了相同主键的更新和删除操作。
#select * from t2 +----+------+------+ | id | name | age | +----+------+------+ | 1 | zs | 30 | | 2 | ls | 31 |
HBase Connector
HBase Connector支持Flink向HBase读取或者写出数据。在Flink中使用HBase Connnector时需要导入对应依赖,目前Flink官方只针对HBase1.4.x和2.2.x版本提供了Connector支持,可以根据自己使用HBase版本导入对应依赖。
HBase 1.4.x对应的HBase Connector依赖包:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-1.4</artifactId>
<version>${flink.version}</version>
</dependency>
HBase 2.2.x对应的HBase Connector依赖包:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hbase-2.2</artifactId>
<version>${flink.version}</version>
</dependency>
与JDBC Connector的使用方式类似,HBase Connector当作为Source时只能以有界流方式读取HBase数据,作为Sink时可以支持批量或者实时Append/upsert方式写出数据到Hbase中。使用HBase Connector的形式如下:
-- 在 Flink SQL 中注册 HBase 表 "mytable" CREATE TABLE hTable ( rowkey INT, family1 ROW<q1 INT>, family2 ROW<q2 STRING, q3 BIGINT>, family3 ROW<q4 DOUBLE, q5 BOOLEAN,q6 STRING>, PRIMARY KEY (rowkey) NOT ENFORCED ) WITH ( 'connector' = 'hbase-1.4', 'table-name' = 'mytable', 'zookeeper.quorum' = 'localhost:2181' ); -- 用 ROW(...) 构造函数构造列簇,并往 HBase 表写数据。 -- 假设 "T" 的表结构是 [rowkey, f1q1, f2q2, f2q3, f3q4, f3q5, f3q6] INSERT INTO hTable SELECT rowkey, ROW(f1q1), ROW(f2q2, f2q3), ROW(f3q4, f3q5, f3q6) FROM T; -- 从 HBase 表扫描数据 SELECT rowkey, family1.q1, family3.q4, family3.q6 FROM hTable; -- temporal join HBase 表,将 HBase 表作为维表 SELECT * FROM myTopic LEFT JOIN hTable FOR SYSTEM_TIME AS OF myTopic.proctime ON myTopic.key = hTable.rowkey;
在Flink SQL中通过DDL定义HBase Connector时需要指定主键key,主键只能基于HBase的rowkey字段定义,如上所示“rowkey INT”就是HBase中的主键,但在DDL中该列名称不一定叫rowkey,如果在DDL中没有声明主键key,HBase Connector默认也是获取rowkey作为主键。
所有HBase表的列族必须定义为ROW类型,字段名必须和HBase表中列族名称一样,ROW中嵌套的字段名对应列族中的列,在定义HBase Connector时,我们不需要将HBase表中所有列族及列都在Flink SQL中声明出来,只需要把用到的列族及列声明出来即可。除了Row类型的列,DDL中其他的字段将被识别为HBase的rowkey,一张表中只能定义一个rowkey。此外,HBase Connector也可以作为时态表与其他表进行关联,具体参考时态表小节,这里不再过多介绍。
下面通过两个案例来演示批量和实时向HBase Connector中写入数据案例。由于Java代码和Scala类似,这里只给出Java代码。
案例一:通过HBase Connector读取HBase数据并将结果写入到HBase Connector创建的表中。
在该案例中通过HBase Connector读取HBase t1数据并写入到t2表中。这里首先需要在HBase中创建t1和t2表并向t1表中插入数据,操作如下:
#启动HDFS和HBase,创建表并插入数据 create 't1','cf1','cf2' create 't2','family1','family2' #向HBase表t1中插入如下数据 put 't1','rk1','cf1:id',1 put 't1','rk1','cf1:name','zs' put 't1','rk1','cf1:age',18 put 't1','rk1','cf2:score',100 put 't1','rk2','cf1:id',2 put 't1','rk2','cf1:name','ls' put 't1','rk2','cf1:age',19 put 't1','rk2','cf2:score',200 put 't1','rk3','cf1:id',3 put 't1','rk3','cf1:name','ww' put 't1','rk3','cf1:age',20 put 't1','rk3','cf2:score',300 #查询HBase表t1中的数据 hbase:10:0> scan 't1' ROW COLUMN+CELL rk1 column=cf1:age, value=18 rk1 column=cf1:id, value=1 rk1 column=cf1:name, value=zs rk1 column=cf2:score, value=100 rk2 column=cf1:age, value=19 rk2 column=cf1:id, value=2 rk2 column=cf1:name, value=ls rk2 column=cf2:score, value=200 rk3 column=cf1:age, value=20 rk3 column=cf1:id, value=3 rk3 column=cf1:name, value=ww rk3 column=cf2:score, value=300
注意:HBase本身是一个"schema-less"(无模式)数据库,以上通过HBase 客户端向HBase表t1中插入数据时,无论你插入的数据是整数、字符串还是其他类型,HBase都将其存储为字节数组,在scan扫描查询时将字节数组转换为了可读的字符串形式。
案例一对应代码如下:
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//HBase Source,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table HBaseSourceTbl (" +
" rk string," +
" cf1 ROW<id string, name string,age string>," +
" cf2 ROW<score string>," +
" PRIMARY KEY(rk) NOT ENFORCED " +
") with (" +
" 'connector' = 'hbase-2.2'," +
" 'table-name' = 't1'," +
" 'zookeeper.quorum' = 'node3:2181,node4:2181,node5:2181'" +
")"
);
//HBase Sink ,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table HBaseSinkTbl (" +
" rk string," +
" family1 ROW<id int, name string,age int>," +
" family2 ROW<score double>," +
" PRIMARY KEY (rk) NOT ENFORCED " +
") with (" +
" 'connector' = 'hbase-2.2'," +
" 'table-name' = 't2'," +
" 'zookeeper.quorum' = 'node3:2181,node4:2181,node5:2181'" +
")"
);
//SQL方式将数据写入sink表中
Table table = tableEnv.sqlQuery("select " +
"rk," +
"CAST(cf1.id AS INT) as id ," +
"cf1.name as name," +
"CAST(cf1.age AS INT) as age ," +
"CAST(cf2.score AS DOUBLE) as score " +
"from HBaseSourceTbl");
tableEnv.executeSql("" +
"insert into HBaseSinkTbl " +
"select rk, ROW(id,name,age) as family1 ,ROW(score) as family2 from " + table
);
以上代码中,HBase Connector读取HBase t1表时,各个列族下的数据类型都设置为了string类型,再向t2表中写出数据时进行了对应类型的转换。代码执行完成后,可以通过HBase 客户端查询HBase t2表中的数据如下:
hbase:12:0> scan 't2' ROW COLUMN+CELL rk1 column=family1:age, value=\x00\x00\x00\x12 rk1 column=family1:id, value=\x00\x00\x00\x01 rk1 column=family1:name, value=zs rk1 column=family2:score, value=@Y\x00\x00\x00\x00\x00\x00 rk2 column=family1:age, value=\x00\x00\x00\x13 rk2 column=family1:id, value=\x00\x00\x00\x02 rk2 column=family1:name, value=ls rk2 column=family2:score, value=@i\x00\x00\x00\x00\x00\x00 rk3 column=family1:age, value=\x00\x00\x00\x14 rk3 column=family1:id, value=\x00\x00\x00\x03 rk3 column=family1:name, value=ww rk3 column=family2:score, value=@r\xC0\x00\x00\x00\x00\x00
案例二:通过Kafka Connector读取Kafka中变更日志流数据,将数据写入到HBase Connector创建的表中。
在该案例中我们通过Kafka Connector读取Kafka中变更日志流,将数据写出到HBase Connector对应的HBase表中。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//读取Kafka 数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table KafkaSourceTbl (" +
" id int," +
" name string," +
" age int," +
" score double," +
" PRIMARY KEY(id) NOT ENFORCED" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 't1'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'debezium-json'" +
")");
//HBase Sink ,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table HBaseSinkTbl (" +
" rk string," +
" family1 ROW<id int, name string,age int>," +
" family2 ROW<score double>," +
" PRIMARY KEY (rk) NOT ENFORCED " +
") with (" +
" 'connector' = 'hbase-2.2'," +
" 'table-name' = 't2'," +
" 'zookeeper.quorum' = 'node3:2181,node4:2181,node5:2181'" +
")"
);
//SQL方式将数据写入sink表中
tableEnv.executeSql("" +
"insert into HBaseSinkTbl " +
"select " +
" cast(id as string) as rk," +
" ROW(id,name,age) as family1," +
" ROW(score) as family2 " +
"from KafkaSourceTbl"
);
运行以上代码之前首先需要删除HBase表t2并重建,然后启动代码,向Kafka Topic t1中输入“debezium-json”格式数据,具体如下:
#删除HBase t2表并重建
hbase:13:0> disable 't2
hbase:14:0> drop 't2'
hbase:15:0> create 't2','family1','family2'
#向Kafka Topic t1中输入如下数据
#kafka-console-producer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic t1
{"before": null,"after": {"id": 1,"name": "zs","age": 18,"score":100.0},"op": "c"}
{"before": null,"after": {"id": 2,"name": "ls","age": 19,"score":200.0},"op": "c"}
{"before": null,"after": {"id": 3,"name": "ww","age": 20,"score":300.0},"op": "c"}
{"before": {"id": 1,"name": "zs","age": 18,"score":100.0},"after": {"id": 1,"name": "zhangsan","age": 18,"score":100.0},"op": "u"}
{"before": {"id": 2,"name": "ls","age": 19,"score":200.0},"after": {"id": 2,"name": "lisi","age": 19,"score":200.0},"op": "u"}
{"before": {"id": 3,"name": "ww","age": 20,"score":300.0},"after": null,"op": "d"}
可以看到以上程序启动后会实时读取Kafka中数据并写入到HBase表中,输入以上数据后,查询HBase 表t2中的数据如下,可以看到针对变更日志数据,通过HBase Connector向HBase表中写入数据时进行了相同主键的更新和删除操作。
hbase:16:0> scan 't2' ROW COLUMN+CELL 1 column=family1:age, value=\x00\x00\x00\x12 1 column=family1:id, value=\x00\x00\x00\x01 1 column=family1:name, value=zhangsan 1 column=family2:score, value=@Y\x00\x00\x00\x00\x00\x00 2 column=family1:age, value=\x00\x00\x00\x13 2 column=family1:id, value=\x00\x00\x00\x02 2 column=family1:name, value=lisi 2 column=family2:score, value=@i\x00\x00\x00\x00\x00\x00
特别注意:代码需要连接到HBase后再输入以上数据,否则会导致代码没有消费Kafka中数据,导致HBase中没有结果。
Flink与Hive集成
Apache Hive是数据仓库生态系统的核心,Flink支持与Hive集成,提供了HiveCatalog,Catalog是元数据管理中心(元数据包含数据库、表、表结构等信息)。Flink与Hive集成主要包含以下两个层面:
-
利用Flink来读写Hive表
HiveCatalog的设计提供了与 Hive 良好的兼容性,用户可以"开箱即用"的访问其已有的 Hive 数仓,不需要修改现有的 Hive Metastore,也不需要更改表的数据位置或分区。
-
Flink可以利用Hive Metastore作为持久化的Catalog
通过HiveCatalog可以将不同会话的Flink元数据存储到Hive Metastore中,这样我们可以将Flink中创建的表(如:Kafka Connector 表)持久化到Hive Metastore中,在不同的Flink作业会话中不需在重复创建,直接查询就可以。
目前Flink支持Hive的最低版本为2.3.0,最高版本为3.1.3,Flink想要与Hive进行集成需要在项目中引入如下依赖:
<!-- Flink Hive 集成所需依赖包 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Hive 依赖包 -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
</exclusion>
</exclusions>
</dependency>
导入依赖时需要注意需要将“log4j-slf4j-impl”从hive-exec中排除,否则会和项目中已有的“log4j-to-slf4j”造成冲突。
Hive Catalog
对应以上集成的两个层面,HiveCatalog可以处理两种表:Hive兼容表和通用表。
-
Hive兼容表是指存储层的元数据和数据都以Hive兼容的方式存储的表,通过 Flink 创建的兼容 Hive 的表可以从 Hive 端查询。
-
通用表是Flink特有的,当通过HiveCatalog创建通用表时,我们只是使用Hive Metastore 来持久化存储元数据,虽然这些表可以对Hive可见,但是无法在Hive中直接查询这些表,否则会导致未知错误。
Flink与Hive集成时需要首先创建HiveCatalog,创建Catalog可以通过两种方式:代码或者SQL方式。
-
代码方式创建HiveCatalog
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive";//catalog name
String defaultDatabase = "default";//default database
String hiveConfDir = "D:\\idea_space\\MyFlinkCode\\hiveconf";//Hive配置文件目录,Flink读取Hive元数据信息需要
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tableEnv.registerCatalog("myhive", hive);
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");
-
SQL方式创建HiveCatalog
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//SQL 方式创建 Hive Catalog
tableEnv.executeSql("CREATE CATALOG myhive WITH (" +
" 'type'='hive'," +//指定Catalog类型为hive
" 'default-database'='default'," +//指定默认数据库
" 'hive-conf-dir'='D:\\idea_space\\MyFlinkCode\\hiveconf'" +//指定Hive配置文件目录,Flink读取Hive元数据信息需要
")");
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");
以上两种方式都可以创建HiveCatalog,都需要指定hive配置文件目录,并将Hive客户端的hive-site.xml文件放在该目录中,以便Flink可以连接到Hive。当创建好HiveCatalog之后就可以在代码中使用该HiveCatalog,进而创建Hive兼容表和通用表,下面分别介绍HiveCatalog支持的这两类表。
Hive兼容表
Hive兼容表可以是Hive中预先创建出来的表,通过Flink SQL读取Hive表数据;也可以通过Flink SQL创建的Hive兼容表。两种都可以在Flink SQL或者Hive中进行数据读写操作。
使用FlinK SQL创建Hive兼容表时,需要在Flink代码中切换到“Hive 方言 ”,所谓Hive 方言就是支持Flink SQL中使用Hive语法编写SQL语句。Flink目前支持两种SQL方言:default和hive,默认使用default,即Flink 默认方言。如果使用Flink SQL 客户端可以通过以下方式来设置使用Hive方言:
Flink SQL> SET table.sql-dialect = hive; -- 使用 Hive 方言 [INFO] Session property has been set. Flink SQL> SET table.sql-dialect = default; -- 使用 Flink 默认 方言 [INFO] Session property has been set.
如果使用代码编程方式可以如下方式设置使用Hive方言:
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode(); TableEnvironment tableEnv = TableEnvironment.create(settings); // 设置使用Hive方言 tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE); // 设置使用Flink默认方言 tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
值得特别注意的是从Flink1.15版本开始,如果想要使用Hive方言必须在项目中导入“flink-table-planner_2.12-xxx.jar”依赖包并同时将“flink-table-planner-loader-xxx.jar”依赖注释掉,否则将抛出 ValidationException异常,如下错误:
Exception in thread "main" org.apache.flink.table.api.ValidationException: Could not find any factory for identifier 'hive' that implements 'org.apache.flink.table.planner.delegation.DialectFactory' in the classpath.
导入依赖如下:
<!-- Flink Table Planner 依赖包 -->
<!-- <dependency>-->
<!-- <groupId>org.apache.flink</groupId>-->
<!-- <artifactId>flink-table-planner-loader</artifactId>-->
<!-- <version>${flink.version}</version>-->
<!-- </dependency>-->
<!-- 该依赖包替换 flink-table-planner-loader 依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
注意:如果不使用Hive兼容表建议在项目中导入“flink-table-planner-loader-xxx.jar”依赖包,Flink1.15版本后,如果使用Hive兼容表使用“flink-table-planner_2.12-xxx.jar”替代“flink-table-planner-loader-xxx.jar”依赖包。下面分别演示Flink SQL操作Hive中创建的Hive兼容表及Flink SQL创建Hive兼容表操作。
1. Flink SQL操作Hive中创建的Hive兼容表
首先在Hive中创建hive_tbl表,并向表中插入数据,方便后续从Hive中查询数据。
#在Hive中创建表并插入数据 hive> create table hive_tbl (id int,name string,age int) row format delimited fields terminated by '\t'; hive> insert into hive_tbl values (1,'zs',18),(2,'ls',19),(3,'ww',20); #查询Hive hive_tbl中的数据 hive> select * from hive_tbl; 1 zs 18 2 ls 19 3 ww 20
注意:在Hive客户端执行SQL语句时,默认Hive的日志级别不输出INFO级别的日志到控制台,但由于一些节点配置了HADOOP_CLASSPATH环境变量,影响了Hive日志默认输出级别,导致INFO日志会输出到Hive 客户端控制台,这时可以在HIVE_HOME/conf/目录中创建log4j.properties文件,并设置Hive日志输出级别即可:
log4j.rootLogger=ERROR,CA log4j.appender.CA=org.apache.log4j.ConsoleAppender log4j.appender.CA.layout=org.apache.log4j.PatternLayout log4j.appender.CA.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
其次,如果想要在IDEA中编写代码连接到Hive还需要将Hive客户端的hive-site.xml文件放在本地某个目录中,以便编写Flink代码时找到Hive。这里在Flink项目中创建hiveconf目录,并将hive-site.xml文件放入到该目录下。
最后,编写Flink SQL连接Hive操作Hive表代码。
-
Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
String name = "myhive";//catalog name
String defaultDatabase = "default";//default database
String hiveConfDir = "D:\\idea_space\\MyFlinkCode\\hiveconf";//Hive配置文件目录,Flink读取Hive元数据信息需要
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir);
tableEnv.registerCatalog("myhive", hive);
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");
//查询Hive中的表
tableEnv.executeSql("show tables").print();
//向Hive中的表插入数据
tableEnv.executeSql("insert into hive_tbl values (4,'ml',21),(5,'t1',22),(6,'gb',23)");
//查询Hive中表的数据
tableEnv.executeSql("select * from hive_tbl").print();
-
Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
val name = "myhive" //catalog name
val defaultDatabase = "default" //default database
val hiveConfDir = "D:\\idea_space\\MyFlinkCode\\hiveconf" //Hive配置文件目录,Flink读取Hive元数据信息需要
val hive = new HiveCatalog(name, defaultDatabase, hiveConfDir)
tableEnv.registerCatalog("myhive", hive)
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive")
//查询Hive中的表
tableEnv.executeSql("show tables").print()
//向Hive中的表插入数据
tableEnv.executeSql("insert into hive_tbl values (4,'ml',21),(5,'t1',22),(6,'gb',23)")
//查询Hive中表的数据
tableEnv.executeSql("select * from hive_tbl").print()
以上代码通过“TableEnvironment.registerCatalog(catalog名称,HiveCatalog)”来注册了hive catalog ,并通过TableEnvironment.useCatalog(catalog名称)设置Flink 当前会话使用该Catalog,后续执行SQL查询时,都可以从Hive中获取对应的表数据。
以上代码运行后输出结果如下:
#查询Hive default库中对应的表 +------------+ | table name | +------------+ | hive_tbl | | test | +------------+ #查询Hive default.hive_tbl表中的数据 +----+-------------+--------------------------------+-------------+ | op | id | name | age | +----+-------------+--------------------------------+-------------+ | +I | 1 | zs | 18 | | +I | 2 | ls | 19 | | +I | 3 | ww | 20 | | +I | 4 | ml | 21 | | +I | 5 | t1 | 22 | | +I | 6 | gb | 23 | +----+-------------+--------------------------------+-------------+
2. Flink SQL创建Hive兼容表及操作
这种方式是直接使用FlinkSQL编写Hive语句操作Hive。需要在项目依赖中使用“flink-table-planner_2.12-xxx.jar”依赖替换“flink-table-planner-loader-xxx.jar”依赖。
-
Java代码
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//设置Hive方言
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
//SQL 方式创建 Hive Catalog
tableEnv.executeSql("CREATE CATALOG myhive WITH (" +
" 'type'='hive'," +//指定Catalog类型为hive
" 'default-database'='default'," +//指定默认数据库
" 'hive-conf-dir'='D:\\idea_space\\MyFlinkCode\\hiveconf'" +//指定Hive配置文件目录,Flink读取Hive元数据信息需要
")");
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");
//创建Hive表
tableEnv.executeSql("create table if not exists flink_hive_tbl (id int ,name string,age int) " +
"row format delimited fields terminated by '\t'");
//插入数据
tableEnv.executeSql("insert into flink_hive_tbl values (1,'zs',18),(2,'ls',19),(3,'ww',20)");
//查询数据
tableEnv.executeSql("select * from flink_hive_tbl").print();
-
Scala代码
//创建TableEnvironment
val settings: EnvironmentSettings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build()
val tableEnv: TableEnvironment = TableEnvironment.create(settings)
//设置Hive 方言
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE)
//SQL 方式创建 Hive Catalog
tableEnv.executeSql("CREATE CATALOG myhive WITH (" +
" 'type'='hive'," +//指定Catalog类型为hive
" 'default-database'='default'," +//指定默认数据库
" 'hive-conf-dir'='D:\\idea_space\\MyFlinkCode\\hiveconf'" +//指定Hive配置文件目录,Flink读取Hive元数据信息需要
")")
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive")
//创建Hive表
tableEnv.executeSql("create table if not exists flink_hive_tbl (id int ,name string,age int) " +
"row format delimited fields terminated by '\t'")
//插入数据
tableEnv.executeSql("insert into flink_hive_tbl values (1,'zs',18),(2,'ls',19),(3,'ww',20)")
//查询数据
tableEnv.executeSql("select * from flink_hive_tbl").print()
在Flink中使用了Hive方言并使用Hive SQL语法创建了Hive表进行了读写,代码执行完成后,也可以在Hive中查询到对应的表及数据。
#代码执行完成后结果 +----+-------------+--------------------------------+-------------+ | op | id | name | age | +----+-------------+--------------------------------+-------------+ | +I | 1 | zs | 18 | | +I | 2 | ls | 19 | | +I | 3 | ww | 20 | +----+-------------+--------------------------------+-------------+ #在Hive 客户端查询表flink_hive_tbl数据 hive> select * from flink_hive_tbl; 1 zs 18 2 ls 19 3 ww 20
通用表
通用表严格来说只是使用Hive Metastore来进行Flink表元数据的持久化存储,默认通过Flink SQL创建的表在当前会话中有效,如果在其他会话中使用就需要重新创建,那么通过利用Hive Metastore进行Flink表元数据持久化存储就能解决重复创建表的问题。虽然通用表对Hive可见,但不能通过Hive进行查询。
下面通过案例来创建通用表,创建通用表后,可以通过其他Flink程序进行操作该表。由于Java代码和Scala代码类似,这里只给出Java代码实现。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//SQL 方式创建 Hive Catalog
tableEnv.executeSql("CREATE CATALOG myhive WITH (" +
" 'type'='hive'," +//指定Catalog类型为hive
" 'default-database'='default'," +//指定默认数据库
" 'hive-conf-dir'='D:\\idea_space\\MyFlinkCode\\hiveconf'" +//指定Hive配置文件目录,Flink读取Hive元数据信息需要
")");
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");
//读取Kafka数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table flink_kafka_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(call_time, 3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")"
);
//通过SQL 查询表中数据
tableEnv.executeSql("select * from flink_kafka_tbl").print();
以上代码执行后,可以在Hive中查看到创建的表,但是不能进行表查询,Hive中查询表如下:
hive> show tables; ... flink_kafka_tbl ...
特别需要注意:创建的通用表数据只是利用Hive存储了元数据,并非是数据,也就是说数据并不会存储在Hive中。如以上案例中,数据还是在Kafka中并非把数据存储在了Hive中。在其他Flink程序中可以直接使用该表不需重建,新的Flink Session会话中读取该表数据时,如果想进行属性的修改可以通过Flink的中SQL提示(SQL Hints)进行修改,SQL Hints的使用语法及使用示例如下:
#SQL Hints使用语法
table_path /*+ OPTIONS(key=val [, key=val]*) */
#SQL Hints使用示例
CREATE TABLE kafka_table1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE kafka_table2 (id BIGINT, name STRING, age INT) WITH (...);
-- 覆盖查询语句中源表的选项
select id, name from kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */;
-- 覆盖 join 中源表的选项
select * from
kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t1
join
kafka_table2 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t2
on t1.id = t2.id;
所以根据以上案例,我们可以在编写新的Flink 程序直接读取表“flink_kafka_tbl”中的数据,默认是实时读取Kafka Topic stationlog-topic中的数据,从“latest-offset”位置读取,我们也可以通过SQL Hints来设置从“earliest-offset”位置读取,代码如下:
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//SQL 方式创建 Hive Catalog
tableEnv.executeSql("CREATE CATALOG myhive WITH (" +
" 'type'='hive'," +//指定Catalog类型为hive
" 'default-database'='default'," +//指定默认数据库
" 'hive-conf-dir'='D:\\idea_space\\MyFlinkCode\\hiveconf'" +//指定Hive配置文件目录,Flink读取Hive元数据信息需要
")");
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");
//通过SQL 查询表中数据
tableEnv.executeSql("select * from flink_kafka_tbl " +
"/*+ OPTIONS('scan.startup.mode'='earliest-offset') */").print();
以上代码编写完成执行后,可以看到输出的结果是从“stationlog-topic”的“earliest-offset”位置读取数据。
Flink批/流读写Hive
这里说的Flink 实时读写Hive表指定的读写Hive兼容表,也就是说Hive既会管理表元数据也会进行数据存储。在上一个小节中,我们已经演示过Flink SQL批量读取和写入数据到Hive。在Flink1.11版本开始,Flink SQL支持了实时读写Hive,这既满足了流式查询Hive数据进行分析又大大增强了Hive数仓的实时性,实现了Flink基于Hive的批流一体数据分析。
本小节不再重点介绍Flink SQL 批量方式读写Hive,重点介绍Flink SQL实时读写Hive。
Flink批/流写Hive
Flink SQL 支持批和流两种方式向Hive中写入数据,当向Hive中批写数据时,只有当写作业完成后数据才能被看见,批模式支持追加写到现有的表或者覆盖现有的表。Flink SQL向Hive中批写数据的方式如下:
# ------ INSERT INTO 将追加到表或者分区,保证数据的完整性 ------ Flink SQL> INSERT INTO mytable SELECT 'Tom', 25; # ------ INSERT OVERWRITE 将覆盖表或者分区中所有已经存在的数据 ------ Flink SQL> INSERT OVERWRITE mytable SELECT 'Tom', 25;
Flink SQL向Hive中流式写数据时,不支持“INSERT OVERWRITE”的方式覆盖表数据。Flink SQL支持实时写入普通Hive表或者分区Hive表,一般实时写入Hive表,建议写入分区表,这样方便后续的查询分析。
下面示例演示了通过FlinkSQL创建Hive分区表,并读取Kafka中的数据将实时数据插入到Hive分区表,通过该示例我们介绍下FlinkSQL实时写入Hive分区表的重点。
#设置Hive方言 SET table.sql-dialect=hive; #使用Hive语法创建Hive分区表 CREATE TABLE hive_table ( user_id STRING, order_amount DOUBLE ) PARTITIONED BY (dt STRING, hr STRING) STORED AS parquet TBLPROPERTIES ( 'partition.time-extractor.timestamp-pattern'='$dt $hr:00:00', 'sink.partition-commit.trigger'='partition-time', 'sink.partition-commit.delay'='1 h', 'sink.partition-commit.watermark-time-zone'='Asia/Shanghai', 'sink.partition-commit.policy.kind'='metastore,success-file' ); #设置Flink default方言 SET table.sql-dialect=default; #创建读取Kafka 实时表 CREATE TABLE kafka_table ( user_id STRING, order_amount DOUBLE, log_ts TIMESTAMP(3), -- 在 TIMESTAMP 列声明 watermark。 WATERMARK FOR log_ts AS log_ts - INTERVAL '5' SECOND ) WITH (...); #读取Kafka数据实时写入到Hive分区表中 INSERT INTO TABLE hive_table SELECT user_id, order_amount, DATE_FORMAT(log_ts, 'yyyy-MM-dd'), DATE_FORMAT(log_ts, 'HH') FROM kafka_table; #批次查询Hive分区表中数据 SELECT * FROM hive_table WHERE dt='2020-05-20' and hr='12';
关于以上示例中通过FlinkSQL创建了Hive分区表,分区字段为“dt”和“hr”,分区一般会按照时间进行分区,重点需要掌握创建Hive分区表的一些参数,下面分别进行介绍。
-
partition.time-extractor.timestamp-pattern
分区时间戳的抽取格式,默认为“yyyy-MM-dd HH:mm:ss”。配置该值就是指定如何从时间戳中获取分区时间字段,需要用hive表中相应的分区字段做占位符替换。举例:如果需要从时间戳中抽取多个分区字段,比如 'year'、'month'、'day' 和 'hour' ,可以配置成: '$year-$month-$day $hour:00:00';如果从时间戳中提取两个分区字段 'dt' 和 'hour' ,可以配置成:'$dt $hour:00:00'。
-
sink.partition-commit.trigger
触发分区提交的时间特征,可配置成“process-time”(默认)和“partition-time”。FlinkSQL将实时写入到Hive表中,只有分区提交了(包括元数据提交、数据提交)我们才能正确的从Hive中查询出数据。该参数就是设置是基于“process-time”(处理时间)还是基于”partition-time”(事件时间)触发分区提交。如果设置为“process-time”,表示当系统时间达到分区创建时间+“sink.partition-commit.delay”指定的延时时间后,就立即触发分区提交(sink.partition-commit.delay参数解释参考下文),这种情况下当数据有延迟时很容易造成数据混乱,所以建议将其配置为“partition-time”,即按照分区内数据对应的事件时间决定触发分区提交。
-
sink.partition-commit.delay
触发分区提交的延迟。例如:当触发分区的时间特征设置为“partition-time”时,watermark大于分区创建时间+该延迟时间时,分区才会真正的触发提交。强烈建议设置该值与分区粒度相同,如:Hive表分区按照1小时分区,该参数可以设置为“1 h”即可。
假设触发分区提交的时间特征设置为“partition-time”,每小时设置一个分区,如果不设置触发分区提交的延迟,那么每到1个小时点上,该分区一创建即会提交,例如:1970-01-01 08:00:00 时刻一到,8点分区就会触发提交,当1970-01-01 09:00:00时刻一到,9点的分区就会触发提交,这样会将8点到9点之间的数据划分到9点分区内,不符合我们的习惯,所以可以设置“sink.partition-commit.delay”来延迟触发分区提交,如果每小时设置一个分区,该延时值可以设置为1小时,当1970-01-01 08:00:00 时刻一到,不会立刻触发分区提交,而是延时1小时,当1970-01-01 09:00:00时刻一到才会提交8点分区,这样可以将8点到9点的数据划分到8点分区中,这就是为什么建议将该值设置为分区粒度一样的原因。
-
sink.partition-commit.watermark-time-zone
如果事件时间是基于TIMESTAMP_LTZ列进行设置,必须将改参数设置为本地时区,否则分区提交可能会在几小时后提交。
-
sink.partition-commit.policy.kind
分区提交的策略,即分区何时可以被下游读取。可以设置为“metastore”、“success-file”值。“metastore”表示向Hive Metastore中添加了分区元数据后,该分区就可以被下游读取;“success-file”表示在分区目录中有了“_SUCCESS”标记文件后,该分区就可以被下游读取。也可以将该值设置为“metastore,success-file”,通知满足两个条件后,该分区才可被下游读取。
此外,通过Flink SQL实时向Hive中写入数据,实际上底层就是向HDFS中写入文件,在编写Flink代码时需要设置checkpoint机制,否则文件不能正常生成。
下面通过一个案例来演示Flink SQL实时向Hive分区表中写入数据。在该案例中通过Kafka Connector创建读取Kafka中数据表,同时创建Hive分区表,将Kafka数据实时写入到Hive分区中。由于Java代码和Scala代码类似,这里只给出Java代码实现。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//设置checkpoint
tableEnv.getConfig().getConfiguration().setLong("execution.checkpointing.interval", 5000L);
//当某个并行度5秒没有数据输入时,自动推进watermark
tableEnv.getConfig().set("table.exec.source.idle-timeout","5000");
//SQL 方式创建 Hive Catalog
tableEnv.executeSql("CREATE CATALOG myhive WITH (" +
" 'type'='hive'," +//指定Catalog类型为hive
" 'default-database'='default'," +//指定默认数据库
" 'hive-conf-dir'='D:\\idea_space\\MyFlinkCode\\hiveconf'" +//指定Hive配置文件目录,Flink读取Hive元数据信息需要
")");
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");
//设置Hive方言
tableEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
//创建Hive分区表
tableEnv.executeSql("" +
"create table rt_hive_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint" +
") partitioned by (dt string,hr string,mm string,ss string) " +
"stored as parquet tblproperties (" +
" 'partition.time-extractor.timestamp-pattern'='$dt $hr:$mm:$ss'," +
" 'sink.partition-commit.trigger'='partition-time'," +
" 'sink.partition-commit.delay'='1 s'," +
" 'sink.partition-commit.watermark-time-zone'='Asia/Shanghai'," +
" 'sink.partition-commit.policy.kind'='metastore,success-file'" +
")"
);
//设置 Flink Default方言
tableEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
//读取Kafka数据,通过SQL DDL方式定义表结构
tableEnv.executeSql("" +
"create table rt_kafka_tbl (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" rowtime AS TO_TIMESTAMP_LTZ(call_time, 3)," +
" WATERMARK FOR rowtime AS rowtime - INTERVAL '2' SECOND" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'stationlog-topic'," +
" 'properties.bootstrap.servers' = 'node1:9092,node2:9092,node3:9092'," +
" 'properties.group.id' = 'testGroup'," +
" 'scan.startup.mode' = 'latest-offset'," +
" 'format' = 'csv'" +
")"
);
//将 Kafka 数据写入 Hive 分区表
tableEnv.executeSql("" +
"insert into rt_hive_tbl " +
"select sid,call_out,call_in,call_type,call_time,duration," +
" DATE_FORMAT(rowtime, 'yyyy-MM-dd') dt," +
" DATE_FORMAT(rowtime, 'HH') hr, " +
" DATE_FORMAT(rowtime, 'mm') mm, " +
" DATE_FORMAT(rowtime, 'ss') ss " +
"from rt_kafka_tbl"
);
以上代码创建了Hive分区表,分区表格式为parquet格式,除此之外,还支持Text/CSV/SequenceFile/ORC格式。分区表设置了四级分区(日、时、分、秒),并设置了”table.exec.source.idle-timeout”参数,当watermark达到分区触发提交时间时,该分区才会提交进而被下游可读。代码执行后可以看到Hive中创建了表“rt_hive_tbl”和“rt_kafka_tbl”:
hive> show tables; ... rt_hive_tbl rt_kafka_tbl ...
向Kafka Topic “stationlog-topic”中输入如下数据:
#kafka-console-producer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic statiog-topic 001,181,182,busy,1001,10 002,182,183,fail,2001,20 003,183,184,busy,3001,30 #1s对应分区提交 004,184,185,busy,4001,40 #2s对应分区提交 001,181,183,busy,5001,50 #3秒对应分区提交 001,181,183,busy,6001,50 #4秒对应分区提交 002,182,183,fail,7001,20
以上数据当输入“004,184,185,busy,4001,40”时,此刻watermark为2000,达到了“1970-01-01 08:00:01”+1s(触发分区提交延迟参数值)时刻,所以1s对应的分区会提交,以此类推,当输入“002,182,183,fail,9001,20”数据时,4s对应的分区被提交,我们可以通过HDFS WEBUI查看对应的分区结果:
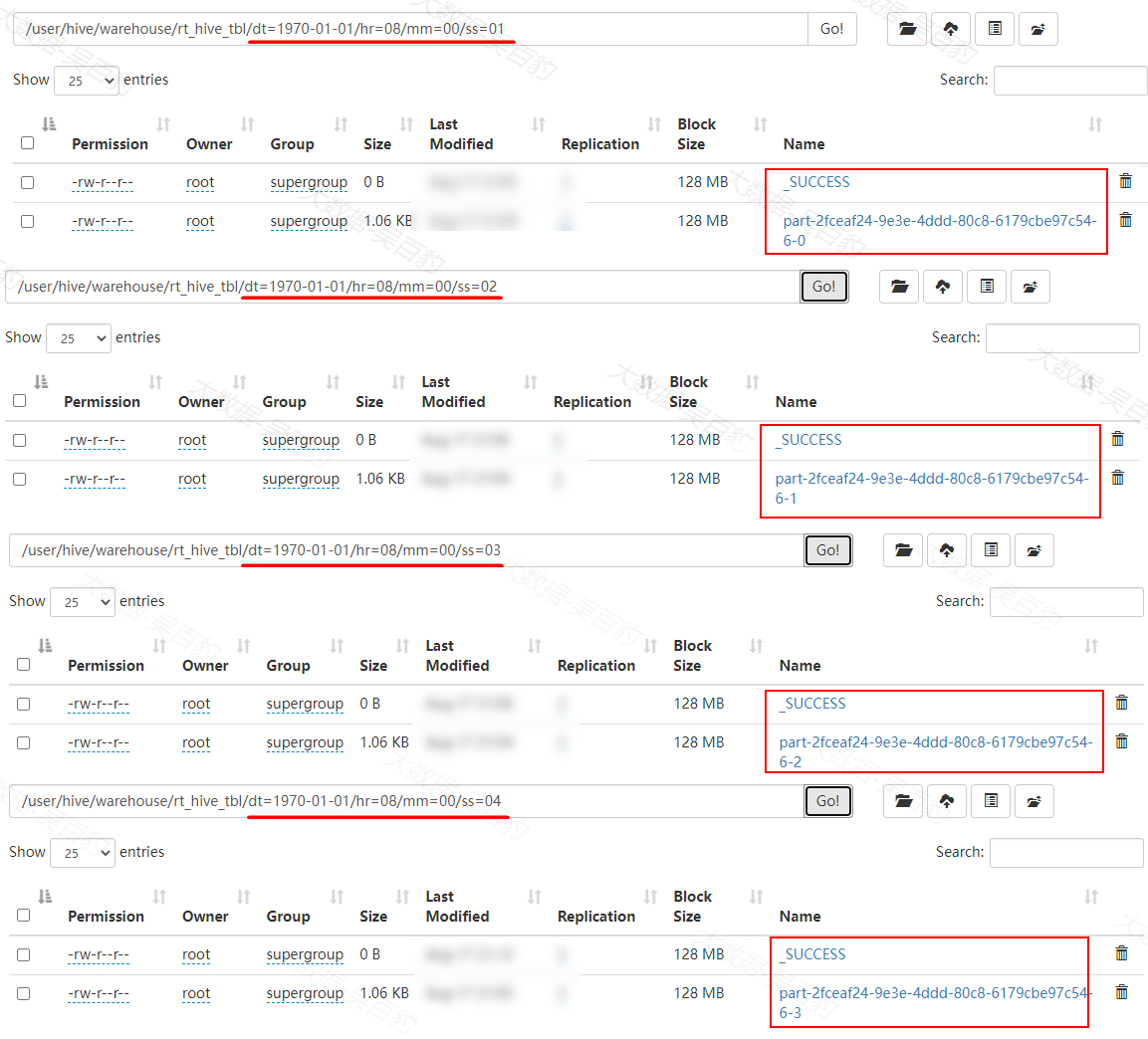
通过HDFS WebUI不仅可以看到已经提交的分区,未提交的分区(5s/6s/7s)也能通过HDFS WebUI查看的到,但是不会从这些分区中查询出来数据。同时我们可以通过Hive中查看表“rt_hive_tbl”中的分区和数据如下:
#rt_hive_tbl分区情况 hive> show partitions rt_hive_tbl; dt=1970-01-01/hr=08/mm=00/ss=01 dt=1970-01-01/hr=08/mm=00/ss=02 dt=1970-01-01/hr=08/mm=00/ss=03 dt=1970-01-01/hr=08/mm=00/ss=04 #rt_hive_tbl分区数据 hive> select * from rt_hive_tbl; 001 181 182 busy 1001 10 1970-01-01 08 00 01 002 182 183 fail 2001 20 1970-01-01 08 00 02 003 183 184 busy 3001 30 1970-01-01 08 00 03 004 184 185 busy 4001 40 1970-01-01 08 00 04
以上案中中我们设置分区级别到秒只是为了方便演示效果,在实际工作中一般不会设置到秒形成分区。
随着Flink SQL实时向Hive分区表中写入数据,小文件也会越来越多,Flink也支持自动对小文件进行合并以减少小文件带来的影响。实时场景下,我们可以设置如下参数来让Flink自动进行小文件合并:
-
auto-compaction:默认值为false。在流式Sink中是否开启自动合并功能。数据首先会被写入临时文件,当checkpoint完成后,该检查点产生的临时文件会被合并,这些临时文件在合并前不可见。
-
compaction.file-size:指定合并目标文件大小,默认值为实际情况下的滚动文件大小。
在Flink 批写数据时也有小文件问题,参数设置与实时场景不同,更多设置请参考Flink官网,这里不再介绍。
Flink批/流读Hive
FlinkSQL支持以批和流两种模式从Hive中读取数据。批读时Flink会基于查询表的状态进行查询,默认情况下Flink将以批模式读取数据,这里不再演示。流读时Flink会实时监控表,并在表中新数据可用时进行增量获取,流读支持读取Hive普通表和分区表,对于普通表Flink将会监控文件夹中新文件的生成进行增量读取,对于分区表Flink会监控新分区数据生成并增量获取新分区数据。
FlinkSQL实时读取Hive表数据可以通过SQL提示( SQL Hints)来完成,形式如下:
SELECT * FROM hive_table /*+ OPTIONS( 'streaming-source.enable'='true', 'streaming-source.monitor-interval' = '2 second', 'streaming-source.consume-start-offset'='2020-05-20' ) */;
以上OPTIONS中的参数解释如下:
-
streaming-source.enable
是否启动流读,默认false。
-
streaming-source.monitor-interval
连续监控分区/文件的时间间隔,默认情况流式读取Hive时间间隔为1分钟。
-
streaming-source.consume-start-offset
流式读取Hive起始消费的时间戳,需要只当成“yyyy-MM-dd HH:mm:ss”形式。
此外,实时读取Hive表要求每个文件必须原子性写入目标目录,如果是分区表,每个分区的元数据也应被原子性添加到Hive Metastore中,这样才能被Flink SQL 实时读取。目前流式读取Hive表不支持Flink DDL的watermark语法,这些表不能被用于窗口操作。
下面通过读取上个案例中“rt_hive_tbl”表数据为例来演示FlinkSQL 实时读取Hive表数据。由于Java代码和Scala代码类似,这里只演示Java代码实现。
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//SQL 方式创建 Hive Catalog
tableEnv.executeSql("CREATE CATALOG myhive WITH (" +
" 'type'='hive'," +//指定Catalog类型为hive
" 'default-database'='default'," +//指定默认数据库
" 'hive-conf-dir'='D:\\idea_space\\MyFlinkCode\\hiveconf'" +//指定Hive配置文件目录,Flink读取Hive元数据信息需要
")");
//将 HiveCatalog 设置为当前会话的 catalog
tableEnv.useCatalog("myhive");
//Flink SQL 方式实时读取Hive分区表数据
tableEnv.executeSql("select * from rt_hive_tbl " +
"/*+ OPTIONS(" +
" 'streaming-source.enable'='true', " +
" 'streaming-source.monitor-interval' = '2 second'," +
" 'streaming-source.consume-start-offset'='1970-01-01 08:00:00'" +
" ) " +
"*/").print();
以上代码编写完成启动后,可以看到能从hive表“rt_hive_tbl”中实时读取到“1970-01-01 08:00:00”之前的数据,如下:
+----+----+---------+--------+----------+----------+---------+-----------+----+----+---+ | op |sid |call_out |call_in |call_type |call_time |duration | dt | hr | mm |ss | +----+----+---------+--------+----------+----------+---------+-----------+----+----+---+ | +I |001 | 181 | 182 | busy | 1001 | 10 |1970-01-01 | 08 | 00 |01 | | +I |004 | 184 | 185 | busy | 4001 | 40 |1970-01-01 | 08 | 00 |04 | | +I |003 | 183 | 184 | busy | 3001 | 30 |1970-01-01 | 08 | 00 |03 | | +I |002 | 182 | 183 | fail | 2001 | 20 |1970-01-01 | 08 | 00 |02 |
然后启动上一小节中流式向Hive表“rt_hive_tbl”中写入数据的代码,继续向对应Kafka Topic“stationlog-topic”中输入如下数据:
#kafka-console-producer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic stationlog-topic 003,181,182,busy,8001,10 002,182,183,fail,9001,20 001,183,184,busy,10001,30 001,183,184,busy,11001,30 001,183,184,busy,12001,30
也能看到Hive 表”rt_hive_tbl”被实时读取,输出如下数据,由于我们没有配置checkpoint状态恢复机制,所以看不到其他部分数据从状态中恢复。
+----+----+---------+--------+----------+----------+---------+-----------+----+----+---+ | op |sid |call_out |call_in |call_type |call_time |duration | dt | hr | mm |ss | +----+----+---------+--------+----------+----------+---------+-----------+----+----+---+ | +I |002 |182 | 183 | fail | 9001 | 20 |1970-01-01 | 08 | 00 |09 | | +I |003 |181 | 182 | busy | 8001 | 10 |1970-01-01 | 08 | 00 |08 |
Flink SQL读取Hive表时,默认情况下会基于文件数量以及每个文件中块的数量来推断出读取并行度。Flink也同时允许灵活配置并发度,可以在TableConfig中配置以下参数:
-
table.exec.hive.infer-source-parallelism
如果该值为true,会根据split的数量推断source并行度;如果是fasle ,source的并行度由配置决定。默认值为true。
-
table.exec.hive.infer-source-parallelism.max
设置source operator推断的最大并行度。默认值1000。
自定义Table Connector
Flink Table 中提供了常见的Connector供用户读取和写入外部存储系统,随着Flink技术在实时领域的广泛应用,很多热门技术组件都提供了与Flink交互的Connector实现,例如:Iceberg、hudi等。但在工作中我们可能用到各种外部存储系统,如果Flink中没有提供与该外界交互的Connector ,我们还可以自定义Table Connector实现与外界系统的交互,本小节将重点介绍在Flink Table中如何自定义Table Source Connector和Table Sink Connector。
Table Connector底层逻辑
想要在Flink Table中自定义Connector需要先了解Flink Table Connector底层对象转换调用流程,下图展示了Flink Table Connector底层转换执行的逻辑。
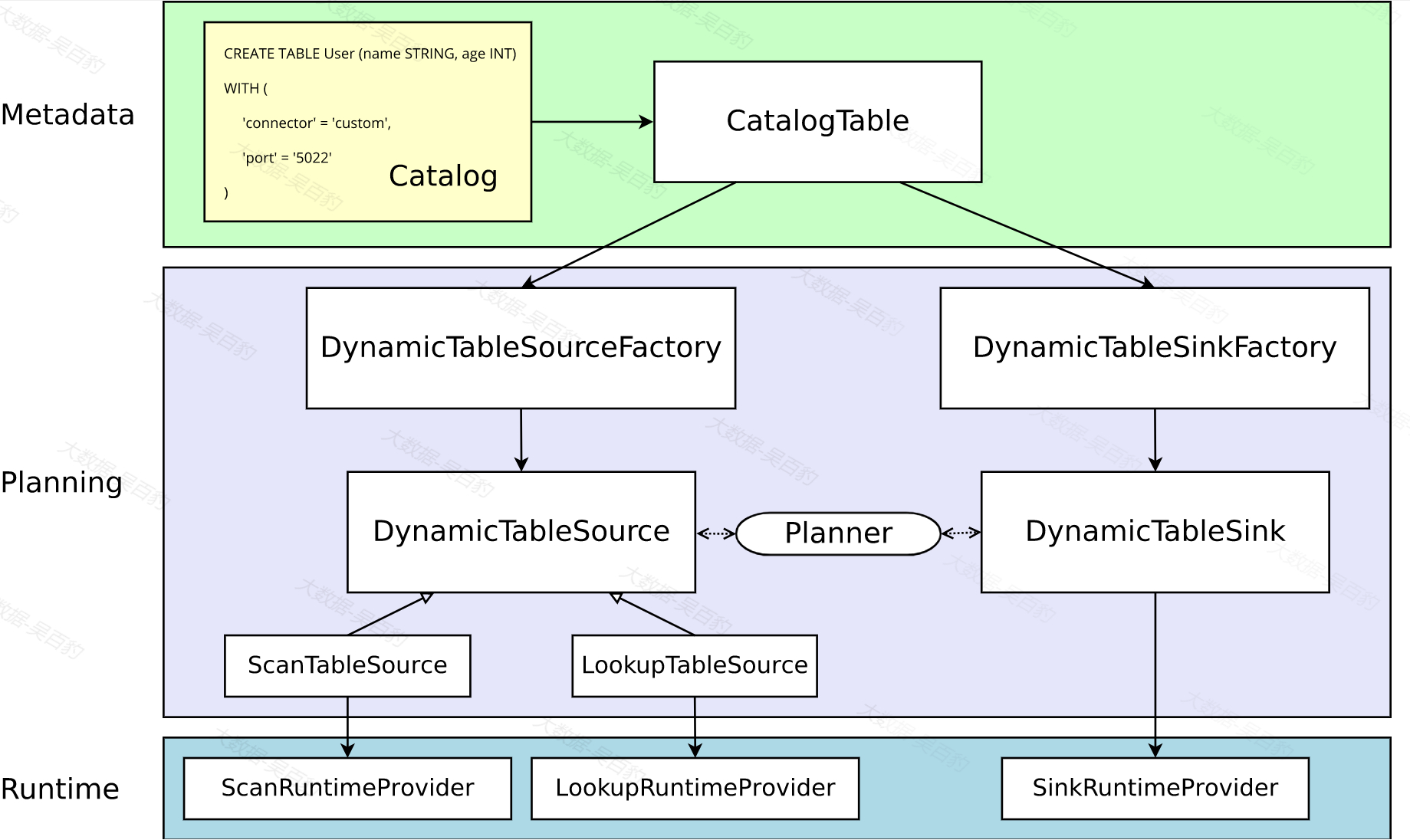
动态表是Flink Table API和SQL编程中的核心概念,当我们通过Table Connector 使用DDL方式定义一个动态表实例执行后,该DDL会被解析为CatalogTable对象,如上图所示“metadata”部分。
上图Flink 解析器解析阶段(上图planning阶段),解析和优化Table或者SQL编写的程序时,需要将CatalogTable解析为DynamicTableSource和DynamicTableSink,两者都为接口,用户需要实现对应接口完成实现逻辑,实现DynamicTableSource接口用于在SELECT 查询中读取数据,实现DynamicTableSink接口用于在INSERT INTO 语句中写入数据。对于DynamicTableSource来说比较特殊,由于Table Connector读取源头数据可以是普通数据也可以是维度数据,所以DynamicTableSource接口又包含两种实现:ScanTableSource和LookupTableSource,分别对应普通数据和维度数据源头。
palnning阶段中的DynamicTableSourceFactory和DynamicTableSinkFactory两个接口用于将CatalogTable的元数据转换为DynamicTableSource和DynamicTableSink的实例。两个工厂类中可以获取Connector中的配置进行校验,然后通过特定方法调用DynamicTableSource或者DynamicTableSink的实现类并将解析的参数、编码器一并传入。
一旦Planning规划完成后,会在runtime运行时通过一系列的provider来调用定义的Source和Sink实现类,Source和Sink实现类可以与外界系统进行交互,provider主要包含 ScanRuntimeProvider(用于调用定义的Source读取普通源数据)、LookupRuntimeProvider(用于调用定义的Source读取维度数据)、SinkRuntimeProvider(用于调用定义的Sink写出结果数据)。在用户自定义Table Connector 中,Source和Sink实现类可以通过Flink DataStream API中SourceFunction和SinkFunction接口来实现。
通过以上Flink Table Connector底层转换逻辑的学习,我们大致可以梳理出用户自定义实现Table Connector的流程:
-
首先,用户实现自定义Connector需要编写类实现org.apache.flink.table.factories.DynamicTableSourceFactory 接口和org.apache.flink.table.factories.DynamicTableSinkFactory 接口,完成对SQL DDL中的参数解析、校验,然后调用创建用户自定义的DynamicTableSource 类或者DynamicTableSink 类。
-
其次,用户需要编写类实现DynamicTableSource 接口或者DynamicTableSink 接口,在实现类中通过对应的provider调用用户自定义的SourceFunction或者SinkFunction实现类。
-
最后,用户需要编写实现类实现DataStream API中的SourceFunction和SinkFunction接口完成数据读取和数据写出实现。
通过以上三个步骤就实现了用户自定义Table Connector(包括Source Connector和SinkConnector)。特别需要注意的是DynamicTableSourceFactory 和 DynamicTableSinkFactory 的实例是使用 Java的SPI(Service Provider Interfaces)发现的,这样用户才能在Flink编程中使用用户自定义的Table Connector。关于SPI可以参考下个小节介绍。
Java SPI(扩展)
在Java中,SPI(Service Provider Interface)是一种用于实现松耦合、可扩展和可插拔式架构的机制。它允许开发人员定义一个服务接口,然后允许不同的实现提供者(服务提供者)为这个接口提供具体的实现,而这些实现可以在应用程序运行时被动态加载和替换,而无需修改主要代码。
SPI机制通常用于开发框架在不改变核心代码的情况下,允许外部模块添加功能或扩展。在Flink中自定义Connector实现就是通过SPI动态加载完成的。SPI机制工作原理如下:
-
定义接口:首先定义服务接口,该接口定义了一组操作或功能。在Flink Table Connector 中相当于Flink框架定义好的DynamicTableSourceFactory 和DynamicTableSinkFactory 接口。
-
创建实现:用户可以创建不同的实现类来实现这个服务接口,每个实现类代表了一种不同的功能或实现方式。在Flink 自定义 Table Connector中相当于自己实现DynamicTableSourceFactory 和DynamicTableSinkFactory 接口的类。
-
配置文件:在类路径的META-INF/services目录下,创建一个名为“接口全限定名”的文件。在这个文件中,列出了提供这个服务接口实现的类的全限定名。这些文件的内容通常是一行一行的实现类的名称。
-
加载与使用:在代码运行时,会通过Java的ServiceLoader类读取配置文件中的实现类名称并实例化,可以在应用程序中使用它们。
SPI机制提供了一种灵活的方式来将服务的定义与实现解耦,使得应用程序可以在不修改主要代码的情况下,根据需要轻松添加、替换或删除不同的功能模块。
自定义Source Connector
用户自定义Source Connector中,读取的外部数据可以是变更日志流或者是维度数据,针对不同数据源用户需要实现ScanTableSource或者LookupTableSource接口。
ScalnTableSource支持有界和无界方式读取外部数据,在运行中会按行扫描外部系统数据,被扫描的数据可以是INSERT/UPDATE/DELETE变更日志数据,实现 ScanTableSource 接口的类必须能够生产 Flink 内部数据结构,因此每条记录需要按照org.apache.flink.table.data.RowData 的方式进行组织返回。
相比于ScanTableSource,LookupTableSource 接口不会全量读取表中数据,只会在需要时向外部存储(其中的数据有可能会一直变化)发起查询请求,惰性地获取数据。LookupTableSource 接口目前只支持处理 insert-only 数据流。
自定义Source Connector实现
下面通过用户自定义Table Connector实现读取Socket数据为例来演示ScanTableSource使用,这里不再演示LookupTableSource 使用。步骤如下:
1) 创建SocketDynamicTableSourceFactory类实现DynamicTableSourceFactory
完整代码如下:
public class SocketDynamicTableSourceFactory implements DynamicTableSourceFactory {
// 定义所有配置项
public static final ConfigOption<String> HOSTNAME = ConfigOptions.key("hostname")
.stringType()
.noDefaultValue();
public static final ConfigOption<Integer> PORT = ConfigOptions.key("port")
.intType()
.noDefaultValue();
//设置输入socket中每行的分割符 ,默认是\n
public static final ConfigOption<Integer> BYTE_DELIMITER = ConfigOptions.key("byte-delimiter")
.intType()
.defaultValue(10); // 等同于 '\n'
/**
* 用于匹配: `connector = '...'`,必须和 `connector` 的值一致,否则会报错,找不到对应的Connector
*/
@Override
public String factoryIdentifier() {
return "socket";
}
/**
* 在Connector中必须包含的配置项
* 后续会通过 helper.validate() 方法进行校验
*/
@Override
public Set<ConfigOption<?>> requiredOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(HOSTNAME);
options.add(PORT);
options.add(FactoryUtil.FORMAT); // 解码的格式器使用预先定义的配置项
return options;
}
/**
* 在Connector中可以包含的配置项
* 后续会通过 helper.validate() 方法进行校验
*/
@Override
public Set<ConfigOption<?>> optionalOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(BYTE_DELIMITER);
return options;
}
/**
* 创建并返回 DynamicTableSource
*/
@Override
public DynamicTableSource createDynamicTableSource(Context context) {
// 使用提供的工具类或实现你自己的逻辑进行校验
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
// 校验所有的配置项
helper.validate();
// 获取校验完的配置项
final ReadableConfig options = helper.getOptions();
final String hostname = options.get(HOSTNAME);
final int port = options.get(PORT);
final byte byteDelimiter = (byte) (int) options.get(BYTE_DELIMITER);
// 创建并返回动态表 source
return new SocketDynamicTableSource(hostname, port, byteDelimiter);
}
}
该实现类中可以对DDL中定义的配置项进行解析获取。以上实现类中主要方法及解释如下:
-
factoryIdentifier()
该方法需要返回一个字符串,用于匹配DDL中 `connector = '...'`的Connector值,该字符串必须和 `connector` 的值一致,否则会报错,找不到对应的Connector。注意:Connector名称不能与已存在与Flink中的Connector名称冲突。
-
requiredOptions()
在通过DDL语言定义Connector时,必须配置的配置项。通过调用 helper.validate() 方法进行校验,缺少的配置项会报错提示。
-
optionalOptions()
在通过DDL语言定义Connector时,必须配置的配置项。通过调用 helper.validate() 方法进行校验。
-
createDynamicTableSource()
此方法是该实现类中重要的方法,主要是返回DynamicTableSource实现类。在该方法中进行DDL参数校验并返回用户自定义实现的DynamicTableSource。
2) 创建SocketDynamicTableSource类实现DynamicTableSource接口
由于这里是读取Socket中的数据,所以实现ScanTableSource接口就可以。完整代码如下:
public class SocketDynamicTableSource implements ScanTableSource {
private final String hostname;
private final int port;
private final byte byteDelimiter;
//实现类构造
public SocketDynamicTableSource(
String hostname,
int port,
byte byteDelimiter) {
this.hostname = hostname;
this.port = port;
this.byteDelimiter = byteDelimiter;
}
/**
* 设置运行期间包含的操作数据类型
*/
@Override
public ChangelogMode getChangelogMode() {
// 由Source端指定只有INSERT操作
return ChangelogMode.newBuilder()
.addContainedKind(RowKind.INSERT)
.build();
}
/**
* 获取运行时的 SourceFunction
*/
@Override
public ScanRuntimeProvider getScanRuntimeProvider(ScanContext runtimeProviderContext) {
// 创建运行时类用于提交给集群
final SourceFunction<RowData> sourceFunction = new SocketSourceFunction(
hostname,
port,
byteDelimiter);
return SourceFunctionProvider.of(sourceFunction, false);
}
/**
* 内部执行计划需要复制表源的实例,需要实现此方法
*/
@Override
public DynamicTableSource copy() {
return new SocketDynamicTableSource(hostname, port, byteDelimiter);
}
/**
* 校验元数据出错时打印到控制台的信息 - 获取 Source 信息
*/
@Override
public String asSummaryString() {
return "Socket Table Source";
}
}
以上实现类中主要方法及解释如下:
-
getChangelogMode()
设置Source中数据类型,可以包含INSERT/UPDATE_BEFORE/UPDATE_AFTER/DELETE不同操作数据类型。
-
getScanRuntimeProvider()
此方法是该实现中重要的方法,主要通过Provider调用用户的Source实现类,并设置数据源是否有边界,返回ScanRuntimeProvider。
-
copy()
该方法实在planning解析器解析阶段内部进行数据源复制用到的方法,需要实现。
-
asSummaryString()
在planning解析器解析阶段会进行元数据校验,如果出现元数据错误会在控制台打印Source信息,此方法返回的字符串信息会显示在控制台中。
3) 创建SocketSourceFunction类继承RichSourceFunction实现读取socket数据
完整代码如下:
public class SocketSourceFunction extends RichSourceFunction<RowData> {
private final String hostname;
private final int port;
private final byte byteDelimiter;
private volatile boolean isRunning = true;
private Socket currentSocket;
public SocketSourceFunction(String hostname, int port, byte byteDelimiter) {
this.hostname = hostname;
this.port = port;
this.byteDelimiter = byteDelimiter;
}
@Override
public void run(SourceContext<RowData> ctx) throws Exception {
while (isRunning) {
// 持续从 socket 消费数据
try (final Socket socket = new Socket()) {
// 保存当前 socket,以便在 cancel 时关闭
currentSocket = socket;
// 连接 socket
socket.connect(new InetSocketAddress(hostname, port), 0);
// 读取数据
try (InputStream stream = socket.getInputStream()) {
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
int b;
while ((b = stream.read()) >= 0) {
// 持续写入 buffer 直到遇到分隔符
if (b != byteDelimiter) {
buffer.write(b);
}
// 解码并处理记录
else {
//将buffer 按照逗号分割符切分,组成RowData
String value = buffer.toString();
GenericRowData genericRowData = new GenericRowData(6);
genericRowData.setField(0, StringData.fromString(value.split(",")[0]));
genericRowData.setField(1, StringData.fromString(value.split(",")[1]));
genericRowData.setField(2, StringData.fromString(value.split(",")[2]));
genericRowData.setField(3, StringData.fromString(value.split(",")[3]));
genericRowData.setField(4, Long.valueOf(value.split(",")[4]));
genericRowData.setField(5, Long.valueOf(value.split(",")[5]));
ctx.collect(genericRowData);
buffer.reset();
}
}
}
} catch (Throwable t) {
t.printStackTrace(); // 打印并继续
}
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isRunning = false;
try {
currentSocket.close();
} catch (Throwable t) {
// 忽略
}
}
}
编写自定义实现的SourceFunction时需要注意以下几点:
-
socket数据源只支持单并行度读取数据,这里继承RichSourceFunction只是告诉用户可以多并行方式读取源头数据。
-
数据返回时需要组织成RowData格式,该格式是Flink Table内部数据结构,Flink运行时会根据该对象进行数据字段转换。
4) 配置SPI动态加载的配置文件
在项目Resource资源目录中创建META-INF/services目录下,创建一个名为“org.apache.flink.table.factories.Factory”的文件,并在文件中写入自己实现SocketDynamicTableSourceFactory类的全限定名,以便代码运行时能自动加载自定义的Connector实现。
在“org.apache.flink.table.factories.Factory”文件中写入如下内容:
com.mashibing.flinkjava.code.chapter9.userdefinedconnector.source.SocketDynamicTableSourceFactory
经过以上步骤就完成了用户自定义Source Connnector读取Socket中的数据。
自定义Source Connector测试
编写如下Java代码通过DDL方式定义Socket Connector(自定义)读取Socket数据。代码如下:
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
tableEnv.executeSql("CREATE TABLE SocketSource (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") WITH (" +
" 'connector' = 'socket'," +
" 'hostname' = 'node5'," +
" 'port' = '9999'," +
" 'byte-delimiter' = '10'," +
" 'format' = 'csv'" +
");");
//打印表结构
tableEnv.executeSql("desc SocketSource").print();
//设置5秒的窗口计算
TableResult result = tableEnv.executeSql("select " +
"sid," +
"window_start," +
"window_end," +
"sum(duration) as total_dur " +
"from TABLE(" +
" TUMBLE(TABLE SocketSource,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND)" +
") " +
"group by sid,window_start,window_end");
result.print();
以上代码中connector必须指定为socket,会根据该Connector的名称匹配用户自定义的DynamicTableSourceFactory,在DDL中定义的参数可以自定义,但要符合在自定义DynamicTableSourceFactory中指定的必须配置项和可选配置项。用户自定义Table Connector中也支持watermark机制。
针对读取的Socket数据进行了滑动窗口设置,代码启动后,可以向socket-9999中输入如下数据,可以看到控制台每隔5秒输出窗口结果:
#向socket-9999中输入数据 001,181,182,busy,1000,10 002,182,183,fail,3000,20 001,183,184,busy,2000,30 002,184,185,busy,6000,40 003,181,183,busy,5000,50 #输入此条数据后会生成第一个窗口结果 001,181,182,busy,7000,10 002,182,183,fail,9000,20 001,183,184,busy,11000,30 002,184,185,busy,6000,40 #输入此条数据后会生成第二个窗口结果 003,181,183,busy,12000,50 #控制台结果 +----+----+-------------------------+-------------------------+----------+ | op |sid | window_start | window_end |total_dur | +----+----+-------------------------+-------------------------+----------+ | +I |002 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 | 20 | | +I |001 | 1970-01-01 08:00:00.000 | 1970-01-01 08:00:05.000 | 40 | | +I |003 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:10.000 | 50 | | +I |001 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:10.000 | 10 | | +I |002 | 1970-01-01 08:00:05.000 | 1970-01-01 08:00:10.000 | 100 |
自定义Sink Connector
用户自定义的Sink Connector会源源不断将数据写出到外部系统,需要通过实现DynamicTableSink接口完成,写出的数据流可以被看做是变更日志流。同样,实现 DynamicTableSink接口的类必须能够处理 Flink 内部数据结构org.apache.flink.table.data.RowData ,最终Sink数据时通过解析RowData并组织数据写出到外部系统。
自定义Sink Connector实现
下面通过用户自定义Table Connector实现将数据写出到Redis。步骤如下:
1) 创建RedisDynamicTableSinkFactory类实现DynamicTableSinkFactory
完整代码如下:
public class RedisDynamicTableSinkFactory implements DynamicTableSinkFactory {
// 定义所有配置项
public static final ConfigOption<String> HOSTNAME = ConfigOptions.key("hostname")
.stringType()
.noDefaultValue();
public static final ConfigOption<Integer> PORT = ConfigOptions.key("port")
.intType()
.noDefaultValue();
public static final ConfigOption<Integer> DBNUM = ConfigOptions.key("db-num")
.intType()
.defaultValue(0);
/**
* 用于匹配: `connector = '...'`,必须和 `connector` 的值一致,否则会报错,找不到对应的Connector
*/
@Override
public String factoryIdentifier() {
return "redis";
}
@Override
public Set<ConfigOption<?>> requiredOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(HOSTNAME);
options.add(PORT);
return options;
}
@Override
public Set<ConfigOption<?>> optionalOptions() {
//return Collections.emptySet();
final Set<ConfigOption<?>> options = new HashSet<>();
options.add(DBNUM);
return options;
}
/**
* 创建并返回 DynamicTableSource
*/
@Override
public DynamicTableSink createDynamicTableSink(Context context) {
// 使用提供的工具类或实现你自己的逻辑进行校验
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
// 校验所有的配置项
helper.validate();
// 获取校验完的配置项
final ReadableConfig options = helper.getOptions();
final String hostname = options.get(HOSTNAME);
final int port = options.get(PORT);
final int dbNum = options.get(DBNUM);
// 创建并返回动态表 Sink
return new RedisDynamicTableSink(hostname, port, dbNum);
}
}
该实现类中可以对DDL中定义的配置项进行解析获取。以上实现类中主要方法及解释如下:
-
factoryIdentifier()
该方法需要返回一个字符串,用于匹配DDL中 `connector = '...'`的Connector值,该字符串必须和 `connector` 的值一致,否则会报错,找不到对应的Connector。注意:Connector名称不能与已存在与Flink中的Connector名称冲突。
-
requiredOptions()
在通过DDL语言定义Connector时,必须配置的配置项。通过调用 helper.validate() 方法进行校验,缺少的配置项会报错提示。
-
optionalOptions()
在通过DDL语言定义Connector时,必须配置的配置项。通过调用 helper.validate() 方法进行校验。
-
createDynamicTableSink()
此方法是该实现类中重要的方法,主要是返回DynamicTableSink实现类。在该方法中进行DDL参数校验并返回用户自定义实现的DynamicTableSink。
2) 创建RedisDynamicTableSink类实现DynamicTableSink接口
完整代码如下:
public class RedisDynamicTableSink implements DynamicTableSink {
private final String host;
private final int port;
private final int dbNum;
/**
* 创建RedisSinkFunction 构造
*/
public RedisDynamicTableSink(String host,int port,int dbNum) {
this.host = host;
this.port = port;
this.dbNum = dbNum;
}
/**
* 设置运行期间包含的操作数据类型
*/
@Override
public ChangelogMode getChangelogMode(ChangelogMode requestedMode) {
// 由Source端指定只有INSERT操作
return ChangelogMode.newBuilder()
.addContainedKind(RowKind.INSERT)
.addContainedKind(RowKind.UPDATE_BEFORE)
.addContainedKind(RowKind.UPDATE_AFTER)
.build();
}
/**
* 获取运行时的 SinkFunction
*/
@Override
public SinkRuntimeProvider getSinkRuntimeProvider(Context context) {
// 创建运行时类用于提交给集群
RedisSinkFunction redisSinkFunction = new RedisSinkFunction(host, port, dbNum);
// 返回 SinkFunctionProvider
return SinkFunctionProvider.of(redisSinkFunction);
}
@Override
public DynamicTableSink copy() {
return new RedisDynamicTableSink(host, port, dbNum);
}
/**
* 校验元数据出错时打印到控制台的信息 - 获取 Sink 信息
*/
@Override
public String asSummaryString() {
return "Redis Table Sink";
}
}
以上实现类中主要方法及解释如下:
-
getChangelogMode()
设置Sink中数据类型,可以包含INSERT/UPDATE_BEFORE/UPDATE_AFTER/DELETE不同操作数据类型。
-
getSinkRuntimeProvider()
此方法是该实现中重要的方法,主要通过Provider调用用户的Sink实现类返回SinkRuntimeProvider。
-
copy()
该方法实在planning解析器解析阶段内部进行数据源复制用到的方法,需要实现。
-
asSummaryString()
在planning解析器解析阶段会进行元数据校验,如果出现元数据错误会在控制台打印Sink信息,此方法返回的字符串信息会显示在控制台中。
3) 创建RedisSinkFunction类继承RichSinkFunction实现向Redis中写入数据
完整代码如下:
public class RedisSinkFunction extends RichSinkFunction<RowData> {
private final String host;
private final int port;
private final int dbNum;
private Jedis jedis;
/**
* 创建RedisSinkFunction 构造
*/
public RedisSinkFunction(String host,int port,int dbNum){
this.host = host;
this.port = port;
this.dbNum = dbNum;
}
@Override
public void open(Configuration parameters) throws Exception {
jedis = new Jedis(host,port);
jedis.select(dbNum);
}
@Override
public void invoke(RowData rowData, Context context) throws Exception {
// 从RowData中获取数据
String sid = rowData.getString(0).toString();
String windowStart = rowData.getString(1).toString();
String windowEnd = rowData.getString(2).toString();
String totalDur = rowData.getLong(3)+"";
//Redis中数据存储格式如下:(窗口时间范围,基站ID,基站通话总时长)
jedis.hset(windowStart+"~"+windowEnd,sid,totalDur);
}
@Override
public void close() throws Exception {
jedis.close();
}
}
编写自定义实现的SinkFunction时需要从RowData格式数据解析数据写出到Ridis中。
4) 配置SPI动态加载的配置文件
在项目Resource资源目录中创建META-INF/services目录下,创建一个名为“org.apache.flink.table.factories.Factory”的文件,并在文件中写入自己实现RedisDynamicTableSinkFactory类的全限定名,以便代码运行时能自动加载自定义的Connector实现。
由于在上一小节已经创建“org.apache.flink.table.factories.Factory”文件,所以这里直接向改文件中追加写入如下内容:
com.mashibing.flinkjava.code.chapter9.userdefinedconnector.sink.RedisDynamicTableSinkFactory
经过以上步骤就完成了用户自定义Sink Connnector写出数据到Redis中。
自定义Sink Connector测试
编写如下Java代码通过DDL方式定义Redis Connector(自定义)将窗口结果数据写入到Redis中。在案例中我们通过自定义Socket Connector 来读取Socket数据并进行窗口设置,将结果写入到Ridis。代码如下:
//创建TableEnvironment
EnvironmentSettings settings = EnvironmentSettings.newInstance()
.inStreamingMode()
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//通过自定义SocketConnector创建表
tableEnv.executeSql("CREATE TABLE SocketSource (" +
" sid string," +
" call_out string," +
" call_in string," +
" call_type string," +
" call_time bigint," +
" duration bigint," +
" time_ltz AS TO_TIMESTAMP_LTZ(call_time,3)," +
" WATERMARK FOR time_ltz AS time_ltz - INTERVAL '2' SECOND" +
") WITH (" +
" 'connector' = 'socket'," +
" 'hostname' = 'node5'," +
" 'port' = '9999'," +
" 'byte-delimiter' = '10'," +
" 'format' = 'csv'" +
");");
//通过自定义RedisConnector创建表
tableEnv.executeSql("CREATE TABLE RedisSink (" +
" sid string," +
" window_start string," +
" window_end string," +
" total_dur bigint" +
") WITH (" +
" 'connector' = 'redis'," +
" 'hostname' = 'node4'," +
" 'port' = '6379'," +
" 'db-num' = '0'" +
");");
//设置5秒的窗口计算
Table result = tableEnv.sqlQuery("select " +
"sid," +
"window_start," +
"window_end," +
"sum(duration) as total_dur " +
"from TABLE(" +
" TUMBLE(TABLE SocketSource,DESCRIPTOR(time_ltz), INTERVAL '5' SECOND)" +
") " +
"group by sid,window_start,window_end");
//打印result的表结构
tableEnv.executeSql("desc " + result).print();
//将结果写入到Redis中
tableEnv.executeSql("insert into RedisSink " +
"select sid," +
"DATE_FORMAT(window_start,'yyyy-MM-dd HH:mm:ss') as window_start," +
"DATE_FORMAT(window_end,'yyyy-MM-dd HH:mm:ss') as window_end," +
"total_dur " +
"from " + result);
以上代码中sink connector必须指定为redis,会根据该Connector的名称匹配用户自定义的DynamicTableSinkFactory,在DDL中定义的参数可以自定义,但要符合在自定义DynamicTableSinkFactory中指定的必须配置项和可选配置项。
代码启动后,可以向socket-9999中输入如下数据,可以看到控制台每隔5秒结果会写入到Redis中。
#向socket-9999中输入数据 001,181,182,busy,1000,10 002,182,183,fail,3000,20 001,183,184,busy,2000,30 002,184,185,busy,6000,40 003,181,183,busy,5000,50 #输入此条数据后会生成第一个窗口结果 001,181,182,busy,7000,10 002,182,183,fail,9000,20 001,183,184,busy,11000,30 002,184,185,busy,6000,40 #输入此条数据后会生成第二个窗口结果 003,181,183,busy,12000,50 #Redis 默认0号库中查询结果 127.0.0.1:6379> keys * 1) "1970-01-01 08:00:05~1970-01-01 08:00:10" 2) "1970-01-01 08:00:00~1970-01-01 08:00:05" 127.0.0.1:6379> hgetall "1970-01-01 08:00:00~1970-01-01 08:00:05" 1) "002" 2) "20" 3) "001" 4) "40" 127.0.0.1:6379> hgetall "1970-01-01 08:00:05~1970-01-01 08:00:10" 1) "001" 2) "10" 3) "003" 4) "50" 5) "002" 6) "100"

















 2771
2771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










