




 本文介绍了如何优化backtrader的性能,包括避免重复计算,本地存储数据以减少网络IO,使用PyPy解释器加速执行,以及通过JupyterLab和importlib解耦数据加载和策略执行。通过这些方法,可以显著提高backtrader回测的调试速度。
本文介绍了如何优化backtrader的性能,包括避免重复计算,本地存储数据以减少网络IO,使用PyPy解释器加速执行,以及通过JupyterLab和importlib解耦数据加载和策略执行。通过这些方法,可以显著提高backtrader回测的调试速度。
本文是backtrader实战内容,解决实战痛点。
查看本专栏完整内容,请访问:https://blog.csdn.net/windanchaos/category_12384821.html
本文发布地址:https://blog.csdn.net/windanchaos/article/details/131818436
本文主要解决backtrader使用者调试代码,耗时费力、编码生产效率奇低的问题。backtrader深度使用用户的福音 ^ . ^
本文适合以下场景的读者:
- 要求读者已经解决基本的
backtrader安装和使用问题,可以编写策略 - 读者策略使用
数据量大以及指标计算量大,需要将数据完整加载执行策略,但是回测跑代码十分耗时,比如调试一次代码,加载和预处理数据要十几分钟甚至几十分钟的情况。 - 本文不能解决
backtrader自身运行机制的执行速度问题,比如python的伪多线程问题、比如策略next方法体就是得一个bar一个bar的循环执行,比如你非参数调优场景且策略只需要单次执行。方案主要解决需要重复debug开发的耗时问题。
理论上节约的时间是以你回测或调试的次数来算的,拍个脑袋,以前1个小时可以调试4次,用了此法调个20次不在话下。时间就是金钱我的朋友~
目录
解决耗时问题的核心思路
读者请注意啊,我提供的解决思路及代码可能并不适合你的代码,不适配的话你需要自己改一改才可
重复计算耗时
backtrader自定义的Strategy的__init__方法中对各种指标线的计算,比如笔者曾今使用沪深300股票池,在策略中初始化了10几条均线,就需要计算1500根移动均线,这些均线的值理论上是稳定不变的,所以思路是:
- 把均线提前计算保存,存db用时取 或
- 数据插入到自定义的
datafeed中作为datafeed的一个字段(本质就是第一种)。
那上面的思路解决的是计算数耗费的时间,在争分夺秒、或者反复使用的场景下有价值。
但,我们这里不提供不讨论不展示具体的示例代码,我们用另一种更接地气且立竿见影的办法。
获取数据耗时
数据存本地,数据存本地,数据存本地,数据存本地。
网络IO是最慢的,对于需要重复的取数据行为,放本地,放db、csv随意。
将Python解释器替换成PyPy
pypy引入了类似JVM的即时编译(JIT)技术,可以将Python代码动态地编译成机器码,从而提高执行速度。使用了增量垃圾回收的技术,可以减少垃圾回收的停顿时间,提高程序的响应性能。PyPy还在内存管理方面进行了优化,可以减少内存占用,提高程序的效率。
但是,任何事物,有利必然有弊。它并不完全兼容所有的Python代码,一些第三方库可能不完全支持PyPy,或者需要进行额外的配置和调整才能在PyPy上正常运行。搞定这些都是你的时间成本。
bakctrader官方博客中有对pypy的测试,详见链接,我专栏中有对应博客文章的中文翻译(付费酌情点击)。效果上看,内存和性能提升还是很明显的。
大致性能提升指标:内存节约30%左右,执行时间节约40%左右。并且作者鼓励大家使用pypy。代价就是你不能绘图了。
backtrader作者在文中鼓励尽量使用
pypy
Use pypy where possible
经笔者验证,本文的核心解决思路可以结合PyPy。你可先切PyPy再做后续,也可以跳过本节。
1、安装提速操作:
没有安装或不会使用anaconda,请自行百度,没什么难度。
# anaconda提速
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --set show_channel_urls yes
# pip提速
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
2、创建PyPy的执行环境
- 可以到pypy官网下载python对应的版本:https://www.pypy.org/download.html 下载安装,不推荐,慢
- 命令行安装
conda create -c conda-forge -n my_pypy pypy python=3.9
通过命令conda env list找到安装目录:

在pycharm中使用该enviroment即可,新建环境目录中找到pypy,并进行设置。
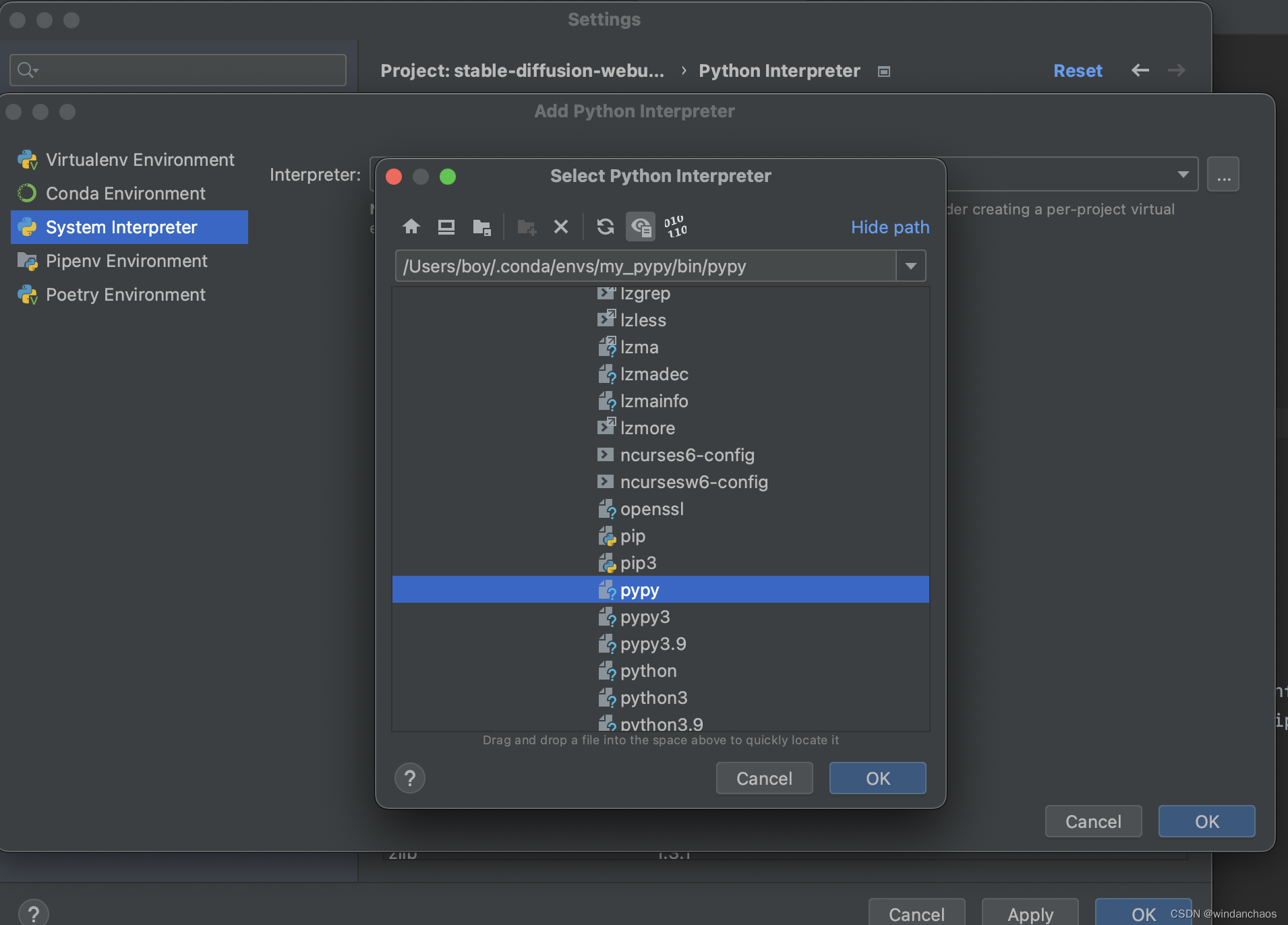
3、获取自己工程的依赖包
pycharm中敲击 pip freeze > requirements.txt
4、剩下的事就是激活该环境,安装依赖
切到PyPy的environment,在conda中操作(而不是pycharm)
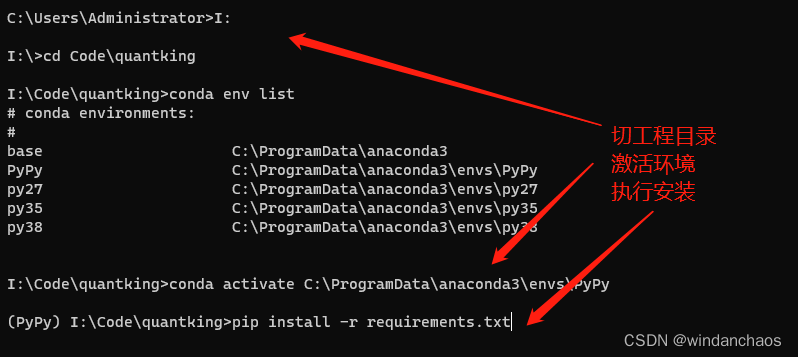
conda activate C:\ProgramData\anaconda3\envs\PyPy
pip istall -r requirements.txt
解决问题的正餐
方案核心:JupyterLab + importlib + 解耦数据加载和策略执行+ 策略类__init__优化
软件的安装
这里不介绍JupyterLab如何使用,有问题找百度或查看其帮助文档,都是没有什么门槛的工具。
安装
pip install jupyterlab
安装以后切到自己代码所在文件夹,windows先输入盘符:,如D:,再切目录。
启动
jupyter lab
技巧:修改类后没生效,百思不得其解的时候,尝试重启kernel(代价就是数据重新加载)
编辑执行文件
之后新建Notebook,后缀.ipynb的文件。
将驱动回测的文件,分几组拷贝进去,
比如我就将的文件分成了5组,
- 一组主要解决环境问题
- 一组主要解决import
- 一组主要解决放入数据
- 一组解决注入策略
- 一组解决绘图。
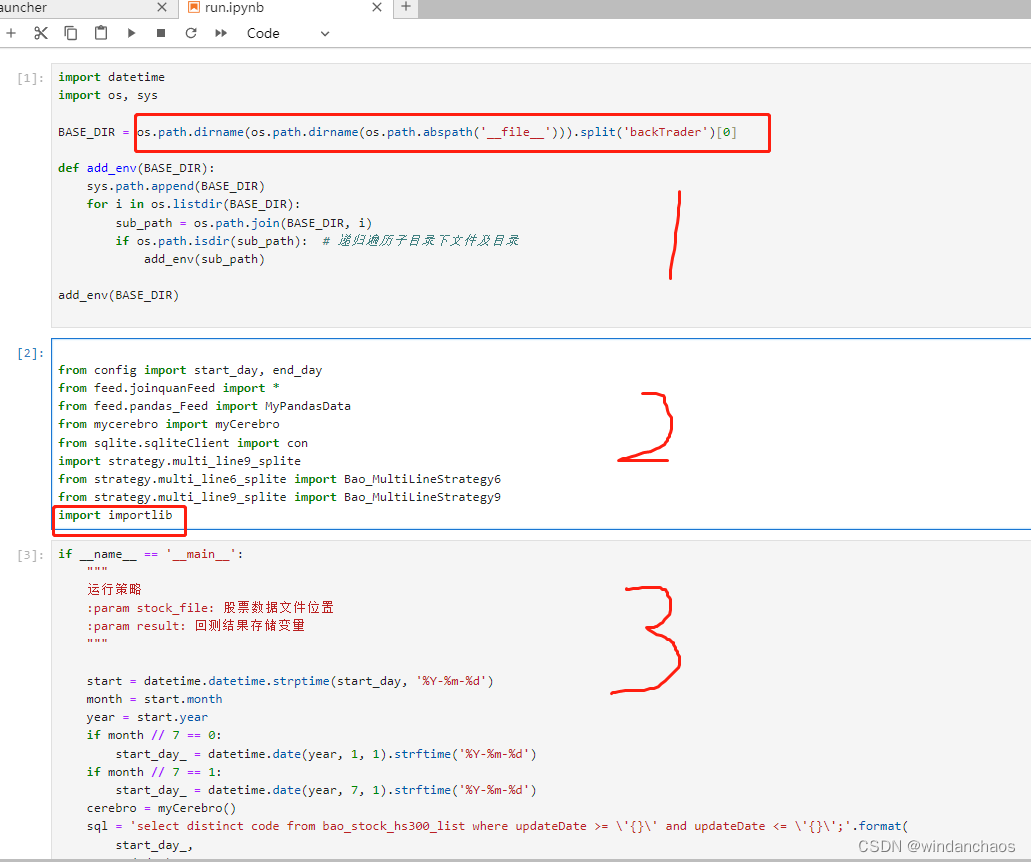
第一组
import 组,你要把这个加到第一个,之后才自己的代码,这个代码主要解决环境问题。
代码中 BASE_DIR需要换成自己的工程目录。
import datetime
import os, sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath('__file__'))).split('backTrader')[0]
def add_env(BASE_DIR):
sys.path.append(BASE_DIR)
for i in os.listdir(BASE_DIR):
sub_path = os.path.join(BASE_DIR, i)
if os.path.isdir(sub_path): # 递归遍历子目录下文件及目录
add_env(sub_path)
add_env(BASE_DIR)
第二组
这是我的,换你的。
from config import start_day, end_day
from feed.joinquanFeed import *
from feed.pandas_Feed import MyPandasData
from mycerebro import myCerebro
from sqlite.sqliteClient import con
import strategy.multi_line9_splite
from strategy.multi_line6_splite import Bao_MultiLineStrategy6
from strategy.multi_line9_splite import Bao_MultiLineStrategy9
import importlib
注意,策略类所在的module(我示例代码就是import strategy.multi_line9_splite)要整个import
importlib也必须要。这个是重新加载类的机制。有了它,你编辑策略类,就可以重新加载到内存,而不用重新跑数据(方法见后文)。
import importlib
第三组
这是我的,换你的。这里只是示意。
注意,绝对不能加cerebro.addstrategy(xxx)和cerebro.run(),就是不能把加策略代码放进去。这个一定注意,因为后边我们主要搞的就是这里。改造Cerebro源码,只加载一次数据,让strategy可以反复加,反复改。
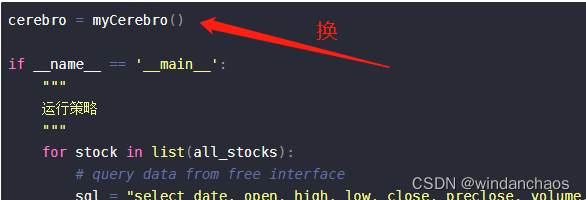
cerebro = myCerebro()
if __name__ == '__main__':
"""
运行策略
"""
for stock in list(all_stocks):
# query data from free interface
sql = "select date, open, high, low, close, preclose, volume, amount as money, turn, pctChg, tradestatus as paused from bao_stock_1d_000300_data where code = \'{}\' and \'{}\' < date and date < \'{}\';".format(
stock, start_day, end_day)
# print('feed',self.p.dataname)
dataframe = pd.read_sql_query(sql=sql, con=con, parse_dates=['date'], index_col='date')
# Pass it to the backtrader datafeed and add it to the cerebro
dataframe['openinterest'] = 0
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
pd.set_option('display.width', 1000)
# print(dataframe)
if dataframe.shape[0] > 500:
data = MyPandasData(dataname=dataframe)
if dataframe.shape[0] >= 120 and stock[3:6] != '688':
cerebro.adddata(data, name=stock)
cerebro.adddata(data, name=stock)
print('data load finished ')
cerebro.broker.setcash(100000)
# cerebro.addsizer(bt.sizers.FixedSize, stake=100)
# 万五佣金
cerebro.broker.setcommission(commission=0.0005)
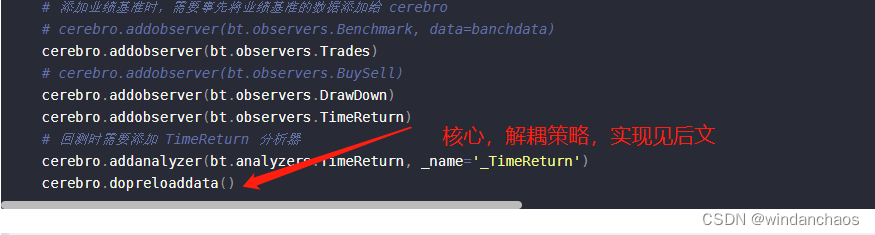
cerebro.addobserver(bt.observers.Broker)
# 添加业绩基准时,需要事先将业绩基准的数据添加给 cerebro
# cerebro.addobserver(bt.observers.Benchmark, data=banchdata)
cerebro.addobserver(bt.observers.Trades)
# cerebro.addobserver(bt.observers.BuySell)
cerebro.addobserver(bt.observers.DrawDown)
cerebro.addobserver(bt.observers.TimeReturn)
# 回测时需要添加 TimeReturn 分析器
cerebro.addanalyzer(bt.analyzers.TimeReturn, _name='_TimeReturn')
cerebro.dopreloaddata()
注意把自己代码中的
cerebro示例初始化类改为myCerebro。
myCerebro类源码后文会给
第四组
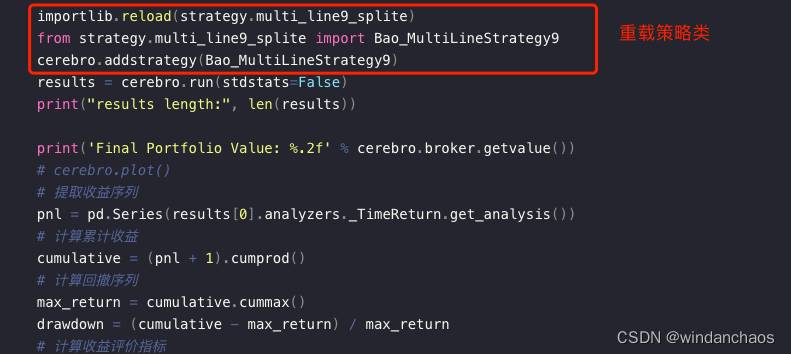
核心就是加策略的方法cerebro.addstrategy和cerebro.run
importlib.reload(strategy.multi_line9_splite)
from strategy.multi_line9_splite import Bao_MultiLineStrategy9
cerebro.addstrategy(Bao_MultiLineStrategy9)
results = cerebro.run(stdstats=False)
print("results length:", len(results))
print('Final Portfolio Value: %.2f' % cerebro.broker.getvalue())
# cerebro.plot()
# 提取收益序列
pnl = pd.Series(results[0].analyzers._TimeReturn.get_analysis())
# 计算累计收益
cumulative = (pnl + 1).cumprod()
# 计算回撤序列
max_return = cumulative.cummax()
drawdown = (cumulative - max_return) / max_return
# 计算收益评价指标
import pyfolio as pf
# 按年统计收益指标
perf_stats_year = (pnl).groupby(pnl.index.to_period('y')).apply(
lambda data: pf.timeseries.perf_stats(data)).unstack()
# 统计所有时间段的收益指标
perf_stats_all = pf.timeseries.perf_stats((pnl)).to_frame(name='all')
perf_stats = pd.concat([perf_stats_year, perf_stats_all.T], axis=0)
perf_stats_ = round(perf_stats, 4).reset_index()
# 打印
print(perf_stats_.iloc[:, [0, 1, 6, 7]])
示例代码的核心如下图:
第五组
这一组不重要,随意了,我把绘图放着里面的。你根据自己需求随意安排。
# 绘制图形
# 代码略
解决backtrader架构问题
下面是图片,截取自Backtrader中文文档的
Backtrader官方中文文档:第八章Indicators指标

根据官方文档描述:在策略中,指标总是在策略的__init__期间实例化。换言之,策略类和指标类耦合了。
另一方面,通过对源码研究,其实backtrader中用到的self.data的初始化(DataFeed注入引擎),也耦合在策略类的执行过程中的,笔者验证确认最耗时的就是这个阶段,数据是一个一个循环添加进去的,有多少个bar就会执行多少次循环……
这是大部分速度慢的根源,是框架为了优雅而带出来负担,读懂源码我们可自行解耦合。
自定义的myCerebro源码
myCerebro继承覆写了父类的几个方法,这里需要将你代码中Cerebro替换成myCerebro。
下面是myCerebro的定义,新建一个文件,引用它即可。
尽管很少有人会在参数调优的场景中进行代码调试,我还是贴心的把
optstrategy提供一下。
backtrader的参数调优本质是自动生成不同参数的策略放入引擎中执行。
import backtrader as bt
smas = {}
class myCerebro(bt.Cerebro):
def __int__(self):
super.__init__()
def addstrategy(self, strategy, *args, **kwargs):
'''
添加策略,为保证可重复执行,需要清除之前添加过的策略
如果你添加了多个策略,该方法需要增加判定清楚条件。
'''
# if len(self.strats) == XX:
# self.strats.clear()
self.strats.clear()
self.strats.append([(strategy, args, kwargs)])
return len(self.strats) - 1
def optstrategy(self, strategy, *args, **kwargs):
'''
寻找最佳参数,为保证可重复执行,需要清除之前添加过的策略组合
'''
self.strats.clear()
self._dooptimize = True
args = self.iterize(args)
optargs = itertools.product(*args)
optkeys = list(kwargs)
vals = self.iterize(kwargs.values())
optvals = itertools.product(*vals)
okwargs1 = map(zip, itertools.repeat(optkeys), optvals)
optkwargs = map(dict, okwargs1)
it = itertools.product([strategy], optargs, optkwargs)
self.strats.append(it)
# 默认preload
def dopreloaddata(self):
self._exactbars = int(self.p.exactbars)
self._dopreload = self.p.preload
for data in self.datas:
data.reset()
if self._exactbars < 1: # datas can be full length
data.extend(size=self.params.lookahead)
data._start()
if self._dopreload:
data.preload()
def run(self, **kwargs):
self._event_stop = False # Stop is requested
if not self.datas:
return [] # nothing can be run
pkeys = self.params._getkeys()
for key, val in kwargs.items():
if key in pkeys:
setattr(self.params, key, val)
# Manage activate/deactivate object cache
bt.linebuffer.LineActions.cleancache() # clean cache
bt.indicator.Indicator.cleancache() # clean cache
bt.linebuffer.LineActions.usecache(self.p.objcache)
bt.indicator.Indicator.usecache(self.p.objcache)
self._dorunonce = self.p.runonce
self._dopreload = self.p.preload
self._exactbars = int(self.p.exactbars)
if self._exactbars:
self._dorunonce = False # something is saving memory, no runonce
self._dopreload = self._dopreload and self._exactbars < 1
self._doreplay = self._doreplay or any(x.replaying for x in self.datas)
if self._doreplay:
# preloading is not supported with replay. full timeframe bars
# are constructed in realtime
self._dopreload = False
if self._dolive or self.p.live:
# in this case both preload and runonce must be off
self._dorunonce = False
self._dopreload = False
self.runwriters = list()
# Add the system default writer if requested
if self.p.writer is True:
wr = bt.WriterFile()
self.runwriters.append(wr)
# Instantiate any other writers
for wrcls, wrargs, wrkwargs in self.writers:
wr = wrcls(*wrargs, **wrkwargs)
self.runwriters.append(wr)
# Write down if any writer wants the full csv output
self.writers_csv = any(map(lambda x: x.p.csv, self.runwriters))
self.runstrats = list()
if self.signals: # allow processing of signals
signalst, sargs, skwargs = self._signal_strat
if signalst is None:
# Try to see if the 1st regular strategy is a signal strategy
try:
signalst, sargs, skwargs = self.strats.pop(0)
except IndexError:
pass # Nothing there
else:
if not isinstance(signalst, bt.SignalStrategy):
# no signal ... reinsert at the beginning
self.strats.insert(0, (signalst, sargs, skwargs))
signalst = None # flag as not presetn
if signalst is None: # recheck
# Still None, create a default one
signalst, sargs, skwargs = bt.SignalStrategy, tuple(), dict()
# Add the signal strategy
self.addstrategy(signalst,
_accumulate=self._signal_accumulate,
_concurrent=self._signal_concurrent,
signals=self.signals,
*sargs,
**skwargs)
if not self.strats: # Datas are present, add a strategy
self.addstrategy(bt.Strategy)
iterstrats = bt.itertools.product(*self.strats)
if not self._dooptimize or self.p.maxcpus == 1:
# If no optimmization is wished ... or 1 core is to be used
# let's skip process "spawning"
for iterstrat in iterstrats:
runstrat = self.runstrategies(iterstrat)
self.runstrats.append(runstrat)
if self._dooptimize:
for cb in self.optcbs:
cb(runstrat) # callback receives finished strategy
else:
# 移动到dopreload
# if self.p.optdatas and self._dopreload and self._dorunonce:
# for data in self.datas:
# data.reset()
# if self._exactbars < 1: # datas can be full length
# data.extend(size=self.params.lookahead)
# data._start()
# if self._dopreload:
# data.preload()
if self.p.optdatas and self._dopreload and self._dorunonce:
for data in self.datas:
data.reset()
data._start()
pool = bt.multiprocessing.Pool(self.p.maxcpus or None)
for r in pool.imap(self, iterstrats):
self.runstrats.append(r)
for cb in self.optcbs:
cb(r) # callback receives finished strategy
pool.close()
if self.p.optdatas and self._dopreload and self._dorunonce:
for data in self.datas:
data.reset()
data._start()
if not self._dooptimize:
# avoid a list of list for regular cases
return self.runstrats[0]
return self.runstrats
def runstrategies(self, iterstrat, predata=False):
'''
Internal method invoked by ``run```to run a set of strategies
'''
self._init_stcount()
self.runningstrats = runstrats = list()
for store in self.stores:
store.start()
if self.p.cheat_on_open and self.p.broker_coo:
# try to activate in broker
if hasattr(self._broker, 'set_coo'):
self._broker.set_coo(True)
if self._fhistory is not None:
self._broker.set_fund_history(self._fhistory)
for orders, onotify in self._ohistory:
self._broker.add_order_history(orders, onotify)
self._broker.start()
for feed in self.feeds:
feed.start()
if self.writers_csv:
wheaders = list()
for data in self.datas:
if data.csv:
wheaders.extend(data.getwriterheaders())
for writer in self.runwriters:
if writer.p.csv:
writer.addheaders(wheaders)
# self._plotfillers = [list() for d in self.datas]
# self._plotfillers2 = [list() for d in self.datas]
# if not predata:
# for data in self.datas:
# data.reset()
# if self._exactbars < 1: # datas can be full length
# data.extend(size=self.params.lookahead)
# data._start()
# if self._dopreload:
# data.preload()
for stratcls, sargs, skwargs in iterstrat:
sargs = self.datas + list(sargs)
try:
strat = stratcls(*sargs, **skwargs)
except bt.errors.StrategySkipError:
continue # do not add strategy to the mix
if self.p.oldsync:
strat._oldsync = True # tell strategy to use old clock update
if self.p.tradehistory:
strat.set_tradehistory()
runstrats.append(strat)
tz = self.p.tz
if isinstance(tz, bt.integer_types):
tz = self.datas[tz]._tz
else:
tz = bt.tzparse(tz)
if runstrats:
# loop separated for clarity
defaultsizer = self.sizers.get(None, (None, None, None))
for idx, strat in enumerate(runstrats):
if self.p.stdstats:
strat._addobserver(False, bt.observers.Broker)
if self.p.oldbuysell:
strat._addobserver(True, bt.observers.BuySell)
else:
strat._addobserver(True, bt.observers.BuySell,
barplot=True)
if self.p.oldtrades or len(self.datas) == 1:
strat._addobserver(False, bt.observers.Trades)
else:
strat._addobserver(False, bt.observers.DataTrades)
for multi, obscls, obsargs, obskwargs in self.observers:
strat._addobserver(multi, obscls, *obsargs, **obskwargs)
for indcls, indargs, indkwargs in self.indicators:
strat._addindicator(indcls, *indargs, **indkwargs)
for ancls, anargs, ankwargs in self.analyzers:
strat._addanalyzer(ancls, *anargs, **ankwargs)
sizer, sargs, skwargs = self.sizers.get(idx, defaultsizer)
if sizer is not None:
strat._addsizer(sizer, *sargs, **skwargs)
strat._settz(tz)
strat._start()
for writer in self.runwriters:
if writer.p.csv:
writer.addheaders(strat.getwriterheaders())
if not predata:
for strat in runstrats:
strat.qbuffer(self._exactbars, replaying=self._doreplay)
for writer in self.runwriters:
writer.start()
# Prepare timers
self._timers = []
self._timerscheat = []
for timer in self._pretimers:
# preprocess tzdata if needed
timer.start(self.datas[0])
if timer.params.cheat:
self._timerscheat.append(timer)
else:
self._timers.append(timer)
if self._dopreload and self._dorunonce:
if self.p.oldsync:
self._runonce_old(runstrats)
else:
self._runonce(runstrats)
else:
if self.p.oldsync:
self._runnext_old(runstrats)
else:
self._runnext(runstrats)
for strat in runstrats:
strat._stop()
self._broker.stop()
if not predata:
for data in self.datas:
data.stop()
for feed in self.feeds:
feed.stop()
for store in self.stores:
store.stop()
self.stop_writers(runstrats)
if self._dooptimize and self.p.optreturn:
# Results can be optimized
results = list()
for strat in runstrats:
for a in strat.analyzers:
a.strategy = None
a._parent = None
for attrname in dir(a):
if attrname.startswith('data'):
setattr(a, attrname, None)
oreturn = bt.OptReturn(strat.params, analyzers=strat.analyzers, strategycls=type(strat))
results.append(oreturn)
return results
return runstrats
改造你的Strategy类
此法,如指标不多,不是必要的。
指标(如均线)是在Strategy类的__init__方法执行之后(即类初始化完成之后),开始执行回测之前实时计算的。它的耗时取决于对应指标的计算耗时。
只需要改造Strategy类的__init__方法。
核心思路:把Strategy类__init__中实例化的指标线存到非Strategy的变量中。比如,smas={}我放在了myCerebro中。(注意:随便放,但不要放到cerebro执行的那个py文件中,会出循环引用问题)。
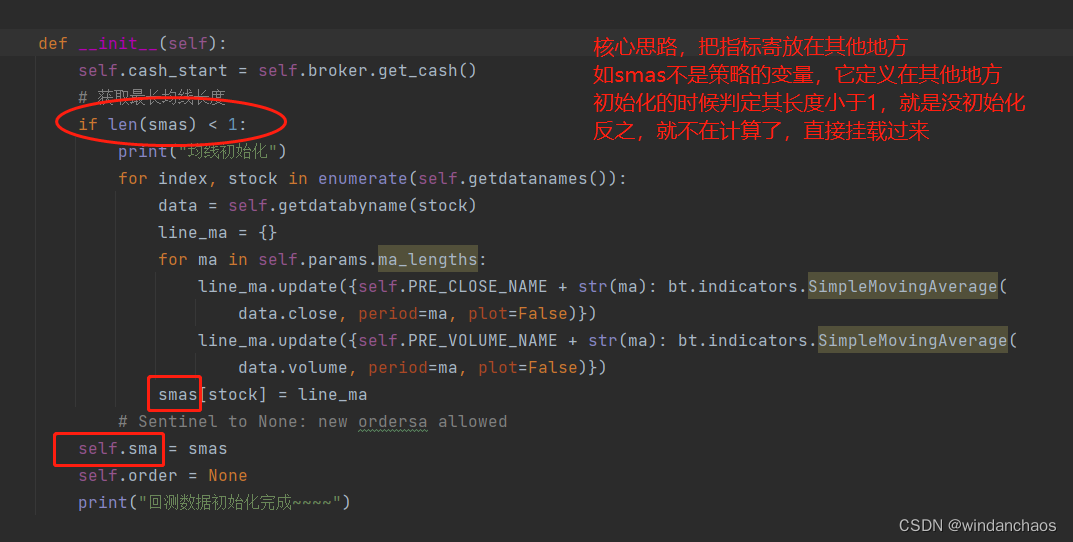
下面截图了解即可,主要是:“此法,如指标不多,不是必要的。”的依据。
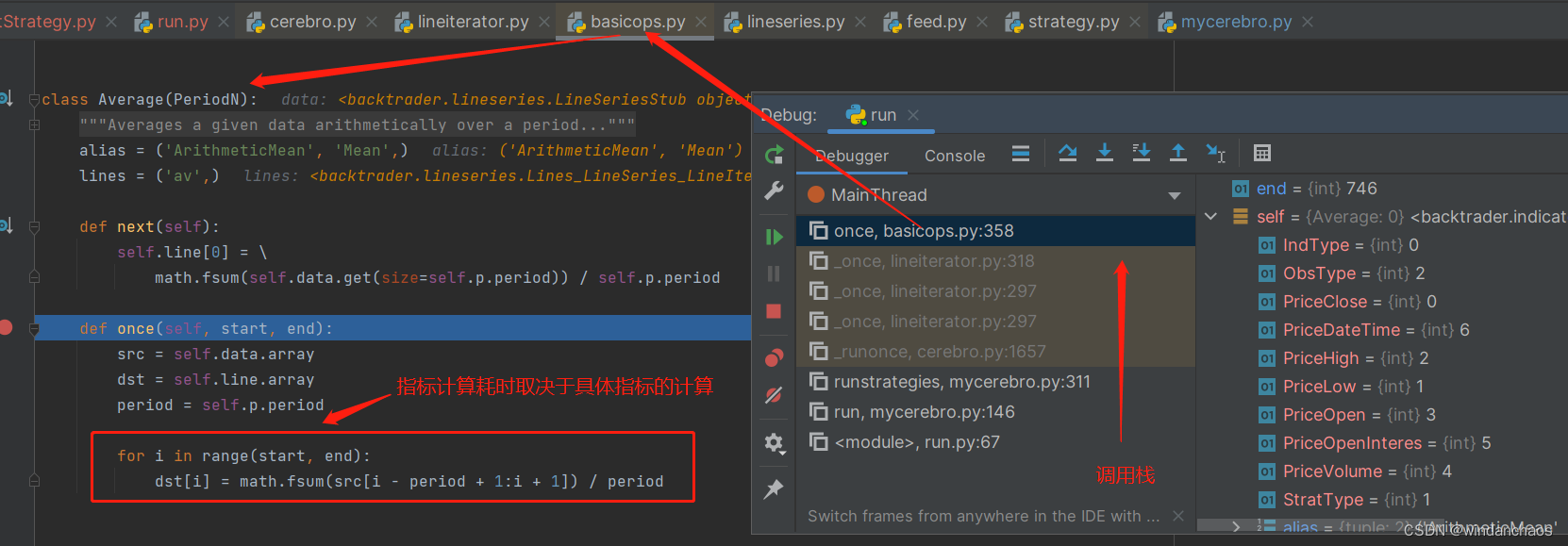
一个典型的调试过程
在jupyter的notebook里执行一次:一组、二组、三组
修改策略类,反复执行第四组。最耗时的第三组的时间就这样被省下来了。如果用PyPy,理论上执行回测涉及的性能也会提高不少。
最后
一切妥当后,就是jupyter的简单使用了……此处省略,不难。
做个总结,本方案核心思路是利用jupyter的分步执行能力 + importlib提供的类重载机制,让backtrader回测的数据只加载和计算一次,策略修改可反复执行。
本文提供一种解决思路,毕竟每个人的环境和代码逻辑、架构都不一样。按本方案执行,你应该会遇到很多坑。
一个一个解决吧~~~



















 296
296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












