



参考书籍:
《互联网大厂推荐算法实践》
感兴趣的朋友可以去看原书😁
3.1 推荐算法中的embedding
embedding是一门自动将概念转换成特征向量的技术,目标是提升推荐算法的扩展能力,从而自动挖掘低频、长尾、小众的模式。
由于推荐系统中的特征高维稀疏,所以我们必须实现稀疏的前代和回代,回代时不用更新整个embedding矩阵,只更新一个batch中出现的几个有限非零特征对应的那几行。实现方式包括tensorflow中的indexslices类。
3.2 共享embedding和独占embedding
3.2.1 共享embedding
共享是指同一套embedding喂入模型的多个地方,发挥多个作用。
优势:1)缓解由于特征稀疏、数据不足导致的训练不充分。2)复用节省存储空间。
例子包括第四章将讲到的FM和第五章将讲到的双塔模型。
3.2.2 独占embedding
优势:1)避免互相干扰。2)更好的进行特征交叉。
1)避免互相干扰。
比如APP的安装,启动,卸载对于embedding有不同的要求,如果用一套embedding难以同时满足所有的要求。
2)更好的进行特征交叉。
比如FM(因子分解机)中,无论第i个特征和哪个特征交叉,FM都是用相同的embedding来生成交叉特征的系数,这样如果模型调整i的embedding以便学习交叉特征的系数,却可能对i和另一个特征组合的系数造成负面影响。
为此,FFM被提出了。FFM的核心思想是,每个特征在与不同特征交叉时,根据对方特征所属的field使用不同的embedding。缺点是参数空间爆炸,因为每个特征有field数个embedding。
之后,阿里巴巴提出了CAN。CAN既像FFM,让每个特征在与其他不同特征交叉时使用完全不同的embedding,也像FM那样不造成参数空间爆炸。
具体步骤如下:
1. 拆解
假设物料的embedding是一个长度为D的一维向量,首先将D均匀分为K段,每段长度为D/K。
2. 变形
假设我们要构建的MLP某一层输入维度为din,输出维度为dout,那么D/K必须先满足D/K=din*dout,然后将D/K变形成din*dout的矩阵。
3. 组装MLP
将第二步产生的矩阵充当MLP网络中的第0层到第K-1层的权重参数。层与层之间插入ReLU。
简单来说,就是把物料的embedding变形成一个小型MLP,然后把用户的embedding喂入这个MLP,输出的结果就是这两个特征交叉的结果。当然,反过来变形用户的embedding,喂入物料的embedding也是可以的。
CAN的优势有两个方面:1)ReLU导致有些位置是0,从而MLP中有些神经元不发挥作用,相当于同一个物料embedding和不同用户embedding交叉时使用不同的embedding,从而减少了不同交叉之间的相互干扰。2)参数空间没有爆炸。
3.3 parameter server:推荐算法的训练加速器
3.3.1 传统分布式计算的不足
推荐系统的数据有两个特点:海量的训练数据,特征空间高维稀疏。
传统的分布式训练无法训练,因为参数量巨大,而且节点之间广播回传所占据的带宽和造成的时延不可想象。
3.3.2 基于PS的分布式训练范式
PS架构是如何克服传统分布式训练架构的困难的:
1)参数由一群PS Server节点共同存储读写,从而突破了单台机器的资源限制。
2)只传递当前batch中有限的几个非零特征的参数,从而大大节省带宽和传输时间。
PS架构中的三类节点功能:
1)worker
从server拉取最新的模型参数
用本地数据训练,计算梯度
向server推送梯度
2)server
存储模型参数
向worker发送模型参数
聚合worker发送的梯度并更新模型参数
3)scheduler
整个PS集群的管理
3.3.3 PS中的并行策略
1. 批量同步并行(BSP)
server等待所有worker推送梯度完成后,汇总梯度并更新模型参数。
缺点:木桶效应,一个慢节点就能拖累整个集群的计算速度。
2. 异步并行(ASP)
每个worker推送自己的梯度后,直接开始下一个batch的数据的训练。
缺点:可能发生梯度失效(stale gradient)问题。
比如有两个worker节点,他们先用θ0版本的参数进行训练,worker1训练好了,向server推送梯度g1,server更新参数为θ1,而这个时候worker2才训练好,但是它用的参数版本还是θ0,这样他算出来的梯度其实已经失效了。
不过由于推荐系统的特征超级稀疏,同时更新同一个特征的参数的可能性非常小,所以ASP还是推荐使用的。
3. 半同步半异步(SSP)
SSP允许worker节点在一定迭代轮数内保持异步,如果最快的worker和最慢的worker之间的迭代步数之差超过了允许的最大值,所有worker都要停下来等。
3.3.4 更先进的PS
1. XDL
采用ASP的方式训练。
创新点:
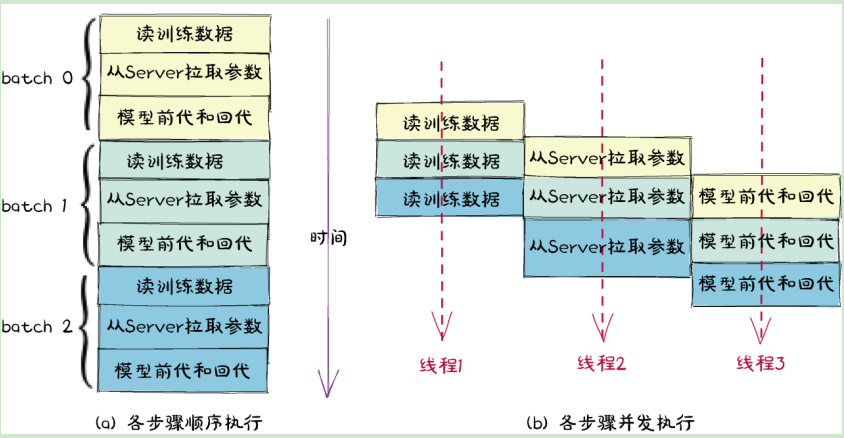
1)引入流水线机制
训练一个推荐模型,可以划分为读取训练数据,从server拉取模型参数,worker前代回代模型三个步骤。
传统模式是完成三个步骤后开始下一个batch的训练。
XDL的做法是为每个步骤分配专门的线程池,并在步骤间引入队列作为流水线,从而让多个步骤可以并发执行。
比如‘读数据’模块在读取batch0的数据之后,只需将数据插入队列,就可以读取batch1的数据,而不必等待拉取参数和前代回代执行完毕。
2)在PS的Server节点上也能部署、训练模型
由于有多模态数据,embedding很大,在server和worker之间频繁传递会占用大量带宽资源,导致很大的时延。
对此,XDL在每个server节点部署一个可学习的压缩模型,先将原始embedding经过这个压缩模型压缩成小embedding向量,再传给worker。
2. Persia
创新点:
1)对于推荐模型中的embedding和DNN权重不同的特点,在训练中采取不同的更新策略和通信策略。
对于embedding参数,由于超级稀疏,采用ASP模式训练,PS模式通信。
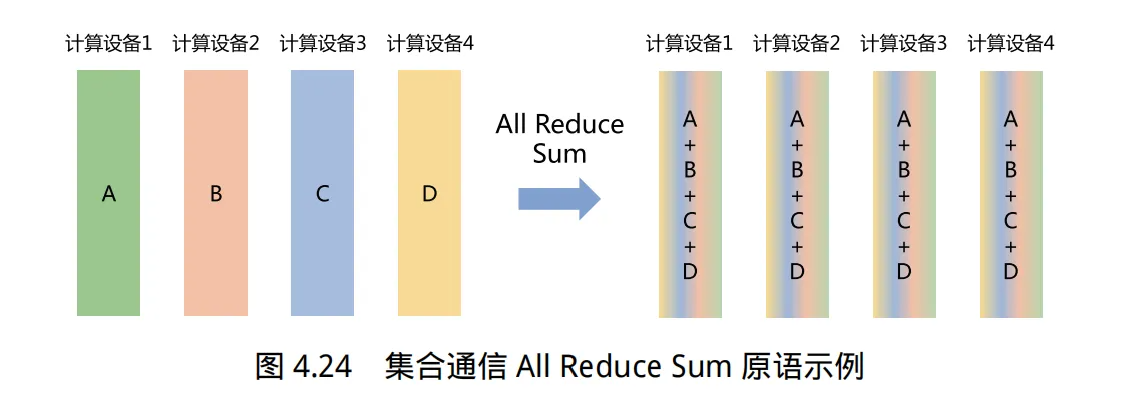
对于DNN权重,由于所有worker都要更新,采用BSP模式训练,AllReduce模式通信,从而worker无需通过server作为中介就能及时更新。
 2)优化模型参数的存储空间
2)优化模型参数的存储空间
对于很久没有更新的特征模型参数,从server中删除;
对于首次遇到的特征,以p的概率接纳并分配存储空间给它,所以它平均出现1/p次才能在server中拥有一席之地,从而避免只出现一两次的特征浪费空间。
3.4 面试题(答案仅供参考)
1. 为什么说Embedding提升了推荐算法的扩展性?
Embedding 之所以能显著提升推荐算法的扩展性,核心在于它将离散、稀疏的特征转化为连续、稠密的向量表示,从而让模型能够自动学习特征间的隐含关系,而非依赖人工规则或简单统计。
2. FFM针对FM的改进在哪里?
FFM中每个特征在与不同特征交叉时,根据对方特征所属的field使用不同的embedding;而FM中每个特征在与不同特征交叉时,使用的是同样的embedding。
3. 简述阿里Co-Action Network的基本思想?
简单来说,就是把物料的embedding变形成一个小型MLP,然后把用户的embedding喂入这个MLP,输出的结果就是这两个特征交叉的结果。当然,反过来变形用户的embedding,喂入物料的embedding也是可以的。
4. 简述Parameter Server是如何应对推荐系统“高维稀疏”的数据环境的?
1)参数由一群PS Server节点共同存储读写,从而突破了单台机器的资源限制。
2)只传递当前batch中有限的几个非零特征的参数,从而大大节省带宽和传输时间。
5. 什么是异步并发(ASP)中的“梯度失效”问题?即使如此,为什么在推荐系统中仍然常用?
比如有两个worker节点,他们先用θ0版本的参数进行训练,worker1训练好了,向server推送梯度g1,server更新参数为θ1,而这个时候worker2才训练好,但是它用的参数版本还是θ0,这样他算出来的梯度其实已经失效了。
不过由于推荐系统的特征超级稀疏,同时更新同一个特征的参数的可能性非常小,所以ASP还是推荐使用的。

















&spm=1001.2101.3001.5002&articleId=162151001&d=1&t=3&u=874cd09663f94b9585479a470b41cb72)
 1130
1130

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










