




目录
1. LlamaIndex 的 CondenseQuestionChatEngine
使用 ConversationalRetrievalChain 实现多轮RAG
4. 意图驱动的RAG(Intent-Driven RAG)
5. 多智能体系统(Multi-Agent Systems)
一、背景:为何多轮会话是RAG的“必修课”?
检索增强生成(Retrieval-Augmented Generation, RAG)技术通过结合外部知识库,极大地提升了大型语言模型(LLM)回答问题的准确性和时效性。一个基础的RAG应用在处理单轮、独立的问答时表现优异。然而,真实世界的交互远不止于此。人类的交流充满了上下文依赖,是自然流畅的多轮对话。
用户很自然地会将这种交流习惯带入与AI的互动中。例如,在客户服务场景中,用户可能会先问“我的订单到哪了?”,在得到回复后接着问“能加急吗?”或者“怎么修改收货地址?”。如果系统无法理解后续问题中的“它”或“那个”指代的是前一轮对话的订单,那么交互体验将大打折扣。这种上下文的缺失,尤其是在检索环节,是当前许多RAG应用面临的核心挑战。本文将深入探讨如何优化RAG系统中的多轮会话能力。
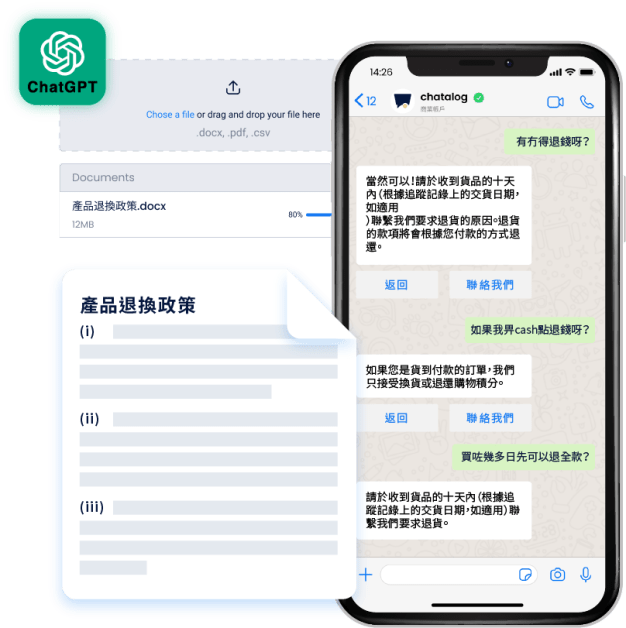
客服机器人基于知识文档(产品退换政策)与用户进行多轮对话
二、核心策略:查询重写(Query Rewriting)
面对多轮对话中上下文依赖的问题,业界普遍采用且行之有效的核心策略是查询重写(Query Rewriting),也称为查询压缩(Query Condensing)。其基本思想非常直观:在进行检索之前,利用LLM的理解能力,将当前用户的问题与之前的对话历史相结合,生成一个全新的、独立的、包含完整上下文信息的问题。
例如,对于之前的对话:
用户: 我想了解一下关于保罗·格雷厄姆(Paul Graham)的信息。
AI: 好的,保罗·格雷厄姆是Y Combinator的联合创始人之一,也是一位著名的程序员和作家。
用户: 他后来做了什么?
直接用“他后来做了什么?”去知识库检索,效果会很差。而查询重写模块会将其改写为:“在联合创办Y Combinator之后,保罗·格雷厄姆做了什么?”。这个新问题是独立的,包含了所有必要信息,可以被RAG系统的检索模块高效、准确地处理。
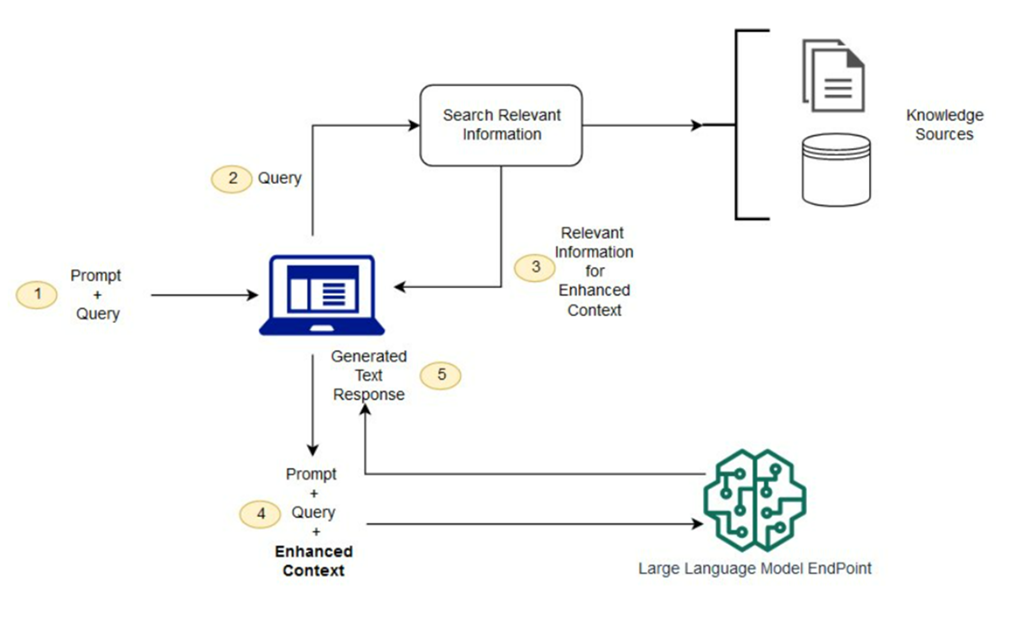
在RAG流程中,查询重写发生在用户输入(Query)之后,信息检索(Search Relevant Information)之前
三、开源框架实战
目前主流的RAG框架,如LlamaIndex、LangChain,都为多轮对话场景提供了开箱即用的解决方案,其核心逻辑都离不开对会话历史的管理和查询重写。
1. LlamaIndex 的 CondenseQuestionChatEngine
LlamaIndex 提供了专门用于会话场景的 Chat Engine。其中,CondenseQuestionChatEngine 是实现多轮对话的基础。它的工作流程正如其名:先压缩(Condense)问题,再查询。
下面是一个使用 LlamaIndex 实现多轮对话的完整示例:
# 1. 安装必要的库
# pip install llama-index openai
import os
from llama_index.core import VectorStoreIndex, SimpleDirectoryRead



















 310
310

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












