



这篇文章是二分答案的第一部分题目,这块题不少,分两次写。所有代码均为手搓或者优秀题解,大家可以放心使用,虽然不是最优解QAQ
算法笔记系列是作者在算法学习过程中的学习记录,会记录一些题目和通用方法,这块系列的更新不会暂停(因为力扣题是刷不完的哈哈哈),反正三四年内肯定是会持续更。我是一天一道,所以更新速度不会太快,喜欢的朋友可以follow,防止迷路。
闲话少叙,我们进入正题~
1、求最小
这种题目的通用思路就是:题目求什么,就二分什么。记住基础二分模型,只需要修改if的判断条件就好。
例题1 — 1283.使结果不超过阈值的最小除数
给你一个整数数组 nums 和一个正整数 threshold ,你需要选择一个正整数作为除数,然后将数组里每个数都除以它,并对除法结果求和。
请你找出能够使上述结果小于等于阈值 threshold 的除数中 最小 的那个。
每个数除以除数后都向上取整,比方说 7/3 = 3 , 10/2 = 5 。
题目保证一定有解。
示例 1:
输入:nums = [1,2,5,9], threshold = 6 输出:5 解释:如果除数为 1 ,我们可以得到和为 17 (1+2+5+9)。 如果除数为 4 ,我们可以得到和为 7 (1+1+2+3) 。如果除数为 5 ,和为 5 (1+1+1+2)。
示例 2:
输入:nums = [2,3,5,7,11], threshold = 11 输出:3
示例 3:
输入:nums = [19], threshold = 5 输出:4
提示:
1 <= nums.length <= 5 * 10^41 <= nums[i] <= 10^6nums.length <= threshold <= 10^6
class Solution:
def smallestDivisor(self, nums: List[int], threshold: int) -> int:
alls = sum(nums)
if alls <= threshold:
return 1
else:
left, right = 1, max(nums)
while left <= right:
mid = left + (right - left) // 2
temp = 0
for i in nums:
temp += (i - 1) // mid + 1
if temp > threshold:
left = mid + 1
else:
right = mid - 1
return left
#思路
题目是要求,一个数组每个元素同时除以一个数,得到的结果累加要小于或等于给定的阙值,求最小的除数。由于是整数除法(12 / 13 = 0),所以除数越大得到的求和的值越小,越满足题意,具有单调性,就可以用二分来找符合题意的位置。
细节:
1、不用去生成一个数组,我们只用改变左右两个端点的值就行,节省空间,除数最小肯定是1,最大就是nums中最大的数,这个数除完数组的累加和就是1,根据提示的信息,阙值肯定是大于等于1,因为阙值大于等于数组长度,数组最短肯定是1。
2、当数组所有值加起来都小于等于阙值时,1就是最小的,这个在这题的数据中可以作为节省空间和时间的方法,这个优化可以让代码两个复杂度都超过90%以上的人。
3、向上取整不能简单的加一,如果原本就是整数的话,加一会导致值变大,就错了,一定是原本的数要减一,除完后统一加一。
4、我这里用的是闭区间的写法,当然这题所有二分法都可以用,大家可以自己去试试看。容易报错,不是很好搞,建议先把基本方法练熟在来尝试。
例题2 — 2187.完成旅途的最小时间
给你一个数组 time ,其中 time[i] 表示第 i 辆公交车完成 一趟旅途 所需要花费的时间。
每辆公交车可以 连续 完成多趟旅途,也就是说,一辆公交车当前旅途完成后,可以 立马开始 下一趟旅途。每辆公交车 独立 运行,也就是说可以同时有多辆公交车在运行且互不影响。
给你一个整数 totalTrips ,表示所有公交车 总共 需要完成的旅途数目。请你返回完成 至少 totalTrips 趟旅途需要花费的 最少 时间。
示例 1:
输入:time = [1,2,3], totalTrips = 5 输出:3 解释: - 时刻 t = 1 ,每辆公交车完成的旅途数分别为 [1,0,0] 。 已完成的总旅途数为 1 + 0 + 0 = 1 。 - 时刻 t = 2 ,每辆公交车完成的旅途数分别为 [2,1,0] 。 已完成的总旅途数为 2 + 1 + 0 = 3 。 - 时刻 t = 3 ,每辆公交车完成的旅途数分别为 [3,1,1] 。 已完成的总旅途数为 3 + 1 + 1 = 5 。 所以总共完成至少 5 趟旅途的最少时间为 3 。
示例 2:
输入:time = [2], totalTrips = 1 输出:2 解释: 只有一辆公交车,它将在时刻 t = 2 完成第一趟旅途。 所以完成 1 趟旅途的最少时间为 2 。
提示:
1 <= time.length <= 1051 <= time[i], totalTrips <= 107
class Solution:
def minimumTime(self, time: List[int], totalTrips: int) -> int:
left, right = 1, min(time) * totalTrips
while left <= right:
mid = left + (right - left) // 2
temp = 0
for i in time:
temp += mid // i
if temp < totalTrips:
left = mid + 1
else:
right = mid - 1
return left
#思路
这题和上题其实差不多,绕来绕去就是要你求那个刚刚好大于的最小位置(毕竟是一个题单里面的哈哈哈)。我本来想要优化双循环的结构,但是发现好像除非不用二分否则都要有这个双循环(因为Python中循环比较慢,所以想要优化),而且无论我怎么改头尾初始化好像都没有太大区别,虽然这个代码时间空间都超90%以上的人。看看各位大佬有没有什么小妙招。
简单来说,这题就是用时越多越满足条件,有单调性可以用二分去找满足条件的最小时间。我用的还是闭区间写法,如果不喜欢可以自行更换。
细节:
1、计算趟数要拿总时间除以time[i],并且是要向下取整。
2、right是可以优化的,假设只有最小的time[i]去跑,所用时间可以做上限,因为在最小的time[i]跑的同时肯定还会有其他的time[i],所以实际用时一定小于我们设定的值。
例题3 — 1011.在D天内送达包裹的能力
传送带上的包裹必须在 days 天内从一个港口运送到另一个港口。
传送带上的第 i 个包裹的重量为 weights[i]。每一天,我们都会按给出重量(weights)的顺序往传送带上装载包裹。我们装载的重量不会超过船的最大运载重量。
返回能在 days 天内将传送带上的所有包裹送达的船的最低运载能力。
示例 1:
输入:weights = [1,2,3,4,5,6,7,8,9,10], days = 5 输出:15 解释: 船舶最低载重 15 就能够在 5 天内送达所有包裹,如下所示: 第 1 天:1, 2, 3, 4, 5 第 2 天:6, 7 第 3 天:8 第 4 天:9 第 5 天:10 请注意,货物必须按照给定的顺序装运,因此使用载重能力为 14 的船舶并将包装分成 (2, 3, 4, 5), (1, 6, 7), (8), (9), (10) 是不允许的。
示例 2:
输入:weights = [3,2,2,4,1,4], days = 3 输出:6 解释: 船舶最低载重 6 就能够在 3 天内送达所有包裹,如下所示: 第 1 天:3, 2 第 2 天:2, 4 第 3 天:1, 4
示例 3:
输入:weights = [1,2,3,1,1], days = 4 输出:3 解释: 第 1 天:1 第 2 天:2 第 3 天:3 第 4 天:1, 1
提示:
1 <= days <= weights.length <= 5 * 1041 <= weights[i] <= 500
class Solution:
def shipWithinDays(self, weights: List[int], days: int) -> int:
left, right = max(weights), sum(weights)
def can(load):
days_used = 1
start_rest = 0
for i in weights:
if start_rest + i <= load:
start_rest += i
else:
days_used += 1
start_rest = i
if days_used > days:
return False
return True
while left < right:
mid = left + (right - left) // 2
if can(mid):
right = mid
else:
left = mid + 1
return left#思路
假定「D 天内运送完所有包裹的最低运力」为 ans,那么在以 ans 为分割点的数轴上具有「二段性」:
数值范围在 (−∞,ans) 的运力必然「不满足」 D 天内运送完所有包裹的要求
数值范围在 [ans,+∞) 的运力必然「满足」 D天内运送完所有包裹的要求
即我们可以通过「二分」来找到恰好满足 D天内运送完所有包裹的分割点 ans。
接下来我们要确定二分的范围,由于不存在包裹拆分的情况,考虑如下两种边界情况:
理论最低运力:只确保所有包裹能够被运送,自然也包括重量最大的包裹,此时理论最低运力为 max,max 为数组 weights 中的最大值
理论最高运力:使得所有包裹在最短时间(一天)内运送完成,此时理论最高运力为 sum,sum 为数组 weights 的总和
由此,我们可以确定二分的范围为 [max,sum]。接下来就可以进行二分操作。
can函数用来判断这个天数是否可以满足要求,用了一个巧妙的结构,在一个循环中天数累加,如果天数超了且循环还没结束,就返回False,否则返回True。还有注意判断是否能加一定是要先判断加完之后的状态,如果只是判断当前状态,那么加完之后,如果超了。要等到下一次加才能检测出来,相当于有一天是超额的。
这题二分不能用我之前的模版,因为判断条件有些不一样,我们需要记录可以的容量,把答案先记录一下,所以right更新不用加一(这里搞不懂也没事,反正自己那个示例画个图就知道了,至于原理不清楚也无所谓,反正以后报错的时候留个心眼,记得查二分部分的代码就行)
例题4 — 875.爱吃香蕉的珂珂
珂珂喜欢吃香蕉。这里有 n 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 h 小时后回来。
珂珂可以决定她吃香蕉的速度 k (单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉 k 根。如果这堆香蕉少于 k 根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉。
珂珂喜欢慢慢吃,但仍然想在警卫回来前吃掉所有的香蕉。
返回她可以在 h 小时内吃掉所有香蕉的最小速度 k(k 为整数)。
示例 1:
输入:piles = [3,6,7,11], h = 8 输出:4
示例 2:
输入:piles = [30,11,23,4,20], h = 5 输出:30
示例 3:
输入:piles = [30,11,23,4,20], h = 6 输出:23
提示:
1 <= piles.length <= 104piles.length <= h <= 1091 <= piles[i] <= 109
class Solution:
def minEatingSpeed(self, piles: List[int], h: int) -> int:
n = len(piles)
left = 0 # 恒为 False
right = max(piles) # 恒为 True
while left + 1 < right: # 开区间不为空
mid = (left + right) // 2
if sum((p - 1) // mid for p in piles) <= h - n:
# 上面减去n是因为每次循环少加了1,可以参考另一个代码理解
right = mid # 循环不变量:恒为 True
else:
left = mid # 循环不变量:恒为 False
return right # 最小的 True
class Solution:
def minEatingSpeed(self, piles: List[int], h: int) -> int:
left, right = 1, sum(piles)
def can(speed):
h_used = 0
for i in piles:
h_used += (i - 1) // speed + 1
if h_used > h:
return False
return True
while left < right:
mid = left + (right - left) // 2
if can(mid):
right = mid
else:
left = mid + 1
return left#思路
给了大家两种代码,一个是用函数,一个没用,判断条件都差不多,还有就是在二分的时候方法不一样,一个是修改过的闭区间用法,一个是开区间用法。其实看到这里大家会发现这些题目都差不多,只是判断条件在变化而已。下面给出开区间的思路。
看示例 1,piles=[3,6,7,11], h=8。
如果珂珂能用 k=4 的速度吃掉所有香蕉,那么也能用更快的速度 k=5,6,⋯ 吃掉所有香蕉。
如果珂珂不能用 k=3 的速度吃掉所有香蕉,那么也不能用更慢的速度 k=2,1,⋯ 吃掉所有香蕉。
这种单调性意味着我们像 二分查找 那样,把答案 k 猜出来。
要解决的问题变成:
判断珂珂能否用 k 的速度,在 h 小时内吃掉所有香蕉。
假设一堆香蕉有 p=piles[i] 根,那么吃完这堆香蕉需要
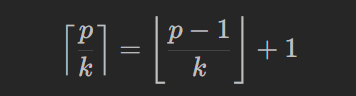
小时。上式可以分类讨论 p 是 k 的倍数,和 p 不是 k 的倍数两种情况证明。
如果满足
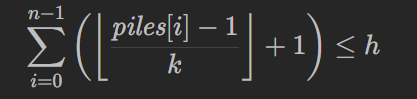
即
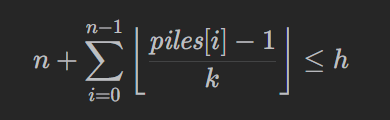
就说明珂珂可以用 k 的速度,在 h 小时内吃掉所有香蕉。
最后,确定二分的范围:
k=0 必然无法吃掉所有香蕉,作为(开区间的)左边界。
k=max(piles) 意味着 1 小时一定能吃完一堆香蕉,必然可以在 h 小时内吃掉所有香蕉(注意题目保证 n≤h),作为(开区间的)右边界。
例题5 — 3296.移山所需的最小秒数
给你一个整数 mountainHeight 表示山的高度。
同时给你一个整数数组 workerTimes,表示工人们的工作时间(单位:秒)。
工人们需要 同时 进行工作以 降低 山的高度。对于工人 i :
- 山的高度降低
x,需要花费workerTimes[i] + workerTimes[i] * 2 + ... + workerTimes[i] * x秒。例如:- 山的高度降低 1,需要
workerTimes[i]秒。 - 山的高度降低 2,需要
workerTimes[i] + workerTimes[i] * 2秒,依此类推。
- 山的高度降低 1,需要
返回一个整数,表示工人们使山的高度降低到 0 所需的 最少 秒数。
示例 1:
输入: mountainHeight = 4, workerTimes = [2,1,1]
输出: 3
解释:
将山的高度降低到 0 的一种方式是:
- 工人 0 将高度降低 1,花费
workerTimes[0] = 2秒。 - 工人 1 将高度降低 2,花费
workerTimes[1] + workerTimes[1] * 2 = 3秒。 - 工人 2 将高度降低 1,花费
workerTimes[2] = 1秒。
因为工人同时工作,所需的最少时间为 max(2, 3, 1) = 3 秒。
示例 2:
输入: mountainHeight = 10, workerTimes = [3,2,2,4]
输出: 12
解释:
- 工人 0 将高度降低 2,花费
workerTimes[0] + workerTimes[0] * 2 = 9秒。 - 工人 1 将高度降低 3,花费
workerTimes[1] + workerTimes[1] * 2 + workerTimes[1] * 3 = 12秒。 - 工人 2 将高度降低 3,花费
workerTimes[2] + workerTimes[2] * 2 + workerTimes[2] * 3 = 12秒。 - 工人 3 将高度降低 2,花费
workerTimes[3] + workerTimes[3] * 2 = 12秒。
所需的最少时间为 max(9, 12, 12, 12) = 12 秒。
示例 3:
输入: mountainHeight = 5, workerTimes = [1]
输出: 15
解释:
这个示例中只有一个工人,所以答案是 workerTimes[0] + workerTimes[0] * 2 + workerTimes[0] * 3 + workerTimes[0] * 4 + workerTimes[0] * 5 = 15 秒。
提示:
1 <= mountainHeight <= 1051 <= workerTimes.length <= 1041 <= workerTimes[i] <= 106
class Solution:
def minNumberOfSeconds(self, mountainHeight: int, workerTimes: List[int]) -> int:
left, right = 1, min(workerTimes) * mountainHeight * (mountainHeight + 1)
def can(used_times):
r_h = mountainHeight
for i in workerTimes:
k = 1
r_t = used_times
while r_t >= i * k:
r_t -= i * k
k += 1
r_h -= (k - 1)
if r_h <= 0:
return True
return False
while left < right:
mid = left + (right - left) // 2
if can(mid):
right = mid
else:
left = mid + 1
return left
class Solution:
def minNumberOfSeconds(self, mountainHeight: int, workerTimes: List[int]) -> int:
def check(m: int) -> bool:
left_h = mountainHeight
for t in workerTimes:
left_h -= (isqrt(m // t * 8 + 1) - 1) // 2
if left_h <= 0:
return True
return False
max_t = max(workerTimes)
h = (mountainHeight - 1) // len(workerTimes) + 1
return bisect_left(range(max_t * h * (h + 1) // 2), True, 1, key=check)
#思路
这题给大家两个代码,前面的是直接按照题意无任何加工出来的,后面的是一个比较好的题解,虽然可读性较差,但是确实很厉害。
基本思路如下:
由于花的时间越多,能够降低的高度也越多,所以有单调性,可以二分答案。
问题变成:
每个工人至多花费 m 秒,总共降低的高度是多少?能否大于等于 mountainHeight?
遍历 workerTimes,设 t=workerTimes[i],那么有

即
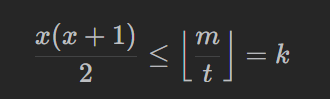
解得
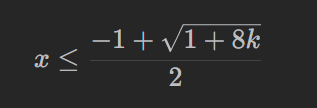
所以第 i 名工人可以把山的高度降低
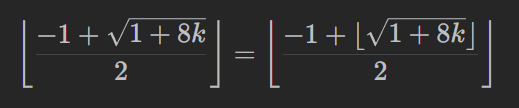
累加上式,如果和 ≥mountainHeight,则说明答案 ≤m,否则说明答案 >m。
最后,讨论二分的上下界。这里用开区间二分,其他二分写法也是可以的。
开区间二分下界:0,无法把山的高度降低到 0。
开区间二分上界:设 maxT 为 workerTimes 的最大值,假设每个工人都是最慢的 maxT,那么单个工人要把山降低 h=⌈mountainHeight/n⌉,耗时 maxT⋅(1+2+⋯+h)=maxT⋅ h(h+1)/2,将其作为开区间的二分上界,一定可以把山的高度降低到 ≤0。
关于上取整的计算,当 a 和 b 均为正整数时,我们有
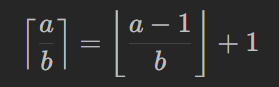
例题6 — 475. 供暖器
冬季已经来临。 你的任务是设计一个有固定加热半径的供暖器向所有房屋供暖。
在加热器的加热半径范围内的每个房屋都可以获得供暖。
现在,给出位于一条水平线上的房屋 houses 和供暖器 heaters 的位置,请你找出并返回可以覆盖所有房屋的最小加热半径。
注意:所有供暖器 heaters 都遵循你的半径标准,加热的半径也一样。
示例 1:
输入: houses = [1,2,3], heaters = [2] 输出: 1 解释: 仅在位置 2 上有一个供暖器。如果我们将加热半径设为 1,那么所有房屋就都能得到供暖。
示例 2:
输入: houses = [1,2,3,4], heaters = [1,4] 输出: 1 解释: 在位置 1, 4 上有两个供暖器。我们需要将加热半径设为 1,这样所有房屋就都能得到供暖。
示例 3:
输入:houses = [1,5], heaters = [2] 输出:3
提示:
1 <= houses.length, heaters.length <= 3 * 1041 <= houses[i], heaters[i] <= 109
class Solution:
def findRadius(self, houses: List[int], heaters: List[int]) -> int:
houses.sort()
heaters.sort()
left, right = 0, max(houses[-1] - heaters[0], heaters[-1] - houses[0])
def can(radius):
house_idx = 0 # 当前需要覆盖的房子索引
for heater in heaters:
# 当前加热器能覆盖的范围是 [heater - radius, heater + radius]
while house_idx < len(houses) and houses[house_idx] <= heater + radius:
# 检查这个房子是否在加热器的覆盖范围内
if houses[house_idx] >= heater - radius:
house_idx += 1 # 这个房子被覆盖了,检查下一个
else:
# 这个房子在加热器左边且超出覆盖范围
break
# 检查是否所有房子都被覆盖
return house_idx == len(houses)
while left < right:
mid = left + (right - left) // 2
if can(mid):
right = mid
else:
left = mid + 1
return left#思路
这题我写的比较中规中矩吧,如果要速度快需要耗费很多空间,而且代码量一下子就上去了,感觉没必要。
我们还是一招吃遍天下鲜,把之前的模版拿来改改就好,要改的无非就是can函数的内容,就是判断的内容而已。
细节:
1、两个数组不一定有序,一定要排序
2、两个数组的值和索引在写的时候要分清,别弄混了,导致边界更新错误
3、起始l、r要注意,l是0,因为有可能取暖器特别多,直接就在家里了;r是取两个数组前后极端值差的最多的长度。
其余部分注释都有,大家可以仔细看看,研究一下。
2、求最大
在练习时,请注意「求最小」和「求最大」的二分写法上的区别。整体来说,求最大的题目会比求最小的难上一点。
前面的「求最小」和二分查找求「排序数组中某元素的第一个位置」是类似的,按照红蓝染色法,左边是不满足要求的(红色),右边则是满足要求的(蓝色)。
「求最大」的题目则相反,左边是满足要求的(蓝色),右边是不满足要求的(红色)。这会导致二分写法和上面的「求最小」有一些区别。
以开区间二分为例:
求最小:check(mid) == true 时更新 right = mid,反之更新 left = mid,最后返回 right。
求最大:check(mid) == true 时更新 left = mid,反之更新 right = mid,最后返回 left。
对于开区间写法,简单来说 check(mid) == true 时更新的是谁,最后就返回谁。相比其他二分写法,开区间写法不需要思考加一减一等细节,推荐使用开区间写二分。
例题7 *— 275.H指数II
给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数,citations 已经按照 非降序排列 。计算并返回该研究者的 h 指数。
h 指数的定义:h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (n 篇论文中)至少 有 h 篇论文分别被引用了至少 h 次。
请你设计并实现对数时间复杂度的算法解决此问题。
示例 1:
输入:citations = [0,1,3,5,6]输出:3解释:给定数组表示研究者总共有5篇论文,每篇论文相应的被引用了0, 1, 3, 5, 6次。 由于研究者有3篇论文每篇 至少 被引用了3次,其余两篇论文每篇被引用 不多于3次,所以她的 h 指数是3。
示例 2:
输入:citations = [1,2,100]输出:2
提示:
n == citations.length1 <= n <= 1050 <= citations[i] <= 1000citations按 升序排列
class Solution:
def hIndex(self, citations: List[int]) -> int:
# 在区间 [left, right] 内询问
left = 1
right = len(citations)
while left <= right: # 区间不为空
# 循环不变量:
# left-1 的回答一定为「是」
# right+1 的回答一定为「否」
mid = (left + right) // 2
# 引用次数最多的 mid 篇论文,引用次数均 >= mid
if citations[-mid] >= mid: # 这样写才是,mid既是文章数,也可以表示引用次数
left = mid + 1 # 询问范围缩小到 [mid+1, right]
else:
right = mid - 1 # 询问范围缩小到 [left, mid-1]
# 循环结束后 right 等于 left-1,回答一定为「是」
# 根据循环不变量,right 现在是最大的回答为「是」的数
return right
#思路
这道题目很巧妙,我一开始是想再构建一个数组去二分,但看看别人的题解,确实很牛逼,这里就干脆展示灵神的题解好了,代码我选了一个我最爱闭区间。灵神的思路大概来说就是,我有原数组越往后引用是越多的,有单调性,那么我们可以用下标来计算论文数量,比如-2就是最后两篇嘛。因此,如果数组索引3的论文引用次数大于等于3,那后面的一定大于等于3,所以后面的文章全是满足条件的,可以用减法算出此时满足条件的文章数。按照这题的意思,我们可以去遍历文章数,如果引用数大于文章数,满足条件,可以扩大mid。这就把原有单调性转为函数的判断依据了。
细节:不可以用len(citaions) - mid >= citations[mid],会超出索引,比如citations = [0]时。
以下是灵神详细思路图解

如果想要其他解法大家可以自行去力扣上寻找。
例题8 — 2226.每个小孩最多能分到多少糖果
给你一个 下标从 0 开始 的整数数组 candies 。数组中的每个元素表示大小为 candies[i] 的一堆糖果。你可以将每堆糖果分成任意数量的 子堆 ,但 无法 再将两堆合并到一起。
另给你一个整数 k 。你需要将这些糖果分配给 k 个小孩,使每个小孩分到 相同 数量的糖果。每个小孩可以拿走 至多一堆 糖果,有些糖果可能会不被分配。
返回每个小孩可以拿走的 最大糖果数目 。
示例 1:
输入:candies = [5,8,6], k = 3 输出:5 解释:可以将 candies[1] 分成大小分别为 5 和 3 的两堆,然后把 candies[2] 分成大小分别为 5 和 1 的两堆。现在就有五堆大小分别为 5、5、3、5 和 1 的糖果。可以把 3 堆大小为 5 的糖果分给 3 个小孩。可以证明无法让每个小孩得到超过 5 颗糖果。
示例 2:
输入:candies = [2,5], k = 11 输出:0 解释:总共有 11 个小孩,但只有 7 颗糖果,但如果要分配糖果的话,必须保证每个小孩至少能得到 1 颗糖果。因此,最后每个小孩都没有得到糖果,答案是 0 。
提示:
1 <= candies.length <= 1051 <= candies[i] <= 1071 <= k <= 1012
class Solution:
def maximumCandies(self, candies: List[int], k: int) -> int:
left, right = 1, max(candies)
while left <= right:
mid = left + (right - left) // 2
temp = 0
for i in candies:
temp += i // mid
if temp >= k:
left = mid + 1
else:
right = mid - 1
return right#思路
这题比上题简单很多,判断条件很好写。我用的模版是闭区间的。
考虑这样一个问题:
能否让每个小孩都至少有 low 颗糖果?
low 越大,越难实现;low 越小,越容易实现。有单调性,可以二分答案。
比如最终 low=5 可以满足要求,但 low=6 无法满足要求,那么答案就是 5。
由于糖果堆只能分割不能合并,对于 candies[i] 来说,可以分出
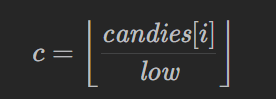
个大小为 low 的糖果堆,满足 c 个小孩。
如果满足
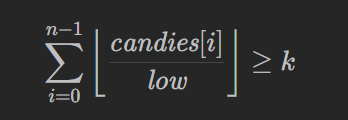
则说明每个小孩都可以有至少 low 颗糖果。此时可以增大二分左边界 left,继续二分。否则,减少二分右边界 right。
细节:
1、left, right的初始值可以这样想,如果人很多去分,那每个人就只能分一个,如果只有1个人,那他最多就能拿走最大的那堆,因为不一定要分完。
2、决定每堆能给几个人的除法要向下取整,因为不用分完,并且不可以合并。
例题9 — 1802.有界数组中指定下标处的最大值
给你三个正整数 n、index 和 maxSum 。你需要构造一个同时满足下述所有条件的数组 nums(下标 从 0 开始 计数):
nums.length == nnums[i]是 正整数 ,其中0 <= i < nabs(nums[i] - nums[i+1]) <= 1,其中0 <= i < n-1nums中所有元素之和不超过maxSumnums[index]的值被 最大化
返回你所构造的数组中的 nums[index] 。
注意:abs(x) 等于 x 的前提是 x >= 0 ;否则,abs(x) 等于 -x 。
示例 1:
输入:n = 4, index = 2, maxSum = 6 输出:2 解释:数组 [1,1,2,1] 和 [1,2,2,1] 满足所有条件。不存在其他在指定下标处具有更大值的有效数组。
示例 2:
输入:n = 6, index = 1, maxSum = 10 输出:3
提示:
1 <= n <= maxSum <= 1090 <= index < n
class Solution:
def maxValue(self, n: int, index: int, maxSum: int) -> int:
left, right = 1, maxSum - n + 1 # 闭区间写法
def can(biggest, index, longs, maxSum):
temp1 = temp2 = 0
if index > biggest - 1: #判断index的左边
temp1 = biggest * (biggest - 1) - biggest * (biggest - 1) // 2 + index - biggest + 1
else:
temp1 = biggest * index - index * (index + 1) // 2
if longs - index - 1 > biggest - 1: # 判断index的右边
temp2 = biggest * (biggest - 1) - biggest * (biggest - 1) // 2 + longs - index - biggest
else:
temp2 = biggest * (longs - index - 1) - (longs - index - 1) *(longs - index) // 2
if temp1 + temp2 + biggest <= maxSum: # 记得别漏加biggest
return True
return False
while left <= right: # 套用模版即可
mid = left +(right - left) // 2
if can(mid, index, n, maxSum):
left = mid + 1
else:
right = mid - 1
return right#思路
这题我感觉没有特别难,但是确实不好理解。我们翻译一下题目:要我们自己构建一个数组,并且在数组索引为index处的值尽可能最大,数组的每个值都是正整数>0(即最小为1),并且数组和小于maxSum,数组相邻的每个值差不大于1,并且数组长度已经给定。
看完我的翻译是不是感觉一下清晰很多,那我们要求的无非就是满足上述要求的最大值,而数组的总值已经确定,那要求单个位置上的最大值,说明其余位置的值越小越好(但是要满足题意)
这里我们可以根据这个条件“数组相邻的每个值差不大于1”来构造数组。试想,如果每个位置上的数差值为0,那这个数组肯定不会满足其余位置最小(因为对于目前的数组我们确定的值只有index位置上的,并且这个值也是我们二分出来的,如果其他位置的值都等于他,那这个数组会很大)。所以我们可以这样做,把整个数组根据index位置分为前后去算,两侧都从index位置的值开始递减1。假设index位置的值为x,那往前就是x - 1,x - 2这样,往后也是一样。但是要记得,如果在这个过程中,x的值不够减了,即到1了,那剩下的数就全为1(既满足最小,也满足数组的每个值都是正整数>0这个条件)。至于求和怎么求大家自己算算就好,这个很简单。也可以看我的代码,为了保证可读性,我并没有简化我的代码,大家可以拿去作参考。
例题10 — 2576.求出最多标记下标
给你一个下标从 0 开始的整数数组 nums 。
一开始,所有下标都没有被标记。你可以执行以下操作任意次:
- 选择两个 互不相同且未标记 的下标
i和j,满足2 * nums[i] <= nums[j],标记下标i和j。
请你执行上述操作任意次,返回 nums 中最多可以标记的下标数目。
示例 1:
输入:nums = [3,5,2,4] 输出:2 解释:第一次操作中,选择 i = 2 和 j = 1 ,操作可以执行的原因是 2 * nums[2] <= nums[1] ,标记下标 2 和 1 。 没有其他更多可执行的操作,所以答案为 2 。
示例 2:
输入:nums = [9,2,5,4] 输出:4 解释:第一次操作中,选择 i = 3 和 j = 0 ,操作可以执行的原因是 2 * nums[3] <= nums[0] ,标记下标 3 和 0 。 第二次操作中,选择 i = 1 和 j = 2 ,操作可以执行的原因是 2 * nums[1] <= nums[2] ,标记下标 1 和 2 。 没有其他更多可执行的操作,所以答案为 4 。
示例 3:
输入:nums = [7,6,8] 输出:0 解释:没有任何可以执行的操作,所以答案为 0 。
提示:
1 <= nums.length <= 1051 <= nums[i] <= 109
class Solution:
def maxNumOfMarkedIndices(self, nums: List[int]) -> int:
nums.sort()
left, right = 0, len(nums) // 2
while left <= right:
mid = left + (right - left) // 2
if all(nums[i] * 2 <= nums[i - mid] for i in range(mid)):
left = mid + 1
else:
right = mid - 1
return right * 2
class Solution:
def maxNumOfMarkedIndices(self, nums: List[int]) -> int:
nums.sort()
i = 0
for x in nums[(len(nums) + 1) // 2:]:
if nums[i] * 2 <= x: # 找到一个匹配
i += 1
return i * 2
#思路
这题说实话,我感觉有点偏数学了,感觉和二分反而没有太大关系。你能想到那个数学关系就能过,想不到就不行,而且其实二分用时也是很久,所以感觉这题就和基础算法没有太大的关系了,还是考验数学水平。我给大家看看灵神的思路吧,注释我就不写了,能看懂就看,看不懂就跳过吧大家。
第一个是二分,第二个是同向双指针。
方法一:二分答案
提示 1
如果 2⋅nums[i]≤nums[j],则称 nums[i] 与 nums[j] 匹配。
如果可以匹配 k 对,那么也可以匹配小于 k 对,去掉一些数对即可做到。
如果无法匹配 k 对,那么也无法匹配大于 k 对(反证法)。
所以 k 越大,越无法选出 k 个能匹配的数对。有单调性,就可以二分答案。
提示 2
现在问题变成:
能否从 nums 中选出 k 个能匹配的数对?
要让哪些数匹配呢?
结论:从小到大排序后,如果存在 k 对匹配,那么一定可以让最小的 k 个数与最大的 k 个数匹配。
证明:假设不是最小的 k 个数与最大的 k 个数匹配,那么我们总是可以把 nums[i] 替换成比它小的且不在匹配中的数,这仍然是匹配的;同理,把 nums[j] 替换成比它大的且不在匹配中的数,这仍然是匹配的。所以如果存在 k 对匹配,那么一定可以让最小的 k 个数和最大的 k 个数匹配。
反过来说,如果最小的 k 个数无法和最大的 k 个数匹配,则任意 k 对都无法匹配。(也可以用反证法证明)
从小到大排序后,nums[0] 要与 nums[n−k] 匹配。如果不这样做,nums[0] 与在 nums[n−k] 右侧的数匹配,相当于占了一个位置,那么后续要选个更大的 nums[i] 与 nums[n−k] 匹配,这不一定能匹配得上。
一般地,nums[i] 要与 nums[n−k+i] 匹配。
如果对于所有的 0≤i<k,都满足 2⋅nums[i]≤nums[n−k+i],那么就可以从 nums 中选出 k 个能匹配的数对。
方法二:同向双指针
由方法一的匹配方式可知,我们需要用 nums 左半部分中的数,去匹配 nums 右半部分中的数。
在 nums 的右半部分中,找到第一个满足 2⋅nums[0]≤nums[j] 的 j,那么 nums[1] 只能匹配右半部分中的下标大于 j 的数,依此类推。
这可以用同向双指针实现。
例题11 — 1898.可移除字符的最大数目
给你两个字符串 s 和 p ,其中 p 是 s 的一个 子序列 。同时,给你一个元素 互不相同 且下标 从 0 开始 计数的整数数组 removable ,该数组是 s 中下标的一个子集(s 的下标也 从 0 开始 计数)。
请你找出一个整数 k(0 <= k <= removable.length),选出 removable 中的 前 k 个下标,然后从 s 中移除这些下标对应的 k 个字符。整数 k 需满足:在执行完上述步骤后, p 仍然是 s 的一个 子序列 。更正式的解释是,对于每个 0 <= i < k ,先标记出位于 s[removable[i]] 的字符,接着移除所有标记过的字符,然后检查 p 是否仍然是 s 的一个子序列。
返回你可以找出的 最大 k ,满足在移除字符后 p 仍然是 s 的一个子序列。
字符串的一个 子序列 是一个由原字符串生成的新字符串,生成过程中可能会移除原字符串中的一些字符(也可能不移除)但不改变剩余字符之间的相对顺序。
示例 1:
输入:s = "abcacb", p = "ab", removable = [3,1,0] 输出:2 解释:在移除下标 3 和 1 对应的字符后,"abcacb" 变成 "accb" 。 "ab" 是 "accb" 的一个子序列。 如果移除下标 3、1 和 0 对应的字符后,"abcacb" 变成 "ccb" ,那么 "ab" 就不再是 s 的一个子序列。 因此,最大的 k 是 2 。
示例 2:
输入:s = "abcbddddd", p = "abcd", removable = [3,2,1,4,5,6] 输出:1 解释:在移除下标 3 对应的字符后,"abcbddddd" 变成 "abcddddd" 。 "abcd" 是 "abcddddd" 的一个子序列。
示例 3:
输入:s = "abcab", p = "abc", removable = [0,1,2,3,4] 输出:0 解释:如果移除数组 removable 的第一个下标,"abc" 就不再是 s 的一个子序列。 提示:
1 <= p.length <= s.length <= 1050 <= removable.length < s.length0 <= removable[i] < s.lengthp是s的一个 子字符串s和p都由小写英文字母组成removable中的元素 互不相同
class Solution(object):
def maximumRemovals(self, s, p, removable):
"""
:type s: str
:type p: str
:type removable: List[int]
:rtype: int
"""
n = len(s)
def can_remove_k_chars(k):
# 优化1:使用布尔数组而不是集合,避免哈希开销
is_removed = [False] * n
for i in range(k):
is_removed[removable[i]] = True
# 优化2:使用索引变量而不是重复访问len(s), len(p)
i = j = 0
p_len = len(p)
# 优化3:减少函数调用和条件判断
while i < n and j < p_len:
if not is_removed[i] and s[i] == p[j]:
j += 1
i += 1
return j == p_len
# 优化4:提前处理边界情况
if not p:
return len(removable)
if len(removable) == 0:
return 0
# 优化5:缓存removable长度
removable_len = len(removable)
# 二分查找
left, right = 0, removable_len
result = 0
while left <= right:
mid = (left + right) >> 1 # 优化6:位运算代替除法,即向右移一位
if can_remove_k_chars(mid):
result = mid # 直接保存结果,避免最后的right返回问题
left = mid + 1
else:
right = mid - 1
return result
#思路
这题简单来说就是我预先准备好一个总字符串和一个子字符串还有一个全是总字符串下标的数组。要求最大的k,即数组下标,并且要满足子字符串仍然是子字符串。
我原本想用字典,通过记述来判断。但是这种方法就没法考虑原始字符的顺序条件,所以最后采用的是双指针+二分的方法。
即s的指针不停向前,p的指针只有满足这个s的指针不是当前数组里面并且指针对应的值有在p里面才+1,如果最后p的指针遍历完所有字符,说明这个mid可以。
二分使用的是闭区间写法
所有优化都有注释标出,仅供参考(其实感觉优化了也快不了多少,这题数据还是蛮大的
例题12 — 1642. 可以到达的最远建筑
给你一个整数数组 heights ,表示建筑物的高度。另有一些砖块 bricks 和梯子 ladders 。
你从建筑物 0 开始旅程,不断向后面的建筑物移动,期间可能会用到砖块或梯子。
当从建筑物 i 移动到建筑物 i+1(下标 从 0 开始 )时:
- 如果当前建筑物的高度 大于或等于 下一建筑物的高度,则不需要梯子或砖块
- 如果当前建筑的高度 小于 下一个建筑的高度,您可以使用 一架梯子 或
(h[i+1] - h[i])个砖块
如果以最佳方式使用给定的梯子和砖块,返回你可以到达的最远建筑物的下标(下标 从 0 开始 )。
示例 1:

输入:heights = [4,2,7,6,9,14,12], bricks = 5, ladders = 1 输出:4 解释:从建筑物 0 出发,你可以按此方案完成旅程: - 不使用砖块或梯子到达建筑物 1 ,因为 4 >= 2 - 使用 5 个砖块到达建筑物 2 。你必须使用砖块或梯子,因为 2 < 7 - 不使用砖块或梯子到达建筑物 3 ,因为 7 >= 6 - 使用唯一的梯子到达建筑物 4 。你必须使用砖块或梯子,因为 6 < 9 无法越过建筑物 4 ,因为没有更多砖块或梯子。
示例 2:
输入:heights = [4,12,2,7,3,18,20,3,19], bricks = 10, ladders = 2 输出:7
示例 3:
输入:heights = [14,3,19,3], bricks = 17, ladders = 0 输出:3
提示:
1 <= heights.length <= 1051 <= heights[i] <= 1060 <= bricks <= 1090 <= ladders <= heights.length
class Solution:
def furthestBuilding(self, heights: List[int], bricks: int, ladders: int) -> int:
temp_arr_1 = []
for i in range(1, len(heights)):
temp_arr_1.append(heights[i] - heights[i - 1])
temp_arr_1.insert(0, 0)
def can(mid):
temp_arr_2 = temp_arr_1[:mid + 1]
positive_diffs = [x for x in temp_arr_2 if x > 0]
temp_arr_3 = sorted(positive_diffs, reverse=True)[:ladders]
ladder_count = Counter(temp_arr_3) # 改用Counter
a = bricks
b = ladders
for x in temp_arr_2:
if x > 0:
if ladder_count[x] > 0: #大的值都会被计数器计数
ladder_count[x] -= 1 # O(1)操作
b -= 1
elif a >= x:
a -= x
else:
return False
return True
#闭区间二分
left, right = 0, len(heights) - 1
while left <= right:
mid = (left + right) >> 1
if can(mid):
left = mid + 1
else:
right = mid - 1
return rightclass Solution:
# 1. 先建立一个高度差的 diff。
# 2. 对于每次循环,得到前 mid 个高度差并进行排序, 去除前ladder个(用梯子),
# 3. 将剩余的高度差求和 与 砖块数比较。
# 4. 如果和小于等于砖块数,则说明可以到达 mid 个建筑物,继续向右查找。
# 5. 如果和大于砖块数,则说明不能到达 mid 个建筑物,向左查找。
# 这种方法的时间复杂度是 O(n log n log n),其中 n 是建筑物的数量。
# 空间复杂度是 O(n),用于存储高度差。
def furthestBuilding(self, heights: List[int], bricks: int, ladders: int) -> int:
n, diff = len(heights), []
for i in range(n - 1):
diff.append(heights[i + 1] - heights[i])
def check(h):
cur_diff = [i for i in diff[:h] if i > 0]
cur_diff.sort(reverse=True)
return sum(cur_diff[ladders:]) <= bricks
l, r = 0, n - 1
while l <= r:
mid = (l + r) // 2
if check(mid):
l = mid + 1
else:
r = mid - 1
return r
#思路
给了两个代码,思路其实是一样的,但是第二个代码会简洁些,因为这题其实是不需要考虑顺序的,只要总数达到要求,就一定可以到。第一个是牺牲了时间和空间去考虑顺序了,第二个代码直接就看总数,所以很快。
代码细节写在注释里面了。这题还可以用堆来解,但是还没刷到,就不放出来了。
其实写到这里就会发现,二分无非就是一个模版,真实解决问题需要其他的许多想法,无论是算法还是数学,或者是一些思想技巧。题目一般都不单纯只有二分,需要大家多积累多练。
3、结语
这次的笔记就做到这里啦~
本来还想再往下做一题,感觉开始有点太难了,还是算了。
下期文章的内容还是二分相关问题
笔记大部分是我手打,有些地方可以会有点小问题。对于上述题目有疑问的可以评论区打出,我看到就会回复
大家一起加油吧~~~


















 497
497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










