




 本文介绍了如何使用Hive对网站浏览日志进行漏斗模型分析,包括计算每个步骤的访问人数、各步骤相对起点人数的比例以及漏出率。通过级联查询和自连接来获取数据,最后汇总两种关键指标,帮助理解用户行为转化过程。
本文介绍了如何使用Hive对网站浏览日志进行漏斗模型分析,包括计算每个步骤的访问人数、各步骤相对起点人数的比例以及漏出率。通过级联查询和自连接来获取数据,最后汇总两种关键指标,帮助理解用户行为转化过程。
网站浏览日志分析(5)漏斗模型分析
load data inpath’/hivedata/pageview/part-r-00000’ INTO TABLE ods_click_pageviews PARTITION(datestr=‘20130918’);
load data inpath’/hivedata/click-part-r-00000’ INTO TABLE ods_click_pageviews PARTITION(datestr=‘20130920’);
SELECT *FROM ods_click_pageviews;
1.需求:查询每一个步骤的总访问人数【这里将request字段中的 item/category/order/index 作为四步计算每一步有多少人访问】
【疑问:如果步骤非常多 我们要一个一个手写 step1/2/3/4/5…吗 自己想到可以动态+1 比如时间】
create table dw_oute_numbs as
select ‘step1’ as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr=‘20130920’ and request like ‘/item%’
union
select ‘step2’ as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr=‘20130920’ and request like ‘/category%’
union
select ‘step3’ as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr=‘20130920’ and request like ‘/order%’
union
select ‘step4’ as step,count(distinct remote_addr) as numbs from ods_click_pageviews where datestr=‘20130920’ and request like ‘/index%’;
SELECT *FROM dw_oute_numbs;
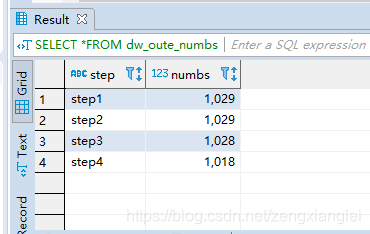
2.需求:查询每一步骤相对于路径起点人数的比例【这里需要用到级联查询,就是自己join 自己】
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr;
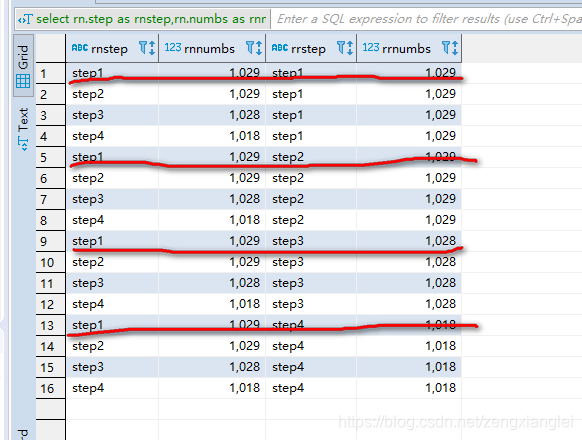
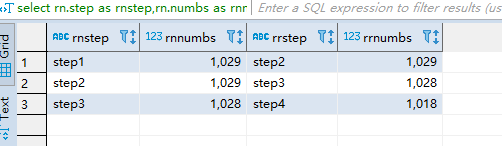
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr WHERE rn.step=‘step1’;
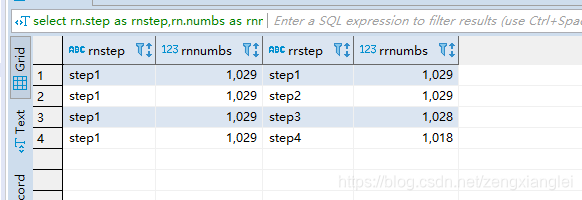
得到上图数据 计算需求很随意喽
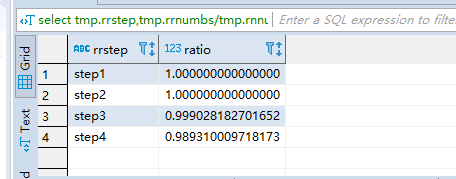
select tmp.rrstep,tmp.rrnumbs/tmp.rnnumbs as ratio
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where tmp.rnstep=‘step1’;
3.需求:查询每一步骤相对于上一步骤的漏出率【首先通过自join表过滤出每一步跟上一步的记录】
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr;
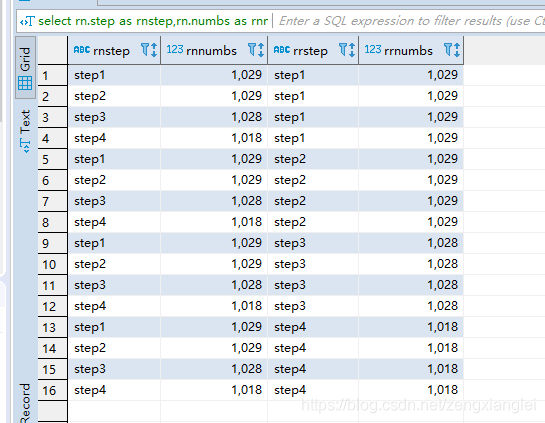
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr where cast(substr(rn.step,5,1) as int)=cast(substr(rr.step,5,1) as int)-1;
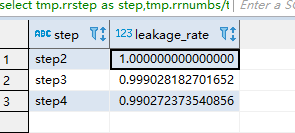
得到上如数据 就非常简单了 【通过普通的计算即可】
select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as leakage_rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1;
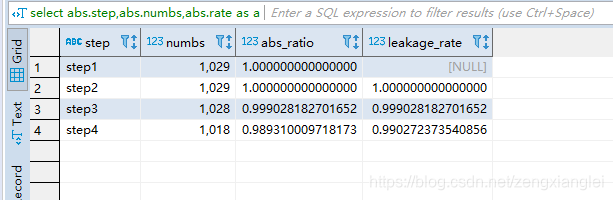
4.汇总以上(2和3需求) 俩种指标
select abs.step,abs.numbs,abs.rate as abs_ratio,rel.rate as leakage_rate
from
(
select tmp.rnstep as step,tmp.rnnumbs as numbs,tmp.rnnumbs/tmp.rrnumbs as rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where tmp.rrstep=‘step1’
) abs
left outer join
(
select tmp.rrstep as step,tmp.rrnumbs/tmp.rnnumbs as rate
from
(
select rn.step as rnstep,rn.numbs as rnnumbs,rr.step as rrstep,rr.numbs as rrnumbs from dw_oute_numbs rn
inner join
dw_oute_numbs rr) tmp
where cast(substr(tmp.rnstep,5,1) as int)=cast(substr(tmp.rrstep,5,1) as int)-1
) rel
on abs.step=rel.step;

















漏斗模型分析 针对pageviews&spm=1001.2101.3001.5002&articleId=90243369&d=1&t=3&u=2ab69ea33b1843129e70eaf74aae0957)
 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










