



一、科研人的检索之痛
作为一个常年和文献打交道的开发者/研究者,你是否经历过这些场景:
-
🔍 为了查一篇文献,打开 Google Scholar、PubMed、Semantic Scholar 三个标签页来回切换
-
💰 看到关键论文,却被付费墙(Paywall)拦住,只能望"文"兴叹
-
📑 好不容易找到PDF,发现只是预印本,正式版本在另一个数据库
-
⏱️ 写综述时,光是检索和下载就耗掉一整天,真正阅读的时间所剩无几
根据相关研究,科研人员在文献检索上平均花费 30%-50% 的研究时间。而这部分时间,本可以花在实验设计、数据分析或论文写作上。
PaperFinder 的出现,就是为了解决这个痛点。
二、PaperFinder 是什么?
PaperFinder 是一款多源文献检索引擎,核心理念是:一次检索,多库联动,开放获取优先。
2.1 核心能力一览
表格
| 功能模块 | 具体能力 | 解决痛点 |
|---|---|---|
| 多源聚合 | 整合 9大开放数据库(Google Scholar、Semantic Scholar、PubMed、arXiv、CORE、OpenAlex 等) | 告别多平台切换 |
| 精准定位 | 支持 DOI / PMID / PMCID 一键检索 | 无需记忆复杂检索式 |
| PDF直达 | 自动匹配开放获取(Open Access)版本,PDF一键下载 | 绕过付费墙,合法免费 |
| 智能问答 | 下载后支持 AI对话式阅读,预设 13个核心问题模板 | 从"检索"到"理解"无缝衔接 |
2.2 技术架构简析
PaperFinder 的后端采用 多源异构数据融合 架构:
plain
复制
用户输入 (DOI/PMID/关键词)
↓
[检索调度层] → 并行查询 9 大数据库 API
↓
[数据融合层] → 去重、排序、元数据补全
↓
[开放获取解析器] → 匹配 Unpaywall / OA Button 等开放获取接口
↓
[结果聚合层] → 统一格式返回 + PDF 直链
这种设计的好处是:
-
速度快:并行查询,响应时间取决于最慢的接口,而非串行累加
-
覆盖全:9大库互补,避免单一数据库的收录盲区
-
命中率高:通过多源交叉验证,大幅提升开放获取文献的检出率
三、实战演示:从检索到理解,只需 3 步
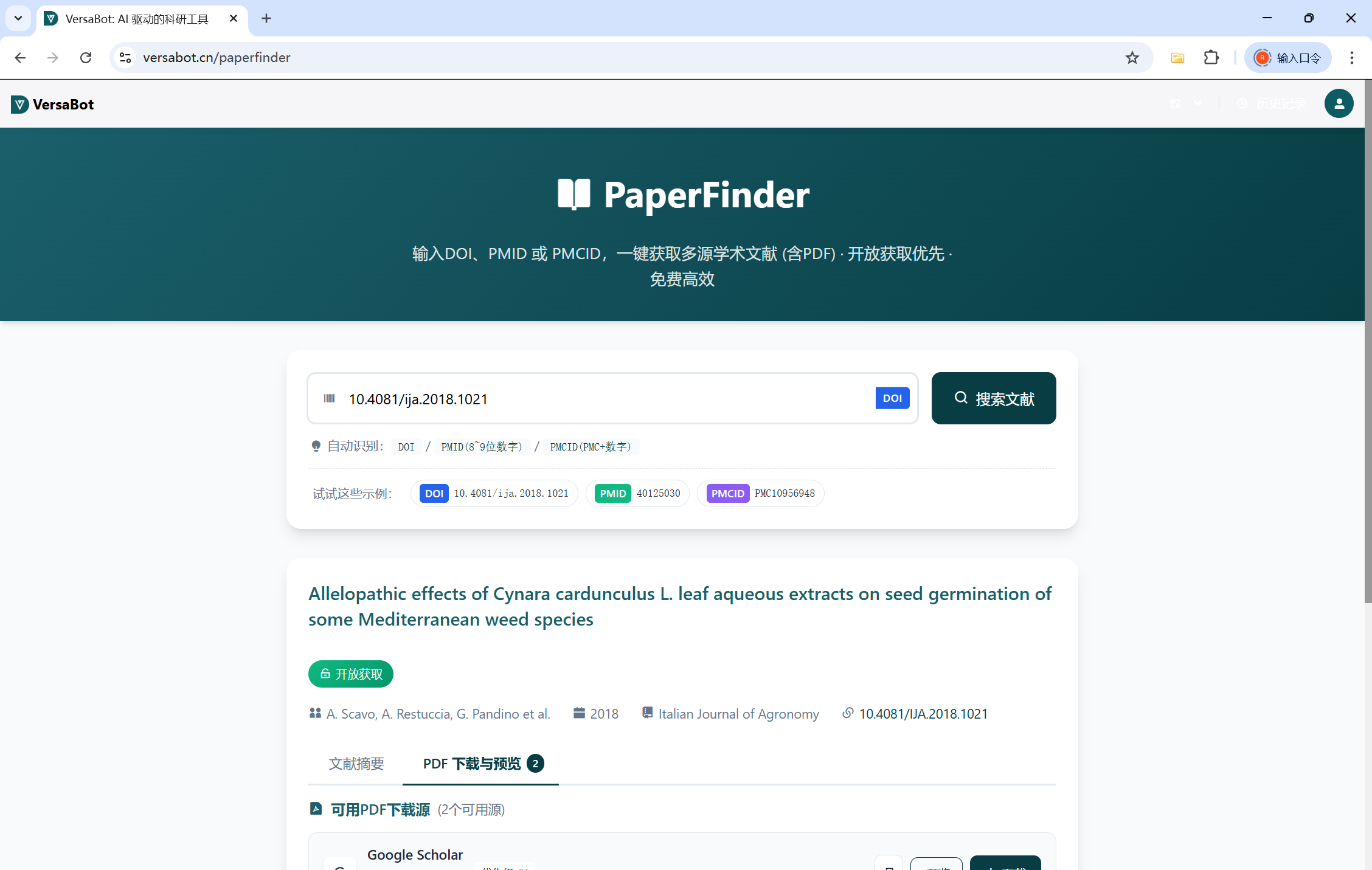
Step 1:输入标识符,一键检索
在搜索框输入文献的 DOI(如 10.1038/s41586-021-03819-2)、PMID 或 PMCID,点击检索。
PaperFinder 会同时在 9 大数据库中发起查询,并在 2-3 秒内 返回聚合结果。
Step 2:查看聚合结果,选择最优版本
结果页会展示:
-
文献元数据:标题、作者、期刊、年份、被引次数
-
多源可用性:哪些数据库收录了该文献
-
开放获取状态:是否有免费 PDF,直链在哪里
-
PDF 下载按钮:一键获取,无需跳转
💡 小技巧:如果某数据库提供了更完整的元数据(如 Semantic Scholar 的引用上下文),PaperFinder 会自动补全,让你看到最丰富的信息。
Step 3:AI 智能问答,快速理解文献
下载 PDF 后,PaperFinder 的 智能阅读助手 接管后续工作。
工具预设了 13 个核心问题模板,覆盖文献阅读的关键节点:
表格
| 问题类别 | 预设问题示例 |
|---|---|
| 研究背景 | 该研究解决了什么问题?前人做了哪些工作? |
| 方法创新 | 核心方法/技术路线是什么?与现有方法相比有何创新? |
| 核心结论 | 主要发现/结论是什么?数据支撑是否充分? |
| 局限展望 | 研究存在哪些局限性?未来可以朝哪些方向拓展? |
| 应用价值 | 该成果在实际应用中的潜力如何? |
点击任意问题,AI 会在 数秒内 从全文定位相关段落,生成结构化答案。
🚀 效率对比:传统方式读一篇文献需 1-2 小时(检索+下载+通读+笔记),PaperFinder 可将核心信息获取压缩到 10-15 分钟。
四、为什么强调"开放获取优先"?
学术出版领域的 付费墙问题 由来已久。据统计,全球每年发表的学术论文中,约 30%-50% 最终会以开放获取形式发布 ,但分散在不同平台,难以一站式发现。
PaperFinder 的 开放获取优先策略 基于以下原则:
-
合法性:只聚合官方开放获取渠道(如 PubMed Central、arXiv、机构知识库)
-
时效性:优先返回最新可用的 OA 版本
-
完整性:如果作者自存档的预印本与正式版本同时存在,会标注版本差异
这不仅帮用户 省钱,更重要的是 省时间——不用在 Sci-Hub 和正版之间反复横跳,也不用担心引用版本的准确性。
五、适用人群与场景
表格
| 用户类型 | 典型场景 | PaperFinder 的价值 |
|---|---|---|
| 研究生/博士生 | 写开题报告、文献综述 | 快速构建领域文献地图 |
| 青年科研人员 | 追踪前沿、寻找合作方向 | 多库覆盖,减少信息盲区 |
| 临床医生 | 查循证医学证据、指南原文 | PubMed 直连,PMCID 精准定位 |
| 开发者/技术写作者 | 调研技术背景、写技术博客 | 快速获取权威参考文献 |
| 图书情报从业者 | 文献传递、参考咨询 | 提升服务效率,降低检索门槛 |
六、与其他工具的对比
表格
| 工具 | 检索范围 | OA支持 | PDF获取 | AI阅读 | 费用 |
|---|---|---|---|---|---|
| Google Scholar | 广 | 部分 | 需跳转 | ❌ | 免费 |
| PubMed | 生物医学 | PMC免费 | 部分直链 | ❌ | 免费 |
| Semantic Scholar | 学术全领域 | 部分 | 需跳转 | 基础摘要 | 免费 |
| SciSpace | 多库 | 部分 | 支持 | Chat with PDF | 部分收费 |
| PaperFinder | 9大开放库聚合 | 优先OA | 一键直链 | 13问模板 | 完全免费 |
PaperFinder 的优势在于 "聚合+直达+理解" 的闭环:不是替代某个数据库,而是把分散的能力串成一条高效工作流。
七、写在最后
科研的本质是创新,而创新需要站在前人肩膀上。但"找肩膀"的过程,不应该消耗我们一半的精力。
PaperFinder 的设计哲学很简单:
让检索回归工具属性,把时间还给思考。
目前 PaperFinder 已开放使用,支持通过 DOI、PMID、PMCID 及关键词进行检索。如果你也厌倦了在多个数据库间反复横跳,不妨试试这个"科研检索神器"。


















 342
342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










