




首先 这是自己实习的内容,对于读者来说也许你已经是 翱翔蓝天,也可能和我一样是个小鸟,那不管如何,请对我的文章多多包容,批示。 谢谢
- 明确自己的思路,这真的很重要
- 1,淘宝商品的 价格,ID,商品的全部图片,是否包邮,标题
- 2,先获取商品列表URL,构造100页每页44个商品的循环
- 3,获取第一页的所有商品详情页ID,构建URL
- 4,详情页里淘宝和天猫的数据个别不一样,需要分别解析,否则会出现空的情况
- 5,商品名字,商品详情是静态加载,容易获取。个别商品名字有特别标注 例如定制两字需要特别剔除
- 6,商品价格,商品图片,商品是否包邮或者需要邮费多少,满多少部分地区包邮
- 7,先简单的保存本地,后期保存在数据库
- 8,反爬虫机制,Cookie,IP,U-A。或者人工打码
- 就以三星s9为例,毕竟我本身也挺想买的
- 偶然看见过文章,说是横排,和纵排的URL不一样,取出的数据不含广告在内
- 因为有广告,所以第一页会有48个,第二页会有44个
先公布在githup找到的一部分代码
def parse(self, response):
# print(response.body.decode('utf-8'))
js = re.findall(r'g_page_config = (.*?)g_srp_loadCss',response.body.decode('utf-8','ignore'),re.S)[0].strip().strip(';')
item_list = json.loads(js)['mods']['itemlist']['data']['auctions']
for item in item_list:
data = TaobaoItem()
data['title'] = re.sub(r'<span.*?</span>','python',item['title'])
data['price'] = item['view_price']
data['fee'] = item['view_fee']
data['area'] = item['item_loc']
data['sales'] = item['view_sales']
data['name'] = item['nick']
data['isTmall'] = '是' if item['shopcard']['isTmall'] else '否'
data['detail_url'] = item['detail_url'].strip().strip('/')
yield data
url_12 = 'https://s.taobao.com/api?_ksTS=1523179236254_226&callback=jsonp227&ajax=true&m=customized&stats_' \
'click=search_radio_all:1&q=python&s=36&imgfile=&initiative_id=staobaoz_20180408&bcoffset=-1' \
'&js=1&ie=utf8&rn=d5706a3802513dad625d594a35702a6b'
yield scrapy.Request(url_12,callback=self.parse_12)


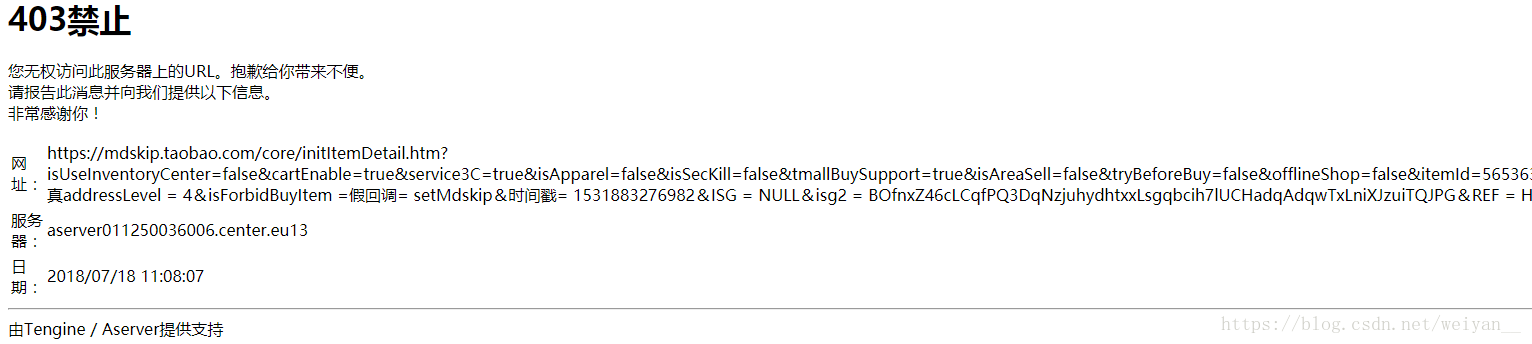
- 有一个我犯得的很重的错误,就是不细心,没看清楚那个JSON数据,导致我花了很长时间去详情页拿 json
因为淘宝的数据很精贵,有专门的反扒小组,所以即便我用芝麻代理运行一次基本上就废了。要加上各种cookies,请求头等
或者强者 可以用更好的方法关闭验证,这就是后话了

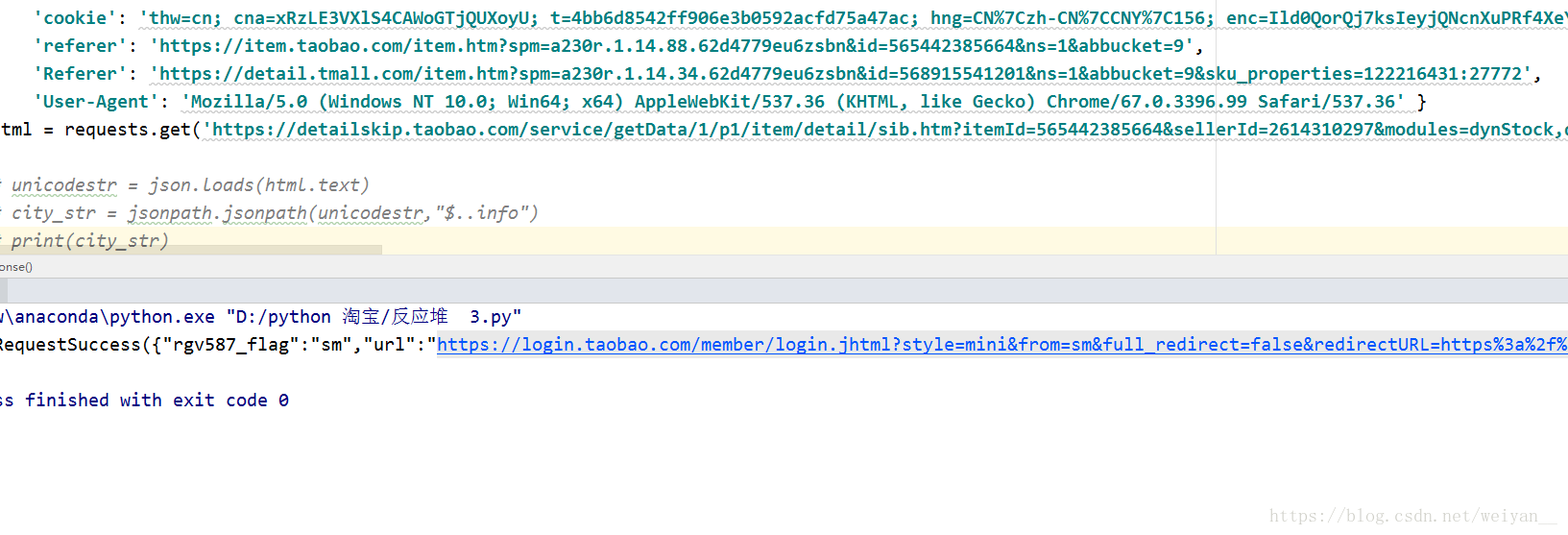
- 列表的第一页JSON 因为接口的原因,只有点击写一页才能有
仔细看 json里面 fee就是包邮的问题,一开始我就一直在详情页找,然后就是麻烦的还IP,heards这些信息,不过也有用,写scrapy的时候再写一个middewares.py 下载器
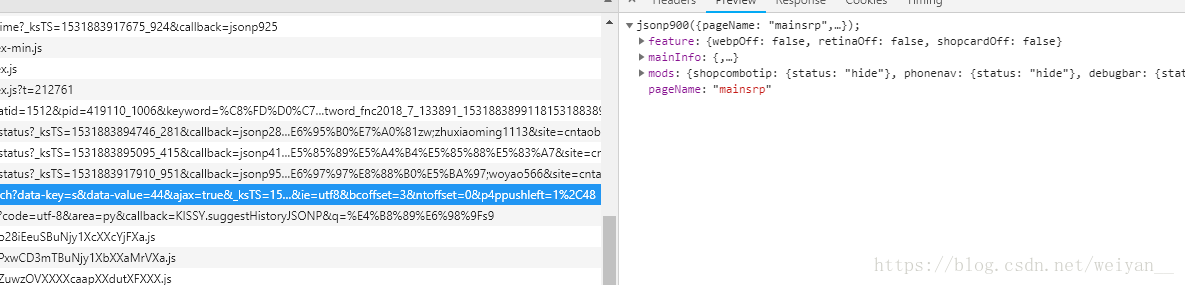

- 图片就是请求这里的数据了,正则,bs4 随你自己

商品详情不是js加载的,关闭js请求就是这样了
还有一些小工具
![]()

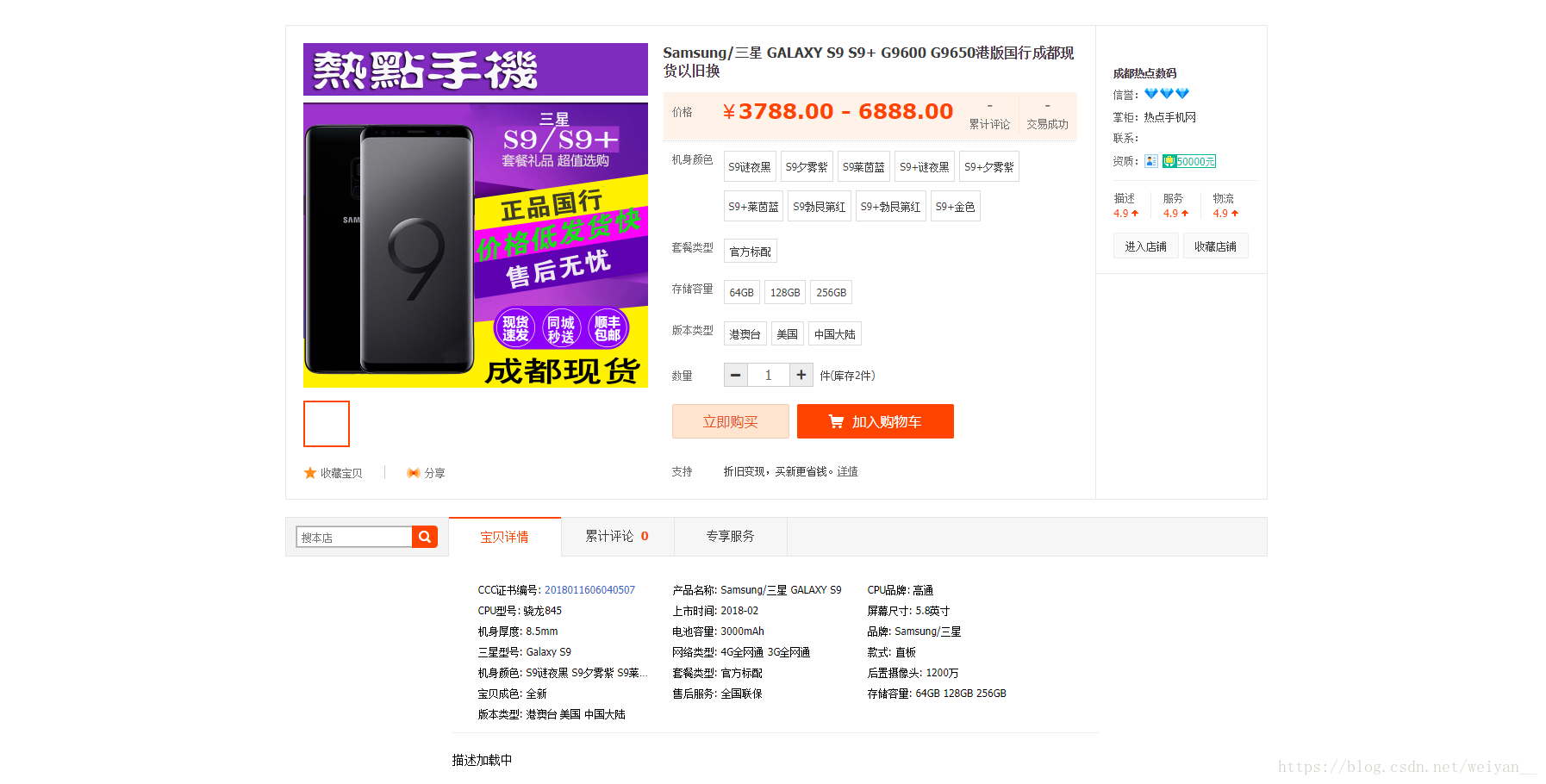
- 没写完,还有很多。暂时这里,大概个吧星期,会把代码和详情再发布



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










