




前言
在智慧农业、农产品自动化分拣等实际应用场景中,基于深度学习的蔬菜分类识别技术具备重要的实用价值。而高质量、划分规范的数据集,搭配主流目标检测模型的训练验证,是提升模型泛化能力与识别精度的关键。本文分享一套用于蔬菜分类的公开数据集,并基于该数据集完成多个主流 YOLO 版本模型的训练与效果对比,为相关研究与工程实践提供数据基础和参考依据。
一、数据集信息
本次实验采用自制蔬菜分类数据集,按照深度学习训练标准进行划分,具体构成如下:
- 训练集:3078 张
- 验证集:764 张
- 测试集:186 张
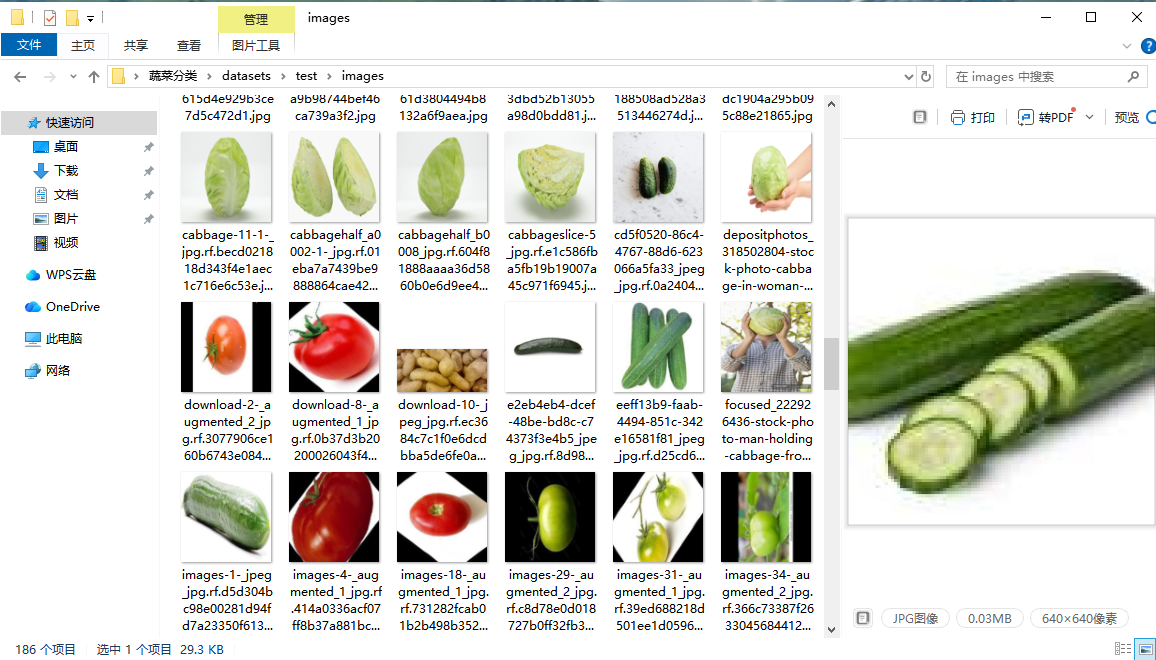
数据集覆盖常见蔬菜类别,样本具备一定的场景多样性,可直接用于模型训练、微调及性能测试,整体规模适合快速迭代实验与 baseline 构建。
二、训练模型信息
基于上述蔬菜分类数据集,分别使用五个版本 YOLO 模型完成完整训练流程,并记录训练过程与指标变化:
- YOLO v5
- YOLO v8
- YOLO v11
- YOLO v12
- YOLO v26
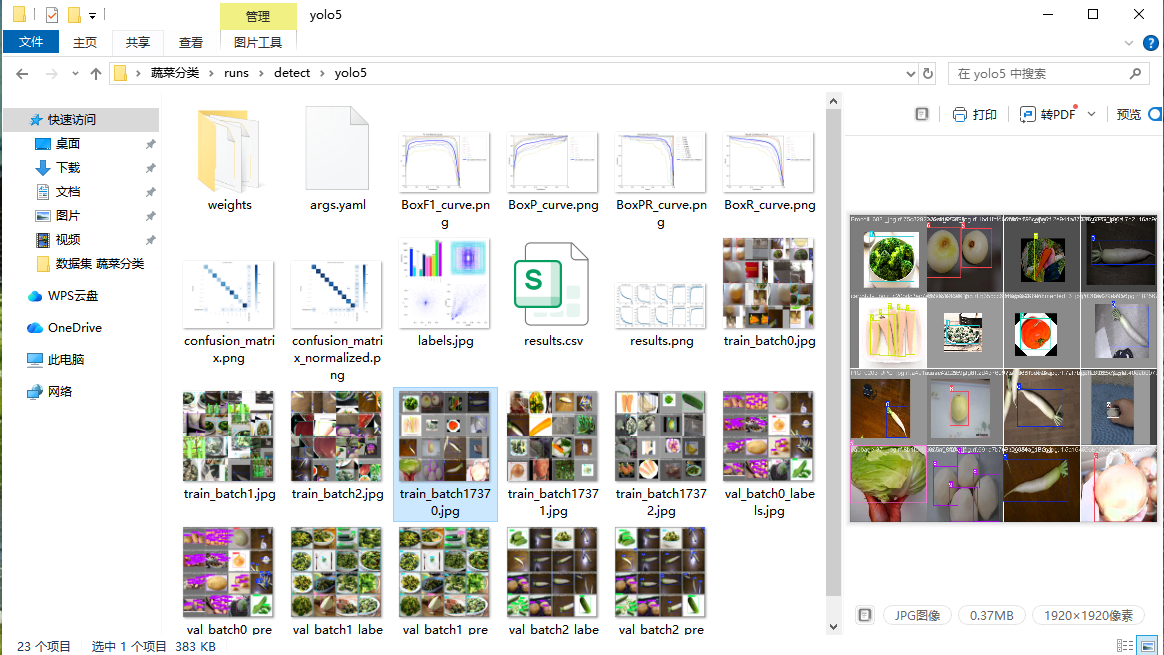
训练过程中均保留损失曲线、精度曲线、召回率等关键指标结果,可直观对比不同版本模型在该蔬菜数据集上的收敛速度、检测精度与训练稳定性差异。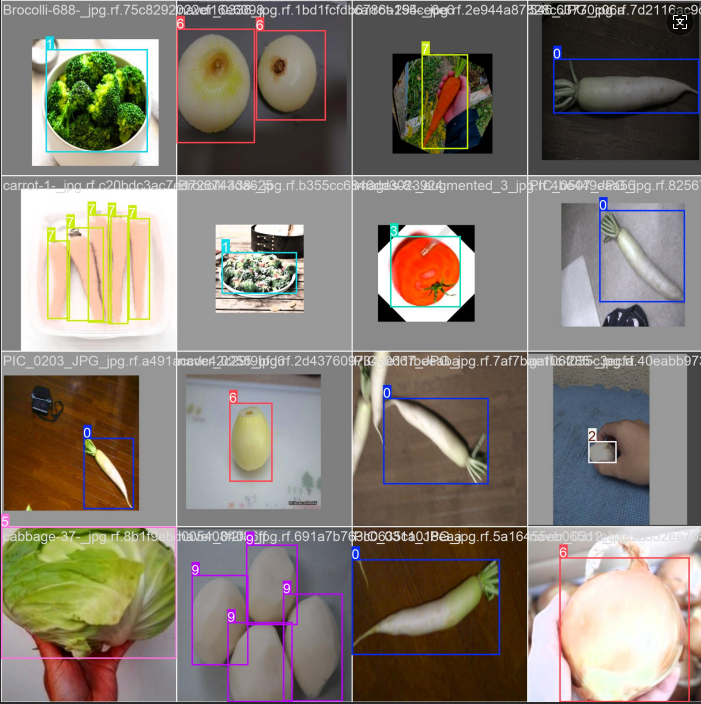
三、总结
本文提供了一份划分规范、规模适中的蔬菜分类数据集,并基于该数据集完成 YOLO v5、v8、v11、v12、v26 五个版本模型的训练与对比。实验结果可用于分析不同 YOLO 版本在蔬菜识别任务上的表现,为后续模型选型、参数调优以及实际部署提供可靠参考。该数据集与训练成果也可作为相关方向的基础实验资源,助力智慧农业相关视觉任务的快速开展。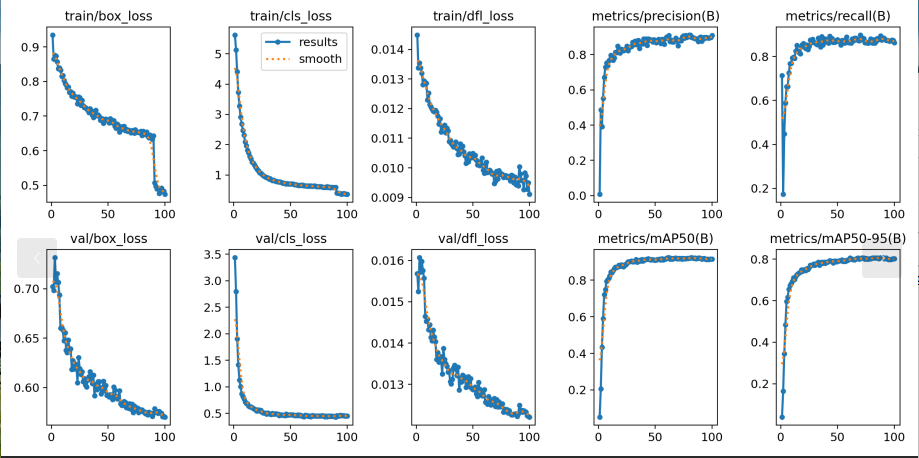

















 6824
6824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










