




 本文详细介绍了优化算法在深度学习中的应用,包括Mini-batch梯度下降法、指数加权平均数(如动量梯度下降法、RMSprop和Adam算法)以及学习率衰减。强调了指数加权平均数在计算历史平均值中的作用,以及动量梯度下降如何加速收敛。此外,还讨论了超参数调试策略和Batch归一化的原理与实践,以及Softmax回归在多分类问题中的应用。最后,提到了在测试时处理Batch归一化的方法和局部最优问题。
本文详细介绍了优化算法在深度学习中的应用,包括Mini-batch梯度下降法、指数加权平均数(如动量梯度下降法、RMSprop和Adam算法)以及学习率衰减。强调了指数加权平均数在计算历史平均值中的作用,以及动量梯度下降如何加速收敛。此外,还讨论了超参数调试策略和Batch归一化的原理与实践,以及Softmax回归在多分类问题中的应用。最后,提到了在测试时处理Batch归一化的方法和局部最优问题。
二、优化算法
2.1 Mini-batch 梯度下降(Mini-batch gradient descent)
将总样本分为m组,为X{1}、X{2}、…、X{t}、…、X{m};
Y{1}、Y{2}、…、Y{t}、…、Y{m}。
每次迭代处理单个的mini-batch X{t}和Y{t},而不是同时处理全部的X和Y训练集。

总结用法:

2.2 理解mini-batch梯度下降法(Understanding mini-batch gradient descent)
使用batch梯度下降法的代价函数的值随着迭代次数增多而下降,mini-batch梯度下降法的代价函数值则为波动下降(因为每次迭代下你都在训练不同的样本集或者说训练不同的mini-batch)。
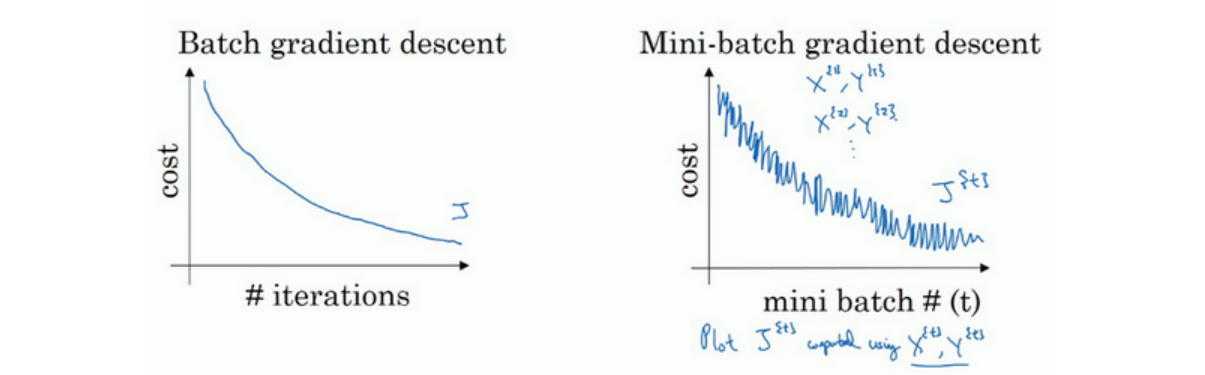
两种极端情况:
- size=m:batch梯度下降法
- size=1:随机梯度下降法
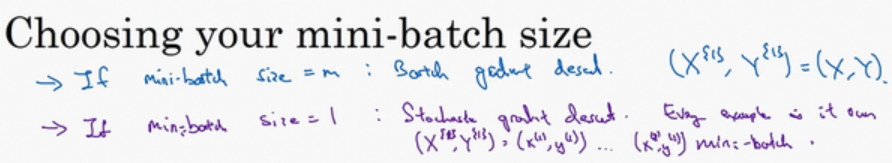
三种方法的结果:
batch梯度下降法:适用于样本数小于2000个的数据集。
mini-batch梯度下降法:适用于样本数目较大的情况。mini-batch大小一般为64到512。考虑到电脑内存设置和使用的方式,将mini-batch大小设置为是2的次方,代码会运行地快一些。处理的mini-batch一定要和CPU/GPU内存相符。
2.3 指数加权平均数(Exponentially weighted averages)
案例:已知每日气温,计算天气趋势(温度的局部平均值,或者说移动平均值)。
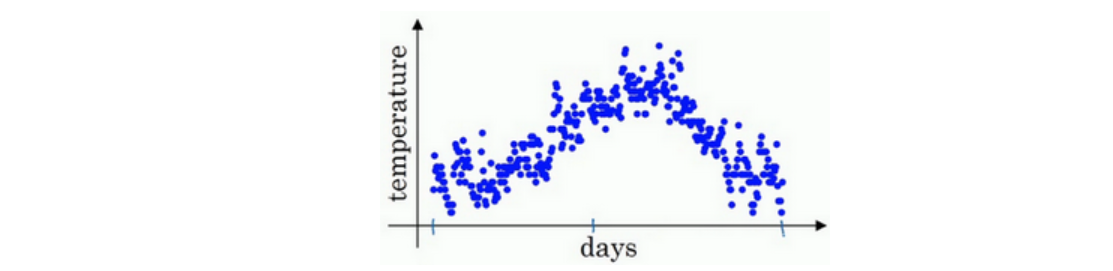
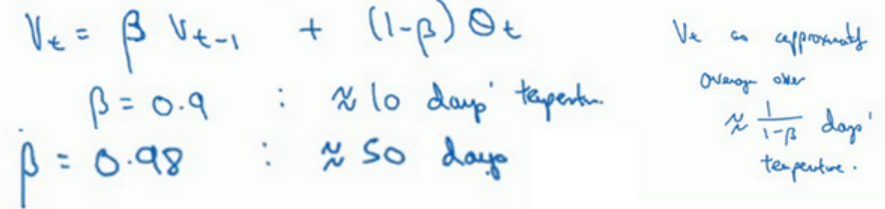
黄线为β=0.5,得到曲线为2天的平均值。
红线为β=0.9,得到曲线为10天的平均值。
绿线为β=0.98,得到曲线为50天的平均值。

β值较大,曲线较为平缓,曲线进一步右移,因为现在平均的温度值更多,要平均更多的值,指数加权平均公式在温度变化时,适应地更缓慢一些,所以会出现一定延迟。
β



















改善深层神经网络:超参数调试、正则化以及优化2&spm=1001.2101.3001.5002&articleId=119246581&d=1&t=3&u=ed961dee542e4cb78bc5c3f2ddacad7e)

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










