






参考博文:
1、https://blog.csdn.net/m0_61356167/article/details/142092402
2、https://cloud.tencent.com/developer/article/2426044
3、https://blog.csdn.net/gitblog_00016/article/details/151286753
4、https://zhuanlan.zhihu.com/p/703887701(画的图特别好)
论文: https://arxiv.org/pdf/2405.14458
代码: GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
1.概述
YOLOv10 是由清华大学研究团队于2024年在 YOLOv9 之后推出的最新实时目标检测模型。它并非YOLO官方团队(Ultralytics)的发布,但在设计和理念上带来了多项重要改进,旨在不增加推理成本的情况下提升性能。
以下是YOLOv10的整体架构图:
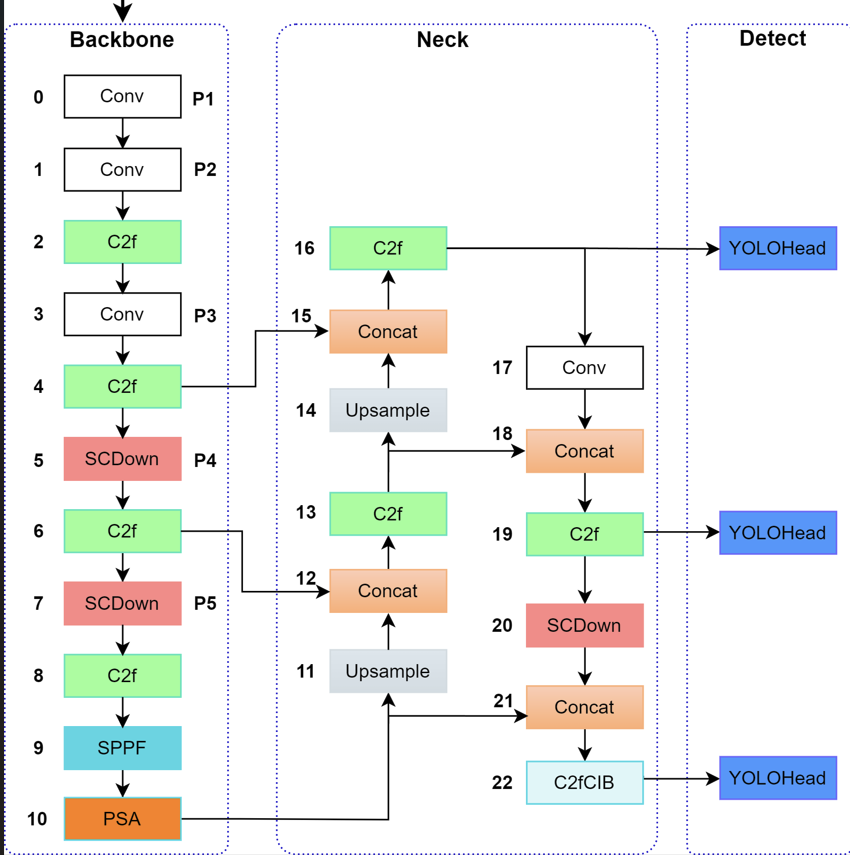
2.改进之处
2.1 核心架构改进:消除后处理瓶颈
YOLOv10 的一个革命性改进是无需非极大值抑制(NMS)。传统的 YOLO 模型在推理时需要依赖 NMS 来去除冗余的检测框,但这带来了额外的计算开销和延迟。
YOLOv10 通过两种策略解决了这个问题:
-
一致性双重分配训练
-
问题:传统YOLO在训练时,一个目标通常分配给一个Anchor进行正样本学习,但在推理时,NMS却要处理多个Anchor预测的同一个目标,造成了训练和推理的不一致。
-
解决方案:YOLOv10 在训练阶段,同时使用一对一(每个目标只匹配一个最佳Anchor)和一对多(每个目标匹配多个Anchor)两种标签分配策略。
-
好处:
-
一对一分支:学习做出果断、精确的预测,直接用于推理,从而摆脱对NMS的依赖。
-
一对多分支:提供丰富的监督信号,帮助模型学习更全面的特征,提升性能。
-
-
结果:在推理时,只需使用“一对一”分支,即可获得高质量、无冗余的预测框,实现了端到端的实时目标检测,显著降低了延迟。
-
-
** holistic(整体)模型设计**对模型的各个组件进行了效率和精度的整体优化:
-
轻量级分类头:发现分类分支的计算成本远高于回归分支。因此,YOLOv10 使用了更浅、更窄的分类头,在几乎不影响精度的情况下减少了大量计算。
-
空间-通道解耦下采样:传统下采样(如卷积)会同时压缩空间维度和变换通道维度,容易导致信息丢失。YOLOv10 将这个过程解耦,先进行点式卷积保持通道数并进行空间下采样,再用 1x1 卷积进行通道变换,更好地保留了信息。
-
等级引导块设计:在构建特征金字塔网络时,不是简单地将不同尺度的特征图相加,而是引入了一种更精细的机制,根据输入特征的等级(信息层次) 来引导融合,提升了多尺度特征的表示能力。
-
2.2 增强特征集成与模型缩放
-
大核卷积
-
在主干网络的深层,使用了 7x7 的大核深度卷积。
-
好处:扩大了感受野,能更好地捕捉图像中更大范围的上下文信息,这对于检测大型物体尤其有利,同时保持了深度卷积的计算效率。
-
-
部分自注意力模块
-
在 backbone 的末端引入了 PSA 模块。
-
好处:自注意力机制能有效建模全局依赖关系,但计算量巨大。YOLOv10 巧妙地将其放在深层且经过下采样的特征图上,并采用部分机制,在引入全局信息的同时,控制了计算成本,提升了模型对复杂场景和物体关系的理解能力。
-
-
先进的模型缩放策略
-
基于 YOLOv9 的广义高效层聚合网络(GELAN),YOLOv10 提出了一种模型缩放策略,可以生成一系列不同尺寸的模型(N, S, M, B, L, X)。
-
这种策略能够更均衡地调整模型的深度、宽度和比例,确保在参数量、计算量和精度之间达到最佳平衡。
-
2.3 总结与对比
| 改进方面 | 传统 YOLO (如 v8) | YOLOv10 | 带来的好处 |
|---|---|---|---|
| 后处理 | 依赖 NMS | NMS-Free(端到端) | 降低延迟,简化部署 |
| 训练策略 | 一对一 或 一对多 | 一致性双重分配 | 训练与推理一致,性能更优 |
| 分类头 | 与回归头对称 | 轻量级分类头 | 减少计算量,提升效率 |
| 下采样 | 标准卷积 | 空间-通道解耦下采样 | 保留更多信息,提升精度 |
| 特征融合 | 常规FPN/PAN | 等级引导块设计 | 更高效的多尺度特征融合 |
| 主干网络 | 标准CSP/ELAN | 大核卷积 + 部分自注意力 | 更大感受野,全局上下文建模 |
| 模型系列 | 基于深度/宽度缩放 | 先进的模型缩放 | 不同尺寸模型性能更均衡 |
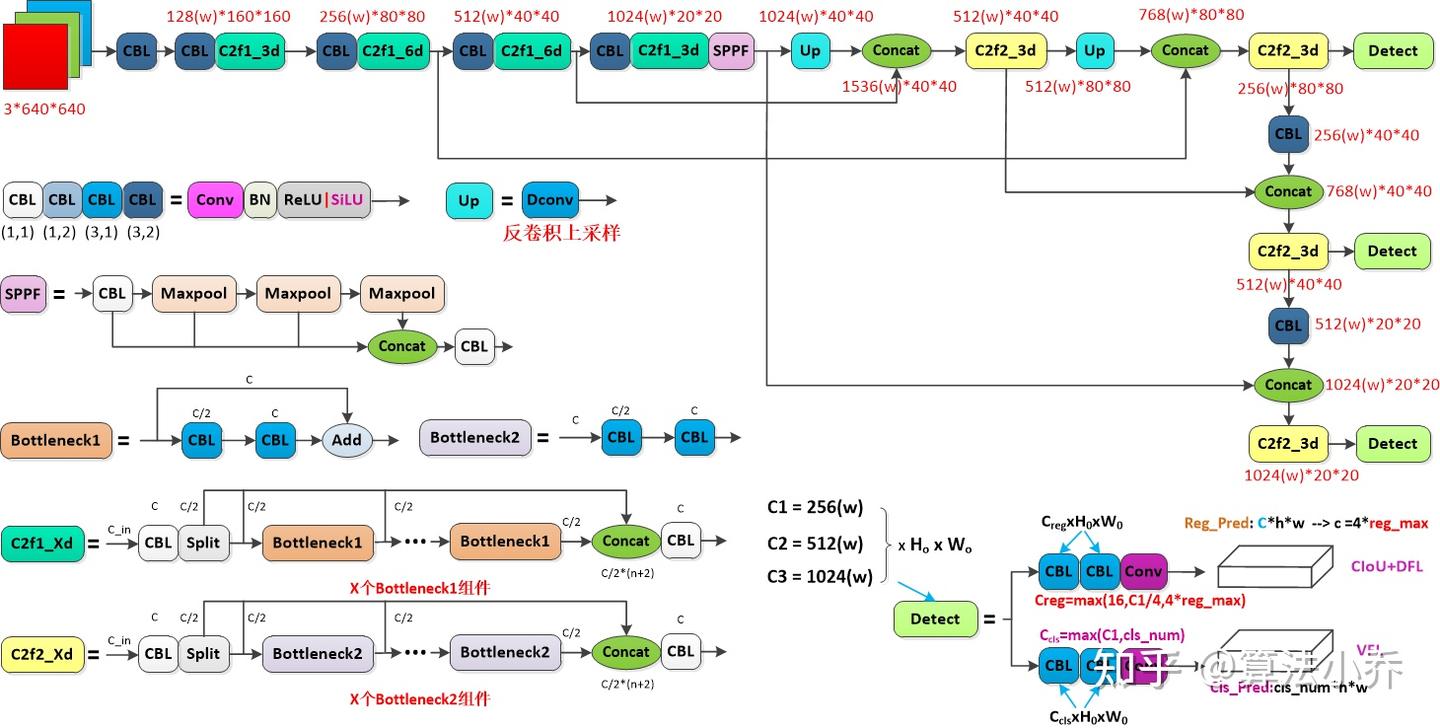
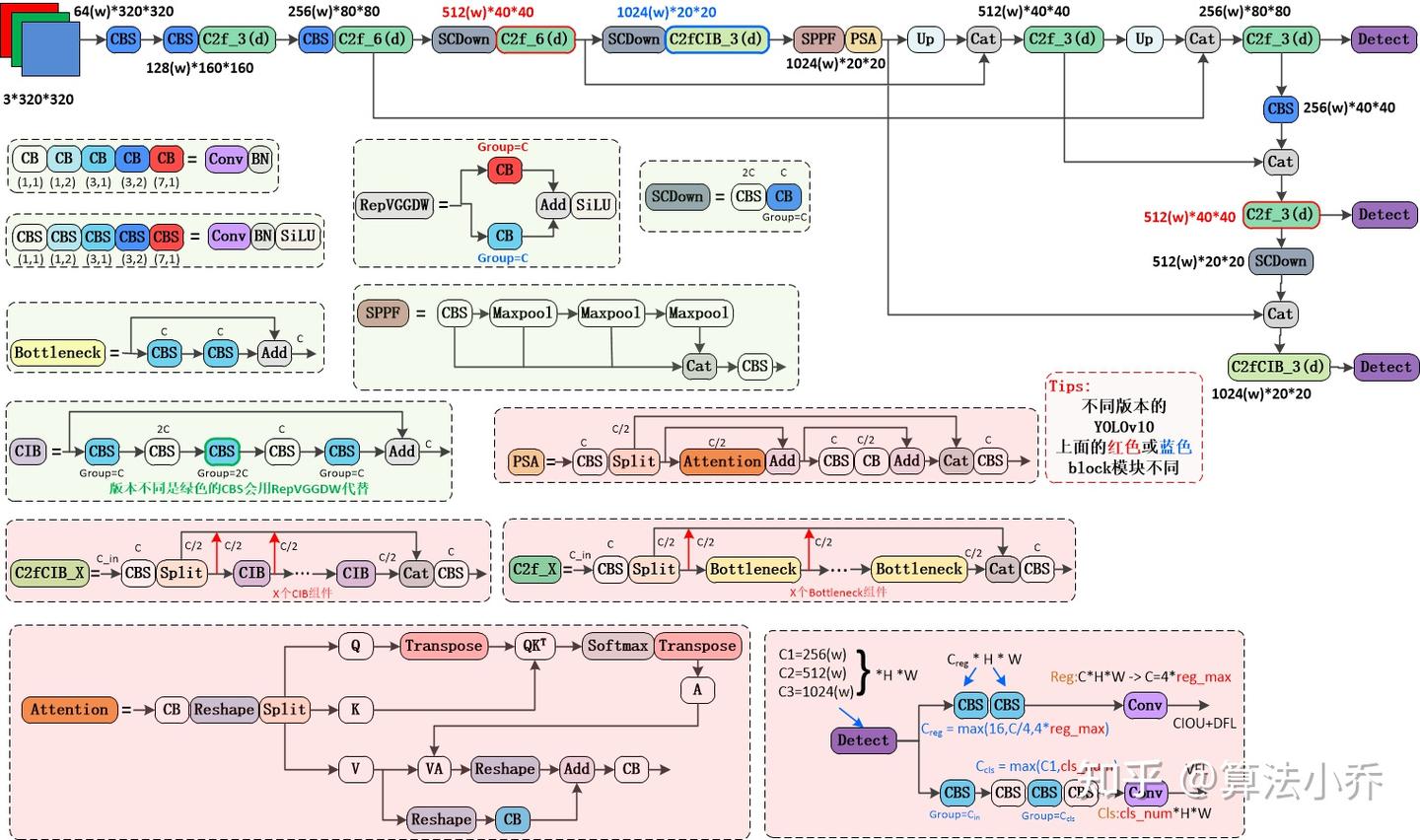
2.4 YOLOv10和YOLOv8结构比较图
注明:图片来自知乎 算法小乔 ,图画的真好
(1) YOLOv8网络结构
(2)YOLOv10网络结构
3.改进介绍
3.1C2fUIB介绍
1. C2fUIB只是用CIB结构替换了YOLOv8中 C2f的Bottleneck结构
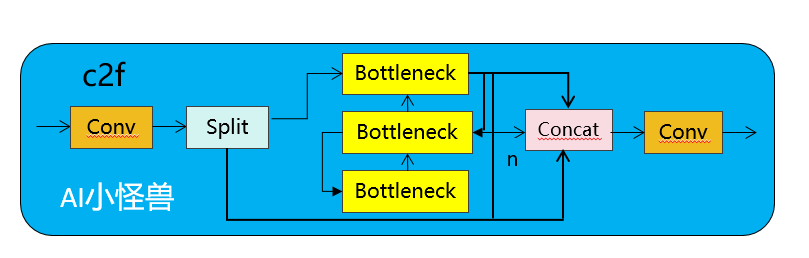
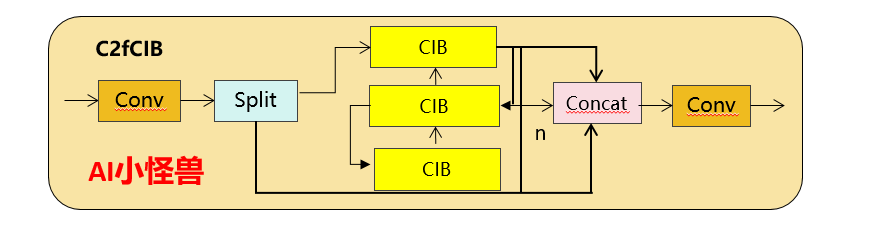
2.CIB 则是将 Bottleneck 中的标准卷积用深度卷积加逐点卷积进行替换。
3x3卷积为深度卷积,1x1为逐点卷积
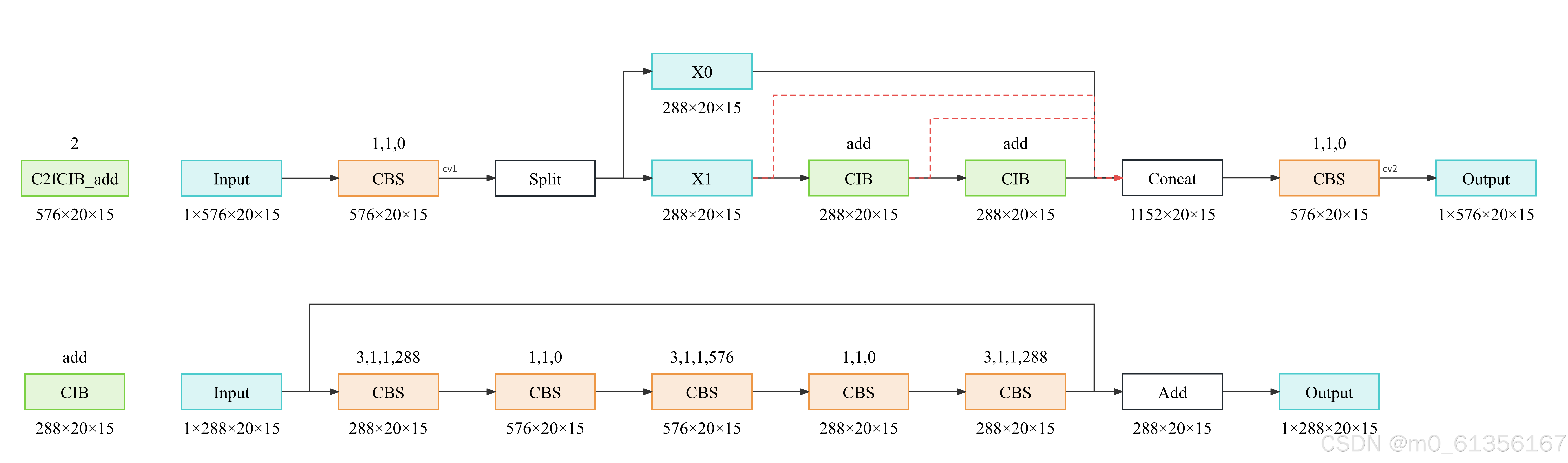
实现代码ultralytics/nn/modules/block.py
class CIB(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, e=0.5, lk=False):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = nn.Sequential(
Conv(c1, c1, 3, g=c1),
Conv(c1, 2 * c_, 1),
Conv(2 * c_, 2 * c_, 3, g=2 * c_) if not lk else RepVGGDW(2 * c_),
Conv(2 * c_, c2, 1),
Conv(c2, c2, 3, g=c2),
)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv1(x) if self.add else self.cv1(x)
class C2fCIB(C2f):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, lk=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(CIB(self.c, self.c, shortcut, e=1.0, lk=lk) for _ in range(n))3.小模型例如yolov10n中,可以把CIB中第二个深层卷积来使用RepVGGDW代替,他有一个7*7和3*3卷积深度卷积,他可以扩大感受野,增强模型能力。
class RepVGGDW(torch.nn.Module):
def __init__(self, ed) -> None:
super().__init__()
self.conv = Conv(ed, ed, 7, 1, 3, g=ed, act=False)
self.conv1 = Conv(ed, ed, 3, 1, 1, g=ed, act=False)
self.dim = ed
self.act = nn.SiLU()
def forward(self, x):
return self.act(self.conv(x) + self.conv1(x))3.2 PSA介绍(引入部分自注意力)
具体来说,在1×1卷积后将特征均匀地分为两部分,只将一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块中。然后,两部分通过1×1卷积连接并融合。此外,遵循将查询和键的维度分配为值的一半,并用BatchNorm替换LayerNorm以实现快速推理。
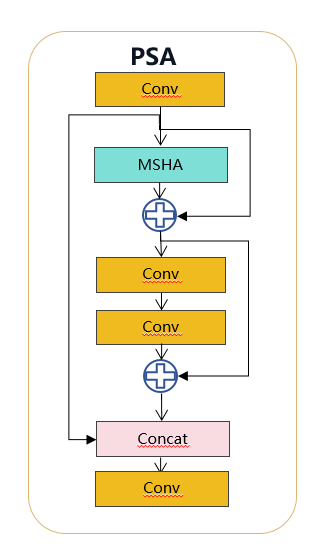
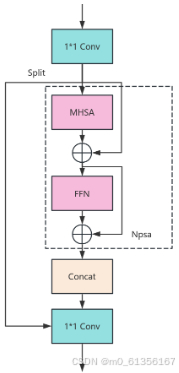
PSA 简化版图示

论文中对这个模块并没有原理上的说明,主要是自注意力的开销比较大,所以设计了 PSA(Partial self-attention)对分辨率最低的特征的一半进行计算,将对于全局的学习能力以较小的计算成本融入 YOLO 中。
Attention 部分的具体计算方式结合下图查看:
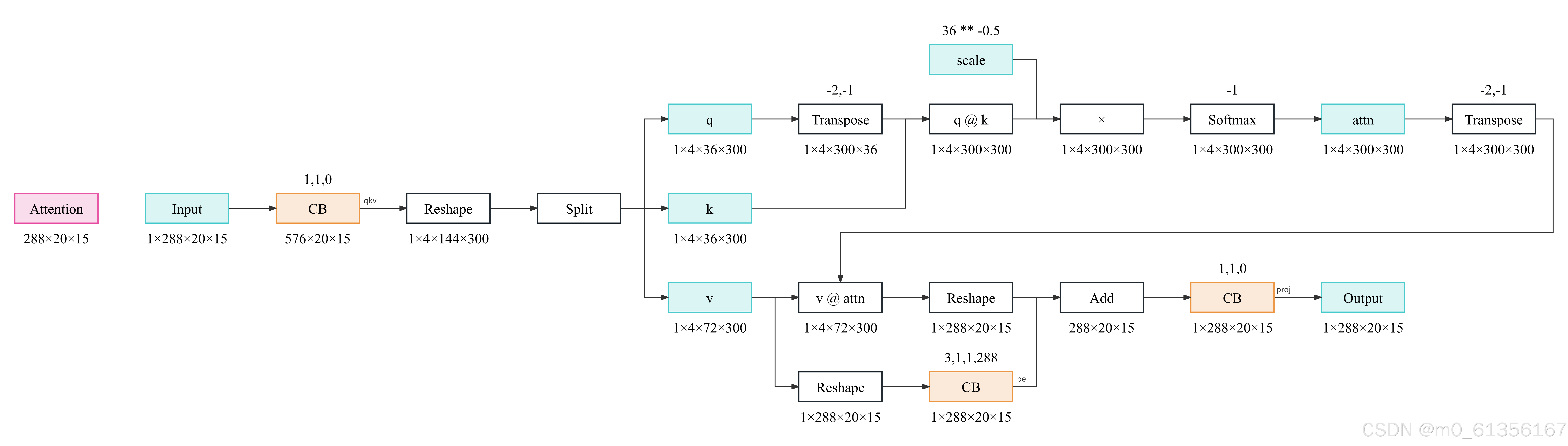
实现代码ultralytics/nn/modules/block.py
class Attention(nn.Module):
def __init__(self, dim, num_heads=8,
attn_ratio=0.5):
super().__init__()
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.key_dim = int(self.head_dim * attn_ratio)
self.scale = self.key_dim ** -0.5
nh_kd = nh_kd = self.key_dim * num_heads
h = dim + nh_kd * 2
self.qkv = Conv(dim, h, 1, act=False)
self.proj = Conv(dim, dim, 1, act=False)
self.pe = Conv(dim, dim, 3, 1, g=dim, act=False)
def forward(self, x):
B, _, H, W = x.shape
N = H * W
qkv = self.qkv(x)
q, k, v = qkv.view(B, self.num_heads, -1, N).split([self.key_dim, self.key_dim, self.head_dim], dim=2)
attn = (
(q.transpose(-2, -1) @ k) * self.scale
)
attn = attn.softmax(dim=-1)
x = (v @ attn.transpose(-2, -1)).view(B, -1, H, W) + self.pe(v.reshape(B, -1, H, W))
x = self.proj(x)
return x
class PSA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert(c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = Attention(self.c, attn_ratio=0.5, num_heads=self.c // 64)
self.ffn = nn.Sequential(
Conv(self.c, self.c*2, 1),
Conv(self.c*2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))3.3 SCDown(空间通道解耦下采样)
- 与v8中的卷积不同,v8使用一个标准卷积同时实现空间下采样 h , w → h / 2 , w / 2 ,h,w→ h/2, w/2h,w→h/2,w/2 和通道变化 c → 2c ,计算成本高。
- SCDown(Spatial-channel decoupled downsampling)将上面两个操作——空间和通道解耦。先通过 1 × 1 的逐点卷积调节通道数,再通过 3 × 3 的深度卷积做空间下采样,在降低计算成本的同时最大限度保留信息。
参数量和计算量计算过程:
v8:
使用一个标准卷积同时实现空间下采样 h , w → h / 2 , w / 2 ,h,w→ h/2, w/2h,w→h/2,w/2 和通道变化 c → 2c
![]()
![]()
v10:
SCDown:先通过 1 × 1 的逐点卷积调节通道数,再通过 3 × 3 的深度卷积做空间下采样,降低计算成本同时保持竞争力的性能:

![]()
![]()
总参数量:
![]()
![]()
总计算量:
实现代码ultralytics/nn/modules/block.py
class SCDown(nn.Module):
def __init__(self, c1, c2, k, s):
super().__init__()
self.cv1 = Conv(c1, c2, 1, 1)
self.cv2 = Conv(c2, c2, k=k, s=s, g=c2, act=False)
def forward(self, x):
return self.cv2(self.cv1(x))4.代码解析
4.1源码整体架构
YOLOv10作为一款实时端到端目标检测算法,其源码采用了模块化设计,结构清晰,易于扩展。以下是YOLOv10的整体架构图:

YOLOv10的源码主要包含以下几个核心目录:
| 目录名 | 主要功能 | 核心文件 |
| ultralytics/models/yolov10 | YOLOv10模型定义 | model.py, train.py, predict.py |
| ultralytics/engine | 训练、推理、验证等引擎 | trainer.py, predictor.py, validator.py |
| ultralytics/data | 数据加载与预处理 | dataset.py, loaders.py, augment.py |
| ultralytics/nn | 神经网络组件 | layers.py, loss.py, activations.py |
| ultralytics/utils | 工具函数 | general.py, metrics.py, plotting.py |
| ultralytics/cfg | 配置文件 | default.yaml, models/ |
4.2 核心模块详细解析
1. 模型模块 (models/yolov10)
该模块包含了YOLOv10模型的核心定义,是二次开发中最常需要修改的部分。
model.py
class YOLOv10:
def __init__(self, model="yolov10n.pt", task=None, verbose=False, names=None):
"""初始化YOLOv10模型"""
# 模型初始化代码
def train(self, **kwargs):
"""训练模型"""
# 训练逻辑代码
def predict(self, source, **kwargs):
"""推理预测"""
# 推理逻辑代码
def val(self, **kwargs):
"""验证模型"""
# 验证逻辑代码
def export(self, **kwargs):
"""导出模型"""
# 模型导出代码train.py
该文件包含了YOLOv10的训练逻辑,关键函数有:
def get_validator(self):
"""获取验证器"""
# 代码实现
def get_model(self, cfg=None, weights=None, verbose=True):
"""获取模型"""
# 代码实现predict.py
该文件包含了推理预测相关的代码,核心函数为:
def postprocess(self, preds, img, orig_imgs):
"""后处理预测结果"""
# 代码实现2. 引擎模块 (engine)
引擎模块是YOLOv10的核心驱动部分,负责协调各个组件完成训练、推理等任务。
trainer.py
训练引擎的核心类,负责整个训练过程的调度:
class Trainer:
def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
"""初始化训练器"""
# 初始化代码
def train(self):
"""开始训练"""
# 训练主逻辑
def setup_model(self):
"""设置模型"""
# 模型设置代码
def get_dataloader(self, dataset_path, batch_size=16, rank=0, mode="train"):
"""获取数据加载器"""
# 数据加载器代码
def validate(self):
"""验证模型"""
# 验证代码predictor.py
推理预测引擎,负责处理输入数据并生成预测结果:
class Predictor:
def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
"""初始化预测器"""
# 初始化代码
def preprocess(self, im):
"""预处理输入图像"""
# 预处理代码
def inference(self, im, *args, **kwargs):
"""执行推理"""
# 推理代码
def postprocess(self, preds, img, orig_imgs):
"""后处理预测结果"""
# 后处理代码validator.py
验证引擎,用于评估模型性能:
class Validator:
def __init__(self, dataloader=None, save_dir=None, pbar=None, args=None, _callbacks=None):
"""初始化验证器"""
# 初始化代码
def __call__(self, trainer=None, model=None):
"""执行验证"""
# 验证代码
def update_metrics(self, preds, batch):
"""更新评估指标"""
# 指标更新代码
def finalize_metrics(self, *args, **kwargs):
"""最终化评估指标"""
# 指标计算代码3. 数据处理模块 (data)
数据处理模块负责数据的加载、增强和预处理,为模型训练和推理提供高质量的数据。
dataset.py
定义了数据集类,负责数据的加载和预处理:
class YOLODataset:
def __init__(self, img_path, imgsz=640, cache=False, augment=True, hyp=DEFAULT_CFG, prefix="", rect=False, batch_size=16, stride=32, pad=0.5, single_cls=False, classes=None, fraction=1.0):
"""初始化数据集"""
# 初始化代码
def __getitem__(self, index):
"""获取数据项"""
# 获取数据代码
def __len__(self):
"""获取数据集大小"""
# 返回数据集大小augment.py
提供了丰富的数据增强方法:
class Albumentations:
def __init__(self) -> None:
"""初始化数据增强器"""
# 初始化代码
def __call__(self, labels):
"""应用数据增强"""
# 数据增强代码
class MixUp:
def __init__(self, dataset, pre_transform=None, p=0.0) -> None:
"""初始化MixUp增强器"""
# 初始化代码
def __call__(self, labels):
"""应用MixUp增强"""
# MixUp代码4. 神经网络模块 (nn)
神经网络模块包含了YOLOv10的网络结构定义,包括各种层、块和损失函数。
blocks.py
定义了YOLOv10中使用的各种网络块:
class CSPDarknetBlock(nn.Module):
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
"""初始化CSPDarknet块"""
# 初始化代码
def forward(self, x):
"""前向传播"""
# 前向传播代码
class SPPF(nn.Module):
def __init__(self, c1, c2, k=5):
"""初始化SPPF块"""
# 初始化代码
def forward(self, x):
"""前向传播"""
# 前向传播代码head.py
定义了YOLOv10的检测头:
class Detect(nn.Module):
def __init__(self, nc=80, ch=()):
"""初始化检测头"""
# 初始化代码
def forward(self, x):
"""前向传播"""
# 前向传播代码loss.py
定义了YOLOv10的损失函数:
class ComputeLoss:
def __init__(self, model, tal_topk=10):
"""初始化损失计算器"""
# 初始化代码
def __call__(self, preds, batch):
"""计算损失"""
# 损失计算代码5. 工具函数模块 (utils)
工具函数模块提供了各种辅助功能,包括指标计算、可视化、文件操作等。
metrics.py
提供了各种评估指标的计算方法:
def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7):
"""计算边界框IOU"""
# IOU计算代码
def ap_per_class(tp, conf, pred_cls, target_cls, plot=False, on_plot=None, save_dir=Path(), names=(), eps=1e-16, prefix=""):
"""计算每个类别的AP"""
# AP计算代码plotting.py
提供了可视化功能:
def plot_images(images, batch_idx, cls, bboxes=np.zeros(0, dtype=np.float32), confs=None, masks=np.zeros(0, dtype=np.uint8), kpts=np.zeros((0, 51), dtype=np.float32), paths=None, fname="images.jpg", names=None, on_plot=None, max_subplots=16, save=True, conf_thres=0.25):
"""绘制图像及预测结果"""
# 绘图代码
def plot_results(file="path/to/results.csv", dir="", segment=False, pose=False, classify=False, on_plot=None):
"""绘制训练结果"""
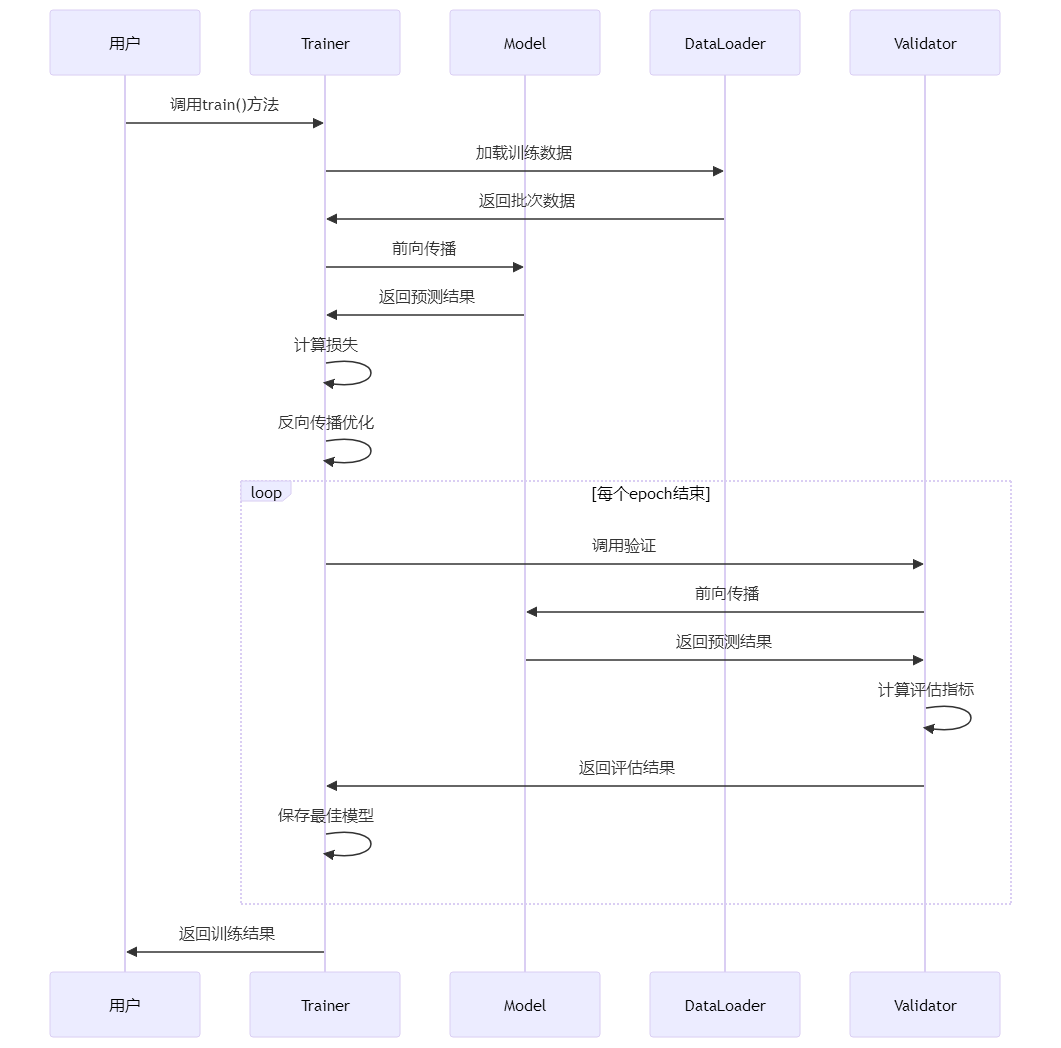
# 绘图代码4.3 核心模块交互流程
训练流程
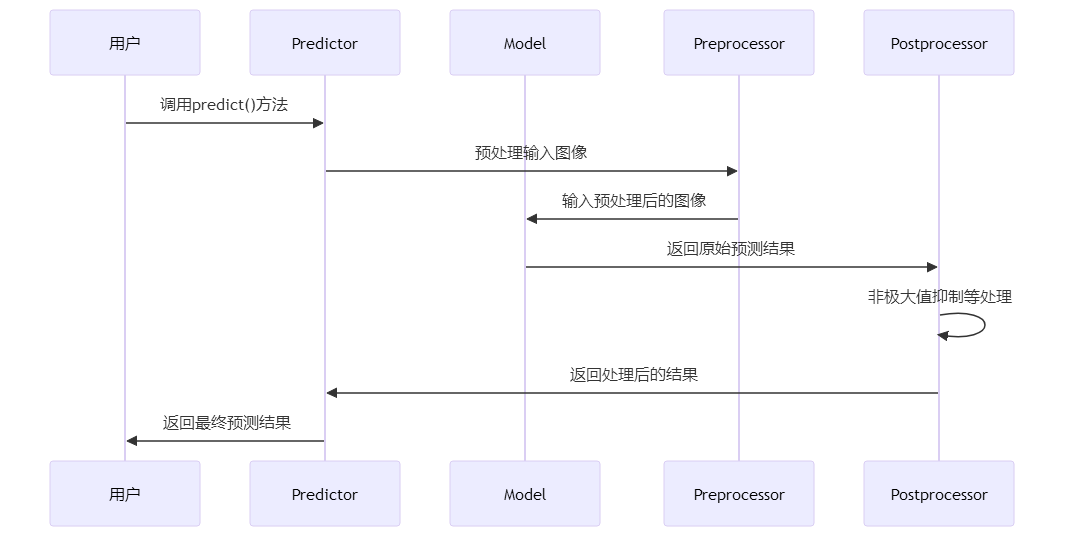
推理流程
5. 二次开发实战示例
示例1:修改损失函数
要修改YOLOv10的损失函数,可以按照以下步骤进行:
1. 在ultralytics/nn/loss.py中定义新的损失类:
class NewComputeLoss:
def __init__(self, model):
"""初始化新的损失计算器"""
# 初始化代码
def __call__(self, preds, batch):
"""计算新的损失"""
# 新的损失计算逻辑2.在训练器中使用新的损失函数:
# 在trainer.py中
from ultralytics.nn.loss import NewComputeLoss
class Trainer:
def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
# ... 其他初始化代码
self.loss_fn = NewComputeLoss(self.model)示例2:添加新的数据增强方法
要添加新的数据增强方法,可以在ultralytics/data/augment.py中添加:
class NewAugmentation:
def __init__(self, p=0.5):
"""初始化新的数据增强器"""
self.p = p
def __call__(self, labels):
"""应用新的数据增强"""
if random.random() < self.p:
# 新的数据增强逻辑
return labels然后在数据集类中使用新的增强方法:
class YOLODataset:
def __init__(self, img_path, imgsz=640, cache=False, augment=True, hyp=DEFAULT_CFG, prefix="", rect=False, batch_size=16, stride=32, pad=0.5, single_cls=False, classes=None, fraction=1.0):
# ... 其他初始化代码
self.augmentations = Albumentations()
self.augmentations.append(NewAugmentation(p=0.5))常见二次开发场景及解决方案
场景1:修改模型结构
如果你想修改YOLOv10的网络结构,可以按照以下步骤进行:
在ultralytics/nn/blocks.py中定义新的网络块
在ultralytics/cfg/models/v10目录下修改对应的yaml配置文件
在ultralytics/models/yolov10/model.py中加载新的配置文件
场景2:添加新的评估指标
如果你想添加新的评估指标,可以在ultralytics/utils/metrics.py中添加相应的计算函数,并在ultralytics/engine/validator.py的finalize_metrics方法中调用新的指标计算函数。
场景3:自定义数据加载
如果你需要加载自定义格式的数据,可以继承ultralytics/data/base.py中的BaseDataset类,并重写__getitem__方法。



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










