



 本文整理了一系列编程笔试题目,涵盖了C++、操作系统、数据结构、数据库、网络、线程同步等多个方面,包括选择题、填空题和理解题,涉及知识点丰富,适合程序员面试复习。
本文整理了一系列编程笔试题目,涵盖了C++、操作系统、数据结构、数据库、网络、线程同步等多个方面,包括选择题、填空题和理解题,涉及知识点丰富,适合程序员面试复习。
题1:
如果x=2014,下面函数的返回值是()
int fun(unsigned int x)
{
int n=0;
while((x+1))
{
n++;
x=x|(x+1);
}
return n;
}A.20 B.21 C.23 D.25
答案: C
题2:
以下代码的输出是()
int a[5]={1,2,3,4,5};
int *ptr=(int*)(&a+1);
printf("%d,%d",*(a+1),*(ptr-1));- 1,2
- 2,5
- 2,1
- 1,5
-
解析:
题关键就在于第二个点,*(ptr-1)输出为多少?
解释如下,&a+1不是首地址+1,系统会认为加了一个整个a数组,偏移了整个数组a的大小(也就是5个int的大小)。所以int *ptr=(int *)(&a+1);其实ptr实际是&(a[5]),也就是a+5.
原因为何呢?
&a是数组指针,其类型为int(*)[5];
函数fun的声明为int fun(int *p[4]),以下哪个变量可以作为fun的合法参数()
- int a[4][4];
- int **a;
- int **a[4]
- int (*a)[4];
题4
下面说法正确的是()
- C++已有的任何运算符都可以重载
- const对象只能调用const类型成员函数
- 构造函数和析构函数都可以是虚函数
- 函数重载返回值类型必须相同
答案: B
题5
典型的创建Windows窗口过程的流程为()
- 注册窗口类->创建窗口->显示窗口->更新窗口->消息循环
- 注册窗口类->创建窗口->更新窗口->显示窗口->消息循环
- 创建窗口->注册窗口类->更新窗口->显示窗口->消息循环
- 创建窗口->注册窗口类->显示窗口->更新窗口->消息循环
在屏幕上显示一个窗口的过程一般有以下步骤,这就是主程序的结构流程:
(1)得到应用程序的句柄(GetModuleHandle)。
(2)注册窗口类(RegisterClassEx)。在注册之前,要先填写RegisterClassEx的参数WNDCLASSEX结构。
(3)建立窗口(CreateWindowEx)。
(4)显示窗口(ShowWindows)。
(5)刷新窗口客户区(UpdateWindow)。
(6)进入无限的消息获取和处理的循环。首先获取消息(GetMessage),如果有消息到达,则将消息分派到回调函数处理(DispatchMessage),如果消息是WM_QUIT,则退出循环。
题6
下面哪个API返回的不属于windows内核对象()
- CreateFile
- CreateSemaphore
- CreateDC
- CeateEvent
内核对象主要要用来供系统和应用程序管理系统资源,像进程、线程、文件等。存取符号对象、事件对象、文件对象、作业对象、互斥对象、管道对象、等待计时器对象等都是内核对象。 除了内核对象外,也可以使用其他类型的对象,如菜单、窗口、鼠标光标、刷子和字体等。这些对象属于用户对象或图形设备接口(GDI)对象,而不是内核对象。
C选项是GDI对象。设备上下文(HDC) CreateDC
用户双击鼠标时产生的消息序列,下面正确的是()
- WM_LBUTTONDOWN,WM_LBUTTONUP,WM_LBUTTONDOWN,WM_LBUTTONUP
- WM_LBUTTONDOWN,WM_LBUTTONUP,WM_LBUTTONUP,WM_LBUTTONDBLCLK
- WM_LBUTTONDOWN,WM_LBUTTONUP,WM_LBUTTONDOWN,WM_LBUTTONDBLCLK
- WM_LBUTTONDOWN,WM_LBUTTONUP,WM_LBUTTONDBLCLK,WM_LBUTTONUP
题8
- 1,2
- 1,3
- 1
- 以上都不正确
题9
以下哪些线程同步锁可以为递归锁
1.信号量 2.读写锁 3.互斥量 4.事件 5.临界区(Critical Section)
- 1,3,4,5
- 5
- 3,5
- 1,3,5
答案:C
常见的进程/线程同步方法有互斥锁(或称互斥量Mutex)、读写锁(rdlock)、条件变量(cond)、信号量(Semophore)等。
在windows系统中,临界区(Critical Section)和事件对象(Event)也是常用的同步方法。
递归锁/非递归锁
Mutex可以分为递归锁(recursive mutex)和非递归锁(non-recursive mutex)。 递归锁也叫可重入锁(reentrant mutex),非递归锁也叫不可重入锁(non-reentrant mutex)。
二者唯一的区别是:
同一个线程可以多次获取同一个递归锁,不会产生死锁。
如果一个线程多次获取同一个非递归锁,则会产生死锁。
Windows下的Mutex和Critical Section是可递归的。
Linux下的pthread_mutex_t锁是默认是非递归的。可以通过设置PTHREAD_MUTEX_RECURSIVE属性,将pthread_mutex_t锁设置为递归锁。
题10
- postmessage发出消息后,将消息放到消息队列中,马上返回
- sendmessage发出消息后,一直等到该消息执行完毕,才返回
- 用sendmessage给其他线程创建的窗口发送消息时,消息也会进消息队列
- 用2个函数只能给当前进程的窗口发送消息
-
题11
关于WM_COPYDATA消息的处理,下面描述错误的是()
- 可以在不同进程之间传递少量只读数据
- 只能通过sendmessage方式来发送该消息
- 只能在窗口过程函数中处理该消息
- 可以在消息队列或窗口过程函数中处理该消息
答案:C
题12
堆排序的空间复杂度是(),堆排序中构建堆的时间复杂度是()。
- O(logn),O(n)
- O(logn),O(nlogn)
- O(1),O(n)
- O(1),O(nlogn)
题13
- 正向最大匹配法
- 逆向最大匹配法
- 最少切分
- 条件随机场
-
目前的分词方法归纳起来有3 类:
第一类是基于语法和规则的分词法。其基本思想就是在分词的同时进行句法、语义分析, 利用句法信息和语义信息来进行词性标注, 以解决分词歧义现象。因为现有的语法知识、句法规则十分笼统、复杂, 基于语法和规则的分词法所能达到的精确度远远还不能令人满意, 目前这种分词系统还处在试验阶段。
第二类是机械式分词法(即基于词典)。机械分词的原理是将文档中的字符串与词典中的词条进行逐一匹配, 如果词典中找到某个字符串, 则匹配成功, 可以切分, 否则不予切分。基于词典的机械分词法, 实现简单, 实用性强, 但机械分词法的最大的缺点就是词典的完备性不能得到保证。据统计, 用一个含有70 000 个词的词典去切分含有15 000 个词的语料库, 仍然有30% 以上的词条没有被分出来, 也就是说有4500 个词没有在词典中登录。
第三类是基于统计的方法。基于统计的分词法的基本原理是根据字符串在语料库中出现的统计频率来决定其是否构成词。词是字的组合, 相邻的字同时出现的次数越多, 就越有可能构成一个词。因此字与字相邻共现的频率或概率能够较好的反映它们成为词的可信度。
最大匹配是指以词典为依据,取词典中最长单词为第一个次取字数量的扫描串,在词典中进行扫描,这是基于词典分词的方法
1.正向最大匹配法
2.逆向最大匹配法
3.最少切分法:使每一句中切出的词数最小,这也是基于词典分词的方法
条件随机场是一个基于统计的序列标记和分割的方法,属于基于统计的分词方法范畴。它定义了整个标签序列的联合概率,各状态是非独立的,彼此之间可以交互,因此可以更好地模拟现实世界的数据.
////////
1)正向最大匹配法(由左到右的方向);
2)逆向最大匹配法(由右到左的方向);
3)最少切分(使每一句中切出的词数最小)。
以上三种是机械分词方法:
条件随机域(场)(conditional random fields,简称 CRF,或CRFs),是一种判别式概率模型,是随机场的一种,常用于标注或分析序列资料,如自然语言文字或是生物序列。
条件随机场(CRF)由Lafferty等人于2001年提出,结合了最大熵模型和隐马尔可夫模型的特点,是一种无向图模型,基于统计学,可以作为一种分词方法
题14
- 特征灵活
- 速度快
- 可容纳较多上下文信息
- 全局最优
-
答案:B
HMM模型是对转移概率和表现概率直接建模,统计共现概率。
MEMM模型是对转移概率和表现概率建立联合概率,统计时统计的是条件概率,但MEMM容易陷入局部最优,是因为MEMM只在局部做归一化。
RF模型中,统计了全局概率,在 做归一化时,考虑了数据在全局的分布,而不是仅仅在局部归一化,这样就解决了MEMM中的标记偏置(label bias)的问题。
CRF没有HMM那样严格的独立性假设条件,因而可以容纳任意的上下文信息。特征设计灵活。(与ME一样) ————与HMM比较
同时,由于CRF计算全局最优输出节点的条件概率,它还克服了最大熵马尔可夫模型标记偏置(Label-bias)的缺点。 ————与MEMM比较
CRF是在给定需要标记的观察序列的条件下,计算整个标记序列的联合概率分布,而不是在给定当前状态条件下,定义下一个状态的状态分布。
CRF需要训练的参数更多,与MEMM和HMM相比,它存在训练代价大、复杂度高的缺点。
CRF模型对于HMM和MEMM模型的优点:
a)与HMM比较。CRF没有HMM那样严格的独立性假设条件,因而可以容纳任意的上下文信息。特征设计灵活(与ME一样)
b)与MEMM比较。由于CRF计算全局最优输出节点的条件概率,它还克服了最大熵马尔可夫模型标记偏置(Label-bias)的缺点。
c)与ME比较。CRF是在给定需要标记的观察序列的条件下,计算整个标记序列的联合概率分布,而不是在给定当前状态条件下,定义下一个状态的状态分布。
CRF模型对于HMM和MEMM模型的缺点:
训练代价大、复杂度高
题15
圆内接三角形是锐角三角形概率是多少()
- 1/4
- 1/3
- 1/2
- 2/3
答案:A
思路1:
三角形的三点在圆上的位置是等概率的。这种任意位置组成的三角形中,最大的那个角必定大于等于60度,因此满是三角形是锐角的变化范围是60-90度,钝角的范围是90-180度
(90-60)/(180-60)=1/4
思路2:
三角形一个点A是固定的,圆心为O,连接AO,并延长交圆于D,AD为直径,分圆为两半三角形另两顶点为BC,当B、C在AD一边时ABC非锐角三角形,这种可能性有1/2当B、C在AD两边时ABC可能为锐角三角形,可能非锐角三角形,当BC与AO不相交时为锐角三角形,相交时非锐角三角形,可能性各一半,即均为1/4锐角三角形的概率为1/4,其他为3/4 故选A
题16
六个人排成一排,甲与乙不相邻,且甲与丙不相邻的不同排法数是多少()
- 216
- 240
- 288
- 360
思路1:
思路2:
题17
- 冒泡
- 选择
- 归并
- 快排
- 堆排序
-
题18
CSomething a();
CSomething b(2);
CSomething c[3];
CSomething &ra = b;
CSomething d=b;
CSomething *pA = c;
CSomething *p = new CSomething(4);- 10
- 9
- 8
- 7
- 6
- 5
有1,2,3,......无穷个格子,你从1号格子出发,每次1/2概率向前跳一格,1/2概率向前跳两格,走到格子编号为4的倍数时结束,结束时期望走的步数为____。
- 两个进程中分别产生生成两个独立的fd
- 两个进程可以任意对文件进行读写操作,操作系统并不保证写的原子性
- 进程可以通过系统调用对文件加锁,从而实现对文件内容的保护
- 任何一个进程删除该文件时,另外一个进程会立即出现读写失败
- 两个进程可以分别读取文件的不同部分而不会相互影响
- 一个进程对文件长度和内容的修改另外一个进程可以立即感知
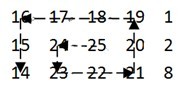
- O(M*N)
- O(M+N)
- O(Mlogn)
- O(N*logM)
- O(M^2*N^2)
- O(max(M,N))
- fread
- gets
- getchar
- pread
- getline
- scanf
答案: D
题23
如下描述中,错误的是____。
SATA硬盘因为有机械部件,随机读写时会发生磁头的物理运动。主流硬盘的平均寻道时间在几毫秒到几十毫秒
SATA硬盘读写的最小单位是扇区,扇区的大小是512字节或者4k
文件系统读写硬盘的最小单位也是扇区
SSD支持随机读写.但是一般读性能要好于写性能
SSD的随机读写延时要比SATA低两个数量级
SSD根据使用技术的不同,写的寿命是有限的,需要软件进行写优化,确保存储单元的写次数基本同步增长
题24
以下函数中,和其他函数不属于一类的是____。
- read
- pread
- write
- pwrite
- fseek
- lseek
题25
下列说法错误的有( )
- 在类方法中可用this来调用本类的类方法
- 在类方法中调用本类的类方法时可直接调用
- 在类方法中只能调用本类中的类方法
- 在类方法中绝对不能调用实例方法
首先这里的类方法是指属于类的方法,而不是属于类对象的方法。在类中一般的方法和数据属于类对象,存储在栈中,但是(A)static成员属于整个类,存储在静态区域,没有this指针,称作类方法。在类方法中,(B)可以直接调用本类中的类方法,(C)可以通过类的作用域调用其他类的类方法,类方法不可以直接调用类中非静态成员,可以直接调用类中的静态成员。(D)如果类方法要调用非静态成员时,可通过对象来引用。
题26
下列运算符,在C++语言中不能重载的是()
- *
- .*
- ::
- operator delete
::作用域符
题27
In C++, which of the following keyword(s) can be used on both a variable and a function?
- static
- virtual
- extern
- inline
- const
题28
Which of the following statement(s) equal(s) value 1 in C programming language?
- the return value of main function if program ends normally
- return (7&1)
- char *str="microsoft"; return str=="microsoft"
- return "microsoft"=="microsoft"
- None of the above
答案: BCD
题29
给出以下定义,下列哪些操作是合法的?
const char *p1 = “hello”;
char *const p2 = “world”;- p1++;
- p1[2] = ‘w’;
- p2[2] = ‘l’;
- p2++;
题30
关于IP地址下列说法错误的是?
- IP地址采用分层结构,它由网络号与主机号两部分组成
- 根据不同的取值范围IP地址可以分为五类
- 202.112.139.140属于B类地址
- 每个C类网络最多包含254台主机
- IPv6采用128位地址长度
- 私有地址只是ABC类地址的一部分
解析:
一个A类IP地址由1字节的网络地址和3字节主机地址组成,网络地址的最高位必须是“0”, 地址范围从1.0.0.0 到126.0.0.0。可用的A类网络有126个,每个网络能容纳1亿多个主机。
2. B类IP地址
一个B类IP地址由2个字节的网络地址和2个字节的主机地址组成,网络地址的最高位必须是“10”,地址范围从128.0.0.0到191.255.255.255。可用的B类网络有16382个,每个网络能容纳6万多个主机 。
3. C类IP地址
一个C类IP地址由3字节的网络地址和1字节的主机地址组成,网络地址的最高位必须是“110”。范围从192.0.0.0到223.255.255.255。C类网络可达209万余个,每个网络能容纳254个主机。
4. D类地址用于多点广播(Multicast)。
D类IP地址第一个字节以“lll0”开始,它是一个专门保留的地址。它并不指向特定的网络,目前这一类地址被用在多点广播(Multicast)中。多点广播地址用来一次寻址一组计算机,它标识共享同一协议的一组计算机。
5. E类IP地址
以“llll0”开始,为将来使用保留。
A类地址:10.0.0.0~10.255.255.255
B类地址:172.16.0.0~172.31.255.255
C类地址:192.168.0.0~192.168.255.255
题31
以下说法正确的是:
- 在并行程度中,当两个并行的线程,在没有任何约束的情况下,访问一个共享变量或者共享对象的一个域,而且至少要有一个操作是写操作,就可能发生数据竞争错误。
- 原语Compare-and-swap(CAS)是实现无锁数据结构的通用原语。
- 获得内部锁的唯一途径是:进入这个内部锁保护的同步块或方法。
- volatile变量具有synchronized的可见性特性,但是不具备原子特性。
- 减小竞争发生可能性的有效方式是尽可能缩短把持锁的时间
答案:ABCDE
题32
下列说法正确的有( )
- 环境变量可在编译source code时指定
- 在编译程序时,所能指定的环境变量不包括class path
- javac一次可同时编译数个Java源文件
- javac.exe能指定编译结果要置于哪个目录(directory)
题33
下列说法错误的有( )
- 能被java.exe成功运行的java class文件必须有main()方法
- J2SDK就是Java API
- Appletviewer.exe可利用jar选项运行.jar文件
- 能被Appletviewer成功运行的java class文件必须有main()方法
题34
以下集合对象中哪几个是线程安全的?( )
- ArrayList
- Vector
- Hashtable
- Stack
题35
初始序列为1 8 6 2 5 4 7 3一组数采用堆排序,当建堆(小根堆)完毕时,堆所对应的二叉树中序遍历序列为:()
- 8 3 2 5 1 6 4 7
- 3 2 8 5 1 4 6 7
- 3 8 2 5 1 6 7 4
- 8 2 3 5 1 4 7 6
题36
IP地址131.153.12.71是一个()类IP地址。
A.A类
B.B类
C.C类
D.D类
答案: B
题37
- 0型语言
- 1型语言
- 2型语言
- 3型语言
-
浏览器访问某页面,HTTP协议返回状态码为403时表示:()
答案: 禁止访问
找不到该页面:404
禁止访问:403
内部服务器访问:500
服务器繁忙:503

题39
1:成员对象的构造函数
2:基类的构造函数
3:派生类本身的构造函数
- 123
- 231
- 321
- 213
-
当派生类中不含对象成员时
· 在创建派生类对象时,构造函数的执行顺序是:基类的构造函数→派生类的构造函数;
· 在撤消派生类对象时,析构函数的执行顺序是:派生类的构造函数→基类的构造函数。
当派生类中含有对象成员时
· 在定义派生类对象时,构造函数的执行顺序:基类的构造函数→对象成员的构造函数→派生类的构造函数;
· 在撤消派生类对象时,析构函数的执行顺序:派生类的构造函数→对象成员的构造函数→基类的构造函数。
题40
进程进入等待状态有哪几种方式?
- CPU调度给优先级更高的线程
- 阻塞的线程获得资源或者信号
- 在时间片轮转的情况下,如果时间片到了
- 获得spinlock未果
C. 时间片轮转使得每个进程都有一小片时间来获得CPU运行,当时间片到时从运行状态变为 就绪状态。
题41
同一进程下的线程可以共享以下?
A. stack
B. data section
C. register set
D. file fd
答案: BD
解析: 线程共享的内容包括:
1.进程代码段
2.进程的公有数据(利用这些共享的数据,线程很容易的实现相互之间的通讯)
3.进程打开的文件描述符、
4.信号的处理器、
5.进程的当前目录和
6.进程用户ID与进程组ID
线程独有的内容包括:
1.线程ID
2.寄存器组的值
3.线程的堆栈
4.错误返回码
5.线程的信号屏蔽码
题42
二进制地址为011011110000,大小为(4)10和(16)10块的伙伴地址分别为: 1 , 2

题43
在数据库系统中,产生不一致的根本原因是( )
A. 数据存储量太大
B. 没有严格保护数据
C. 未对数据进行完整性控制
D. 数据冗余
答案D
数据库中有可能会存在不一致的数据。
造成数据不一致的原因主要有:
- 数据冗余
如果数据库中存在冗余数据,比如两张表中都存储了用户的地址,在用户的地址发生改变时,如果只更新了一张表中的数据,那么这两张表中就有了不一致的数据。
- 并发控制不当
比如某个订票系统中,两个用户在同一时间订同一张票,如果并发控制不当,可能会导致一张票被两个用户预订的情况。当然这也与元数据的设计有关。
- 故障和错误
如果软硬件发生故障造成数据丢失等情况,也可能引起数据不一致的情况。因此我们需要提供数据库维护和数据恢复的一些措施。
题44
用容积分别为15升和27升的两个杯子向一个水桶中装水,可以精确向水桶中注入( )升水?
- 53
- 25
- 33
- 52
答案: C
解析: 只能是3的倍数
题45
网桥和交换机工作在数据链路层,路由器工作在网络层
题46
对于满足SQL92标准的SQL语句:SELECT foo,count(foo) FROM pokes WHERE foo>10 GROUP BY foo HAVINO ORDER BY foo,其执行的顺序应该为( )
- FROM->WHERE->GROUP BY->HAVING->SELECT->ORDER BY
- FROM->GROUP BY->WHERE->HAVING->SELECT->ORDER BY
- FROM->WHERE->GROUP BY->HAVING->ORDER BY->SELECT
- FROM->WHERE->ORDER BY->GROUP BY->HAVING->SELECT
答案: A
题47
在unix系统中,目录结构采用()
A 单级目录结构
B 二级目录结构
C 单纯树形目录结构
D 带链接树形目录结构
题48
在一个单CPU的处理机中,有P1,P3,P5三个作业,有两个IO设备IO1,IO2,并且能够实现抢先式多任务并行工作的多道程序环境中,投入运行优先级由高到低P5,P1,P3三个作业,他们使用设备的先后顺序和占用设备的时间分别为:P1:IO2(10ms) CPU(10ms) IO1(30ms)CPU(10ms)P3:IO1(30ms) CPU(10ms) IO2(30ms)CPU(10ms)P5:CPU(20ms) IO1(30ms) CPU(10ms) IO2(15ms)忽略其他的时间损耗,3个作业投入到全部完成的情况下。请问下列哪些选项为IO2的设备利用率?
A. 0.55 B. 0.26 C. 0.48 D. 0.5 E 0.39
答案: E
题49
关于epoll和select的区别,哪些说法是正确的?
A. epoll和select都是I/O多路复用的技术,都可以实现同时监听多个I/O事件的状态
B. epoll相比select效率更高,主要是基于其操作系统支持的I/O事件通知机制,而select是基于轮询机制
C.epoll支持水平触发和边沿触发两种模式
D.select能并行支持I/O比较小,且无法修改
答案: ABC
题50
Internet的网络层含有的协议是?
A. IP
B. ICMP
C. ARP
D. RARP
答案: ABCD
题51
以下是C++的不同数据类型值的比较语句,请问这些判断语句中作为条件部分的语句编写有问题的有:
- 如果变量bVar是布尔类型:if(false==bVar){doSomeThing();}
- 如果变量nVar是int型:if(0==nVar){doSomeThing();}
- 如果变量fVar为浮点型:if(0.02=fVar){doSomeThing();}
- 如果变量sVar为字符串型:if(""==sVar){doSomeThing();}
题52
以下是C++的不同数据类型值的比较语句,请问这些判断语句中作为条件部分的语句编写有问题的有:
- 如果变量bVar是布尔类型:if(false==bVar){doSomeThing();}
- 如果变量nVar是int型:if(0==nVar){doSomeThing();}
- 如果变量fVar为浮点型:if(0.02=fVar){doSomeThing();}
- 如果变量sVar为字符串型:if(""==sVar){doSomeThing();}
题53
TCP链接中主动断开链接netstat观察可能出现的状态流转是:
A.ESTABLISHED->CLOSE_WAIT->TIME_WAIT->CLOSED
B.ESTABLISHED->TIME_WAIT->CLOSE_WAIT->CLOSED
C.ESTABLISHED->FIN_WAIT_1->FIN_WAIT_2->TIME_WAIT->CLOSED
D.ESTABLISHED->FIN_WAIT_1->TIME_WAIT->CLOSED
答案: CD
题54
以下涉及到内存管理的代码段中,有错误的是:
int *a=new int(12); //..... free(a);
int *ip=static_cast<int*>(malloc(sizeof(int))); *ip=10; //..... delete ip;
double *a=new double[1]; //.... delete a;
int *ip=new int(12);
for(int i=0;i<12;++i){
ip[i]=i;
}
delete []ip;
题55
下面哪些特性可能导致代码体积膨胀:
宏定义
模板
内联函数
递归
题56

(1,99,2)
(5,68,1)
(3,70,3)
(7,45,null)
成绩表中主键是“PK=科目代码”,所以 科目代码要唯一,所以可排除AC;在数据库完整性里有说:外键必须可以找到或者为空,所以 B是可以的,而D为空,所以也满足。故选BD
题57
设x、y、t均为int型变量,则执行语句:t=3; x=y=2; t=x++||++y; 后,变量t和y的值分别为____。
- t=1 y=2
- t=1 y=3
- t=2 y=2
- t=2 y=3
- t=3 y=2
- t=3 y=3
题58
关于函数模板,描述错误的是?
- 函数模板必须由程序员实例化为可执行的函数模板
- 函数模板的实例化由编译器实现
- 一个类定义中,只要有一个函数模板,则这个类是类模板
- 类模板的成员函数都是函数模板,类模板实例化后,成员函数也随之实例化
题59
在Linux 系统中,在运行一个程序时,程序中未初始化的全局变量会被加载到以下哪个内存段中?
A. BSS
B. TEXT
C. DATA
D, STACK
答案: A
解析:
BSS(Block Started by Symbol)通常是指用来存放程序中未初始化的全局变量和静态变量的一块内存区域。特点是:可读写的,在程序执行之前BSS段会自动清0。所以,未初始的全局变量在程序执行之前已经成0了。
数据段:数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
代码段:代码段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
栈(stack):栈又称堆栈, 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区
题60
i的初始值为0,i++在两个线程里面分别执行100次,能得到最大值是 200,最小值是 2
题61
在c语言中,要求运算必须是整形的运算符是:
A /
B ++
C !=
D %
答案: D
题62
题57
设x、y、t均为int型变量,则执行语句:t=3; x=y=2; t=x++||++y; 后,变量t和y的值分别为____。
- t=1 y=2
- t=1 y=3
- t=2 y=2
- t=2 y=3
- t=3 y=2
- t=3 y=3
题58
关于函数模板,描述错误的是?
- 函数模板必须由程序员实例化为可执行的函数模板
- 函数模板的实例化由编译器实现
- 一个类定义中,只要有一个函数模板,则这个类是类模板
- 类模板的成员函数都是函数模板,类模板实例化后,成员函数也随之实例化
题59
在Linux 系统中,在运行一个程序时,程序中未初始化的全局变量会被加载到以下哪个内存段中?
A. BSS
B. TEXT
C. DATA
D, STACK
答案: A
解析:
BSS(Block Started by Symbol)通常是指用来存放程序中未初始化的全局变量和静态变量的一块内存区域。特点是:可读写的,在程序执行之前BSS段会自动清0。所以,未初始的全局变量在程序执行之前已经成0了。
数据段:数据段(data segment)通常是指用来存放程序中已初始化的全局变量的一块内存区域。数据段属于静态内存分配。
代码段:代码段(code segment/text segment)通常是指用来存放程序执行代码的一块内存区域。这部分区域的大小在程序运行前就已经确定,并且内存区域通常属于只读, 某些架构也允许代码段为可写,即允许修改程序。在代码段中,也有可能包含一些只读的常数变量,例如字符串常量等。
堆(heap):堆是用于存放进程运行中被动态分配的内存段,它的大小并不固定,可动态扩张或缩减。当进程调用malloc等函数分配内存时,新分配的内存就被动态添加到堆上(堆被扩张);当利用free等函数释放内存时,被释放的内存从堆中被剔除(堆被缩减)
栈(stack):栈又称堆栈, 是用户存放程序临时创建的局部变量,也就是说我们函数括弧“{}”中定义的变量(但不包括static声明的变量,static意味着在数据段中存放变量)。除此以外,在函数被调用时,其参数也会被压入发起调用的进程栈中,并且待到调用结束后,函数的返回值也会被存放回栈中。由于栈的先进先出特点,所以栈特别方便用来保存/恢复调用现场。从这个意义上讲,我们可以把堆栈看成一个寄存、交换临时数据的内存区
题60
i的初始值为0,i++在两个线程里面分别执行100次,能得到最大值是 200,最小值是 2
题61
在c语言中,要求运算必须是整形的运算符是:
A /
B ++
C !=
D %
答案: D
题61
已知int a[]={1,2,3,4,5};int*p[]={a,a+1,a+2,a+3};int **q=p;表达式*(p[0]+1)+**(q+2)的值是____。
答案: 5
题62
给出以下定义,下列哪些操作是合法的?
char a[] = "hello";
char b[] = "world";
const char *p1 = a;
char* const p2 = b;- p1++
- p1[2]='w';
- p2[2]='l';
- p2++
题63
类成员函数的重载、覆盖和隐藏区别描述正确的有?
A. 覆盖是指在同一个类中名字相同,参数不同
B. 重载是指派生类函数覆盖基类函数,函数相同,参数相同,基类函数必须有virtual关键字
C. 派生类函数与基类函数相同,但是参数不同,会"隐藏"父类函数
D. 函数名字相同,参数相同,基类无virtual关键字的派生类的函数会"隐藏"父类函数
答案: CD
a.成员函数被重载的特征:
(1)相同的范围(在同一个类中);
(2)函数名字相同;
(3)参数不同;
(4)virtual 关键字可有可无。
b.覆盖是指派生类函数覆盖基类函数,特征是:
(1)不同的范围(分别位于派生类与基类);
(2)函数名字相同;
(3)参数相同;
(4)基类函数必须有virtual 关键字。
c.“隐藏”是指派生类的函数屏蔽了与其同名的基类函数,规则如下:
(1)如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无virtual关键字,基类的函数将被隐藏(注意别与重载混淆)。
(2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual 关键字。此时,基类的函数被隐藏(注意别与覆盖混淆)
enum string{
x1,
x2,
x3=10,
x4,
x5,
} x- 5
- 12
- 0
- 随机值
题65
以下函数用法正确的个数是:
void test1()
{
unsigned char array[MAX_CHAR+1],i;
for(i=0;i<=MAX_CHAR;i++){
array[i]=i;
}
}
char*test2()
{
char p[] = "hello world";
return p;
}
char *p =test2();
void test3(){
char str[10];
str++;
*str='0';
}答案: 0
1
2
3
4
void foo(){
++a;
printf("%d ",a);
}- 3 2
- 2 3
- 3 3
- 2 2


















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










