




人工智能大模型技术这几年呈涌现式发展,随之带来的应用迭代来与日俱增,下面通过在阿里云PAI平台上进行两个简单的实验来感受一下大模型的一些概念。
目录
4.1执行lora微调脚本02_finetune_qwen3_medical.py. 23
4.2执行评估脚本02_test_finetuned_model.py. 28
5.1执行03_knowledge_distillation.py. 32
5.2 执行04_comparison_test_cases_final.py. 36
章节一 实验前准备
1.1注册阿里云账号并开通PAI平台相关权限
浏览器输入阿里云网址进入首页
https://www.aliyun.com/product/list
搜索PAI(阿里的AI一站式平台)
来到交互式建模(在此之前需要先按上面的流程来到PAI,按照指引授权开通相应的权限后才能使用),然后选择规格即可创建进行快速AI开发的容器环境(容器镜像-notebook实例)
准备环节总结(参考官方文档将重点内容进行摘录)
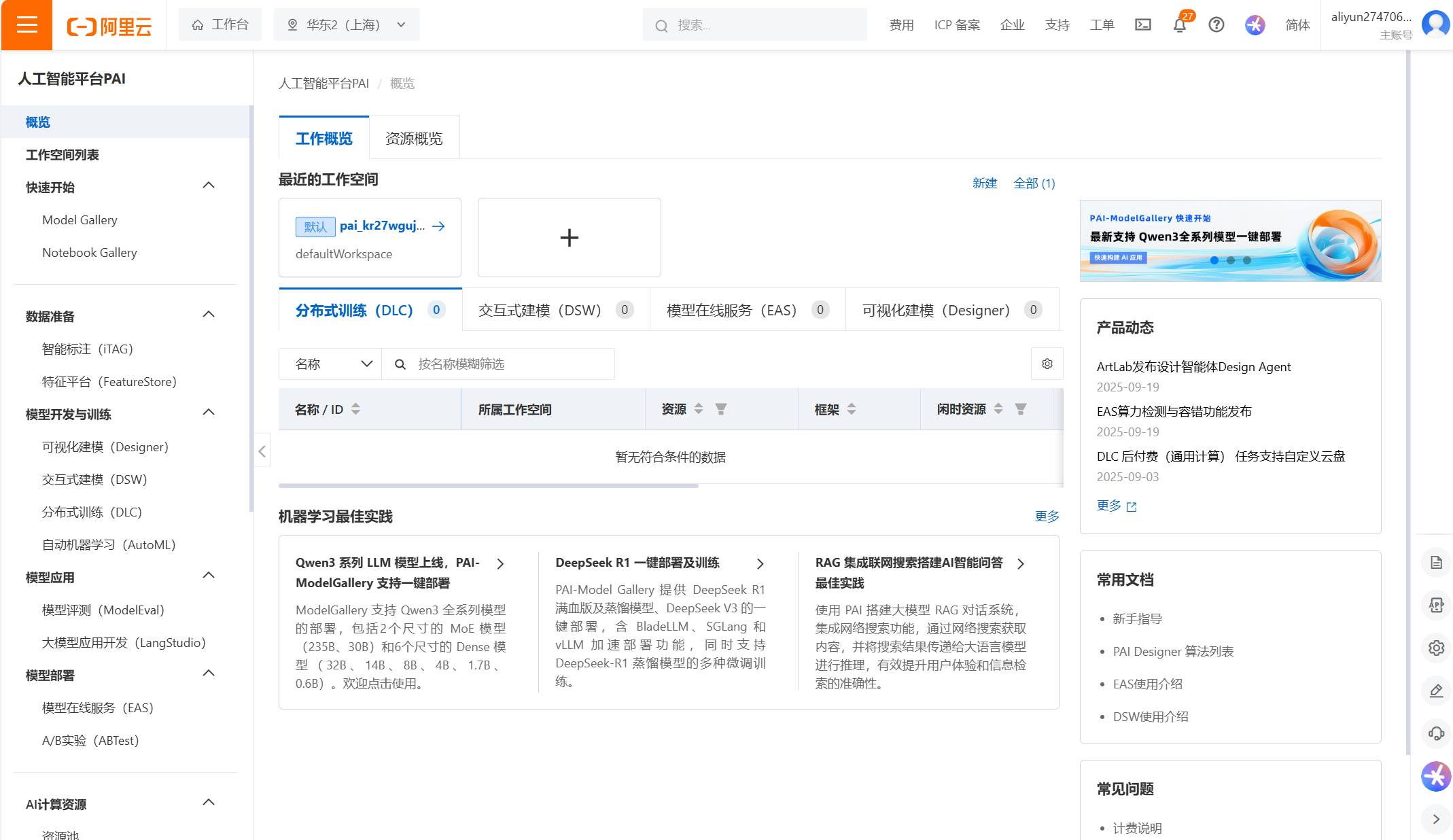
1.进入DSW页面
登录PAI控制台;
在概览页面选择目标地域;
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内;
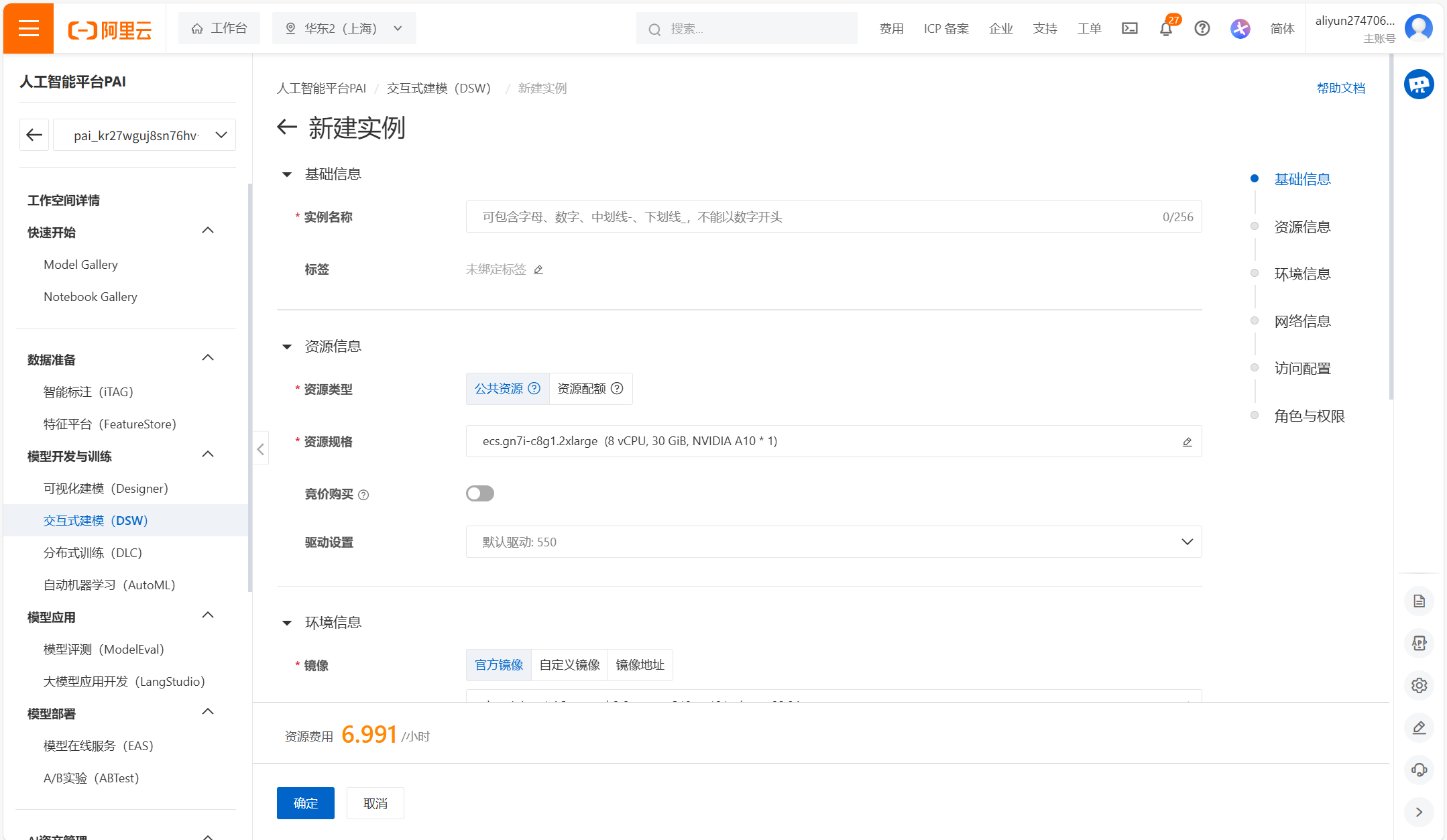
2.在工作空间页面的左侧导航栏选择模型开发与训练 > 交互式建模(DSW),进入DSW页面;
单击新建实例;
在配置实例向导页面,配置以下关键参数。
基础信息

资源信息

我们实验选择的实例规格为8核 64g内存 48g显存
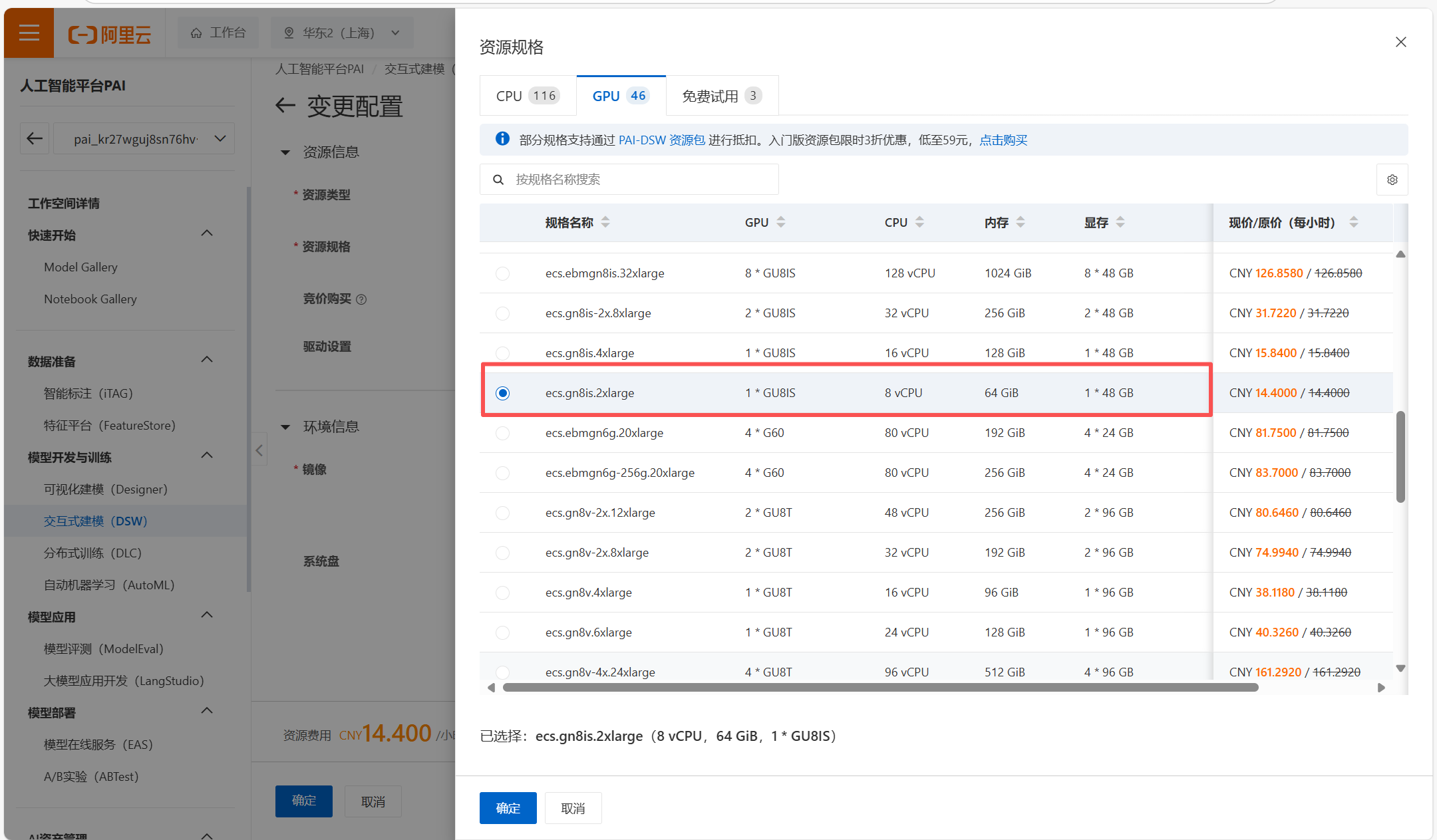
后面配置默认即可
启动后单击新增的网页进入开发实例
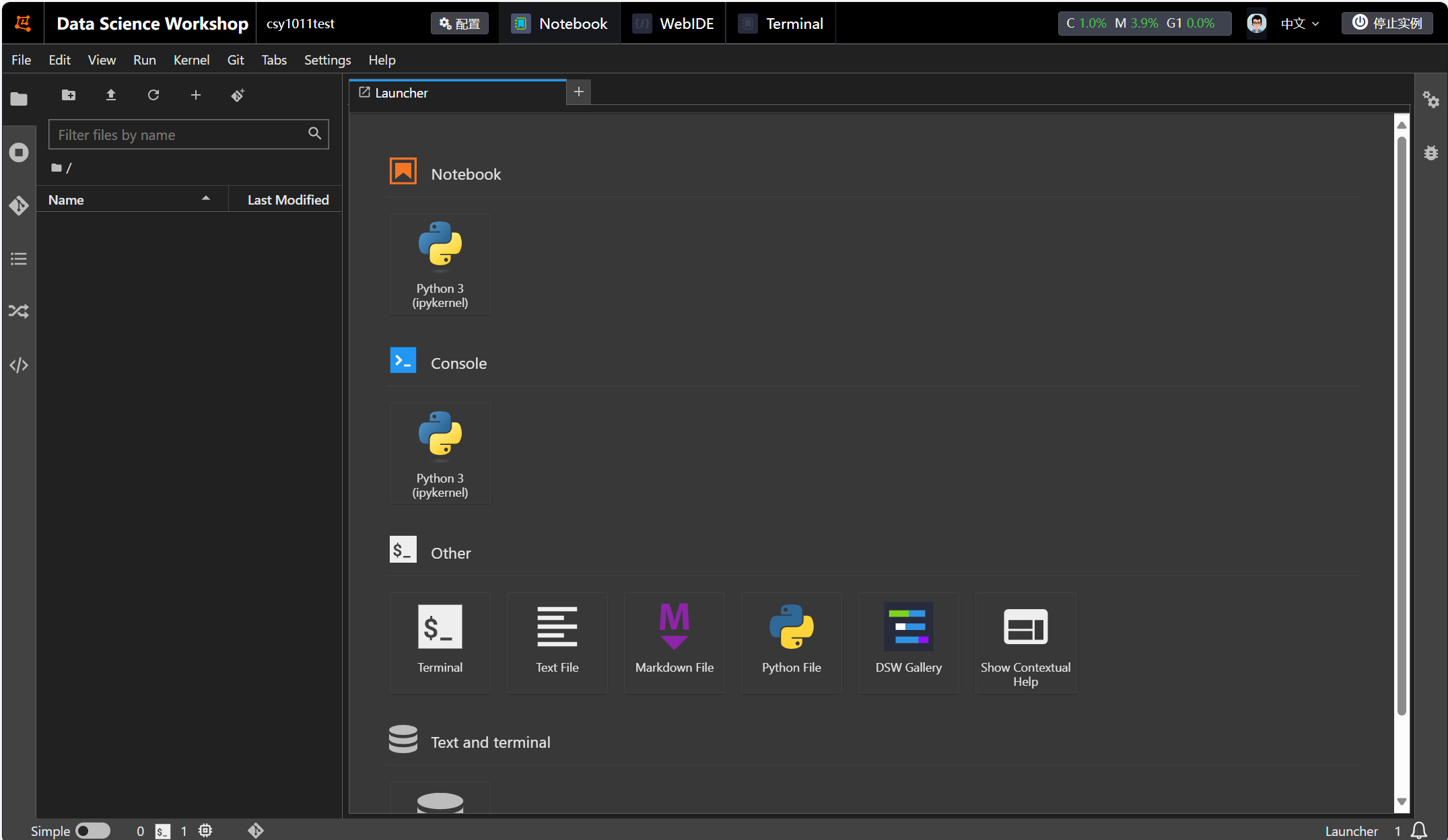
1.2提要
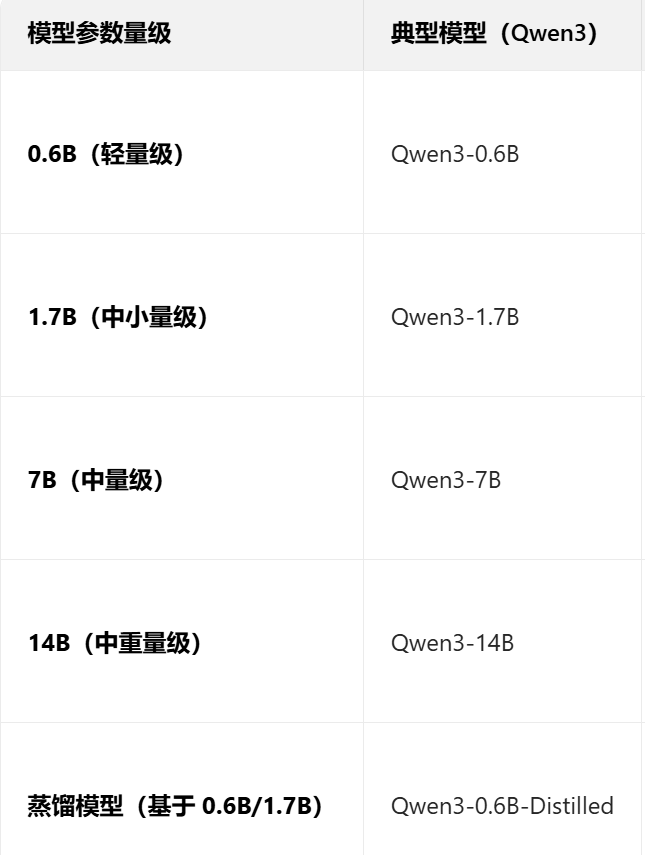
我在阿里云上DWS上起容器镜像的notebook实例(8核 内存64g 显存48g),微调数据集选用医疗对话数据-HuatuoGPT-sft-data-v1(在章节二会进行介绍),模型选择qwen3系列(后面也会介绍)。实验分为两个,实验一是使用采样5000条的huotuo数据集进行qwen3-0.6b的lora微调训练,受限于时间主要体现一个微调思想(微调在垂直领域-行业模型的应用);实验二是分析蒸馏模型的意义,基于实验一得到的qwen3-0.6b-lora和qwen3-1.7b-lora权重模型进行基线测试(0.6b-base、0.6b-lora、1.7b-base、1.7b-lora),对比体现微调和参数量两个不同因素对模型性能的影响。
补充说明:使用qwen3系列的思路可以无缝迁移到deepseek系列模型,因为这两款国内较为前沿的开源模型底层协议都遵循openai的范式,在应用层面上出入不大;对于实验演示使用的qwen3-0.6b模型,参数量最小是因为考虑时间因素,只要一套pipline跑地通(0.6b),切换模型参数只需要下载好对应的权重后在提供的脚本里更改模型路径即可(终端执行时更改后面的model参数),原理一样,只是随着数据集规格的增大、模型参数的增大,训练成本随之提高(算力、时间),但是也会得到性能更优的模型。
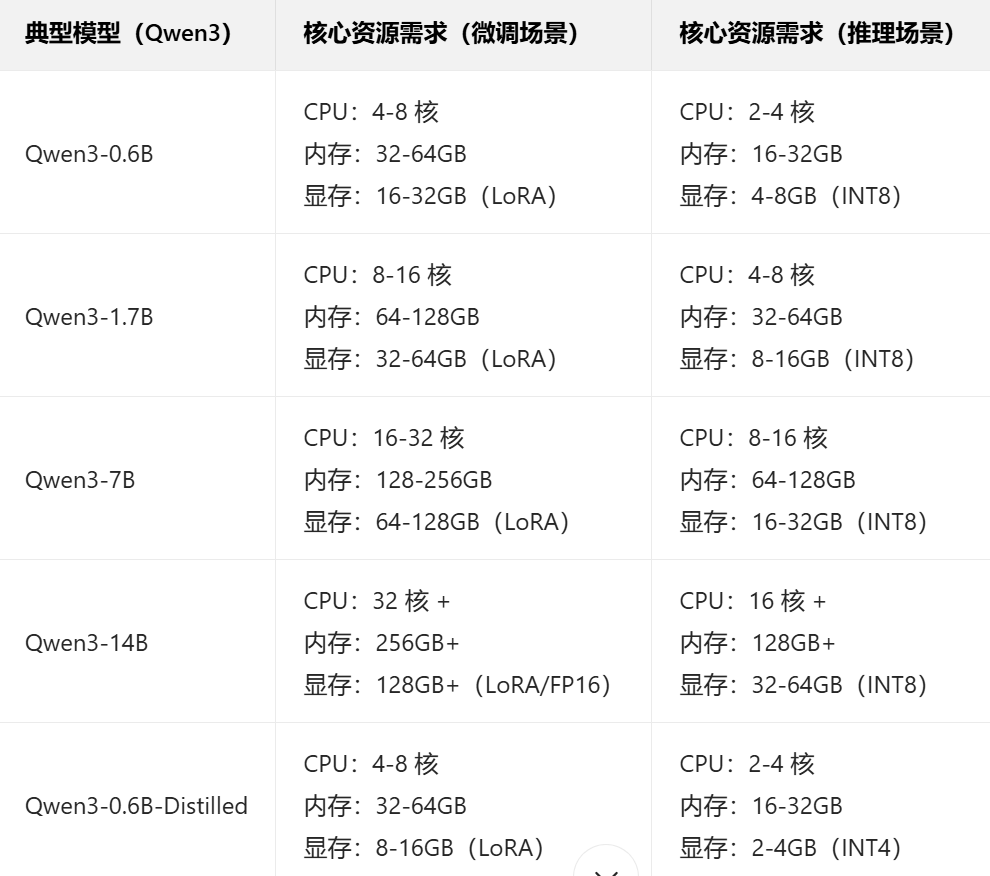
核心资源需求的核心影响因素,在梳理对应关系前,需明确资源消耗的关键变量,避免绝对化匹配。模型类型:基座模型(Base)> 指令微调模型(SFT)> 蒸馏模型(Distilled),相同参数量下,基座模型对资源需求最高。训练 / 推理模式:全参数微调 > LoRA/QLoRA 微调 > 推理部署,微调阶段需额外预留数据加载、梯度计算的资源。量化精度:FP32(4 字节 / 参数)> FP16(2 字节 / 参数)> BF16(2 字节 / 参数)> INT8(1 字节 / 参数)> INT4(0.5 字节 / 参数),量化可显著降低显存占用。数据集规模:单条样本越长、总样本量越大,对 CPU 内存的占用越高(需缓存数据批次)。


















 1252
1252

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










