



文章标题
config/build/install dpdk
dpdk super general analysis
tell you guys about why there is dpdk, is more about the reason or source of dpdk and there is no a lot technology involved just like a simple story.
reference link
dpdk super easy method just like below process
nearly the same with the flow i give you guys below, you can choose the one you like
just for comparison
reference link
1. 通用简易流程
1.安装meson
apt install meson
2.安装python3-pip
apt install python3-pip
3.Pip3安装ninja
pip3 install meson ninja
4.安装最新版meson
pip3 install --user meson
5.配置新版本的路径
export PATH=/usr/local/bin:$PATH
6.更新elftools
pip3 install pyelftools --upgrade
至此环境基本配置完成
1.在dpdk官网下载dpdk源码
2.解压下载的dpdk压缩包
tar xf dpdk-20.11.9.tar.xz
3.安装numa环境
apt-get install numactl
apt-get install libnuma-dev
5.编译dpdk
meson build
进入build目录执行
ninja
ninja install
6.编译dpdk例子程序
设置环境变量
export RTE_SDK=dpdk路径
export RTE_TARGET=x86_64-native-linux-gcc
make
7.加载uio、igb_uio和绑定网卡
modprobe uio
insmod igb_uio.ko
dpdk-devbind.py -b igb_uio 05:00.0 05:00.1
dpdk-devbind.py -s 可查看当前有哪些网卡
8.绑定大页内存
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages
mkdir /mnt/huge
mount -t hugetlbfs nodev /mnt/huge
9.运行dpdk例子程序
./l2fwd -c 0x3 -n 1 -- -p 0x3 -q 1 --no-mac-updating
./testpmd -c 0xf -n 1 -- -i --portmask=0x3 --nb-cores=1
需要注意的是igb_uio.ko已经默认不在dpdk编译中了,我使用的是19.11编出来的但是也没问题可以正常用
链接参考
link
2. dpdk api document
3. dpdk official tutorial
Compiling the DPDK Target from Source
focus on params config–>
Running Sample Applications
guide for programmer
NUMA
NUMA(Non-Uniform Memory Access),即非一致性内存访问,是一种关于多个CPU如何访问内存的架构模型,早期,在计算机系统中,CPU是这样访问内存的:
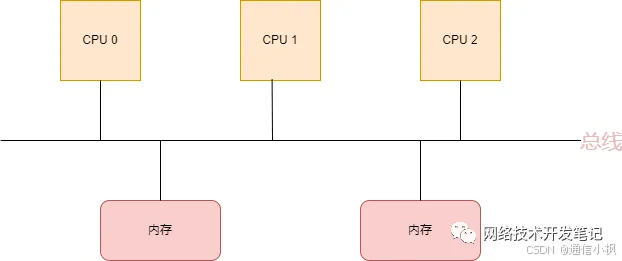
在这种架构中,所有的CPU都是通过一条总线来访问内存,我们把这种架构叫做SMP架构(Symmetric Multi-Processor),也就是对称多处理器结构。可以看出来,SMP架构有下面4个特点:
• CPU和CPU以及CPU和内存都是通过一条总线连接起来
• CPU都是平等的,没有主从关系
• 所有的硬件资源都是共享的,即每个CPU都能访问到任何内存、外设等
• 内存是统一结构和统一寻址的(UMA, Uniform Memory Architecture)
但是随着CPU多核技术的发展,一颗物理CPU中集成了越来越多的core,导致SMP架构的性能瓶颈越来越明显,因为所有的处理器都通过一条总线连接起来,因此随着处理器的增加,系统总线成为了系统瓶颈,另外,处理器和内存之间的通信延迟也较大。
为了解决SMP架构下不断增多的CPU Core导致的性能问题,NUMA架构应运而生,NUMA调整了CPU和内存的布局和访问关系,具体示意如下图:
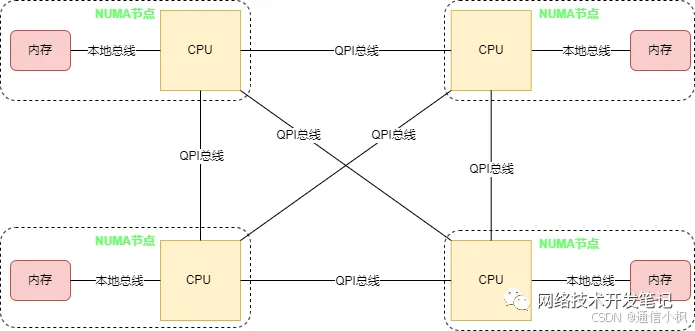
NUMA架构下的CPU和内存分布
在Linux系统上,可以查看到NUMA架构下CPU和内存的分布情况,不过在这之前,我们先得理清几个概念:
• Socket:表示一颗物理 CPU 的封装(物理 CPU 插槽),简称插槽。为了避免将逻辑处理器和物理处理器混淆,Intel 将物理处理器称为插槽,Socket表示可以看得到的真实的CPU核 。
• Core:物理 CPU 封装内的独立的一组程序执行的硬件单元,比如寄存器,计算单元等,Core表示的是在同一个物理核内逻辑层面的核。同一个物理CPU的多个Core,有自己独立的L1和L2 Cache,共享L3 Cache。
• Thread:使用超线程技术虚拟出来的逻辑 Core,需要 CPU 支持。为了便于区分,逻辑 Core 一般被写作 Processor。在具有 Intel 超线程技术的处理器上,每个内核可以具有两个逻辑处理器,这两个逻辑处理器共享大多数内核资源(如内存缓存和功能单元)。此类逻辑处理器通常称为 Thread 。超线程可以在一个逻辑核等待指令执行的间隔(等待从cache或内存中获取下一条指令),把时间片分配到另一个逻辑核。高速在这两个逻辑核之间切换,让应用程序感知不到这个间隔,误认为自己是独占了一个核。对于每个逻辑线程,拥有完整独立的寄存器集合和本地中断逻辑,共享执行单元和一二三级Cache,超线程技术可以带来20%~30%的性能提升。
• Node:即NUMA Node,包含有若干个 CPU Core 的组。
一般都是1个Node=1个Socket=多个Core=2*多个Thread
reference link
cpu的亲和性
说到这里,为什么讲着讲着dpdk讲到了cpu相关的numa架构上去呢?这是因为dpdk的线程需要绑核操作,绑核的话又涉及到了cpu的这些知识。这里分析一下cpu的亲和性。引用一下维基百科的说法,CPU亲和性就是绑定某一进程(或线程)到特定的CPU(或CPU集合),从而使得该进程(或线程)只能运行在绑定的CPU(或CPU集合)上。CPU亲和性利用了这样一个事实:进程上一次运行后的残余信息会保留在CPU的状态中(也就是指CPU的缓存)。如果下一次仍然将该进程调度到同一个CPU上,就能避免缓存未命中等对CPU处理性能不利的情况,从而使得进程的运行更加高效。
CPU亲和性分为两种:软亲和性和硬亲和性。软亲和性主要由操作系统来实现,Linux操作系统的调度器会倾向于保持一个进程不会频繁的在多个CPU之间迁移,通常情况下调度器都会根据各个CPU的负载情况合理地调度运行中的进程,以减轻繁忙CPU的压力,提高所有进程的整体性能。除此以外,Linux系统还提供了硬亲和性功能,即用户可以通过调用系统API实现自定义进程运行在哪个CPU上,从而满足特定进程的特殊性能需求。reference link
IOMMU
在执行dpdk提供的应用程序时,会发现他会检测IOMMU是否是available的,这里介绍一下它是什么。
在计算机领域,IOMMU(Input/Output Memory Management Unit)是一个内存管理单元(Memory Management Unit),它的作用是连接DMA-capable I/O总线(Direct Memory Access-capable I/O Bus)和主存(main memory)。传统的内存管理单元会把CPU访问的虚拟地址转化成实际的物理地址。而IOMMU则是把设备(device)访问的虚拟地址转化成物理地址。为了防止设备错误地访问内存,有些IOMMU还提供了访问内存保护机制。
IOMMU (Input and Output Memory Management Unit),其名称显然是由MMU衍生而来。之所以二者名称如此相似,是因为它们的功能非常相似。以下是一张解释IOMMU功能的经典图片:
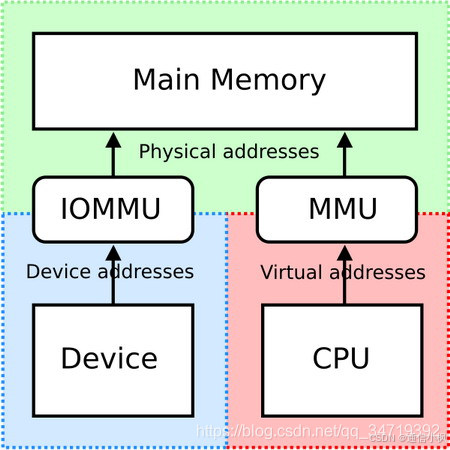
从上图中不难看出,IOMMU是DMA(直接内存访问,即设备与内存直接通信,而无需经过CPU)过程中的一个环节。本系列的文章更多时候会把IOMMU看作一种机制,从这个角度,我们也可以说:IOMMU是DMA的一种实现方式。
愿意阅读本文的读者,相信对于MMU并不陌生:MMU是将CPU虚拟地址转换为内存物理地址的硬件单元。类似地,IOMMU是将设备地址(又称总线地址)转换为内存物理地址的单元。我们完全可以参照虚拟内存机制,来理解IOMMU的作用:
① IOMMU使得设备无法直接访问物理地址,大大增加了设备进行DMA攻击的难度。
② 部分设备的引脚数较少,导致其位数较低,无法寻址到整个物理内存空间。以目前主流的32位设备为例,其在物理内存中直接寻址的范围是[0, 4GB)。但是,现代操作系统的内存往往大于4GB。如果设备申请DMA时,内核为设备分配的DMA buffer的地址高于4GB(以下简称为“high buffer”),则设备将无法寻址到它。
有了IOMMU以后,IOMMU就可以在[0, 4GB)范围内分配一段与高地址buffer长度相同的内存,让设备能够直接寻址(以下称为“low buffer”)。设备向low buffer写入后,IOMMU就会将low buffer中的内容,复制到high buffer,而后通知CPU从high buffer读取内容。反之亦然——CPU向high buffer写入后,IOMMU就会将high buffer中的内容,复制到low buffer,而后通知设备从low buffer读取内容。这样,CPU和设备都能读取到对方写入的内容。这样在high buffer和low buffer之间复制内容的操作,在IOMMU机制中被称为“sync”或“bounce”。
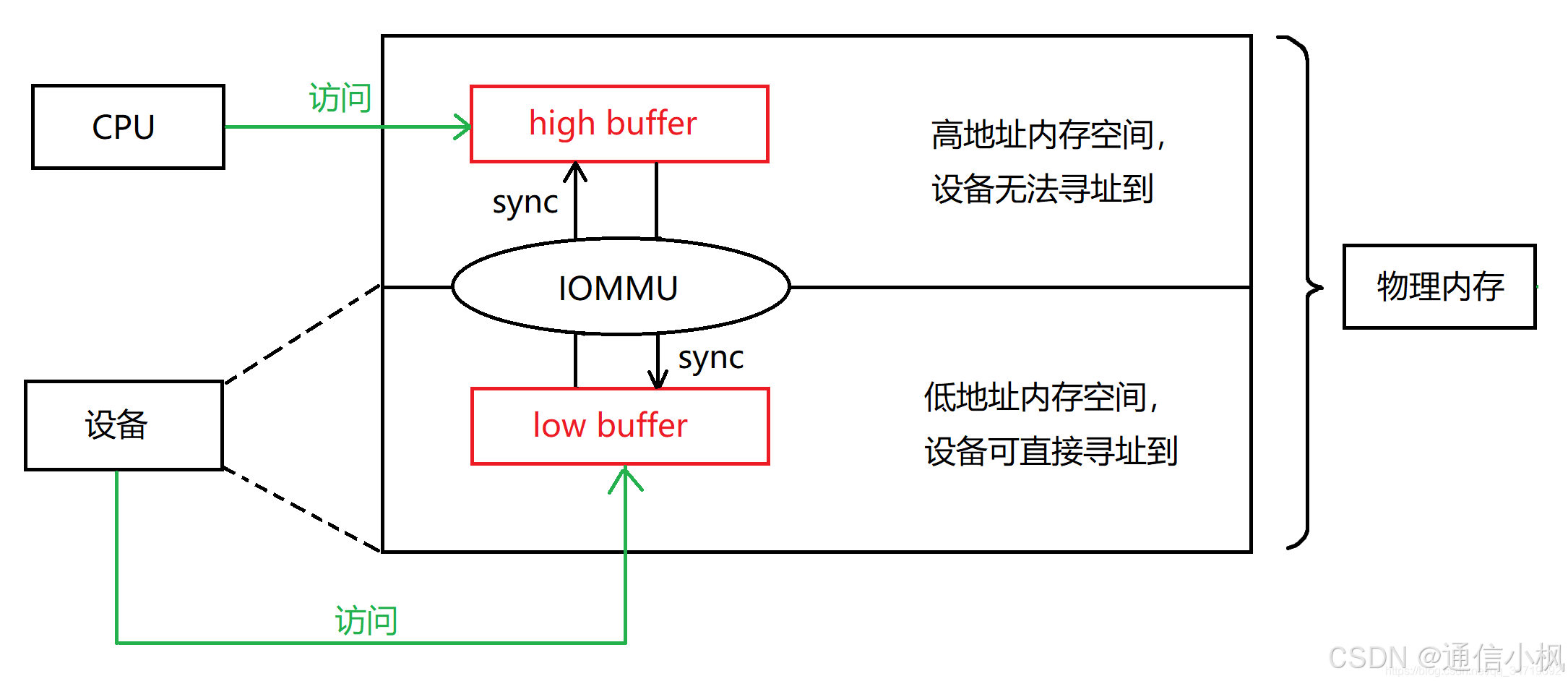
参考这篇
blog
DPDK — TestPMD
TestPMD 的本质是一个使用 DPDK 库实现的 DPDK Application,作用是在以太网端口之间转发数据包。通过 TestPMD 运行时的命令行,我们可用于配置端口(Port)之间的数据包转发和网卡(Network Interface)支持的其他功能。此外,我们还可以用 TestPMD 来尝试一些不同的驱动程序的功能,例如:RSS、过滤器和 Intel Ethernet Flow Director(以太网流量控制器)。
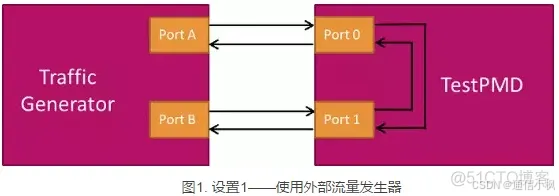
TestPMD 支持两种配置场景:
TestPMD 把两个以太网端口连接到外部的流量发生器。
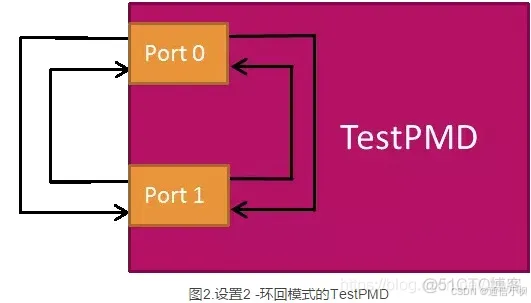
TestPMD 把两个以太网端口连成环回模式,这样就可以在没有外部流量发生器的情况下检查网络设备的接收和传输功能。
讲的非常详细
reference link


















 2062
2062

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










