




 本文介绍了信息论中的熵,包括Jensen不等式、熵的定义、性质,以及联合熵、条件熵、互信息和相对熵的概念。熵作为衡量随机变量不确定性的度量,其基本性质和相关定理如最大熵原理、信息不等式等被详细阐述。此外,还讨论了互信息与变量独立的关系,以及条件互信息的概念。
本文介绍了信息论中的熵,包括Jensen不等式、熵的定义、性质,以及联合熵、条件熵、互信息和相对熵的概念。熵作为衡量随机变量不确定性的度量,其基本性质和相关定理如最大熵原理、信息不等式等被详细阐述。此外,还讨论了互信息与变量独立的关系,以及条件互信息的概念。
信息论基础——熵
一 、Jensen不等式
定理1 设fff 为区间III 上的凹函数,pi∈[0,1],i=1,2,⋯ ,np_{i} \in[0,1], i=1,2,\cdots,npi∈[0,1],i=1,2,⋯,n,且∑i=1npi=1\sum_{i=1}^{n} p_{i}=1∑i=1npi=1,则对任何xi∈Ix_{i} \in Ixi∈I,有f(∑i=1npixi)⩾∑i=1npif(xi)f\left(\sum_{i=1}^{n} p_{i} x_{i}\right) \geqslant \sum_{i=1}^{n} p_{i} f\left(x_{i}\right)f(i=1∑npixi)⩾i=1∑npif(xi)
若 fff 严格凹,上式的等号只有在下列条件满足时才成立:若pi⋅pj≠0p_{i} \cdot p_{j} \neq 0pi⋅pj̸=0,则必有xi=xjx_{i}=x_{j}xi=xj
证明:略
对于对数函数f(x)=logxf(x)=\log xf(x)=logx在区间(0,+∞)(0,+\infty)(0,+∞)是凹函数,有log(∑i=1npixi)⩾∑i=1npilogxi\log \left(\sum_{i=1}^{n} p_{i} x_{i}\right) \geqslant \sum_{i=1}^{n} p_{i} \log x_{i}log(∑i=1npixi)⩾∑i=1npilogxi,∀i,xi>0,pi⩾0\forall i, x_{i}>0, p_{i} \geqslant 0∀i,xi>0,pi⩾0,且∑i=1npi=1\sum_{i=1}^{n} p_{i}=1∑i=1npi=1。
二、熵
一个离散随机变量XXX的熵H(X)H(X)H(X)的定义为H(X)=∑XP(X)log1P(X)=−∑XP(X)logP(X)
H(X)=\sum_{X} P(X) \log \frac{1}{P(X)}=-\sum_{X} P(X) \log P(X)
H(X)=X∑P(X)logP(X)1=−X∑P(X)logP(X) logP(X)\log P(X)logP(X)以为222底,熵的单位是比特,以eee为底,熵的单位是奈特
熵是对随机变量的不确定性的度量。随机变量XXX的熵越大,说明它的不确定性越大。
熵的基本性质
(1)(1)(1) H(X)⩾0H(X) \geqslant 0H(X)⩾0
(2)(2)(2) H(X)⩽log∣X∣H(X) \leqslant \log |X|H(X)⩽log∣X∣,等号成立当且仅当对XXX的所有取值xxx有P(X=x)=1∣X∣P(X=x)=\frac{1}{|X|}P(X=x)=∣X∣1
证明:(1)(1)(1) 对XXX的任意取值xxx,总有−P(X=x)logP(X=x)⩾0-P(X=x) \log P(X=x) \geqslant 0−P(X=x)logP(X=x)⩾0
(2)(2)(2) H(X)=∑xP(X)log1P(X)⩽log∑XP(X)1P(X)=log∣X∣\begin{aligned} H(X) &=\sum_{x} P(X) \log \frac{1}{P(X)} \\ & \leqslant \log \sum_{X} P(X) \frac{1}{P(X)}=\log |X| \end{aligned}H(X)=x∑P(X)logP(X)1⩽logX∑P(X)P(X)1=log∣X∣命题得证,此性质经常被称为最大熵原理
三、联合熵、条件熵和互信息
联合熵:两个离散随机变量XXX和YYY的联合熵的定义为
H(X,Y)=∑X,YP(X,Y)log1P(X,Y)=−∑X,YP(X,Y)logP(X,Y)H(X, Y)=\sum_{X, Y} P(X, Y) \log \frac{1}{P(X, Y)}=-\sum_{X, Y} P(X, Y) \log P(X, Y)H(X,Y)=X,Y∑P(X,Y)logP(X,Y)1=−X,Y∑P(X,Y)logP(X,Y)
条件熵:给定Y=xY=xY=x时XXX的条件熵为
H(X∣Y=y)=∑XP(X∣Y=y)log1P(X∣Y=y)H(X | Y=y)=\sum_{X} P(X | Y=y) \log \frac{1}{P(X | Y=y)}H(X∣Y=y)=X∑P(X∣Y=y)logP(X∣Y=y)1
条件熵H(X∣Y=y)H(X | Y=y)H(X∣Y=y)度量的是已Y=yY=yY=y知后,XXX的不确定性
由于知道YYY的概率分布,因此可以计算观测YYY后XXX的熵的期望值,即
H(X∣Y)=∑y∈ΩYP(Y=y)H(X∣Y=y)=∑y∈ΩYP(Y=y)∑XP(X∣Y=y)log1P(X∣Y=y)=∑Y∑XP(Y)P(X∣Y)log1P(X∣Y)=∑X,YP(X,Y)log1P(X∣Y)\begin{aligned} H(X | Y) &=\sum_{y \in \Omega_{Y}} P(Y=y) H(X | Y=y) \\ &=\sum_{y \in \Omega_{Y}} P(Y=y) \sum_{X} P(X | Y=y) \log \frac{1}{P(X | Y=y)} \\ &=\sum_{Y} \sum_{X} P(Y) P(X | Y) \log \frac{1}{P(X | Y)} \\ &=\sum_{X, Y} P(X, Y) \log \frac{1}{P(X | Y)} \end{aligned}H(X∣Y)=y∈ΩY∑P(Y=y)H(X∣Y=y)=y∈ΩY∑P(Y=y)X∑P(X∣Y=y)logP(X∣Y=y)1=Y∑X∑P(Y)P(X∣Y)logP(X∣Y)1=X,Y∑P(X,Y)logP(X∣Y)1H(X∣Y)H(X | Y)H(X∣Y)称为给定YYY时XXX的条件熵
注意:H(X∣Y)H(X | Y)H(X∣Y)与H(X∣Y=y)H(X | Y=y)H(X∣Y=y)有所不同,后者是在已知YYY取某一特定值yyy时XXX的条件熵,是在已知Y=yY=yY=y后,XXX剩余的不确定性。而H(X∣Y)H(X | Y)H(X∣Y)则是在未知YYY的取值时,对观测到YYY的取值后XXX剩余的不确定性的一个期望。
例: 设联合分布P(X,Y)P(X,Y)P(X,Y)及边缘分布P(X)P(X)P(X)和P(Y)P(Y)P(Y)如下:
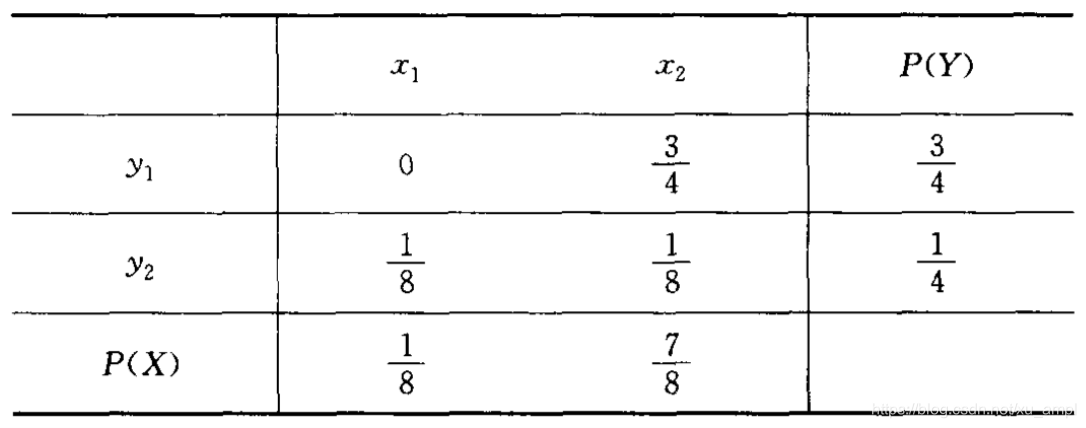
从而得H(X)=−18log18−78log78=0.544H(X∣Y=y1)=−0log0−1log1=0H(X∣Y=y2)=−12log12−12log12=1H(X∣Y)=34H(X∣Y=y1)+14H(X∣Y=y2)=0.25
\begin{array}{l}{H(X)=-\frac{1}{8} \log \frac{1}{8}-\frac{7}{8} \log \frac{7}{8}=0.544} \\ {H\left(X | Y=y_{1}\right)=-0 \log 0-1 \log 1=0} \\ {H\left(X | Y=y_{2}\right)=-\frac{1}{2} \log \frac{1}{2}-\frac{1}{2} \log \frac{1}{2}=1} \\ {H(X | Y)=\frac{3}{4} H\left(X | Y=y_{1}\right)+\frac{1}{4} H\left(X | Y=y_{2}\right)=0.25}\end{array}
H(X)=−81log81−87log87=0.544H(X∣Y=y1)=−0log0−1log1=0H(X∣Y=y2)=−21log21−21log21=1H(X∣Y)=43H(X∣Y=y1)+41H(X∣Y=y2)=0.25
在观测到YYY前,XXX 的不确定性是H(X)H(X)H(X),通过观测YYY,我们的期望XXX的不确定性会变为H(X∣Y)H(X|Y)H(X∣Y),因此H(X)H(X)H(X)与H(X∣Y)H(X|Y)H(X∣Y)之差I(X;Y)=H(X)−H(X∣Y)I(X ; Y)=H(X)-H(X | Y)I(X;Y)=H(X)−H(X∣Y)就是对YYY包含多少关于XXX的信息的一个度量,称之为YYY关于XXX的信息,下面可以看到I(X;Y)=I(Y;X)I(X ; Y)=I(Y ; X)I(X;Y)=I(Y;X),因此它又称为和之间的互信息
定理2 对任意两个离散随机变量XXX和YYY,有I(X;Y)=∑X,YP(X,Y)logP(X,Y)P(X)P(Y)(a)I(X;Y)=I(Y;X)(b)H(X,Y)=H(X)+H(Y∣X)=H(Y)+H(X∣Y)(c)I(X;Y)+H(X,Y)=H(X)+H(Y)(e)
\begin{array}{l}{I(X ; Y)=\sum_{X, Y} P(X, Y) \log \frac{P(X, Y)}{P(X) P(Y)}} \qquad(a)\\ {\qquad I(X ; Y)=I(Y ; X)}\qquad(b) \\ {H(X, Y)=H(X)+H(Y | X)=H(Y)+H(X | Y)} \qquad(c)\\ {I(X ; Y)+H(X, Y)=H(X)+H(Y)}\qquad(e)\end{array}
I(X;Y)=∑X,YP(X,Y)logP(X)P(Y)P(X,Y)(a)I(X;Y)=I(Y;X)(b)H(X,Y)=H(X)+H(Y∣X)=H(Y)+H(X∣Y)(c)I(X;Y)+H(X,Y)=H(X)+H(Y)(e)其中式(c)(c)(c)称为熵的链规则
证明:(1)(1)(1)对式(a)(a)(a) ,I(X;Y)=H(X)−H(X∣Y)=∑XP(X)log1P(X)−∑X,YP(X,Y)log1P(X∣Y)=∑X,YP(X,Y)log1P(X)−∑X,YP(X,Y)log1P(X∣Y)=∑X,YP(X,Y)logP(X∣Y)P(X)=∑X,YP(X,Y)logP(X,Y)P(X)P(Y)
\begin{array}{l}{I(X ; Y)=H(X)-H(X | Y)} \\ {\quad=\sum_{X} P(X) \log \frac{1}{P(X)}-\sum_{X, Y} P(X, Y) \log \frac{1}{P(X | Y)}} \\ {=\sum_{X, Y} P(X, Y) \log \frac{1}{P(X)}-\sum_{X, Y} P(X, Y) \log \frac{1}{P(X | Y)}} \\ {=\sum_{X, Y} P(X, Y) \log \frac{P(X | Y)}{P(X)}} \\ {=\sum_{X, Y} P(X, Y) \log \frac{P(X, Y)}{P(X) P(Y)}}\end{array}I(X;Y)=H(X)−H(X∣Y)=∑XP(X)logP(X)1−∑X,YP(X,Y)logP(X∣Y)1=∑X,YP(X,Y)logP(X)1−∑X,YP(X,Y)logP(X∣Y)1=∑X,YP(X,Y)logP(X)P(X∣Y)=∑X,YP(X,Y)logP(X)P(Y)P(X,Y) (2)(2)(2) 对式(b)(b)(b),由式(a)(a)(a)的推导知显然成立
(3)(3)(3) 对式(c)(c)(c),H(X,Y)=−∑X,YP(X,Y)logP(X,Y)=−∑XYXYP(X,Y)logP(X)−∑XYP(X,Y)logP(Y∣X)=−∑XP(X)logP(X)−∑XYP(X,Y)logP(Y∣X)=H(X)+H(Y∣X)
\begin{aligned} H(X, Y) &=-\sum_{X, Y} P(X, Y) \log P(X, Y) \\ &=-\sum_{X Y}^{X Y} P(X, Y) \log P(X)-\sum_{X Y} P(X, Y) \log P(Y | X) \\ &=-\sum_{X} P(X) \log P(X)-\sum_{X Y} P(X, Y) \log P(Y | X) \\ &=H(X)+H(Y | X) \end{aligned}
H(X,Y)=−X,Y∑P(X,Y)logP(X,Y)=−XY∑XYP(X,Y)logP(X)−XY∑P(X,Y)logP(Y∣X)=−X∑P(X)logP(X)−XY∑P(X,Y)logP(Y∣X)=H(X)+H(Y∣X) 同理可证H(X,Y)=H(Y)+H(X∣Y)H(X, Y)=H(Y)+H(X | Y)H(X,Y)=H(Y)+H(X∣Y)
(4)(4)(4)对式(d)(d)(d),有I(X;Y)+H(X,Y)=(H(X)−H(X∣Y))+(H(Y)+H(X∣Y))=H(X)+H(Y)\begin{aligned} I(X ; Y)+H(X, Y) &=(H(X)-H(X | Y))+(H(Y)+H(X | Y)) \\ &=H(X)+H(Y) \end{aligned}I(X;Y)+H(X,Y)=(H(X)−H(X∣Y))+(H(Y)+H(X∣Y))=H(X)+H(Y)
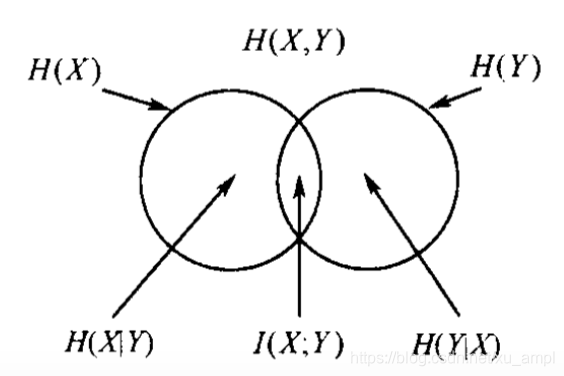
定理得证. 下图为联合熵、条件熵以及互信息之间的关系
四、相对熵
对定义于随机变量XXX的状态空间ΩX\Omega_{X}ΩX上的两个概率分布P(X)P(X)P(X)和Q(X)Q(X)Q(X),可以用相对熵来度量它们之间的差异,即有KL(P,Q)=∑xP(X)logP(X)Q(X)K L(P, Q)=\sum_{x} P(X) \log \frac{P(X)}{Q(X)}KL(P,Q)=x∑P(X)logQ(X)P(X)其中约定:log0q=0;plogp0=∞\log \frac{0}{q}=0 ; \quad p \log \frac{p}{0}=\inftylogq0=0;plog0p=∞
∀p>0.KL(P,Q)\forall p>0 . K L(P, Q)∀p>0.KL(P,Q)又被称为P(X)P(X)P(X)和Q(X)Q(X)Q(X)之间的 Kullback-Leibler \text { Kullback-Leibler } Kullback-Leibler 距离,但它不是一个真正意义上的距离,因为KL(P,Q)≠KL(Q,P)K L(P, Q) \neq K L(Q, P)KL(P,Q)̸=KL(Q,P)
定理3 (信息不等式)
设P(X)P(X)P(X)和Q(X)Q(X)Q(X)为定义在某个变量XXX的状态空间ΩX\Omega_{X}ΩX的两个概率分布,则有KL(P,Q)⩾0K L(P, Q) \geqslant 0KL(P,Q)⩾0其中,当且仅当PPP与QQQ相同,即P(X=x)=Q(X=x),∀x∈ΩXP(X=x)=Q(X=x), \forall x \in \Omega _XP(X=x)=Q(X=x),∀x∈ΩX时等号成立
证明
∑XP(X)logP(X)Q(X)=−∑XP(X)logQ(X)P(X)⩾−log∑XP(X)Q(X)P(X)(Jensen不等式)=−log∑XQ(X)=−log1=0\sum_{X} P(X) \log \frac{P(X)}{Q(X)}=-\sum_{X} P(X) \log \frac{Q(X)}{P(X)}\\\geqslant-\log \sum_{{X}} P(X) \frac{Q(X)}{P(X)}(Jensen不等式)\\{=-\log \sum_{X} Q(X)} {=-\log 1=0}X∑P(X)logQ(X)P(X)=−X∑P(X)logP(X)Q(X)⩾−logX∑P(X)P(X)Q(X)(Jensen不等式)=−logX∑Q(X)=−log1=0 定理得证
推论 对于满足∑Xf(X)>0\sum_{X} f(X)>0∑Xf(X)>0的非负函数f(X)f(X)f(X),定义概率分布P∗(X)P^{*}(X)P∗(X)为
P∗(X)=f(X)∑Xf(X)P^{*}(X)=\frac{f(X)}{\sum_{X} f(X)}P∗(X)=∑Xf(X)f(X) 那么对于任意其它的概率分布P(X)P(X)P(X),则有∑Xf(X)logP∗(X)⩾∑Xf(X)logP(X)\sum_{X} f(X) \log P^{*}(X) \geqslant \sum_{X} f(X) \log P(X)X∑f(X)logP∗(X)⩾X∑f(X)logP(X)其中当且仅当P∗P^*P∗与PPP相同时等号成立
证明: 根据上述定理有KL(P∗,P)=∑XP∗(X)logP∗(X)P(X)⩾0K L\left(P^{*}, P\right)=\sum_{X} P^{*}(X) \log \frac{P^{*}(X)}{P(X)} \geqslant 0KL(P∗,P)=X∑P∗(X)logP(X)P∗(X)⩾0因此有∑XP∗(X)logP∗(X)⩾∑XP∗(X)logP(X)\sum_{X} P^{*}(X) \log P^{*}(X) \geqslant \sum_{X} P^{*}(X) \log P(X)X∑P∗(X)logP∗(X)⩾X∑P∗(X)logP(X)即∑Xf(X)∑Xf(X)logP∗(X)⩾∑Xf(X)∑Xf(X)logP(X)\sum_{X} \frac{f(X)}{\sum_{X} f(X)} \log P^{*}(X) \geqslant \sum_{X} \frac{f(X)}{\sum_{X} f(X)} \log P(X)X∑∑Xf(X)f(X)logP∗(X)⩾X∑∑Xf(X)f(X)logP(X)从而有∑Xf(X)logP∗(X)⩾∑Xf(X)logP(X)\sum_{X} f(X) \log P^{*}(X) \geqslant \sum_{X} f(X) \log P(X)X∑f(X)logP∗(X)⩾X∑f(X)logP(X)推论得证
五、互信息与变量独立
定理4 对任意两个离散随机变量XXX和YYY,有
(1)(1)(1) I(X;Y)⩾0I(X ; Y) \geqslant 0I(X;Y)⩾0
(2)(2)(2) H(X∣Y)⩽H(X)H(X | Y) \leqslant H(X)H(X∣Y)⩽H(X)
上面两式当且仅当XXX和YYY相互独立时等号成立。
证明:由定理2中式 I(X;Y)=∑X,YP(X,Y)logP(X,Y)P(X)P(Y)I(X ; Y)=\sum_{X, Y} P(X, Y) \log \frac{P(X, Y)}{P(X) P(Y)}I(X;Y)=∑X,YP(X,Y)logP(X)P(Y)P(X,Y)可得I(X;Y)=KL(P(X,Y),P(X)P(Y))I(X ; Y)=K L(P(X, Y), P(X) P(Y))I(X;Y)=KL(P(X,Y),P(X)P(Y))即I(X;Y)I(X ; Y)I(X;Y)是分布于P(X,Y)P(X, Y)P(X,Y)和P(X)P(Y)P(X) P(Y)P(X)P(Y)之间的相对熵,根据信息不等式,I(X;Y)⩾0I(X ; Y) \geqslant 0I(X;Y)⩾0当且仅当
P(X,Y)=P(X)P(Y)P(X, Y)=P(X) P(Y)P(X,Y)=P(X)P(Y)时等号成立。亦即I(X;Y)=0I(X ; Y)=0I(X;Y)=0,当且仅当XXX和YYY相互独立。由于I(X;Y)=H(X)−H(X∣Y)I(X ; Y)=H(X)-H(X | Y)I(X;Y)=H(X)−H(X∣Y),所以H(X∣Y)⩽H(X)H(X | Y) \leqslant H(X)H(X∣Y)⩽H(X),且H(X∣Y)=H(X)H(X | Y)=H(X)H(X∣Y)=H(X)且仅当XXX和YYY相互独立,定理得证。
定理4 从信息论角度为边缘独立这一概念提供了一个直观解释,即两个随机变量相互独立当且仅当它们之间的互信息为零。
条件熵H(X∣Z)H(X|Z)H(X∣Z)表示给定ZZZ时XXX剩余的不确定性
再进一步给定YYY,H(X∣Z,Y)H(X | Z, Y)H(X∣Z,Y)为XXX剩余的不确定性
两者之差为给定ZZZ时观测YYY取值会带来的关于XXX的信息量,即I(X;Y∣Z)=H(X∣Z)−H(X∣Z,Y)I(X ; Y | Z)=H(X | Z)-H(X | Z, Y)I(X;Y∣Z)=H(X∣Z)−H(X∣Z,Y)称为给定ZZZ时YYY关于XXX的信息。易证I(X;Y∣Z)=I(Y;X∣Z)I(X ; Y | Z)=I(Y ; X | Z)I(X;Y∣Z)=I(Y;X∣Z),因此I(X;Y∣Z)I(X ; Y | Z)I(X;Y∣Z)也称为给定ZZZ时XXX和YYY的条件互信息
定理5 对任意3个离散随机变量X,YX,YX,Y和ZZZ,有
(1)(1)(1) I(X;Y∣Z)⩾0I(X ; Y | Z) \geqslant 0I(X;Y∣Z)⩾0
(2)(2)(2) H(X∣Y,Z)⩽H(X∣Z)H(X | Y, Z) \leqslant H(X | Z)H(X∣Y,Z)⩽H(X∣Z)
上式两式当且仅当X⊥Y∣ZX \perp Y|ZX⊥Y∣Z时等号成立
证明:I(X;Y∣Z)=H(X∣Z)−H(X∣Y,Z)=∑X,ZP(X,Z)log1P(X∣Z)−∑X,Y,ZP(X,Y,Z)log1P(X∣Y,Z)=∑X,Y,ZP(X,Y,Z)log1P(X∣Z)−∑X,Y,ZP(X,Y,Z)log1P(X∣Y,Z)=∑X,Y,ZP(X,Y,Z)logP(X∣Y,Z)P(X∣Z)\begin{aligned} I(X ; Y | Z) &=H(X | Z)-H(X | Y, Z) \\ &=\sum_{X, Z} P(X, Z) \log \frac{1}{P(X | Z)}-\sum_{X, Y, Z} P(X, Y, Z) \log \frac{1}{P(X | Y, Z)} \\ &=\sum_{X, Y, Z} P(X, Y, Z) \log \frac{1}{P(X | Z)}-\sum_{X, Y, Z} P(X, Y, Z) \log \frac{1}{P(X | Y, Z)} \\ &=\sum_{X, Y, Z} P(X, Y, Z) \log \frac{P(X | Y, Z)}{P(X | Z)} \end{aligned}I(X;Y∣Z)=H(X∣Z)−H(X∣Y,Z)=X,Z∑P(X,Z)logP(X∣Z)1−X,Y,Z∑P(X,Y,Z)logP(X∣Y,Z)1=X,Y,Z∑P(X,Y,Z)logP(X∣Z)1−X,Y,Z∑P(X,Y,Z)logP(X∣Y,Z)1=X,Y,Z∑P(X,Y,Z)logP(X∣Z)P(X∣Y,Z)=∑ZP(Z)∑X,YP(X,Y∣Z)logP(X,Y∣Z)P(X∣Z)P(Y∣Z)=∑ZP(Z)KL(P(X,Y∣Z),P(X∣Z)P(Y∣Z))⩾0
\begin{array}{l}{=\sum_{Z} P(Z) \sum_{X, Y} P(X, Y | Z) \log \frac{P(X, Y | Z)}{P(X | Z) P(Y | Z)}} \\ {=\sum_{Z} P(Z) K L(P(X, Y | Z), P(X | Z) P(Y | Z))} \\ {\geqslant 0}\end{array}
=∑ZP(Z)∑X,YP(X,Y∣Z)logP(X∣Z)P(Y∣Z)P(X,Y∣Z)=∑ZP(Z)KL(P(X,Y∣Z),P(X∣Z)P(Y∣Z))⩾0当且仅当(P(X,Y∣Z)=P(X∣Z)P(Y∣Z)(P(X, Y | Z)=P(X | Z) P(Y | Z)(P(X,Y∣Z)=P(X∣Z)P(Y∣Z),即X⊥Y∣ZX \perp Y|ZX⊥Y∣Z时等号成立
直观解释给定ZZZ,两个随机变量XXX和YYY相互条件独立,当且仅当它们的条件互信息为零。


















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










