




该项目和【AI大模型应用开发】【项目实战】10.基于BERT+PET方式实现新零售行业决策评价系统
有很多相似的地方, 可以先看该篇文章加深理解, 再回过头来看当前文章
一.基于BERT+P-Tuning文本分类介绍
1. 项目背景
- 文本是信息传播的重要途径和载体,将文本数据正确归类,从而更好地组织、利用这些信息,具有重要的研究意义。文本分 类致力于解决上述问题,是自然语言处理 ( Natural Language Processing,NLP)领域的经典任务之一,被广泛应用于舆情 监测、情感分析等场景中。
- 目前实现文本分类的方法很多,如经典的应用于文本的卷积神经网络( Text-CNN) 、 循环神经网络 ( Text-RNN)、基于BERT等 预训练模型的fine-tuning等,但是这些方法多为建立在具有大量的标注数据下的有监督学习。在很多实际场景中,由于领域 特殊性和标注成本高,导致标注训练数据缺乏,模型无法有效地学习参数,从而易出现过拟合现象。因此,如何通过小样本 数据训练得到一个性能较好的分类模型是目前的研究热点
- 这里将以"电商平台用户评论"为背景,基于BERT+P-Tuning ( 软模版)方法实现评论文本的准确分类,这样做的目的在于提升用户体验。通过深入了解用户对不同商品或服务的评价,平台能够快速回应用户需求,改进产品和服务。自动分类也为 个性化推荐奠定基础,帮助用户更轻松地找到符合其偏好的商品。同时,这项技术降低了运营成本,替代了繁重的人工处理 工作。通过评论分析,电商平台还能迅速获取市场反馈,为商家提供有针对性的数据,助力制定精准的运营策略。
2. P-Tuning 回顾
2.1 定义
P-Tuning(Pattern-Tuning)是一种连续空间可学习模板, P- Tuning的目的是解决PET的缺点,使用可学习的向量作为伪模板,不再手动构建模板
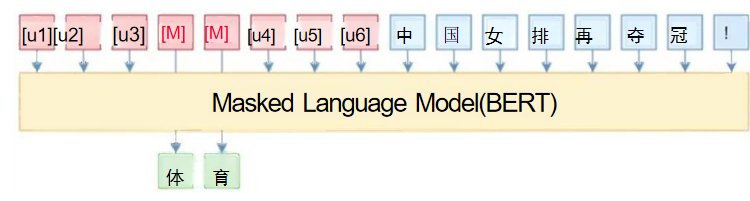
以新闻分类任务为例:原始文本:中国女排再夺冠! P-Tuning可学习模板:[u1][u2]…[MASK]…[un], Label: 体育/财经/时政/军事
2.2 P-Tuning 的实现过程
将模版(用特殊字符代替自然语言,特殊字符可以自由学习)与原始文本拼在一起输入预训练模型,预训练模型会对模板中的mask做预测,得到一个label
2.3 P-Tuning 的特点
- 优点
- 可学习模板参数, 全局优化学习到更好的模板表示
- 缓解人工模板带来的不稳定性
- 缺点
- 超多分类任务场景:预测难度大
- 蕴含任务(给定两句话,让模型判断两句话的逻辑关系)等不适合基于模板方式解决
3. 环境准备
基于 pytorch+transformers 实现,运行前请安装相关依赖包:

4. 项目架构
4.1 项目架构流程图
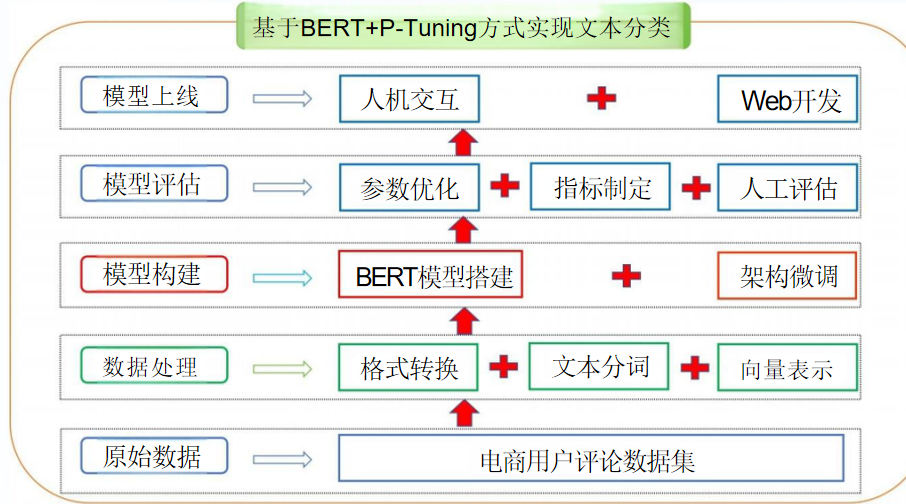
4.2 项目整体代码介绍

二.基于BERT+P-Tuning方式数据预处理
1. 查看项目数据集
数据存放位置:/P-Tuning/data
data文件夹里面包含3个txt文档,分别为:train.txt、dev.txt、verbalizer.txt
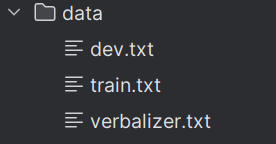
train.txt, dev.txt,verbalizer.txt和【上一篇】【项目实战】10.基于BERT+PET方式实现新零售行业决策评价系统
数据一致
2. 编写Config类项目文件配置代码
代码路径: /P-Tuning/ptune_confi g.py
config文件目的:
配置项目常用变量, 一般这些变量属于不经常改变的, 比如: 训练文件路径、模型训练次数、模型超参数等等
具体代码实现:
定义了一个用于配置深度学习项目(特别是基于 BERT 的 P-Tuning模型)的 Python 类 ProjectConfig
# coding:utf-8
import torch
class ProjectConfig(object):
def __init__(self):
# 是否使用GPU
self.device = 'cuda:0' if torch.cuda.is_available() else 'cpu' # windows电脑/linux服务器
# self.device = "mps:0" # MAC电脑
# 预训练模型bert路径
self.pre_model = '/www/python-data/P-Tuning/bert-base-chinese'
# 训练集和验证集的数据文件路径
self.train_path = '/www/python-data/P-Tuning/data/train.txt'
self.dev_path = '/www/python-data/P-Tuning/data/dev.txt'
# 定义标签词映射(将模型预测的 token 映射回实际分类标签)的文件路径
self.verbalizer = '/www/python-data/P-Tuning/data/verbalizer.txt'
# 输入文本的最大序列长度,超过此长度的文本将被截断
self.max_seq_len = 256
# 每次训练迭代送入模型的样本数量
self.batch_size = 8
# 学习率
self.learning_rate = 5e-5
# 权重衰减系数,用于防止过拟合,这里设为 0 表示不使
self.weight_decay = 0
# 预热学习率(用来定义预热的步数), 学习率预热比例
# 在训练初期,学习率会从 0 线性增加到设定值,防止模型在初期因梯度不稳定而崩溃。
# 这里表示预热的步数占总训练步数的 6%
self.warmup_ratio = 0.06
# 伪token的个数
self.p_embedding_num = 6
# 标签的最大长度(在 PET 中,标签通常由一个或几个词组成
self.max_label_len = 2
# 整个数据集被遍历训练的轮数
self.epochs = 20
# 每训练 2 个 step 打印一次训练日志(如 loss 等)
self.logging_steps = 2
# 每训练 20 个 step 在验证集上进行一次评估
self.valid_steps = 20
# 训练过程中保存模型权重(checkpoints)的本地目录路径
self.save_dir = '/www/python-data/P-Tuning/checkpoints'
if __name__ == '__main__':
pc = ProjectConfig()
print(pc.verbalizer)
3. 编写数据处理相关代码
代码路径:/PET/data_handle
data_handle文件夹中一共包含两个py脚本:
data_preprocess.py,data_loader.py
data_preprocess.py
目的 : 将样本数据转换为模型接受的输入数据,导入必备的工具包
代码是 P-Tuning模型中至关重要的数据预处理模块,它的核心任务是将原始的文本数据(如 电脑\t这款笔记本外观不错)转换成模型能够理解的数字格式(Input IDs),将模板与原始输入文本进行拼接,构造模型接受的输入数, 定义数据转换方法convert_example()
# 导入必备工具包
import torch
import numpy as np
from rich import print
from datasets import load_dataset
from transformers import AutoTokenizer
from ptune_config import *
from functools import partial
def convert_example(
examples: dict,
tokenizer,
max_seq_len: int,
max_label_len: int,
p_embedding_num=6,
train_mode=True,
return_tensor=False
) -> dict:
"""
将样本数据转换为模型接收的输入数据。
Args:
examples (dict): 训练数据样本, e.g. -> {
"text": [
'娱乐 嗨放派怎么停播了',
'体育 世界杯为何迟迟不见宣传',
...
]
}
max_label_len (int): 最大label长度,若没有达到最大长度,则padding为最大长度
p_embedding_num (int): p-tuning token 的个数
train_mode (bool): 训练阶段 or 推理阶段。
return_tensor (bool): 是否返回tensor类型,如不是,则返回numpy类型。
Returns:
dict (str: np.array) -> tokenized_output = {
'input_ids': [[101, 3928, ...], [101, 4395, ...]],
'token_type_ids': [[0, 0, ...], [0, 0, ...]],
'mask_positions': [[5, 6, ...], [3, 4, ...]],
'mask_labels': [[183, 234], [298, 322], ...]
}
"""
tokenized_output = {
'input_ids': [],
'attention_mask': [],
'mask_positions': [], # 记录label的位置(即MASK Token的位置)
'mask_labels': [] # 记录MASK Token的原始值(即Label值)
}
"""
examples--》Dataset({
features: ['text'],
num_rows: 63
})
"""
# print(f'examples--》{examples}')
# print("*"*80)
"""
examples['text']--》Column(['电脑\t(1)这款笔记本外观感觉挺漂亮的,分量吗,对我
来说不算沉。 , '水果\t很差的果,表面色泽就已经看到不新鲜啦,跟图片相比,简直一个天一个地,还有
烂果,果大细不一致,小到哭。'...])
"""
# print(f"examples['text']--》{examples['text']}")
for i, example in enumerate(examples['text']):
try:
start_mask_position = 1 # 将 prompt token(s) 插在 [CLS] 之后
if train_mode:
label, content = example.strip().split('\t', 1) # 1 表示只切一次
# print(f'label--》{label}') # label--》电脑
"""
content--》(1)这款笔记本外观感觉挺漂亮的,分量吗,对我来说不算沉。
(2)安装了WindowsXP系统后,运行的速度挺快。发热量没有想象中那么大。可能尚未运行
很耗资源的程序,没有感到内存的弊病。不过,1G的内存确实有点小。
(3)附赠的包很不错,挺有手感的。但是附赠的鼠标实在是太小了,幸好同时订了一个双飞
燕的鼠标哟。
"""
# print(f'content--》{content}')
else:
content = example.strip()
# 对content进行编码
encoded_inputs = tokenizer(
text=content,
truncation=True,
max_length=max_seq_len, # 最大长度
padding='max_length' #补齐最大长度
)
except:
continue
input_ids = encoded_inputs['input_ids']
"""
encoded_inputs-->{'input_ids': [101, 113, 122, 114, 6821, 3621, 5011, 6381,
3315, 1912, 6225, 2697, 6230, 2923, 4023, 778, 4638, 8024, 1146, 7030, 1408,
8024, 2190, 2769, 3341, 6432, 679, 5050, 3756, 511, 113, 123, 114, 2128, 6163,
749, 100, 5143, 5320, 1400, 8024, 6817, 6121, 4638, 6862, 2428, 2923, 2571,
511, 1355, 4178, 7030, 3766, 3300, 2682, 6496, 704, 6929, 720, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1]}
"""
# print(f'encoded_inputs-->{encoded_inputs}')
# print("*"*80)
"""
input_ids-->[101, 113, 122, 114, 6821, 3621, 5011, 6381, 3315, 1912, 6225,
2697, 6230, 2923, 4023, 778, 4638, 8024, 1146, 7030, 1408, 8024, 2190, 2769,
3341, 6432, 679, 5050, 3756, 511, 113, 123, 114, 2128, 6163, 749, 100, 5143,
5320, 1400, 8024, 6817, 6121, 4638, 6862, 2428, 2923, 2571, 511, 1355, 4178,
7030, 3766, 3300, 2682, 6496, 704, 6929, 720, 102]
"""
# print(f'input_ids-->{input_ids}') # input_ids就是原始的x(输入值)
# print(f'原始的input_id的长度-->{len(input_ids)}') # 原始的input_id的长度-->60
mask_tokens = ['[MASK]'] * max_label_len # 1.生成 MASK Tokens, 和label长度一致
# print(f'mask_tokens-->{mask_tokens}') # mask_tokens-->['[MASK]', '[MASK]']
mask_ids = tokenizer.convert_tokens_to_ids(mask_tokens) # token 转 id
# print(f'mask_ids-->{mask_ids}') # mask_ids-->[103, 103]
# 列表生成式: unused和bert-base-chinese下面的vocab.txt对应
p_tokens = ["[unused{}]".format(i + 1) for i in range(p_embedding_num)] # 2.构建 prompt token(s)
# print(f'p_tokens-->{p_tokens}') # 里面是空的,但有数据, 是一个伪token: p_tokens-->['', '', '', '', '', '']
p_tokens_ids = tokenizer.convert_tokens_to_ids(p_tokens) # token 转 id
# print(f'p_tokens_ids-->{p_tokens_ids}') # p_tokens_ids-->[1, 2, 3, 4, 5, 6], 对应vocab.txt中unused的索引
tmp_input_ids = input_ids[:-1] # 不取最后一个值,剔除最后一个token
# print(f'tmp_input_ids-->{len(tmp_input_ids)}') # tmp_input_ids-->59
tmp_input_ids = tmp_input_ids[:max_seq_len - len(mask_ids) - len(p_tokens_ids)-1] # 根据最大长度-p_token长度-label长度,裁剪content的长度, 给后面的伪token留空, 好进行拼接
"""
tmp_input_ids1-->[101, 113, 122, 114, 6821, 3621, 5011, 6381, 3315, 1912, 6225,
2697, 6230, 2923, 4023, 778, 4638, 8024, 1146, 7030, 1408, 8024, 2190, 2769,
3341, 6432, 679, 5050, 3756, 511, 113, 123, 114, 2128, 6163, 749, 100, 5143,
5320, 1400, 8024, 6817, 6121, 4638, 6862, 2428, 2923, 2571, 511, 1355, 4178]
"""
# print(f'tmp_input_ids1-->{tmp_input_ids}')
print(len(tmp_input_ids)) # 51
tmp_input_ids = tmp_input_ids[:start_mask_position] + mask_ids + tmp_input_ids[
# 3.插入 MASK -> [CLS][MASK][MASK]世界杯...[SEP]
start_mask_position:]
"""
tmp_input_ids2--[101, 103, 103, 113, 122, 114, 6821, 3621, 5011, 6381, 3315,
1912, 6225, 2697, 6230, 2923, 4023, 778, 4638, 8024, 1146, 7030, 1408, 8024,
2190, 2769, 3341, 6432, 679, 5050, 3756, 511, 113, 123, 114, 2128, 6163, 749,
100, 5143, 5320, 1400, 8024, 6817, 6121, 4638, 6862, 2428, 2923, 2571, 511,
1355, 4178]
"""
# print(f'tmp_input_ids2--{tmp_input_ids}')
# print(f'插入mask之后的数据长度tmp_input_ids2-->{len(tmp_input_ids)}') # 入mask之后的数据长度tmp_input_ids2-->53
input_ids = tmp_input_ids + [input_ids[-1]] # 补上[SEP]
"""
input_ids11-->[101, 103, 103, 113, 122, 114, 6821, 3621, 5011, 6381, 3315,
1912, 6225, 2697, 6230, 2923, 4023, 778, 4638, 8024, 1146, 7030, 1408, 8024,
2190, 2769, 3341, 6432, 679, 5050, 3756, 511, 113, 123, 114, 2128, 6163, 749,
100, 5143, 5320, 1400, 8024, 6817, 6121, 4638, 6862, 2428, 2923, 2571, 511,
1355, 4178, 102]
"""
# print(f'input_ids11-->{input_ids}')
# 得到了最终的input_ids
input_ids = p_tokens_ids + input_ids # 4.插入 prompt -> [unused1][unu



















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










