




1、准备环境
1.1、打开实例
打开魔搭平台免费实例:https://www.modelscope.cn/my/mynotebook
1.2、搭建LLaMA-Factory环境
搭建LLaMA-Factory环境,参见我的另一篇文章:https://blog.csdn.net/willhu2008/article/details/147999715?spm=1011.2415.3001.5331
1.3、下载模型
找到Qwen/Qwen1.5-1.8B-Chat,根据提示下载。

1.4、测试模型
模型下载完成后,先来运行一下试试。
创建模型运行命令,在LLaMA-Factory/examples/inference目录下,将llama3.yaml复制并重命名为QWen1.5_1.8b.yaml(名称不唯一),将内容更改为以下的内容,并保存(一定记得保存)。
model_name_or_path: ../Qwen1.5-1.8B-Chat
template: chatml
infer_backend: huggingface # choices: [huggingface, vllm, sglang]
trust_remote_code: true
进入LLaMA-Factory目录下,激活虚拟环境:
source env/bin/activate输入下列命令运行模型:
llamafactory-cli chat examples/inference/qwen1.5_1.8b.yaml等待一段时间出现"User:"后,就可以输入问题进行对话了。
2、模型微调
2.1、修改微调训练数据
首先对大模型的身份进行调整。微调文件为:/LLaMA-Factory/data/identity.json。将其下载后,替换所有的{{author}}和{{name}},再上传到该文件夹。

2.2 添加、注册自定义的训练数据集
也可以将自定义的数据集上传到data文件夹,并在/mnt/workspace/LLaMA-Factory/data/dataset_info.json中注册:
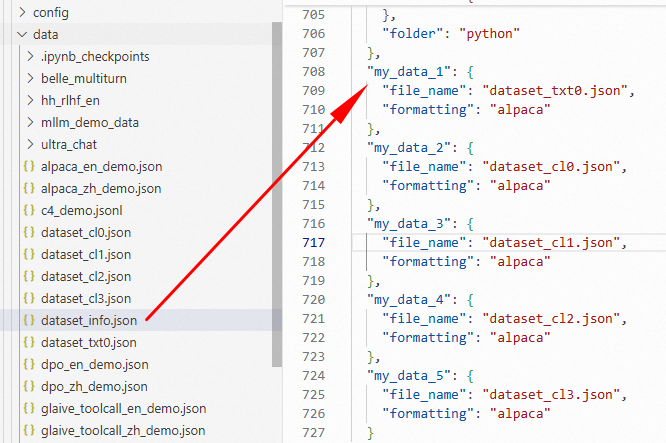
添加格式如下:
"my_data_4": { # 在webui的下拉框中显示的名称
"file_name": "dataset_xx.json", # 自定义数据集名称
"formatting": "alpaca" # 数据格式
},
"my_data_5": {
"file_name": "dataset_yy.json",
"formatting": "alpaca"
}2.3 利用WebUI微调
输入命令:
llamafactory-cli webui显示错误:

退出虚拟环境:deactivate,运行命令:
wget https://cdn-media.hf-mirror.com/frpc-gradio-0.3/frpc_linux_amd64 -O /root/.cache/huggingface/gradio/frpc/frpc_linux_amd64_v0.3
注意:wget后不能留太多空格,否则显示:“wget : 未找到命令”。
如果没有那个目录,则先用sudo创建:
sudo mkdir -p /root/.cache/huggingface/gradio/frpc如果下载速度很慢,可以用系统浏览器先下载到电脑,然后上传,再复制,如
cp ./res/frpc_linux_amd64 /root/.cache/huggingface/gradio/frpc/frpc_linux_amd64_v0.3安装成功后,修改权限:
chmod +x /root/.cache/huggingface/gradio/frpc/frpc_linux_amd64_v0.3再次运行命令:llamafactory-cli webui,显示:
* Running on local URL: http://0.0.0.0:7860
* Running on public URL: https://3b1fbc5c5cf19b0ca1.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from the terminal in the working directory to deploy to Hugging Face Spaces (https://huggingface.co/spaces)不用理会,直接点击打开http://0.0.0.0:7860或https://3b1fbc5c5cf19b0ca1.gradio.live
在打开的网页上,参考下图修改响应参数。
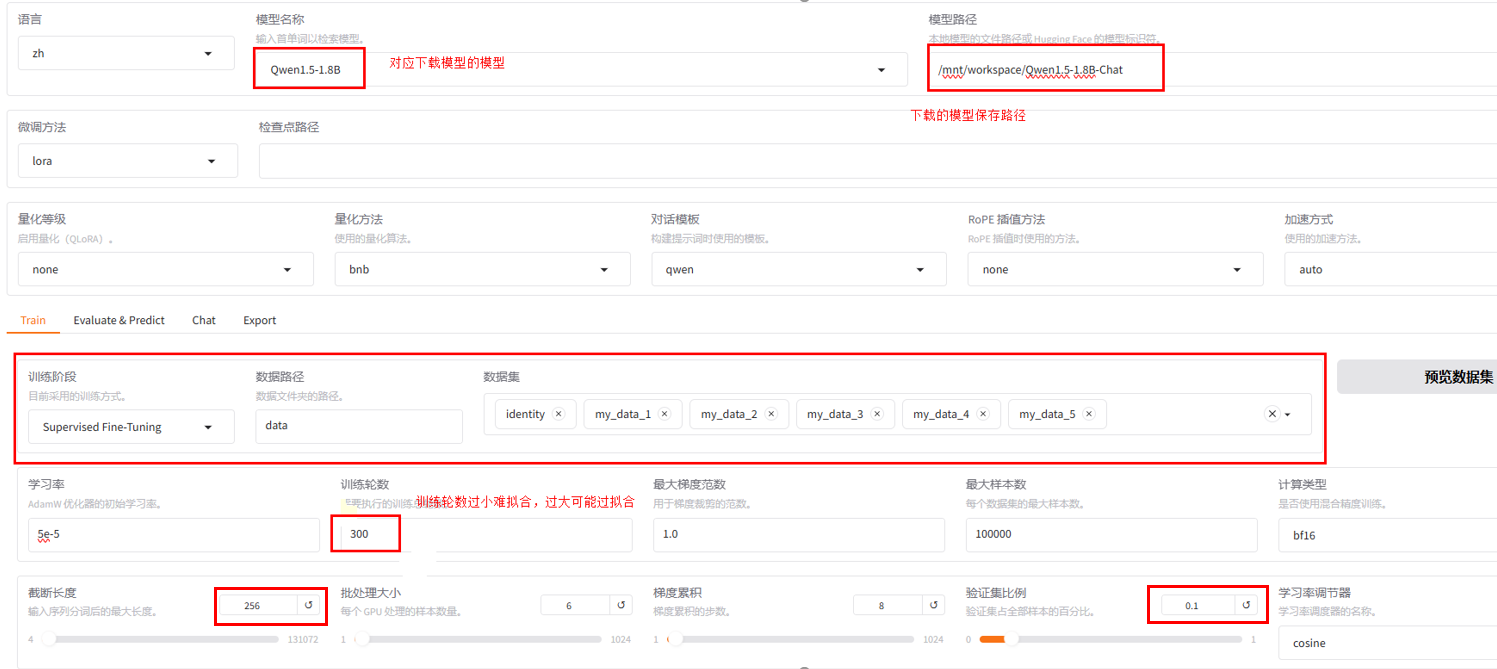
参数配置建议:
1. 基础设置
学习率:2e-4
训练轮数:8~10
截断长度:1024
批次大小:4
梯度累积:2
随机种子:42
2. LoRA 设置
LoRA 秩:8
LoRA Alpha:16
LoRA Dropout:0.05
LoRA 模块:all (全部训练)
3. 数据设置
验证集比例:0.1
预处理批次:8
打乱数据:✅ 开启
4. 保存设置
保存步数:50
日志步数:5
只保存最优模型:✅ 开启
配置好之后,点击开始,进行训练。
可调整学习率、训练轮数等参数,使得loss 降到 1.0~1.3 不再怎么降,可以停,效果最好,有风格又不背数据;loss 掉到 0.3~0.9 很低,模型只会死记硬背数据集原话,不会自由创作,说话死板、不通顺。
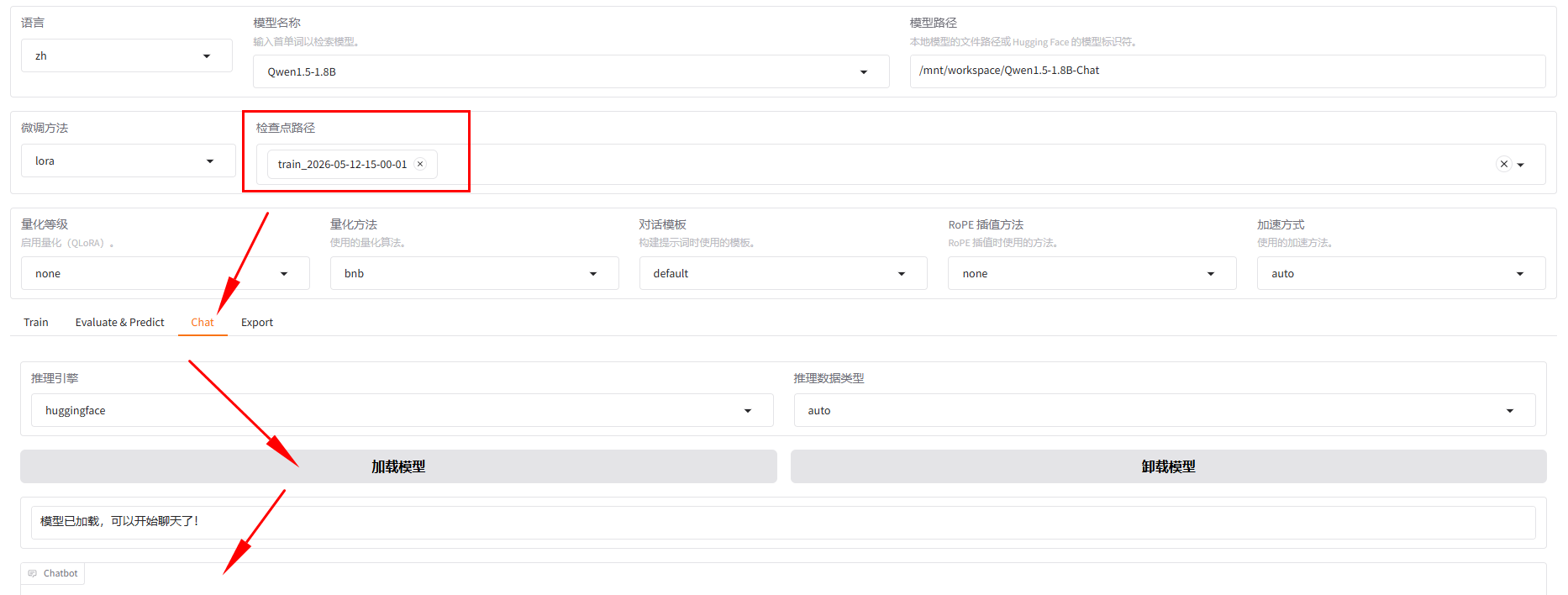
2.4 模型测试
微调成功后,可以和模型对话。



















 4949
4949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












