












一、配置
1、源库类型
数据迁移支持多种源数据库,为了防止相互之间的干扰,按不同的源数据库类型生成了独立的配置文件,所以我们需要知道当前激活的配置。
#利用find命令查找application.yml文件,将"active"的值设置当前激活的源数据库类型(sping->profiles->active)
[root@node1 ~]# find /KingbaseES/V9/ -name
"application.yml" /KingbaseES/V9/ClientTools/guitools/KDts/KDTS-CLI/conf/application.yml
active: oracle # 准备迁移的数据库,如 dm(达梦)、gbase、kingbase、mysql、oracle 等,具体的配置在 kdts-数据库名.yml文件中
2、运行模式
迁移工具除了进行数据迁移还可以进行源库和目标库的数据对比,可根据需要切换运行模式。打开/KingbaseES/V9/ClientTools/guitools/KDts/KDTS-CLI/conf/application.yml文件,去"runningmode"前的#号后设置要运行的模式:
#默认开启的。看自己的实际情况。
runningMode: DataMigration
3、源数据库
3.1 源库连接设置
[kingbase@node1 conf]$ cat datasource-oracle.yml
########################源数据库连接信息########################
sources:
#源数据库类型
- dbType: Oracle
#源数据库版本(9i,10g,11g,12c,19c)
dbVersion: 11g
#连接字符串,格式为:jdbc:oracle:thin:@//<host>:<port>/<SERVICE_NAME>
#url: jdbc:oracle:thin:@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCPS)(HOST=1.2.3.4)(PORT=2484))(CONNECT_DATA= (SERVER = DEDICATED)(SERVICE_NAME=orcl))) #SSL使用
url: jdbc:oracle:thin:@//1.2.3.4:1521/ORCL
#驱动类名
driverClassName: oracle.jdbc.OracleDriver
#用户名(大写)
username: USERNAME1
#用户名是否使用密文(使用bin/cryptotool.sh或cryptotool.bat生成)
ciphertextUsername: false
#密码
password: 123456
#密码是否使用密文(使用bin/cryptotool.sh或cryptotool.bat生成)
ciphertextPassword: false
#数据库连接验证SQL
connectionTestSql: select 1 from dual
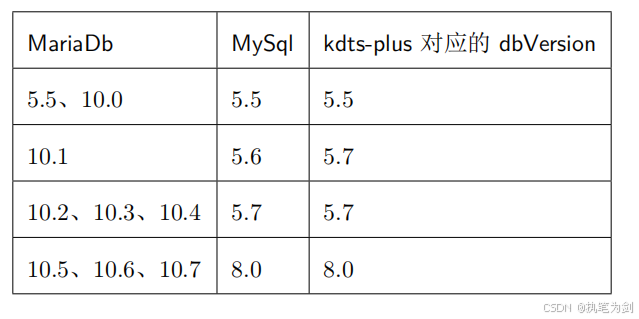
Mariadb与MySQL相同
配置“连接字符串”时需要考虑数据库的初始化字符集等因素,例如当 MySQL 数据库的字符集是 GBK 或
GB2312 时,应在 url 中添加“useUnicode=true&characterEncoding=utf-8”。
3.2 包含或排查的模式
#要迁移的模式(大写),多个模式用英文逗号隔开,如:A,B,C(不要回车换行),也可填入"*"(需要双引号,将迁移源库中此用户所能访问的所有模式)
#schemas: SCHEMA1,SCHEMA2,SCHEMA3
#schemas: "*"
schemas: SCHEMA1
#不迁移的模式,多个模式用英文逗号隔开,如:A,B,C(不要回车换行)
schemaExcludes: SYS,SYSTEM,MGMT_VIEW,DBSNMP,SYSMAN,OUTLN,FLOWS_FILES,MDSYS,ORDSYS,EXFSYS,WMSYS,APPQOSSYS,APEX_030200,OWBSYS_AUDIT,ORDDATA,CTXSYS,ANONYMOUS,XDB,ORDPLUGINS,OWBSYS,SI_INFORMTN_SCHEMA,OLAPSYS,SCOTT,ORACLE_OCM,XS$NULL,BI,PM,MDDATA,IX,SH,DIP,OE,APEX_PUBLIC_USER,HR,SPATIAL_CSW_ADMIN_USR,SPATIAL_WFS_ADMIN_USR
3.3 大表拆分设置
#游标提取记录数(每次和服务器交互提取的数据行数,加大该值可提升读取效率,但会增加内存开销(一次将指定数量的数据取回放在缓存中))
fetchSize: 1000
#含大对象数据表的游标提取记录数(同上,只是此参数针对有大对象字段的表)
tableWithLargeObjectFetchSize: 100
#含大大对象数据表的游标提取记录数(同上,只是此参数针对大对象字段长度超过1G的表)
tableWithBigLargeObjectFetchSize: 5
#大表拆分阈值行数(当表的行数超过此值时,将对表进行拆分,每块的记录数为此值和表总记录数除以“拆分最大块数”中的最大值)
largeTableSplitThresholdRows: 5000000
#大表拆分阈值大小(单位为M)(当表的数据大小(普通字段+大对象字段)超过此值时,将对表进行拆分)
largeTableSplitThresholdSize: 5000
#大表拆分阈值块数(当表的块数超过此值时,将对表进行拆分,分块数为表总块数除以此值和拆分最大块数取小)
largeTableSplitThresholdBlocks: 0
#大表拆分最大块数(每张表的最大拆分块数,应不超过总的读线程数)
largeTableSplitMaxChunkNum: 24
#大表拆分条件定义文件(优先于按行数和大小拆分)
largeTableSplitConditionFile: large-table-split-condition.json
3.4 表过滤设置
#表数据过滤条件定义文件
tableDataFilterConditionFile: table-data-filter-condition.json
3.5 包含或排查的对象
#注意:在下面使用英文逗号隔开的配置项中,如果对象名称中包含!@#$%^&*(_+}{]|\\'g;:?/,<等特殊字符时可使用双引号,但双引号需加斜杠转义,如\"Schema1\".\"Table!@#$%^&*(_+}{]|\\,<ABC\"
#只迁移的表,多个表用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/table-includes.txt文件后在文件中配置(文件优先)
tableIncludes:
#不迁移的表,多个表用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/table-excludes.txt文件后在文件中配置(文件优先)
tableExcludes:
#表优先列表
tablePriorityList:
#只迁移的字段,多个字段用英文逗号隔开,如:A,B,Table1.C,Schema1.Table1.D(不要回车换行,可指定表名、模式名),也可创建conf/column-includes.txt文件后在文件中配置(文件优先)
columnIncludes:
#不迁移的字段,多个字段用英文逗号隔开,如:A,B,Table1.C,Schema1.Table1.D(不要回车换行,可指定表名、模式名),也可创建conf/column-excludes.txt文件后在文件中配置(文件优先)
columnExcludes:
#只迁移的视图,多个视图用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/view-includes.txt文件后在文件中配置(文件优先)
viewIncludes:
#不迁移的视图,多个视图用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/view-excludes.txt文件后在文件中配置(文件优先)
viewExcludes:
#只迁移的函数,多个函数用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/function-includes.txt文件后在文件中配置(文件优先)
functionIncludes:
#不迁移的函数,多个函数用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/function-excludes.txt文件后在文件中配置(文件优先)
functionExcludes:
#只迁移的存储过程,多个存储过程用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/procedure-includes.txt文件后在文件中配置(文件优先)
procedureIncludes:
#不迁移的存储过程,多个存储过程用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/procedure-excludes.txt文件后在文件中配置(文件优先)
procedureExcludes:
#只迁移的包,多个包用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/package-includes.txt文件后在文件中配置(文件优先)
packageIncludes:
#不迁移的包,多个包用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/package-excludes.txt文件后在文件中配置(文件优先)
packageExcludes:
#只迁移的序列,多个序列用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/sequence-includes.txt文件后在文件中配置(文件优先)
sequenceIncludes:
#不迁移的序列,多个序列用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/sequence-excludes.txt文件后在文件中配置(文件优先)
sequenceExcludes:
#只迁移的同义词,多个同义词用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/synonym-includes.txt文件后在文件中配置(文件优先)
synonymIncludes:
#不迁移的同义词,多个同义词用英文逗号隔开,如:A,B,Schema1.C,D(不要回车换行,可指定模式名),也可创建conf/synonym-excludes.txt文件后在文件中配置(文件优先)
synonymExcludes:
3.6 要迁移的对象类别
#是否迁移序列
migrateSequence: true
#序列是否使用CurrVal做当前值(调用CurrVal前需要调用NextVal,会耗费一个序列值)
sequenceUseCurrentValue: true
#序列仅更新值(不创建)
sequenceOnlyUpdatingValue: false
#是否迁移用户自定义类型
migrateUserDefinedType: true
#是否迁移用户自定义类型
migrateUserDefinedTypeBody: true
#是否迁移表结构
migrateTableStructure: true
#是否迁移数据
migrateTableData: true
#是否迁移主键
migrateTablePrimaryKey: true
#是否迁移索引
migrateTableIndex: true
#是否迁移唯一性约束
migrateTableUnique: true
#是否迁移外键
migrateTableForeignKey: true
#是否迁移检查约束
migrateTableCheck: true
#是否迁移视图
migrateView: false
#是否迁移函数
migrateFunction: false
#是否迁移存储过程
migrateProcedure: false
#是否迁移包
migratePackage: false
#是否迁移包体
migratePackageBody: false
#是否迁移同义词
migrateSynonym: false
#是否包含公共同义词
includePublicSynonym: false
#是否迁移触发器
migrateTrigger: false
#是否迁移注释
migrateComment: true
#是否排除无效对象
excludeInvalidObject: false
#是否使用数据库系统统计信息(如表的记录数、大小等)
useDbmsStats: false
#是否使用手工脚本
useManualScript: false
3.7 kdms转换设置
#是否使用kdms做转换(视图、函数、存储过程、包、触发器)
useDms: false
#kdms访问地址
dmsUrl: http://1.2.3.4:12580/kdms/
#kdms源数据库类型
dmsSourceDbType: Oracle
#kdms目标数据库类型
dmsTargetDbType: Kingbase_ES_V8_R6
3.8 其他设置项
#网络读取超时时长(秒,0表示永不超时,若出现类似“Socket read timed out”异常时,可增大此值)
netReadTimeout: 0
#读数据超时时长(单位毫秒,0表示永不超时)
readDataTimeout: 0
#最大重试次数
maxRetries: 1
#重试间隔(毫秒)
retryInterval: 500
#读数据(中断后)能否恢复
readDataCanResume: false
#字符(CHAR、VARCHAR、CLOB)是否需要解码(Oracle字符集为US7ASCII、WE8ISO8859P1等时若迁移后字符里的中文乱码,设为true后重迁)
characterNeedDecoding: false
#国家字符(NCHAR、NVARCHAR、NCLOB)是否需要解码(Oracle字符集为US7ASCII、WE8ISO8859P1等时若迁移后国家字符里的中文乱码,设为true后重迁)
nationalCharacterNeedDecoding: false
#编码字符集(Oracle字符集为US7ASCII、WE8ISO8859P1等时若迁移后字符里的中文乱码,设为"ISO-8859-1"后重迁)
encodingCharset:
#解码字符集(Oracle字符集为US7ASCII、WE8ISO8859P1等时若迁移后字符里的中文乱码,设为"GB18030"后重迁)
decodingCharset:
#是否解码字节(Oracle字符集为US7ASCII时若迁移后字符里的中文乱码,设为true后重迁)
decodingBytes: false
#保持数据有序
keepSequentialData: false
3.9 数据对比设置(仅“数据对比”运行模式时有效)
#源端数据对比缓冲区大小(行数)
dataCompareBufferSize: 1000000
#数据对比摘要算法
dataCompareAlgorithm: MD5 #CRC32、MD5、SHA1、SHA256、SHA384、SHA512
#系统改变号(SCN,参考:select TO_CHAR(CURRENT_SCN) from V$DATABASE)
systemChangeNumber:
#统计分区表记录数时是否不使用系统改变号(System Change Number, SCN)
countingPartitionTableNotUsingScn: false
#是否开启并行HINT
enableParallelHint: true
#是否允许并行拆分和读取表
parallelSplitAndReadTable: true
#数据盲迁
dataBlindMigrating: false
#数据分块逆序
reverseDataChunkOrder: false
#最后数据分区优先
lastDataPartitionFirst: false
#是否强制创建视图(解决视图依赖问题)
forcibleView: false
3.10 源数据库最大连接数
#源数据库最大连接数
maxPoolSize: 100
4、目标数据库
4.1 目标库连接设置
#目标数据库类型(Kingbase, Kingbase_ADB)
dbType: Kingbase
#目标数据库版本(Kingbase: V7,V8R3,V8R6,V8R6C7,V9;Kingbase_ADB: 3)
dbVersion: V8R6
#目标端数据库兼容模式(Oracle,PG,MySQL,SQLServer)
compatibleDbType: Oracle
#连接字符串,格式为:jdbc:kingbase8://{host}:{port}/{database}
url: jdbc:kingbase8://1.2.3.4:54321/database1?ApplicationName=kingbase_transfer #Kingbase V8R6,V8R6C7,V9使用
#url: jdbc:kingbase83://1.2.3.4:54321/database1 #Kingbase V8R3使用
#url: jdbc:kingbase://1.2.3.4:54321/DATABASE1 #Kingbase V7使用
#url: jdbc:postgresql://1.2.3.4:54322/database1 #Kingbase_ADB使用,格式为:jdbc:postgresql://{host}:{port}/{database}
#连接字符串(Unix Domain Sockets)
#url: jdbc:kingbase8:///db?socketFactory=org.newsclub.net.unix.AFUNIXSocketFactory$FactoryArg&socketFactoryArg=/tmp/.s.KINGBASE.54321&sslMode=disable
#驱动类名
driverClassName: com.kingbase8.Driver #KingbaseV8R6,V8R6C7,V9使用
#driverClassName: com.kingbase83.Driver #Kingbase V8R3使用
#driverClassName: com.kingbase.Driver #Kingbase V7使用
#driverClassName: org.postgresql.Driver #Kingbase_ADB使用
#用户名
username: kingbase
#用户名是否使用密文(使用bin/cryptotool.sh或cryptotool.bat生成)
ciphertextUsername: false
#密码
password: 123456
#密码是否使用密文(使用bin/cryptotool.sh或cryptotool.bat生成)
ciphertextPassword: false
#目标模式,多个模式用英文逗号隔开,如:A,B,C(不要回车换行),也可填入"*"(需要双引号,则目标模式与源模式同名)
#schemas: SCHEMA1,SCHEMA2,SCHEMA3
#schemas: SCHEMA1
schemas: "*"
#目标模式统一前缀,指定后所有的目标模式名前都会添加此前缀
schemaPrefix:
#目标模式统一后缀,指定后所有的目标模式后都会添加此后缀
schemaSuffix:
#目标模式属主,多个属主用英文逗号隔开,如:A,B,C(不要回车换行),也可填入"*"(需要双引号,则目标属主与目标模式同名)
schemaOwners:
#目标模式表空间,多个表空间用英文逗号隔开,如:A,B,C(不要回车换行),也可填入"*"(需要双引号,则目标表空间与目标模式同名)
schemaTablespaces:
#数据库连接验证SQL
connectionTestSql: select 1
温馨提示:如果迁移程序和目标数据库(KingbaseES)在同一台计算机上,并且操作系统是 Linux,可以使
用 Unix Domain 进行连接,可提高数据传输效率。
5.2 其他设置项
#批量提交记录数(行数)
writeBatchSize: 1000
#批量提交记录数(行数)--大大对象数据
writeBatchSizeBigLob: 10
#批量提交数据大小(单位为M)
writeBatchByteSize: 128
#大对象数据读入内存阈值(单位兆,默认128M)
lobInMemoryThresholdSize: 128
#删除目标库中已存在的对象(如表、视图等)
dropExistingObject: true
#是否截断表(清空表数据)
truncateTable: false
#目标数据库对象重命名-除表名、列名外的其他对象: pk、fk、constraint、unique constraint、index 等
renameObject: true
#检查约束不验证已存在数据
checkConstraintNotValidated: true
#是否记录成功脚本
logSuccessScript: true
#是否创建目标模式
createTargetSchema: true
#迁移结果保留时长(单位为天)
resultRetentionDays: 7
#是否删除空字符(解决 无效的 "UTF8" 编码字节顺序(invalid byte sequence for encoding "UTF8": 0x00))
removeNullCharacter: false
#是否删除首尾空白字符
removeWhiteSpaceCharacter: false
#是否将分区表当作普通表迁移
partitionTableAsNormal: false
#是否创建默认分区表
createDefaultPartitionTable: true
#是否将全局临时表当作普通表迁移,目标库未V8R3时,设为true
globalTemporaryTableAsNormal: false
#写数据超时时长(单位毫秒,0表示永不超时)
writeDataTimeout: 0
#写数据任务超时后重置是否删除数据
deleteWriteJobData: false
#临时排除保留字
excludeReservedWords: true
#最大重试次数
maxRetries: 2
#重试间隔(毫秒)
retryInterval: 500
温馨提示:
- 如果只迁移表数据,应将“drop-existing-object”设置为 false,避免删除目标库中表。
- 如果将大表拆分为多次迁移,应将“truncate-table”设置为 false。
5.3 数据对比设置(仅“数据对比”运行模式时有效)
#目标端数据对比缓冲区大小(行数)
dataCompareBufferSize: 1000000
#数据对比顺序比对并行度
dataCompareSequentialParallelism: 5
#是否按照unlogged表迁移
unloggedTable: false
#是否将unlogged表重置为普通表,当unloggedTable: true时,可以配置reloggedTable:true,两个参数配合使用
reloggedTable: false
#是否执行检查点(以无日志表迁移时设为true)
issueCheckpoint: false
#是否使用 insert 的方式迁移数据,默认为 Copy 方式(当 ora_input_emptystr_isnull=on 时,Copy 方式迁移的数据无法查询到时,设置为true)
useInsert: false
#是否使用遗留二进制拷贝签名
useLegacyBinaryCopySignature: true
#是否转义对象标识符(例如"tableName"、 `tableName`、[tableName])
quotedIdentifier: true
#对象识符大小写(DefaultCase、UpperCase、LowerCase、None)
identifierCase: DefaultCase
#是否重试执行失败的迁移任务(解决因依赖问题导致的迁移失败)
5.4 目标数据库最大连接数
retryFailedJob: false
#目标数据库最大连接数
5、线程池线程数
数据迁移属于 IO 密集型操作,涉及网络络 IO 和磁盘 IO 的交互,一旦发生 IO,线程就会处于等待状态,当 IO结束,数据准备好后,线程才会继续执行。
对于 IO 密集型线程数的设置公式为:线程数 = CPU 核心数/(1-阻塞系数) ,其中阻塞系数一般为0.8~0.9 之间,取 0.9 则:
#例如下面两个计算线程数的案例
双核 CPU: 2/(1-0.9) = 20
64核2路 CPU: 64*2/(1-0.9) = 1280
配置文件:kb-thread-config.xml
6、其他配置
/KingbaseES/V9/ClientTools/guitools/KDts/KDTS-CLI/conf/manual_script -->手工脚本,用于迁移编辑后的迁移失败的对象
/KingbaseES/V9/ClientTools/guitools/KDts/KDTS-CLI/conf/mapping_rule/column -->自定义表字段映射规则
/KingbaseES/V9/ClientTools/guitools/KDts/KDTS-CLI/conf/mapping_rule/data_type -->自定义数据类型映射规则
/KingbaseES/V9/ClientTools/guitools/KDts/KDTS-CLI/conf/mapping_rule/default_value -->自定义字段缺省值映射规则
/KingbaseES/V9/ClientTools/guitools/KDts/KDTS-CLI/conf/mapping_rule/table_datatable_data -->自定义数据映射规则
#每个目录下都有对应的使用说明文档 readme.md 和示例文件 example.json,请参考对应文档使用。
二、运行日志
迁移程序会在 kdts-xxx/logs 目录下按迁移日期和时间创建日志目录,该目录下会有 3 个日志文件以及不同模式名的子目录,每个子目录下存放该模式相关的日志(error.log、info.log、warn.log),请注意查看 error.log 中的内容。
温馨提示:
- Linux 平台下在 logs 根目录下会有一个名为“kdts-xxx-日期 + 时间.log”的日志,里面会包含全部的日志内容,Windows 平台受限于操作系统,无此日志。
- “数据对比”的日志目录名有“DataCompare-”前缀。
三、迁移报告
迁移程序会在 kdts-xxx/result 目录下按迁移日期和时间创建报告目录,该目录下会有 index.html 以及不同模式名的子目录,每个子目录下存放该模式的详细报告,可打开 index.html 进行查看。
- 模式信息首页(index.html)
- XXX 详细信息(如表结构、表数据、表主键等, detail_XXX.html)
- 失败脚本目录 (FailedScript)
- 成功脚本目录 (SuccessScript)
- 在 FailedScript、IgnoredScript 和 SuccessScript 目录下会生成与之对应(失败、略过、成功)的脚本:
- 迁移成功表结构 SQL 脚本
- 迁移失败表结构 SQL 脚本
四、KingbaseES优化配置参数
max_connections=2000
shared_buffers=RAM*0.4GB #RAM 指内存,最大设置为 64GB
work_mem =10MB
maintenance_work_mem=6GB
effective_cache_size=RAM*0.5GB #RAM 指内存(free -g)RAM*0.5GB
max_locks_per_transaction=1024
#wal_level = minimal
max_wal_size=100GB
checkpoint_timeout=5min
checkpoint_completion_target=0.9
max_parallel_workers_per_gather=0
logging_collector=on
log_destination='stderr'
log_directory='sys_log'
log_filename='kingbase-%d.log'
log_truncate_on_rotation=on
log_rotation_age=1440
log_connections=on
log_disconnections=on
log_statement='ddl'
log_checkpoints=on
log_lock_waits=on
log_autovacuum_min_duration=0
log_temp_files=0
lc_messages='C'
log_min_duration_statement=1000
log_line_prefix='%t [%p]: [%l-1] user=%u,db=%d,app=%a,client=%h'
ignore_char_null_check=true
max_worker_processes=100
max_parallel_workers=80
#max_parallel_workers_per_gather=64
max_parallel_maintenance_workers=64
#maintenance_work_mem=16GB



 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










