





聚类算法
聚类是一种经典的无监督学习方法,无监督学习的目标是通过对无标记训练样本的学习,发掘和揭示数据集本身潜在的结构与规律,即不依赖于训练数据集的类标记信息。聚类则是试图将数据集的样本划分为若干个互不相交的类簇,从而每个簇对应一个潜在的类别。
聚类算法全面解析
1.距离度量基础
1.1 闵可夫斯基距离族
通用公式:
distmk(xi,xj)=(∑u=1nxiu−xjup)1/p dist_{mk}(x_i,x_j) = (\sum_{u=1}^n x_{iu}-x_{ju} ^p)^{1/p} distmk(xi,xj)=(u=1∑nxiu−xjup)1/p
常见变体:
-
曼哈顿距离(p=1):dist=∑xi−yidist = ∑x_i - y_idist=∑xi−yi
-
欧氏距离(p=2):dist=√(∑(xi−yi)2)dist = √(∑(x_i - y_i)²)dist=√(∑(xi−yi)2)
1.2 属性类型处理
由于属性分为连续属性与离散属性。连续属性可以直接使用距离公式计算,对于离散属性而言还要再分为有序属性和无序属性,有序属性可以连续化然后通过距离公式计算,而无需属性则需要使用one-hot编码再使用VDM距离法。
- 有序属性 直接参与计算 身高:高(1)→中(0.5)→矮(0)
- 无序属性 VDM距离法 性别:(男→[1,0], 女→[0,1])
VDM距离公式:
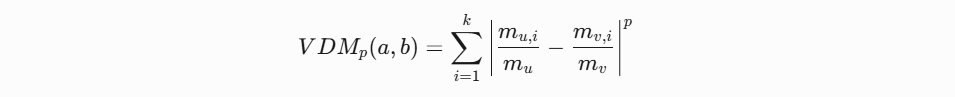
聚类性能评估
2.1 外部指标
由于无监督,因此不能对比标签来看聚类模型得准确率。因此此时找到一个外部得参考模型得输出作为伪标签,然后评价聚类效果

2.2 内部指标
基于聚类结果自身特性进行评估

原型聚类算法
3.1 K-Means
K-Means的思想十分简单,首先随机指定类中心,根据样本与类中心的远近划分类簇,接着重新计算类中心,迭代直至收敛。但是其中迭代的过程并不是主观地想象得出,事实上,若将样本的类别看做为“隐变量”(latent variable),类中心看作样本的分布参数,这一过程正是通过 EM算法的两步走 策略而计算出,其根本的目的是为了最小化平方误差函数E:
E=∑i=1k∑x∈Ci∣x−μi∣2 E=\sum_{i=1}^k \sum_{x\in C_i} |x-\mu_i|^2E=i=1∑



















 2181
2181

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










