




 这篇博客总结了使用seaborn库进行线性关系分析的方法,包括regplot()和lmplot()函数的运用,探讨了单变量及多变量的关系,并指出lmplot()在处理多变量关系时的优势,适合数据探索和分析。
这篇博客总结了使用seaborn库进行线性关系分析的方法,包括regplot()和lmplot()函数的运用,探讨了单变量及多变量的关系,并指出lmplot()在处理多变量关系时的优势,适合数据探索和分析。
学习https://seaborn.pydata.org 记录,描述不一定准确,具体请参考官网
%matplotlib inline
import numpy as np
import pandas as pd
from scipy import stats, integrate
import seaborn as sns
import matplotlib.pyplot as plt
# seaborn中文乱码解决方案
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf',size=14)
sns.set(font=myfont.get_name())np.random.seed(sum(map(ord, "regression")))
tips = sns.load_dataset("tips")线性回归
1、regplot()
# 简单使用regplot()
sns.regplot(x="total_bill", y="tip", data=tips)
2、lmplot()
# 简单使用lmplot()
sns.lmplot(x="total_bill", y="tip", data=tips)
# x_jitter 表示沿轴随机分布,相对避免重叠
sns.lmplot(x="size", y="tip", data=tips, x_jitter=.05)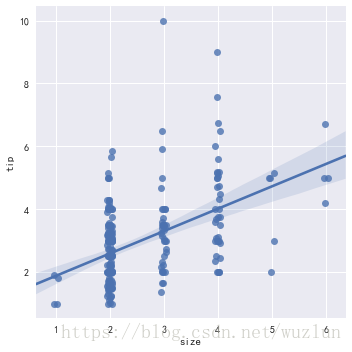
sns.lmplot(x="size", y="tip", data=tips, x_estimator=np.mean)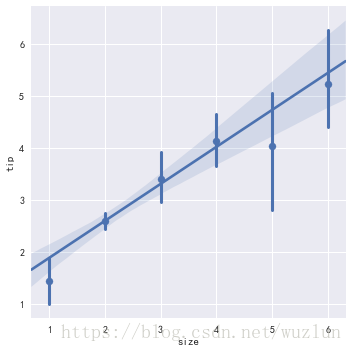
拟合不同模型
anscombe = sns.load_dataset("anscombe")
anscombe[::-5]| dataset | x | y | |
|---|---|---|---|
| 43 | IV | 8.0 | 6.89 |
| 38 | IV | 8.0 | 7.04 |
| 33 | IV | 8.0 | 6.58 |
| 28 | III | 6.0 | 6.08 |
| 23 | III | 8.0 | 6.77 |
| 18 | II | 4.0 | 3.10 |
| 13 | II | 13.0 | 8.74 |
| 8 | I | 12.0 | 10.84 |
| 3 | I | 9.0 | 8.81 |
1、lmplot()
# 原来数据还可以这样查询 anscombe.query("dataset == 'I'")
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'I'"), ci=None, scatter_kws={"s": 80})
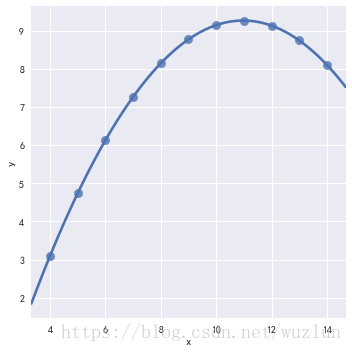
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),ci=None, scatter_kws={"s": 80})
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'II'"),order=2, ci=None, scatter_kws={"s": 80})
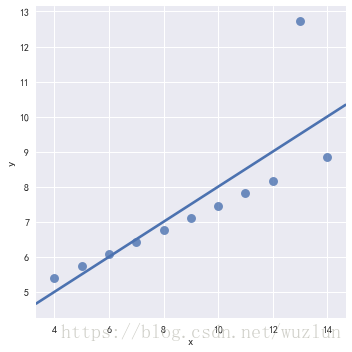
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"),ci=None, scatter_kws={"s": 80})
# robust=True 使用 robust回归
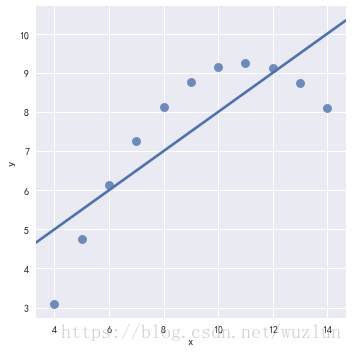
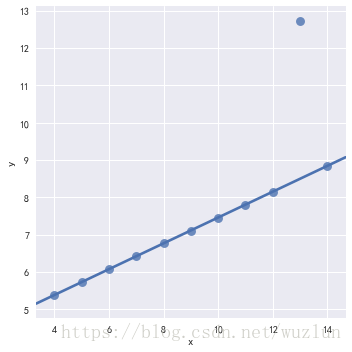
sns.lmplot(x="x", y="y", data=anscombe.query("dataset == 'III'"),robust=True, ci=None, scatter_kws={"s": 80})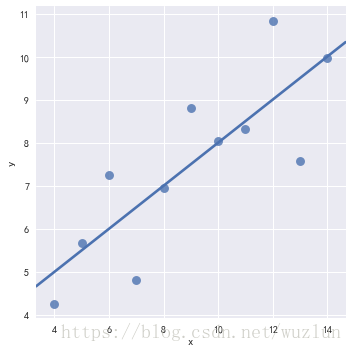
tips["big_tip"] = (tips.tip / tips.total_bill) > .15
sns.lmplot(x="total_bill", y="big_tip", data=tips, y_jitter=.03)
# 使用逻辑回归
sns.lmplot(x="total_bill", y="big_tip", data=tips,logistic=True, y_jitter=.03)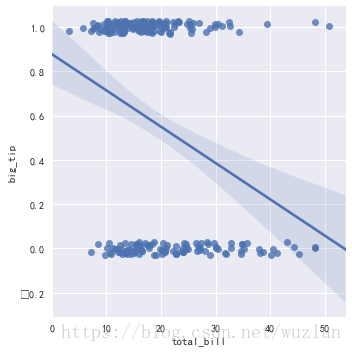
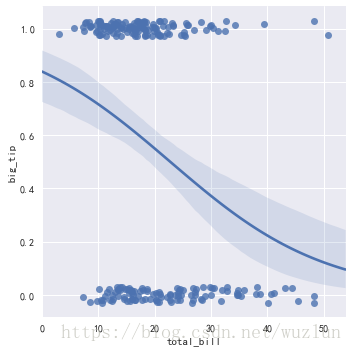
# 非参数回归
sns.lmplot(x="total_bill", y="tip", data=tips,lowess=True)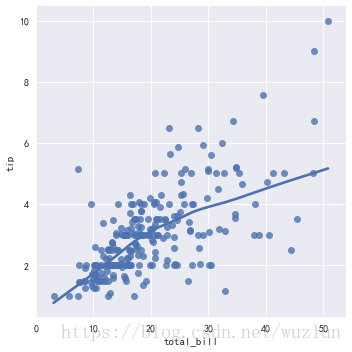
2、regplot()
# 绘制残差分布
sns.residplot(x="x", y="y", data=anscombe.query("dataset == 'I'"),scatter_kws={"s": 80});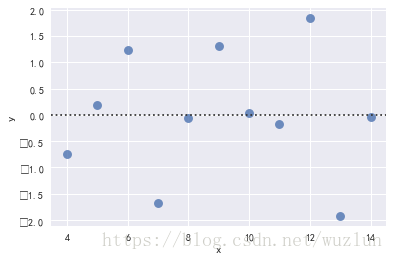
多变量关系
上面的图表展示了许多探索一对变量之间关系的方法。很多时候,我们更关心两个变量变化是如何影响第三个变量的。这也是lmplot()~与regplot()的区别之一。regplot()只能显示一对变量之间的关系,而lmplot()结合了regplot()与FacetGrid,提供了一个简单的接口,允许你探索最多其他三个分类变量的影响。
# 增加分类
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips)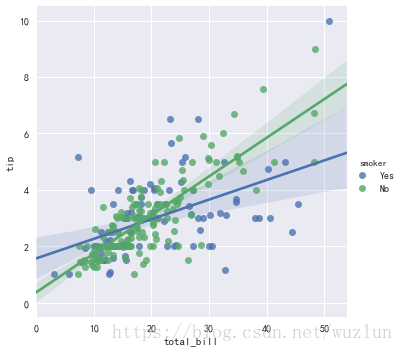
# 增加样式
sns.lmplot(x="total_bill", y="tip", hue="smoker", data=tips, markers=["o", "x"], palette="Set1")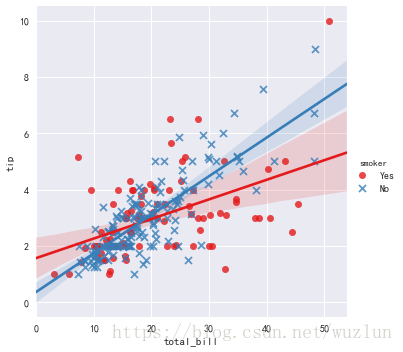
# 横向增加时间变量
sns.lmplot(x="total_bill", y="tip", hue="smoker", col="time", data=tips);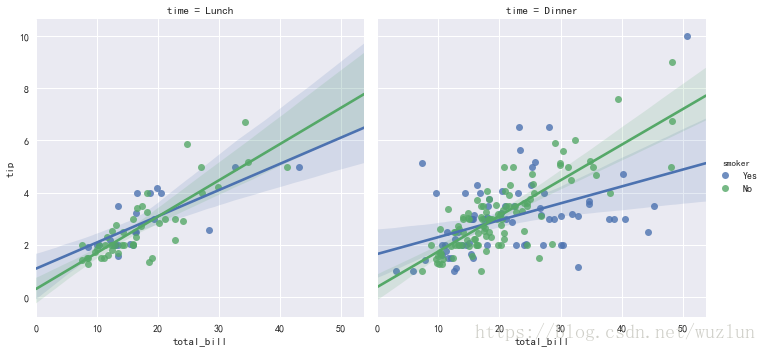
# 纵向增加性别变量
sns.lmplot(x="total_bill", y="tip", hue="smoker",col="time", row="sex", data=tips);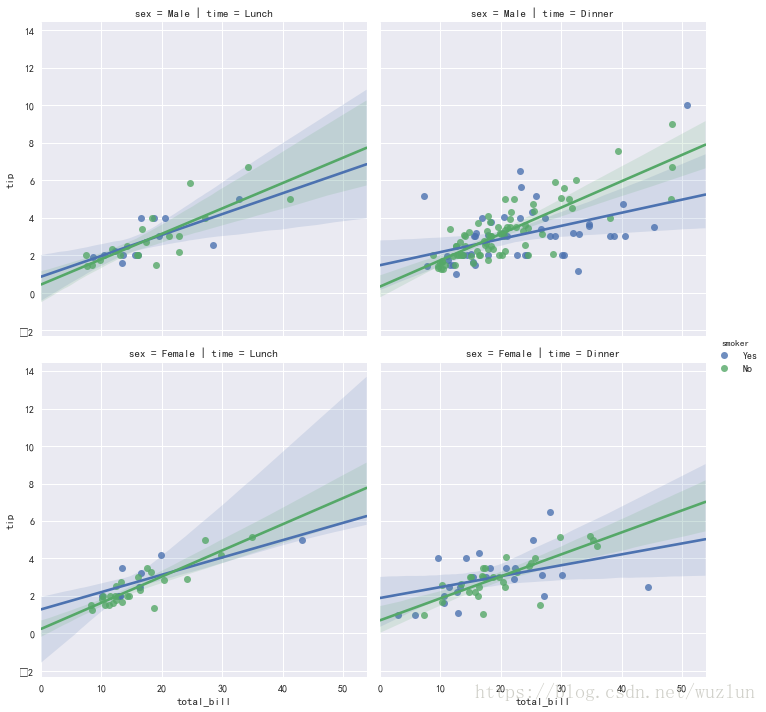
# 分两行显示 col_wrap=2
sns.lmplot(x="total_bill", y="tip", col="day",col_wrap=2,data=tips)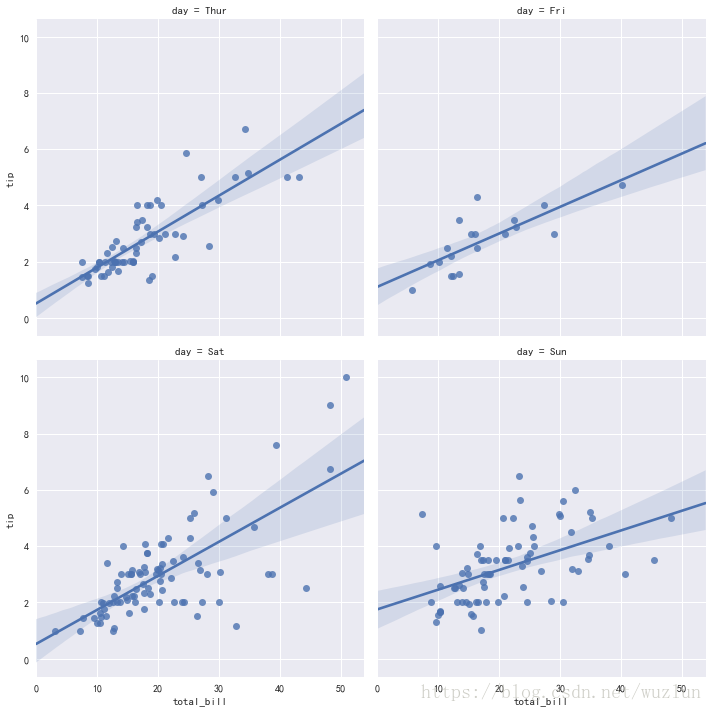


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










