




【C/C++】从 POSIX Socket 到 TCP 生命周期:一文理解网络 IO 的核心原理
一、先建立一张总图:socket API 调用链
客户端与服务器的 API 看起来是两条不同的路径,但它们最终都围绕同一件事:让用户态代码拿到一个文件描述符 fd,并通过这个 fd 操作内核里的 TCP 连接。
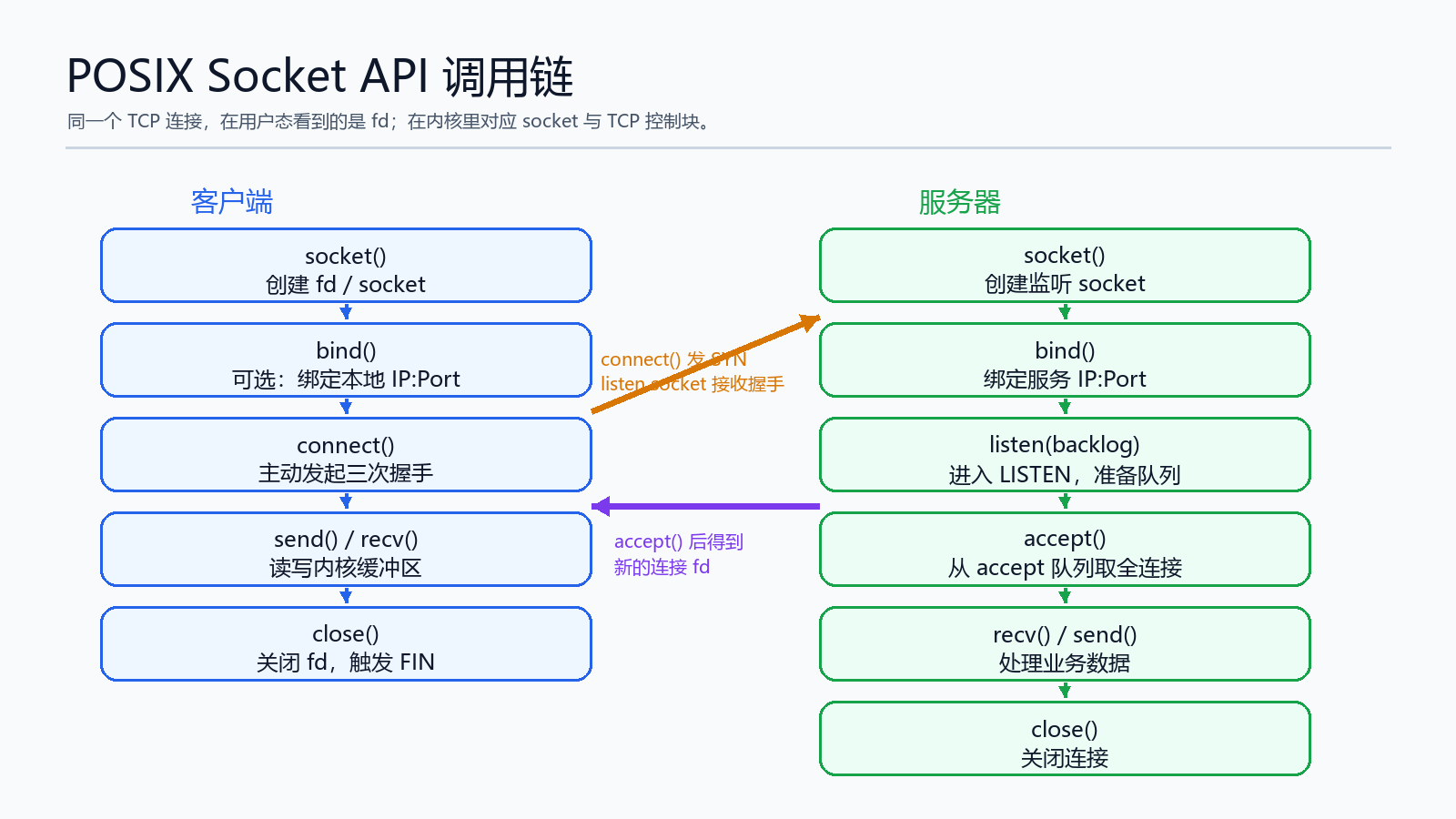
典型客户端调用顺序:
socket() -> bind() 可选 -> connect() -> send()/recv() -> close()
典型服务器调用顺序:
socket() -> bind() -> listen() -> accept() -> recv()/send() -> close()
这里有一个很重要的理解:网络编程表面上是在读写 fd,本质上是在驱动内核维护 socket、TCP 控制块、收发缓冲区以及 TCP 状态机。
二、socket():创建 fd 与 TCP 控制块
socket() 的结果通常是一个整数 fd:
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd < 0) {
perror("socket");
return -1;
}
对应用层来说,fd 像一个“句柄”;对内核来说,它背后关联着 socket 对象和协议控制块。对于 TCP 连接,控制块里会保存本端地址、对端地址、端口、状态、窗口、序列号、重传定时器等信息。
可以把它粗略理解成:
用户态 fd
-> 内核 file
-> socket
-> TCP 控制块
这也是为什么我们说“fd 对应一个连接”,更准确地说是“fd 通过内核对象间接引用一个连接”。
三、bind():把 IP 和端口写入控制块
服务器必须 bind(),因为它需要告诉内核:我要监听哪个本地 IP 和端口。
struct sockaddr_in addr = {0};
addr.sin_family = AF_INET;
addr.sin_port = htons(8080);
addr.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(fd, (struct sockaddr *)&addr, sizeof(addr)) < 0) {
perror("bind");
return -1;
}
客户端通常不需要显式 bind()。如果不手动绑定,内核会自动选择一个本地临时端口。只有在需要固定本地端口、多网卡选择出口 IP、或做特殊网络测试时,客户端才常见显式 bind()。
四、listen(backlog):进入 LISTEN,并准备队列
listen(fd, backlog) 不是“开始 accept”,而是把 socket 变成监听 socket,让 TCP 状态进入 LISTEN,并准备处理连接建立过程中的队列。
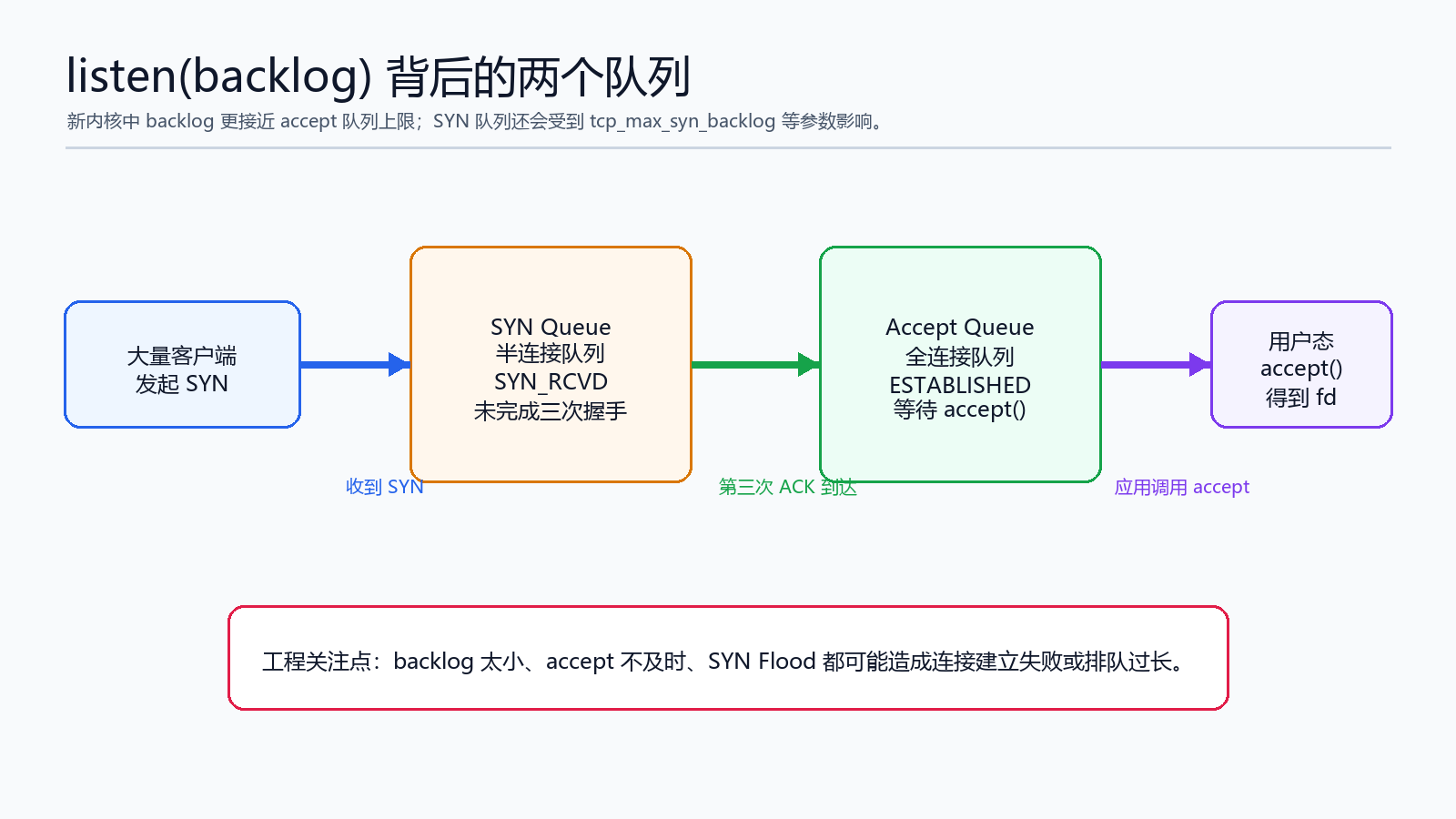
常见理解里,服务端连接建立会涉及两个队列:
SYN Queue:半连接队列,保存已经收到 SYN、回复了 SYN+ACK,但还没有收到第三次 ACK 的连接。Accept Queue:全连接队列,三次握手完成后,连接进入这里,等待应用层accept()取走。
历史上,不同内核版本对 backlog 的语义有所变化。工程上更实用的记法是:
listen(backlog)影响全连接排队能力。- SYN 队列还会受到
tcp_max_syn_backlog、SYN Cookie 等机制影响。 accept()不及时,会让全连接队列堆积,最终导致新连接建立变慢或失败。
可以用下面的命令观察相关配置:
sysctl net.core.somaxconn
sysctl net.ipv4.tcp_max_syn_backlog
ss -lnt
五、TCP 三次握手:确认双方初始序列号
三次握手不只是“连上了”,更关键的是双方同步初始序列号,并确认双方收发能力正常。
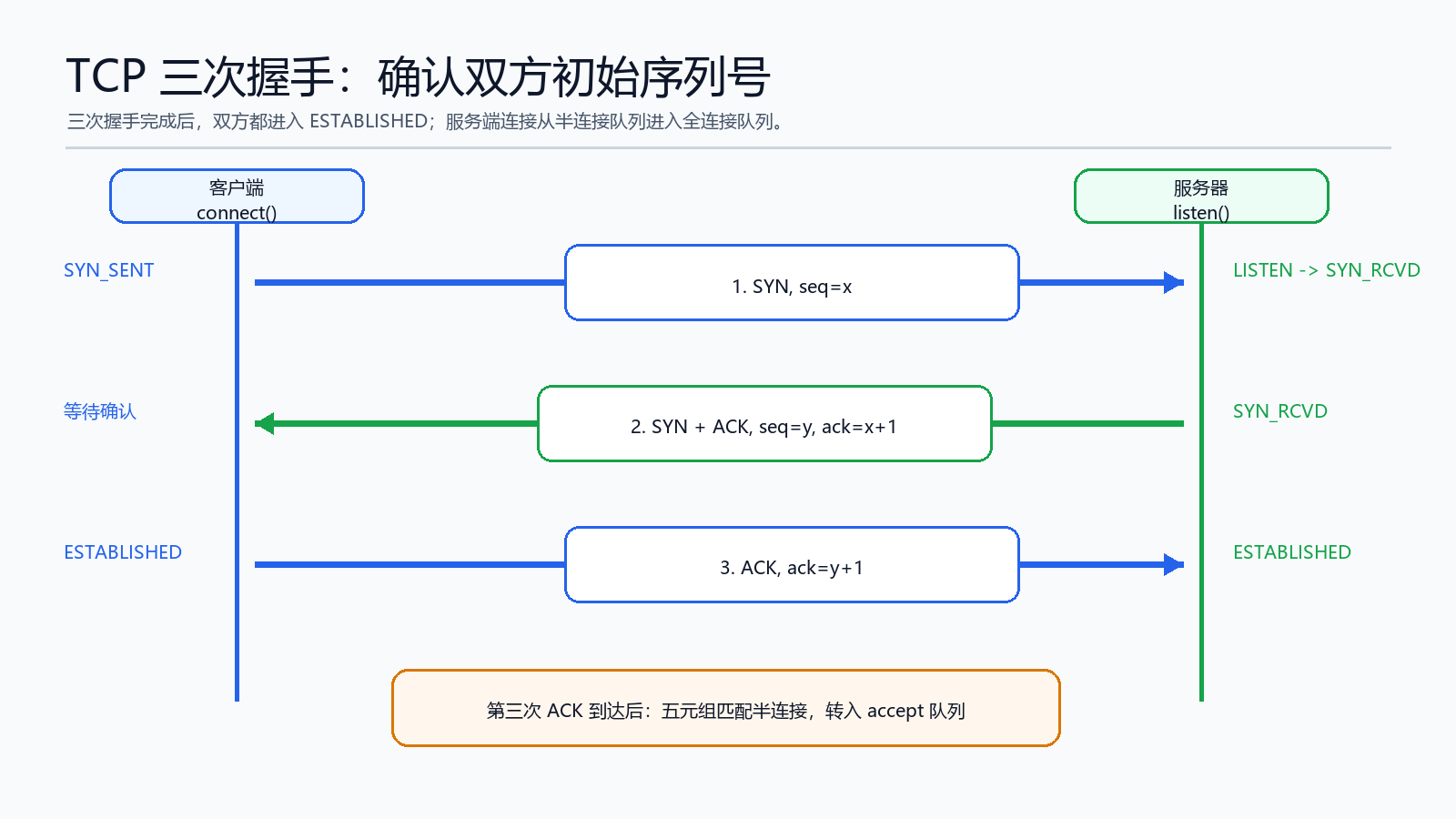
简化过程如下:
1. 客户端 connect(),发送 SYN,seq = x,进入 SYN_SENT
2. 服务端收到 SYN,进入 SYN_RCVD,回复 SYN + ACK,seq = y,ack = x + 1
3. 客户端收到后进入 ESTABLISHED,回复 ACK,ack = y + 1
4. 服务端收到第三次 ACK,连接进入 ESTABLISHED,并进入 accept 队列
第三次 ACK 到达服务端时,内核会根据五元组查找对应半连接:
源 IP、源端口、目的 IP、目的端口、协议
找到后,连接从半连接队列迁移到全连接队列。此时应用层调用 accept(),才能得到一个新的连接 fd。
一个容易忽略的点:P2P 同时打开
普通 C/S 模型里,服务器先 listen(),客户端再 connect()。但 TCP 协议本身支持 simultaneous open:双方都没有处于 LISTEN,而是同时发起 connect(),双方互相发送 SYN,也可能建立连接。这类场景在 P2P、打洞和协议实验里更容易遇到。
六、accept():从全连接队列取连接
accept() 做的事情可以粗略理解为:
从 accept queue 取出一个已完成握手的连接
为这个连接分配一个新的 fd
让应用层后续通过这个 fd recv/send
如果监听 fd 设置了边缘触发 EPOLLET,必须把监听 fd 设置成非阻塞,并且在一次事件通知里循环 accept(),直到返回 EAGAIN。
while (1) {
int cfd = accept4(listenfd, NULL, NULL, SOCK_NONBLOCK);
if (cfd >= 0) {
// 把 cfd 加入 epoll,后续关注读写事件
add_epoll(epfd, cfd, EPOLLIN | EPOLLRDHUP | EPOLLET);
continue;
}
if (errno == EAGAIN || errno == EWOULDBLOCK) {
// accept queue 已经取空
break;
}
perror("accept4");
break;
}
边缘触发的核心是“状态从无到有时通知一次”。如果你只 accept() 一次,队列里剩下的连接可能不会再次触发通知,导致连接被饿住。
七、send/write 与 recv/read:读写的是内核缓冲区
send() 并不等于“数据已经到达对端业务代码”,它通常只是把数据拷贝到本机内核发送缓冲区,后续由 TCP 协议栈负责分段、重传、拥塞控制和确认。
ssize_t n = send(fd, data, len, 0);
if (n < 0) {
perror("send");
}
recv() 也不是直接从网卡取数据,而是从内核接收缓冲区读取已经到达、按序交付给应用层的数据。
char buf[4096];
ssize_t n = recv(fd, buf, sizeof(buf), 0);
if (n > 0) {
// buf[0..n) 是本次读到的数据
} else if (n == 0) {
// 对端关闭连接
} else {
perror("recv");
}
TCP 在传输阶段还会涉及:
- 滑动窗口:控制发送方最多可以发送多少未确认数据。
- 慢启动:拥塞窗口从小到大试探网络容量。
- 拥塞控制:根据丢包、延迟等信号调节发送速率。
- 延迟确认:接收端可能稍后再 ACK,以减少小包。
- 超时重传:数据迟迟没有确认时重新发送。
这些机制都说明:应用层的一次 send(),不等于网络上的一次完整传输。
八、epoll + Reactor:把连接存储和事件分发解耦
当连接数上来之后,服务器通常不会为每个连接创建一个线程,而是用 epoll 等 IO 多路复用机制管理大量 fd。
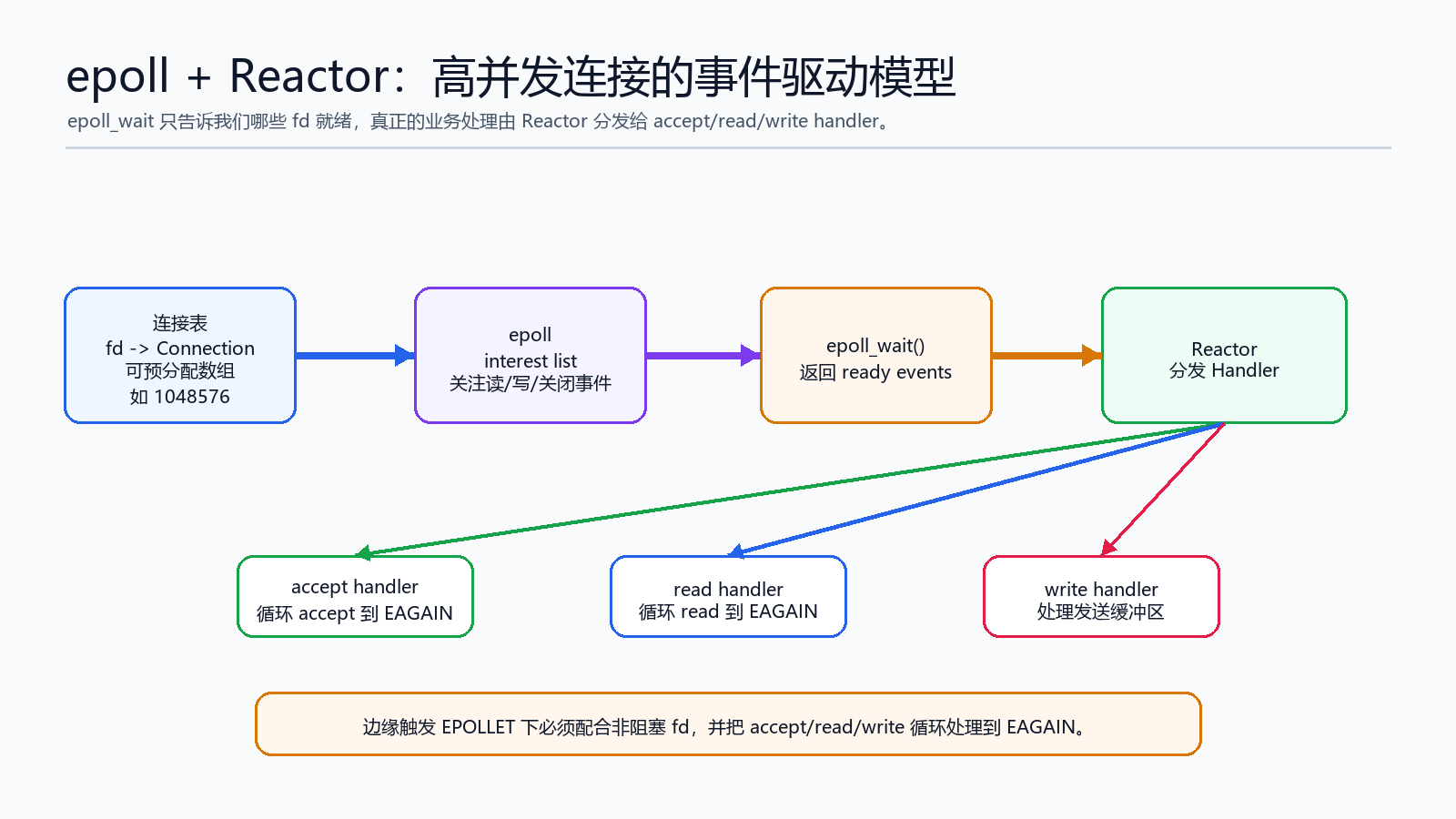
典型 Reactor 思路:
连接表保存 fd -> Connection
epoll 负责监听 fd 就绪事件
epoll_wait 返回活跃事件
Reactor 根据事件类型分发给不同 handler
如果你要优化 Reactor 的连接存储,可以考虑按 fd 直接索引一个连接数组。比如预分配 1048576 个槽位:
#define MAX_CONN 1048576
typedef struct connection {
int fd;
char rbuf[4096];
char wbuf[4096];
size_t wlen;
} connection_t;
static connection_t *connections[MAX_CONN];
connection_t *get_conn(int fd) {
if (fd < 0 || fd >= MAX_CONN) {
return NULL;
}
return connections[fd];
}
这种方式查询快,代价是数组空间固定。如果 fd 上限很大、连接稀疏,也可以改成哈希表或对象池。
九、完整代码片段:epoll 边缘触发 Echo Server
下面是一个精简版 Linux C 示例,重点展示监听 socket、非阻塞、epoll_wait、循环 accept/read 的结构。
#define _GNU_SOURCE
#include <arpa/inet.h>
#include <errno.h>
#include <fcntl.h>
#include <netinet/in.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/epoll.h>
#include <sys/socket.h>
#include <unistd.h>
#define MAX_EVENTS 1024
static int set_nonblock(int fd) {
int flags = fcntl(fd, F_GETFL, 0);
if (flags < 0) return -1;
return fcntl(fd, F_SETFL, flags | O_NONBLOCK);
}
static void add_epoll(int epfd, int fd, uint32_t events) {
struct epoll_event ev;
memset(&ev, 0, sizeof(ev));
ev.events = events;
ev.data.fd = fd;
if (epoll_ctl(epfd, EPOLL_CTL_ADD, fd, &ev) < 0) {
perror("epoll_ctl add");
close(fd);
}
}
int main(void) {
int listenfd = socket(AF_INET, SOCK_STREAM, 0);
if (listenfd < 0) {
perror("socket");
return 1;
}
int on = 1;
setsockopt(listenfd, SOL_SOCKET, SO_REUSEADDR, &on, sizeof(on));
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(8080);
addr.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(listenfd, (struct sockaddr *)&addr, sizeof(addr)) < 0) {
perror("bind");
return 1;
}
if (listen(listenfd, SOMAXCONN) < 0) {
perror("listen");
return 1;
}
if (set_nonblock(listenfd) < 0) {
perror("set_nonblock");
return 1;
}
int epfd = epoll_create1(0);
if (epfd < 0) {
perror("epoll_create1");
return 1;
}
add_epoll(epfd, listenfd, EPOLLIN | EPOLLET);
struct epoll_event events[MAX_EVENTS];
char buf[4096];
while (1) {
int n = epoll_wait(epfd, events, MAX_EVENTS, -1);
if (n < 0) {
if (errno == EINTR) continue;
perror("epoll_wait");
break;
}
for (int i = 0; i < n; ++i) {
int fd = events[i].data.fd;
uint32_t ev = events[i].events;
if (fd == listenfd) {
while (1) {
int cfd = accept4(listenfd, NULL, NULL, SOCK_NONBLOCK);
if (cfd >= 0) {
add_epoll(epfd, cfd, EPOLLIN | EPOLLRDHUP | EPOLLET);
continue;
}
if (errno == EAGAIN || errno == EWOULDBLOCK) break;
perror("accept4");
break;
}
continue;
}
if (ev & (EPOLLERR | EPOLLHUP | EPOLLRDHUP)) {
close(fd);
continue;
}
if (ev & EPOLLIN) {
while (1) {
ssize_t len = read(fd, buf, sizeof(buf));
if (len > 0) {
// Echo:读到什么就写回什么。真实业务要处理半包、粘包和写缓冲。
ssize_t off = 0;
while (off < len) {
ssize_t wn = write(fd, buf + off, (size_t)(len - off));
if (wn > 0) {
off += wn;
} else if (wn < 0 && (errno == EAGAIN || errno == EWOULDBLOCK)) {
break;
} else {
close(fd);
break;
}
}
continue;
}
if (len == 0) {
close(fd);
break;
}
if (errno == EAGAIN || errno == EWOULDBLOCK) {
break;
}
perror("read");
close(fd);
break;
}
}
}
}
close(epfd);
close(listenfd);
return 0;
}
编译运行:
gcc -O2 -Wall -Wextra epoll_echo.c -o epoll_echo
./epoll_echo
客户端可以用 nc 测试:
nc 127.0.0.1 8080
十、TCP 四次挥手:为什么主动关闭方会 TIME_WAIT
连接关闭时,close() 会回收用户态 fd,并驱动 TCP 发送 FIN。常见过程如下:
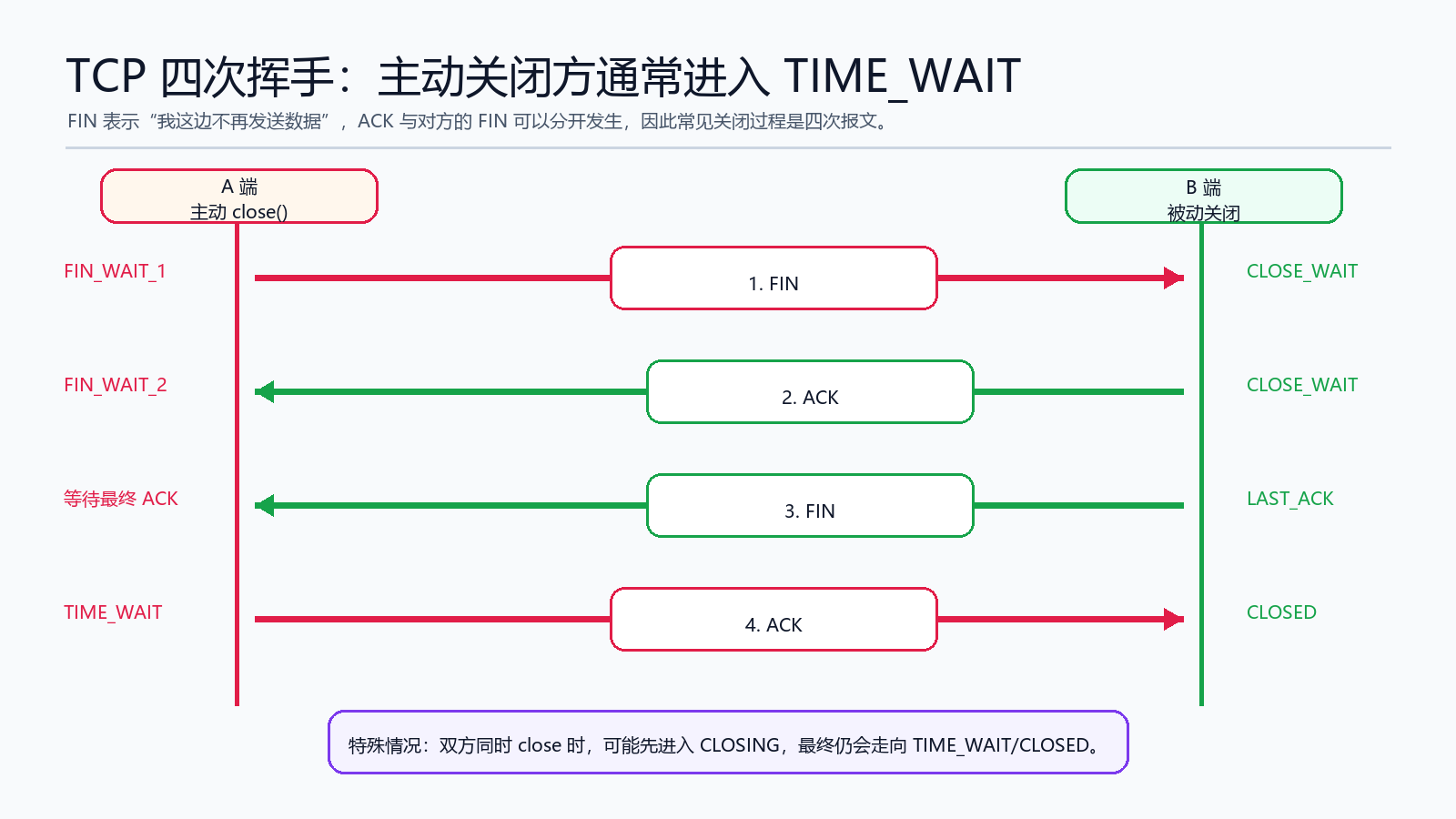
简化状态迁移:
A 主动 close:FIN_WAIT_1 -> FIN_WAIT_2 -> TIME_WAIT -> CLOSED
B 被动关闭:CLOSE_WAIT -> LAST_ACK -> CLOSED
为什么经常是四次?因为 TCP 是全双工协议。A 说“我不发了”不代表 B 也立刻不发。B 可以先 ACK A 的 FIN,等业务层也关闭后再发送自己的 FIN。
TIME_WAIT 的意义主要有两个:
- 确保最后一个 ACK 有机会被对端收到;如果丢了,对端会重传 FIN。
- 等待网络中旧报文自然消失,避免影响后续复用同一四元组的新连接。
还有一种特殊情况:双方同时 close(),都在 FIN_WAIT_1 时先收到对方 FIN,就会进入 CLOSING,最终仍会走向 TIME_WAIT 或 CLOSED。
至于 shutdown(),它用于半关闭连接,例如只关闭写方向但继续读。普通业务如果不需要半关闭,直接 close() 更简单;如果协议需要“我发完了,但还要等你响应”,再考虑 shutdown(fd, SHUT_WR)。
十一、客户端最小代码片段
最后给一个最小 TCP 客户端,用来和前面的服务器配合测试。
#include <arpa/inet.h>
#include <stdio.h>
#include <string.h>
#include <sys/socket.h>
#include <unistd.h>
int main(void) {
int fd = socket(AF_INET, SOCK_STREAM, 0);
if (fd < 0) {
perror("socket");
return 1;
}
struct sockaddr_in addr;
memset(&addr, 0, sizeof(addr));
addr.sin_family = AF_INET;
addr.sin_port = htons(8080);
inet_pton(AF_INET, "127.0.0.1", &addr.sin_addr);
if (connect(fd, (struct sockaddr *)&addr, sizeof(addr)) < 0) {
perror("connect");
return 1;
}
const char *msg = "hello tcp\n";
send(fd, msg, strlen(msg), 0);
char buf[1024];
ssize_t n = recv(fd, buf, sizeof(buf) - 1, 0);
if (n > 0) {
buf[n] = '\0';
printf("recv: %s", buf);
}
close(fd);
return 0;
}
总结
网络 IO 的学习不能只停留在 API 名字上。更好的方式是把 API、内核对象和 TCP 状态机对应起来:
socket()创建 fd,并关联内核 socket/TCP 控制块。bind()设置本地 IP 和端口。listen()进入监听状态,并准备连接队列。connect()触发三次握手。accept()从全连接队列取出连接,并返回新的 fd。send/recv操作的是内核缓冲区,不等于数据立刻到达对端应用。epoll负责事件通知,Reactor 负责事件分发。close()触发连接关闭,主动关闭方通常会进入TIME_WAIT。
当这些概念连成一条线,Linux 网络编程里的很多“为什么”就会变得清楚:为什么 ET 模式要非阻塞?为什么 accept 要循环?为什么 send 可能只写入部分数据?为什么服务端会出现大量 CLOSE_WAIT 或 TIME_WAIT?这些问题的答案,基本都藏在 fd、缓冲区、队列和 TCP 状态机之间。

















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










