




# 加速下载
pip install some-package -i https://pypi.tuna.tsinghua.edu.cn/simple
# 配置清华大学镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
阿里云: https://mirrors.aliyun.com/pypi/simple/
豆瓣: http://pypi.douban.com/simple/
一、基础知识
1、基本数据类型
Number(数字): int、float、bool(0/1)、complex(复数)String(字符串): 用单引号 ’ 或双引号 " 括起来,同时使用反斜杠\转义特殊字符Bool(布尔): True/FalseList(列表): 列表中元素的类型可以不相同,支持数字、字符串、嵌套列表,使用中括号"[]"表示,元素之间用逗号隔开Tuple(元组): 与列表类似,但元组的元素不能修改,使用小括号"()"表示,元素之间用逗号隔开Set(集合): 是一种无序、可变的数据类型,用于存储唯一的元素,使用大括号"{}"表示,元素之间用逗号分隔Dictionary(字典): 是一种映射类型,元素通过键来存取的,使用"{}"标识,它是一个无序的"key:value"的集合Byte(字节数组): 是不可变的二进制序列(byte sequence),元素是整数值(0到255之间的整数),而不是Unicode字符
数据类型分类:
不可变数据(Immutable,变量重赋值等于新建):Number、String、Tuple可变数据(Changeable,变量重赋值等于替换):List、Dictionary、Set、Bytes
数据类型非空判断:
True:非零的数字、字符串、列表、元组、字典False:False、None、0(0、0.0、0j)、“”、[]、{}、()、set()
2、数据类型转换
精度:布尔(bool)< 整型(int) < 浮点型(float)< 复数(complex)
2.1、隐式类型转换
Python 自动将一种**低精度数据类型** 转换为另一种 高精度数据类型
num_int = 123
num_flo = 1.23
num_new = num_int + num_flo
print("num_new 值为:",num_new) # 输出124.23
print("num_new 数据类型为:",type(num_new)) # num_new 数据类型<class 'float'>
2.2、显式类型转换
需要手动进行转换,将数据类型作为函数名包含需要类型转换的变量,然后函数将返回一个新的对象,表示转换的值
| 函数 | 描述 |
|---|---|
| int(x ,base] | 将x转换为一个整数 |
| float(x) | 将x转换到一个浮点数 |
| str(x) | 将对象 x 转换为字符串 |
| tuple(s) | 将序列 s 转换为一个元组(不可变数据) |
| list(s) | 将序列 s 转换为一个列表(可变数据) |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典,d 必须是一个 (key, value)元组序列 |
- int(): 将其他对象转换为整型
1. 布尔值: True -> 1 | False -> 0
2. 浮点数: 取整,省略小数点后面的内容
3. 字符串: 合法整数字符串,直接转换为对应数字。不合法的整数字符串,则报错。如: a= int("11.6")
4. 对于其他不能转换为整型的对象,则直接抛出异常。如: a = int(None)
- float(): 将其他对象转换为浮点型
1. 布尔值: True -> 1.0 | False -> 0.0
2. 字符串: 合法小数字符串,直接转换为对应数字。不合法的小数字符串,则报错。a = float('abc')
3. 对于其他不能转换为浮点型型的对象,则直接抛出异常。如: a = float(None)
- str(): 将其他对象转换为字符串
- bool(): 将其他对象转换为布尔值
1. 对所有表现空性的对象,都会转换为 False。其他的转换为 True
2. 空性: 0(0.0, 0f), None, '', "", [], {}, {}(集合)
3、运算符
3.1、算术运算符
对浮点数进行数值运算,结果也是浮点数
假设变量 a=10,变量 b=21
| 运算符 | 描述 |
|---|---|
| + | 加 - 两个对象相加 |
| - | 减 - 得到负数或是一个数减去另一个数 |
| * | 乘 - 两个数相乘 |
| / | 除 - x 除以 y |
| % | 取模 - 返回除法的余数 |
| ** | 幂 - 返回x的y次幂(x^y)(注: 除开(), 通常其优先级最高) |
| // | 取整除 - 往小的方向取整数 |
a = 10 + 5 # 两个字符串相加,是将两个字符串进行拼接
a = 10 - 5
a = 10 * 5 # 字符串和数字相乘,是对字符串做复制操作,将字符串重复指定次数
a = 10 / 5 # 取商,除法运算的结果总是浮点数
a = 10 % 5 # 取余/模,返回除法的余数
a = 10 // 3 # 向下取整数 9//2=4 -9//2=-5
a = 10 ** 2 # 幂运算,几次方
a = 16 ** 0.5 # 16的平方根
3.2、比较(关系)运算符
- 关系成立返回True, 否则返回False
- 当两个字符串进行比较时,是“逐位比较”字符串的unicode编码
| 运算符 | 描述 |
|---|---|
| == | 等于 - 比较对象是否相等 |
| != | 不等于 - 比较两个对象是否不相等 |
| > | 大于 - 返回x是否大于y |
| < | 小于 - 返回x是否小于y。所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意,这些变量名的大写。 |
| >= | 大于等于 - 返回x是否大于等于y。 |
| <= | 小于等于 - 返回x是否小于等于y。 |
3.3、赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
| := | 海象运算符,这个运算符的主要目的是在表达式中同时进行赋值和返回赋值的值。 | Python3.8 版本新增运算符。 |
3.4、逻辑运算符
又称短路运算符,优先级:not(逻辑非) > and(逻辑与) > or(逻辑或)
* not: 若not右边是布尔值,则加not直接进行取反。若右边是非布尔值,则会先将其转换为布尔值再取反
* and: 符号两侧的值都为True时,返回True; 只要有一个False,则返回False
- and是短路与运算符,找False
- 当第一个值为False,则返回第一个值,否则返回第二个值
* or: 符号两侧的值都为False时,返回False; 只要有一个True,则返回True
- or是短路或运算符,找True
- 当第一个值为True,则返回第一个值,否则返回第二个值
* and/or/not 在处理非布尔值时,python会将其当成布尔值进行运算,最终再返回原值
# 处理非布尔值,则转换成布尔值
a = 1 # 转换成True
a= not a # False
b = "" # 转换成False
b = not b # True
passwd = "" # False
if not passwd: # 如果是not False==》True
print("bbbbb")
# 逻辑与: 找False
True and print("猜猜我会进来吗?") # 会打印print语句
False and print("猜猜我会进来吗?") # 不会打印
result = 1 and 2 # True and True 返回第二个数2,没找到False,返回第二个数
result = 1 and 0 # True and False 返回False的 0
result = 0 and 2 # False and True 返回False的 0
result = "" and 2 # False and True 返回False的 ""
result = 0 and None # False and False 返回第一个False的 0
# 逻辑或: 找True
True or print("猜猜我会进来吗?") # 不会打印print语句
False or print("猜猜我会进来吗?") # 会打印
result = 1 or 2 # True and True 返回第一个数 1
result = 1 and 0 # True and False 返回True的 1
result = 0 and 2 # False and True 返回True的 2
result = 0 and None # False and False 返回第二个False的 None,因为没有找到True,只能返回第二个数
3.5、位运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与:参与运算的两个值,对应位都为1时,结果位才为1,否则为0 | a & b 结果为对应位相与后的十进制数 |
| | | 按位或:参与运算的两个值,对应位只要有一个为1,结果位就为1 | a | b 结果为对应位相或后的十进制数 |
| ^ | 按位异或:参与运算的两个值,对应位不同时,结果位为1;相同时为0 | a ^ b 结果为对应位相异或后的十进制数 |
| ~ | 按位取反:对每个二进制位取反,0变1、1变0,即 ~x = -x - 1 | ~a 结果为按位取反后的十进制数 |
| << | 左移:把一个数的二进制位全部左移n位,高位丢弃,低位补0,等价于乘以 2^n | a << 2 表示将a的二进制左移2位 |
| >> | 右移:把一个数的二进制位全部右移n位,低位丢弃,高位补符号位(正数补0,负数补1),等价于除以 2^n 向下取整 | a >> 2 表示将a的二进制右移2位 |
3.6、三目(条件)运算符
# 语法:
语句1 if 条件表达式 else 语句2
- 先判断条件表达式真假,真则取语句1的值,否则取语句2的值
- 三目运算符是可以嵌套, 但需要注意if和else的配对使用
food_for_pet = {
"dog", "beef",
"cat", "chicken"
}
food = food_for_pet[pet] if pet in food_for_pet else None
a if a > b else c if c > d else d # 不建议
a if a > b else ( c if c>d else d ) # 不建议
a if (a > b and a > c) else ( d if d > e else f ) # 不建议
3.7、成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False | x in y,若x在序列y中返回True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False | x not in y,若x不在序列y中返回True |
3.8、身份运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | 判断两个标识符是否引用同一个对象(内存地址相同),是则返回 True,否则返回 False | x is y,若x和y引用同一对象则返回True |
| is not | 判断两个标识符是否引用不同对象(内存地址不同),不是则返回 True,否则返回 False | x is not y,若x和y引用不同对象则返回True |
4、变量存储
变量名是贴在内存对象上的标签/引用,不是装数据的盒子。
变量中存储的不是对象的值,而是对象的id(内存地址),对象本身没有直接存储到变量中:
- 当使用变量时,实际上就是通过对象id查找对象
- 变量中保存的对象,只有在为变量重新赋值时才会改变
- 变量和变量之间相互独立的,修改一个变量不会影响另一个变量
# 对象两类:
* 不可变对象(int/str/tuple):
- 引用时,值不可修改,修改相当于新建对象,会换成新的内存地址
- 新建时,都会新建一个独立对象,值不可修改,内存地址不一样
- 元组不可变是约束引用,内部可变对象仍可修改
* 可变对象(list/dict):
- 引用时,值可修改,地址不变
- 新建时,都会新建一个独立对象,值可修改,内存地址不一样

# 不可变对象
a=1
b=1
print(id(a), id(b), a is b, a==b) # id(a) = id(b),True,,rue
内存区域:
[整数对象1] ←内存中只有1个地址: 0x1001
↑ ↑
a b (两个标签贴在同一个对象上)
# 原理
* 小整数(-5~256)Python会缓存复用,不会创建新对象
a = 100
b = a # 同一个对象,引用计数+1
a = 200 # 新建int对象,a指向新对象
内存区域:
[整数对象100] ← 内存地址:0x1003
↑ ↑
a b (两个标签贴在同一个对象上)
a新指向对象后:
[整数对象100 ] ← 内存地址:0x1003
↑
b
[整数对象200] ← 新内存地址:0x1004
↑
a
# 可变对象
a=[1,2]
b=[1,2] # 新建对象,两个内存地址不一样
print(id(a), id(b), a is b, a==b) # id(a) ≠ id(b) ,False,True
内存区域:
[列表对象1: [1,2]] ← 地址:0x2001
↑
a
[列表对象2: [1,2]] ← 地址:0x2002
↑
b
x = [1, 2, 3] # 创建列表对象,贴标签 x
y = x # 给同一个对象再贴一个标签y,refcount会加1
y.append(4) # 通过任意标签修改对象,所有标签都会变化
内存区域:
[列表对象1: [1, 2, 3] ← 地址:0x2003
↑ ↑
x y(两个标签贴在同一个对象上)
# 元组(不可变)+ 内部列表(可变)
a=(1, 2, [3, 4])
b=(1, 2, [3, 4])
print(id(a), id(b), a is b, a==b) # 整体值相等,地址不同
内存区域:
元组a (0x3001):[1, 2, 列表x: [3,4] (0x3002)]
↑
a
元组b (0x3003):[1, 2, 列表y: [3,4] (0x3004)]
↑
b
# 说明
* 元组本身是不可变对象,但这里是字面量创建,会生成两个独立元组
* 两个元组内部的列表也是两个独立对象
# 修改元组内部的列表
a=(1, 2, [3, 4])
b=(1, 2, [3, 4])
a[-1].append(5) # (1, 2, [3, 4, 5])
print(id(a), id(b), a is b, a==b) # id(a) 不变,id(a)≠id(b) → False,False
修改后内存区域:
元组a (0x3001):[1, 2, 列表x: [3,4,5] (0x3002)]
↑
a (修改后元组地址不会变,子对象列表地址也不会变,但子对象值可修改)
元组b (0x3003):[1, 2, 列表y: [3,4] (0x3004)]
↑
b
# 说明
* 元组不可变是子对象引用不可变,不是子对象本身不可变
* 元组里存的是列表的地址,这个地址不能改
* 但列表本身是可变的,里面的值可以随便改
5、流程控制语句
5.1、if 语句
if 条件表达式:
代码块
或
if 条件表达式1:
代码块
elif 条件表达式2:
代码块
...
else:
代码块
* 如果条件表达式为True,则执行当前代码块,然后语句结束
* 如果条件表达式为False,则继续向下执行,直到找到True的表达式,然后执行代码块,最后退出
* 如果所有的表达式都是False,则执行else中的代码块
if 条件语句
==, !=, >, >=, <, <=
同时检查多个条件: and, or, not
and: 表示多个条件都满足,则为True。若其中一个不满足,则为False
or: 表示至少有一个条件满足,则为True。两个都不满足,则为False
not: 表示取反。比如: if not a>4: 则a<=4是下面代码才执行
判断是否在列表里:in, not in
# 一、判断是否相等
if name1 == "john"
# 二、判断是否不相等
if name2 != "tom"
# 三、判断多个条件 and
# and 前后两个条件都满足才是True,只满足其中一个或者两个都不满足都是False
if age1 < 20 < age2
# 四、判断多个条件 or
# or 前后两个条件只有一个满足时为True,两个都不满足时为 False
if age1 >= 20 or age2 <= 18
# 五、判断特定值是否在列表里 in
users = ["John", "Tom", "Jerry", "Kate"]
name1 = "Tom"
if name1 in users
# 六、判断特定值不在列表里 not in
name2 = "Zkc"
if name2 not in users
# 七、判断列表非空
if item
5.2、for循环
for variable in iterable:
# 对iterable中的每一个元素执行的代码块
# 在每次循环中,variable会被赋值为当前元素
# 循环停止的两个场景:
1、当元素被找到,break被触发
2、循环结束
# 导致循环完成的原因
1、先设置⼀个标记,然后在循环结束时打上标记
2、使⽤else从句
# for-else 结构
在for循环中,当循环正常完成所有迭代,else语句才会被执行。如果循环被break打断,则else子句不会被执行
# for-else 语法:
for i in 条件表达式:
代码块1
else:
代码块2
# for-else 举例:
for num in range(10):
if num / 11 == 1:
print(num)
break
else:
print("没有能整除11的数")
5.3、while循环
while condition:
# 当 condition 为 True 时,重复执行这里的代码
statement_1
# 关键:
# 循环体内通常要有代码来改变condition的状态,否则可能导致无限循环。
# while-else 结构:
与for-else类似,while循环的else块会在循环条件变为False而正常结束时执行。如果循环被break打断,else块则不会执行
# while-else 语法:
while 条件表达式:
代码块
else:
代码块
* 如果条件表达式为True,则执行循环体代码块,直到条件表达式为False,则结束循环
* 当循环正常完成所有迭代,则else语句才会执行。若循环被break打断,则else子句不会执行
* 三要素: 初始化变量、条件表达式、更新表达式
# for vs while 如何抉择?
1. 当遍历一个已知的序列或需要循环固定的次数时,使用for循环
2. 当在某条件为真的情况下才执行代码,但不确定循环次数时,使用while循环
5.4、break 与 continue
1. break
break会立即终止当前所在的最内层循环,程序的执行将跳转到循环结构之后的下一条语句。
2. continue
continue语句会跳过当前这次循环中continue之后的剩余代码,直接进入下一次循环的迭代。
# break与continue的区别
* break: 结束整个循环
* continue: 结束本次循环,进入下一次循环
3. pass
pass是一个占位语句。当语法上需要一个语句,但逻辑上不想做任何事情时,就使用pass。它不会执行任何操作。
常用于: 定义一个空的函数或类,作为未来实现的框架。在if或except等需要代码块的地方,临时占位。
5.5、循环嵌套
- 外层循环控制图形高度
- 内层循环控制图形长度
- 外层循环每执行一次,内层循环执行一圈
"""
每行执行完换行,print默认有换行符,不然就30个*号连成一行,每执行一轮内层循环就用print换行
* * * * * *
* * * * * *
* * * * * *
* * * * * *
* * * * * *
"""
def prac_15():
for i in range(5):
for j in range(6):
print('*', end=" ")
print()
def prac_15_1():
i = 0
while i < 5:
j = 0
while j < 6:
print("*", end=" ")
j += 1
i += 1
print()
# 九九乘法表
def prac_16_1():
for i in range(1, 10):
for j in range(1, 10):
if i >= j:
print(f"{j} x {i} = %2d" % (i*j), end=" ")
print()
def prac_16_2():
i = 1
while i < 10:
j = 1
while j < 10:
if j <= i:
print(f"{j} * {i} =", j * i, end="\t")
j += 1
i += 1
print()
def prac_16_3():
for i in range(1, 10):
for j in range(1, i + 1):
print("{i} * {j} = {m}".format(i=i, j=j, m=i * j), end=' ')
print()
def prac_16_4():
# 逆序打印
for i in range(1, 10):
for j in range(i, 10):
print("{i} * {j} = {m}".format(i=i, j=j, m=i * j), end=' ')
print()
"""
*
* *
* * *
* * * *
* * * * *
"""
def func1():
i = 0
while i < 5:
j = 0
while j < i+1:
print('*', end=" ")
j += 1
i += 1
print()
"""
*
* *
* * *
* * * *
* * * * *
"""
def func2():
for i in range(5):
for j in range(i + 1):
print('*', end=" ")
print()
"""
* * * * *
* * * *
* * *
* *
*
"""
def func3():
i = 0
while i < 5:
j = 0
while j < 5-i:
print('*', end=' ')
j += 1
i += 1
print()
def func4():
for i in range(5):
for j in range(5 - i):
print('*', end=" ")
print()
"""
* * * * *
* * * *
* * *
* *
*
0 0 1 2 3 4
1 0 1 2 3 4
2 0 1 2 3 4
3 0 1 2 3 4
4 0 1 2 3 4
"""
def func5():
i = 0
while i < 5:
j = 0
while j < 5:
if j >= i: # j < i
print('*', end=" ")
else:
print(' ', end=" ")
j += 1
i += 1
print()
def func5_1(row):
i = 0
while i < row:
j = 0
while j < row:
if i > j:
print(" ", end=" ")
else:
print("*", end=" ")
j += 1
i += 1
print()
"""
*
* *
* * *
* * * *
* * * * *
0 0<5-0-1=4 1<5-0-1 2<5-0-1 3<5-0-1 4<5-0-1
1 0<5-1-1=3 1<5-1-1 2<5-1-1 3<5-1-1 4<5-1-1
2 0<5-2-1=2 1<5-2-1 2<5-2-1 3<5-2-1 4<5-2-1
3 0<5-3-1=1 1<5-3-1 2<5-3-1 3<5-3-1 4<5-3-1
4 0<5-4-1=0 1<5-4-1 2<5-4-1 3<5-4-1 4<5-4-1
"""
def func6():
i = 0
while i < 5:
j = 0
while j < 5:
if j < 5-i-1:
print(' ', end=" ")
else:
print('*', end=" ")
j += 1
i += 1
print()
6、列表 (List, list):可变序列
列表是一个有序且可变的容器,可以存放任意类型的元素。
- 有序:列表中元素的排列顺序是固定的,存入时的顺序就是它保持的顺序
- 可变:在列表创建后,可随时添加、删除或修改其中的元素。
- 任意类型:一个列表中可以同时包含整数、浮点数、字符串或者其他列表
# 所有序列的通用操作,跟索引有关,适用于所有序列
max(), min(), len(), sort(), count(), index(), my_list[i]
'XX' in my_list, 'XX' not in my_list
# 添加元素
* append(x): 在列表末尾添加一个元素x
* extend(iterable): 将一个可迭代对象(如另一个列表)中的所有元素追加到列表末尾
* insert(i, x): 在索引i处插入一个元素x,可将元素加入到列表中的指定位置
# 索引
* index(data): 返回data第一次在列表中出现的索引
# 删除元素
* remove(value): 根据元素删除,如果元素不在列表中,将报错
* del: 删除一个元素值,可通过索引值获得需要删除的元素
- del 列表名[索引值]: 删除索引对应的值
- del 列表名: 删除列表
- del 关键字将变量从内存中删除,后续的代码就不能再使用这个变量
* pop(): 返回列表中最后一个元素并从列表中删除
* pop(i): 返回列表中指定的元素并从列表中删除
* clear(): 清空列表中的所有元素
# 排序与反转
* sort(): 将列表进行排序,会修改原列表
* reverse(): 将列表中的元素进行反转
* sorted(list): 内置函数,返回一个新的排好序的列表,不修改原列表
# 列表分片
* 形式: 列表名[左索引值:右索引值:步长] "左闭右开原则"
* 当需要从列表一次性取出多个元素时,通过列表分片的方式来实现
* 左右索引值及步长都可以忽略,左索引值忽略时表明列表元素从0开始,右索引值省略表示包括做索引值右边的所有元素,步长省略默认为1
1. 尽量使用stride为正数,且不带start或end索引的切割操作。尽量避免用负数做stride
2. 在同一个切片操作内,不要同时使用start、end和stride。如果确实需要执行这种操作,那就考虑将其拆解为两条赋值语句,其中一条做范围切割,另一条做步进切割,或考虑使用内置itertools模块中的islice。
# 列表拷贝的三种方式:
1. 通过将已知列表赋值给另一个变量
2. 通过列表分片进行拷贝
3. 通过列表内置方法copy()赋值
# 1、创建列表
my_list = list()
my_list = []
name_list = ['Bob', 'Jack', 'Lisa', 'Jerry']
add_list = ['zhangsan', 'lisi']
# 2. 列表的 + 和 *
fruits_1 = add_list + ['pick'] # 列表相加,生成新列表
fruits_2 = ['zkc'] * 3
# 3、查询列表元素
print(name_list[0])
print(name_list[-1])
# 4、添加元素
name_list.append('Tom') # 一次性向列表末尾添加
name_list.insert(2, 'Rose') # 向指定位置添加
name_list.extend(add_list) # 将可迭代对象中元素依次添加进列表
# 5、修改
name_list[2] = 'Herry'
# 6、删除元素
del name_list[1]
del name_list[:2] # 可以根据切片删除
name = name_list.pop() # 默认弹出列表末尾元素,删除的元素还可以访问
name = name_list.pop(2) # 默认弹出指定位置元素,删除的元素还可以访问
name_list.remove('Jack') # 根据元素删除
# 7、切片--遵循 左闭右开 原则 [开始索引,结束索引,步长(默认为1)]
# 逆序列表的步长用: 负数
my_list_1 = name_list[:3] # ['Bob', 'Jack', 'Lisa']
my_list_2 = name_list[2:] # ['Jack', 'Lisa', 'Jerry']
my_list_3 = name_list[::-1] # ['Jerry', 'Lisa', 'Jack','Bob'] 负步长==列表倒序
my_list_4 = name_list[::2] # 步长为2 ['Bob', 'Lisa']
my_list_5 = name_list[1::2] # 步长为2 ['Jack', 'Jerry']
my_list_6 = name_list[::] # 全列表的分片,相当于创建了一个原列表的副本,全列表复制
7、元组 (Tuple, tuple):不可变的序列
元组是不可变序列, 也叫不可变列表,一旦初始化就不能修改,只能通过引用给元组重新赋值。
元组和列表的区别:
元组与列表非常相似,除了元组是不可变序列,不能赋值和添加,列表是可变序列,其他所有的操作都和列表一样。
要创建一个只包含一个元素的元组,必须在该元素后面加上一个"**,**",否则Python会将其解释为普通的值
# 1、创建元组
my_tuple = ()
my_tuple1 = tuple()
my_tuple2 = ('name1', 'name2', 'name3')
my_tuple3 = 'name1', 'name2', 'name3' # 当确定元组中有数据时,也可以省略()
my_tuple4 = ('name1', ) # 元组中至少要有一个","
my_tuple5 = 'name1', # 元组中至少要有一个 ","
t = ('骆昊', 38, True, '四川成都')
# 2、访问
print("索引访问: ", t[0])
for item in t:
print("遍历访问: ", item)
# 3、更新
t[0] = 'zkc' # 元素不可更新
# 重新赋值
t = ('zkc', 30, False, 'NJ')
# 元组本身不允许修改和删除,可以对元组的元素进行操作并生成一个新的元组
# 分片 + 拼接生成新的元组
t = (1, 2, 3, 4, 5)
t = t[:3] + (10,) + t[3:] # (1, 2, 3, 10, 4, 5)
# 4、元组不可修改,但其中的可变序列,可以修改
a=(1, 2, [3, 4])
a[-1].append(5) # (1, 2, [3, 4, 5])
# 5、删除
可以通过del语句直接删除一个元组,但不允许del删除元组的某个元素
del my_tuple4
# 分片 + 拼接实现元素删除
t = (1, 2, 3, 4, 5)
t = t[:3] + t[4:] # (1, 2, 3, 5)
# 6、元组转列表
list_tt = list(t)
# 7、列表转元组
fruits_list = ['apple', 'banana', 'orange', 'grape']
fruits_tuple = tuple(fruits_list)
8、打包和解包(解构)
- 解包(Tuple Unpacking): 将序列中的每一个元素都赋值给一个变量
- 在解包时,**
变量数量必须和序列中的元素数量**保持一致 - 在变量前添加
“*”,表示该变量会获取序列中剩余的所有元素,不能同时出现两个“*” - 不需要的单个元素用
“_”替代
- 在解包时,**
- 打包(Tuple Packing): 创建元组时省略括号
# 一、元组的解包(解构)
my_tuple = 10, 20, 30, 40 # 打包
a, b, c, d = my_tuple # 解包 将元组中的元素都赋值给一个变量
# 不需要的元素用 "*变量名" 统一接收
a, b, *c = my_tuple
print(a, b, c) # 10 20 [30, 40]
a, *b, c = my_tuple
print(a, b, c) # 10 [20, 30] 40
*a, b, c = my_tuple
print(a, b, c) # [10, 20] 30 40
# 不需要的单个元素用 "-" 替代
a = (1, 2, 3)
x, y, _ = a
m, _, n = a
print(x, y) # 1 2
print(m, n) # 1 3
# 使用解包,交换两个数位置
# 等号右边是不带()的元组,对这个元组进行解包。将元组里每个元素,都分别赋值给一个变量
a = 300
b = 100
a, b = b, a # 通过解包,将a的值换成300,b的值换成100
# 二、列表的解包
my_list = [1, 2, 3, 4, 5]
a, b, c, d, e = my_list # 1 2 3 4 5
a, b, *c = my_list # 1 2 [3, 4, 5]
# 三、字符串的解包
my_str = "hello world"
m, n, t* = my_str # h e ['l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd']
# 四、集合解包
a = (1, 3, 2, 4)
x, y ,z, w = a
# 五、for循环解包
b = [(1, 2), (3, 4), (5, 6), (7, 8), (9, 10)]
for index, item in b:
print(index, item)
9、字典 (Dictionary, dict)
字典是存储键-值对(key-value)的集合。它建立了一种映射关系,通过一个唯一的键,可以快速地查找到与之对应的值。
- 键-值映射:每个元素都由
键-值对组成。 - 无序性:字典是
无序的,通过键来访问元素 - 键的唯一性与不可变性:
- 在字典中,
键必须是唯一的。如果存入一个已存在的键,新的值会覆盖旧的值。 键必须是不可变类型,如字符串、数字、元组。列表、集合或其它字典不能作为键,因为它们是可变的。
- 在字典中,
- 值的任意性:
值可以是任何数据类型,包括数字、字符串、列表、字典。
# 访问元素
* 通过方括号[]和键来访问对应的值。如果键不存在,会引发KeyError
* get(key, 默认值): 如果键不存在,返回None(或指定的默认值),而不会报错
# 添加或修改元素
* 通过dict[key] = value的语法。如果键已存在,则修改其值;如果键不存在,则添加新的键-值对
* update(new_dict): 更新字典,key存在时更新,不存在时添加key-value
* dict.fromkeys(iterable, value): 创建所有value相同的字典,第一个参数是可迭代对象, 第二个参数是value
* setdefault(key, value): 添加k-v,如果key存在,则返回value,如果key不存在,则新增k-v,并返回value
# 1.创建字典
empty_dict = {}
empty_dict = dict()
cdict1 = dict(name="Bob", age=25, city="London")
cdict2 = dict([('name', 'Charlie'), ('age', 42)])
cdict3 = dict((['a',2],['b',3]))
cdict4 = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
cdict5 = {x: x**2 for x in (2, 4, 6)}
error_codes = {404: "Not Found",200: "OK"} # 键是数字,值是字符串
student_courses = {
"John": ["Math", "Art"],
"Mary": ["History", "Math"]
}# 值是列表
my_dict = {"name": "zkc", "city": "New York"}
new_dict = {"id": "1", "name": "Jack"}
# 2、访问字典
my_name = my_dict['name']
my_name = my_dict.get('name', '')
# 3、添加或修改元素
my_dict['name'] = "zkk"
# 新增item
my_dict.update(new_dict)
my_list = ["name", "username"]
my_dict1 = dict.fromkeys(my_list, "Mary")
name = my_dict.setdefault("new_name", "umesh")
# 4、删除字典
del my_dict["name"] #根据key永久删除指定的键-值对,如果键不存在,会报错
value = my_dict.pop('name', '') # 删除该字典指定的key,并且返回value值. 若key不存在,返回默认值
key, value = my_dict.popitem() # 删除该字典末尾的键值对,并返回key, value组成的元组
# 5、清除字典
my_dict.clear()
# 6、遍历字典
1. keys()和values()都会返回一个列表
2. keys()可省略,遍历字典中所有key
3. items()返回字典的(key,value)列表
items()把字典中的键值对转化成一个列表
其中每个元素是一个tuple,tuple的第一个元素是键,第二个元素是值
for key, value in my_dict.iteams()
for key in my_dict.keys()
for value in my_dict.values()
for key in person: # 省略keys
print(key, person[key])
# 7、返回特定顺序的字典
"""
# 字典返回特定顺序
1. 先进行排序,看要求是根据key排序还是根据value排序
2. 排序时可以用lambda表达式,使用x[0], x[1]来取key 和 value 的值
"""
dict_test2 = {"zkc": "python", "Connor": "Java", "Lisa": "C++", "John": "python",
}
test3 = {}
# 根据 key 排序, 在循环items()时, 要先将key进行排序
for k,v in sorted(dict_test2.items(), key=lambda x: x[0]):
test3[k] = v # 将原字典中的k进行排序后重新写入字典
print("根据 key 排序: ", test3)
# 根据 value 排序, 在循环items()时,要先将values排序
test4 = {}
for key, value in sorted(dict_test2.items(), key=lambda x:x[1]):
test4[key] = value
print("根据 value 排序: ", test4)
# 8、去除重复数据
"""
# set集合无序,不重复
# 比如dict_test3的value中有重复值,我们将重复值进行过滤再循环
"""
for value in set(dict_test2.values()):
print("去重复后的value值:", value)
10、集合 (Set, set)
集合中只能存储不可变对象,并且元素是无序的、元素唯一不可重复的。
- 无序性:
集合中的元素没有固定的顺序。存入元素时不会记录它们的排列位置。因此,集合不支持索引和切片操作。 - 唯一性:
集合中不允许有重复的元素。如果向集合中添加一个已经存在的元素,集合不会发生任何变化。
# 添加元素
* add(elem): 添加一个元素到集合中
* update(iterable): 将一个可迭代对象中的所有元素添加到集合中
# 删除元素
* remove(elem): 从集合中删除元素elem。如果elem不存在,会引发KeyError
* discard(elem): 从集合中删除元素elem。如果elem不存在,不会报错
* pop(): 随机删除并返回集合中的一个元素。如果集合为空,会报错
* clear(): 清空集合
# 集合的关系运算
* 并集: 返回一个新集合,包含两个集合中的所有元素
- 操作符: |
- 方 法: a.union(b)
* 交集: 返回一个新集合,包含两个集合中共同拥有的元素
- 操作符: &
- 方 法: a.intersection(b)
* 差集: 返回一个新集合,包含在第一个集合中,但不在第二个集合中的元素
- 操作符: -
- 方 法: a.difference(b)
* 对称差集: 返回一个新集合,包含所有只在其中一个集合中出现的元素(即并集减去交集)
- 操作符: ^
- 方 法: a.symmetric_difference(b)
# 1、创建集合
使用{}或者set()函数来创建集合,但创建一个空集合时,必须使用set()函数,因为{}被用来创建空字典
my_set = set() # 空集合。不能使用{}
my_set = {"name", "hobby", "class"}
# 2、访问
for elm in my_set:
print(elm ** 2, end=' ')
# 3、添加元素
my_set.add('gender')
# 4、更新元素
# 将一个序列中的元素添加到当前集合中
# 参数可以为:序列、字典。字典值使用键值
new_set = set(range(10))
my_set.update(new_set)
new_list = list(range(5))
my_set.update(new_list)
new_tuple = ('Jack', 'Mary', 'Bob')
my_set.update(new_tuple)
new_dict = {1001: 'aa', 1002: 'bb', 1003: 'cc'}
my_set.update(new_dict) # 传递参数为字典时,只添加 key 值到集合中
# 5、删除元素
my_set.remove('name') # 删除指定元素
value = my_set.pop() # 随机删除并返回集合中的一个元素
del my_set # 从内存中删除集合
# 5、清空集合
my_set.clear()
# 6、列表转集合
my_list = list(range(5))
my_set1 = set(my_list)
# 7、字典转集合
my_dict = {'a': 1, 'b': 2, 'c': 3}
my_set2 = set(my_dict)
# 8、元组转集合
my_tuple = (1, 2, 3, 4, 4,)
my_set3 = set(my_tuple)
# 9、生成数值集合
set_44 = set(range(1, 11))
print(set_44)
# 10、集合的运算
aa = {1, 2, 3, 4}
bb = {3, 4, 5, 6}
cc = {1, 1, 2, 2, 2, 3, 3, 3, 3}
# 去重
print("去重后效果: ", cc)
# 交集 &
print("交集:", aa & bb) # {3, 4}
print("交集:", aa.intersection(bb))
# 并集 |
print("并集: ", aa | bb) # {1, 2, 3, 4, 5, 6}
print("并集: ", aa.union(bb))
# 差集 -
print("属于aa但不属于bb的: ", aa - bb) # {1, 2}
print("属于bb但不属于aa的: ", bb - aa) # {5, 6}
print("属于aa但不属于bb的: ", aa.difference(bb))
# 异或集 ^ 获取两个集合中不是公共的部分
print("异或集: ", aa ^ bb) # {1, 2, 5, 6}
print("异或集: ", aa.symmetric_difference(bb))
# 子集 <= 检查一个集合是否是另一个集合的子集
# 如果集合a的元素全部都在集合b中出现,那么集合a是集合b的子集
a = {1, 2, 3}
b = {1, 2, 3, 4, 5}
c = {1, 2, 3}
result = a <= b # True
result = a <= c # True
result = b <= a # False
# 真子集 < 检查一个集合是否是另一个集合的子集
# 集合b中含有集合a的所有元素,并且集合b中含有集合a中没有的元素,则集合a是集合b的真子集
result = a < b # True
result = a < c # False
11、推导式
11.1、列表生成式/推导式
1. 基础型
[表达式 for 变量 in 列表]
[x**2 for x in range(10)]
2. 筛选型
[表达式 for 变量 in 列表 if 条件]
[x for x in range(30) if x % 5 == 0]
3. 筛选型
[表达式 for 变量 in 列表 if 条件...if 条件...]
[(x,y) for x in range(10) for y in range(10) if x % 2 == 0 if y % 2 != 0]
4. 条件型
[结果值1 if 判断条件 else 结果值2 for 变量名 in 原列表 ]
"""
1、if 在for后面,则没有else
2、if 在for前面,则必须要加else
"""
list_d = [x for x in range(10) if x % 2 == 0]
list_e = [x if x % 2 == 0 else -x for x in range(10)]
print("列表生成式list_d", list_d) # [0, 2, 4, 6, 8]
print("列表生成式list_e", list_e) # [0, -1, 2, -3, 4, -5, 6, -7, 8, -9]
list1 = ['python', 'go', 'java']
list2 = [ word.title() if word.startswith('p') else word.upper() for word in list1 ]
def list_comprehension():
# 1.求 0 ~ 10 的平方
list_demo = [x ** 2 for x in range(10)]
print(list_demo)
# 2.计算 30 以内可以被 5 整除的整数
list_demo1 = [x for x in range(30) if x % 5 == 0]
print(list_demo1)
# 3.x能整除2的,而y不能整除2进行显示
list_demo2 = [(x, y) for x in range(10) for y in range(10) if x % 2 == 0 if y % 2 != 0]
print(list_demo2)
# ===>等价于
list2 = []
for x in range(10):
for y in range(10):
if x % 2 == 0:
if y % 2 != 0:
list2.append((x, y))
print(list2)
# 4.利用下标对列表元素进行对应输出
slogan = ['1.Jost do it', '2.一切皆有了能', '3.让编程改变世界']
brand = ['2.李宁', '3.全栈工程师', '1.Nick']
new_list = [name + ":" + value[2:] for value in slogan for name in brand if name[0] == value[0]]
print(new_list)
# 5.针对结果值进行判断处理。
list1 = ['python', 'go', 'java']
list2 = [i.title() if i.startswith('p') else i.upper() for i in list1]
print(list2)
11.2、元组生成式/推导式
( 表达式 for 变量 in Sequence )
( 表达式 for 变量 in Sequence if 条件)
(x for x in range(1,10))
11.3、集合生成式/推导式
( 表达式 for 变量 in Sequence )
( 表达式 for 变量 in Sequence if 条件)
11.4、字典生成式/推导式
{ key_expr: value_expr for 变量 in collection }
# 或者
{ key_expr: value_expr for 变量 in collection if 条件 }
def dict_comprehension():
# 将列表中各字符串值为键,各字符串的长度为值,组成键值对
brand = ['Google', 'Tencent', 'Alibaba', 'Baidu']
new_brand = {key: len(key) for key in brand}
print(new_brand)
# 提供一个包含四个数字的元组,求得平方为值来创建字典:
tuple_demo = (1, 2, 4, 8)
new_tuple_demo = {key: key**2 for key in tuple_demo}
print(new_tuple_demo)
# 将现有字典的值进行一些变换来创建一个新的字典,如将所有值翻倍:
original_dict = {'a': 1, 'b': 2, 'c': 3}
new_original_dict = {key: value * 2 for key, value in original_dict.items()}
print(new_original_dict)
# 从一个字典中筛选出特定条件的键值对
original_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
new_original_dict = {key: value for key, value in original_dict.items() if value > 2}
print(new_original_dict)
12、字符串(String, str)
1. 创建字符串
* 字符串:
- 使用单引号(')、双引号 (") 或 三引号 (''' 或 """)来创建字符串
* 单引号和双引号: 功能完全相同,主要用于方便地在字符串中包含另一种引号
* 三引号: 用于创建跨越多行的字符串,其中的换行符会被保留
2. 字符串的"不变性"(Immutability)
字符串是不可变的。一旦一个字符串被创建,它内部的任何字符都不能被单独修改。任何对字符串的"修改"操作,实际上都是创建了一个新的字符串
3. 字符串操作
- 拼接("+"): 将两个字符串连接成一个新的字符串
- 重复("*"): 将一个字符串重复多次
- 获取长度: len()是一个内置函数,可以返回字符串中包含的字符数量
4. 索引和切片
字符串是一个有序的字符序列,我们可以通过"索引(Index)"来访问单个字符,或者通过切片(Slice)**来获取一个子字符串
- 索引: Python的索引从0开始
- 切片: [start:stop:step],它会返回一个新的字符串
5. 常用的字符串方法
# 大小写转换
* title(): 将每个单词的首字母变成大写
* upper(): 将每个单词的所有字母变成大写
* lower(): 将每个单词的所有字母变成小写
* s.capitalize(): 返回首字母大写,其余小写的新字符串
# 去除空白符
* strip(): 去除字符串两端的空格
* lstrip(): 去除字符串左边的空格
* rstrip(): 去除字符串右边的空格
# 查找与替换
* s.find(sub[, start[, end]]): 从左向右查找子字符串sub首次出现的位置,找不到则返回-1
* s.rfind(sub[, start[, end]]): 从右向左查找子字符串sub首次出现的位置,找不到则返回-1
* s.index(sub[, start[, end]]): 返回指定字符串的索引位置,若字符串不存在则抛出异常
* s.replace(old, new, num): 将指定字符串替代为目标字符串,返回新的字符串
- num: 将字符串中不超过num个的字符串进行替换,默认-1表示全部替换
* s.startswith(substr[,start[,end]]): 检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False
* s.endswith(substr[, start[, end]]): 检查字符串是否是以指定子字符串结尾,如果是则返回 True,否则返回 False
# 分割与连接
* s.split(sep): 以sep为分隔符,将字符串分割成一个列表。如果sep省略,默认以所有空白字符(空格、换行、制表符)为分隔符
* sep.join(iterable): 用sep字符串,将一个可迭代对象(如列表)中的所有字符串元素连接成一个新字符串
# 字符串判断
* isdigit(): 所有字符都是数字,为真返回 Ture,否则返回 False
* islower(): 所有字符都是小写,为真返回 Ture,否则返回 False
* isupper(): 所有字符都是大写,为真返回 Ture,否则返回 False
* istitle(): 所有单词都是首字母大写,为真返回 Ture,否则返回 False
* isspace(): 所有字符都是空白字符,为真返回 Ture,否则返回 False
* swapcase(): 对字符串的大小写字母进行转换,将大写转小写,小写转大写
6. 格式化字符串
- f-string格式化
- format格式化
7. 原始字符串
使用r前缀时,字符串中的反斜杠不会被视为转义符号,而是作为普通的字符输出
name = ['zkc', 'zKc', 'zkC']
for i in name:
print(i.title(), i.lower(), i.upper())
word = "\tmy\tname\tis\t"
user = "zkc"
print(word.strip()+user)
print(word.lstrip()+user)
old_str = "123"
new_str = "Zkc Java"
print("所有字符都是数字:", old_str.isdigit())
print("所有字符都是小写:", new_str.islower())
# 字符串拼接
1. 使用 "+" 拼接
str_name = "wang" + "shang" + "kun"
print("使用+拼接字符串", str_name)
2. 使用join拼接, 将列表里的内容使用指定的连接符进行连接
name_list = ["wang", "shang", "kun"]
print("使用join连接字符串", " ".join(["wang", "shang", "kun"]))
3. 使用format格式化
a = "zkk"
print("使用format格式化: {}".format(a))
4. 使用f-string格式化
b = "zkc"
print(f"使用f-string格式化: {b}")
5. 使用%s占位符
e = "error"
f = "warn"
g = "debug"
print("log level:%s %s %s" % (e, f, g))
6. 使用replace替换
c = "hello world"
d = c.replace("l","L", 3)
7. 索引
s = "Python"
s[0] # P
s[5] # n
# 索引也可以是负数,表示从末尾开始计数
s[-1] # 最后一个字符 n
8. 切片
s = "Learn Python"
s[0:5] # 索引0到4 Learn
s[6:12] # 索引6到11 Python
s[:5] # 开头到索引4 Learn
s[6:] # 索引6到末尾 Python
s[:] / s[::] # 复制整个字符串 Learn Python
s[::2] # 每隔一个字符取一个 Er yhn
s[::-1] # 步长为-1,实现字符串反转 nohtyP nraeL
13、is 和 ==
* is: 判断两个变量是否引用内存中同一个对象(内存地址相同)
- 若是,则返回True,否则返回False
- 等价于id(x) == id(y)
* is not: 判断两个变量是否引用内存中不同对象
- 若是,则返回结果True,否则返回False
- 等价于id(x) != id(y)
* ==: 调用__eq__()方法判断两个变量值/内容是否相等
- a==b 等效于 a.__eq__(b)
* id(): 用于获取对象内存地址
# 使用is场景:
1. 与None比较: if x is None
2. 检查单例对象: if flag is True
3. 判断两个变量是否指向同一个对象: if self is other
14、any()和all()函数
内置的迭代器判断函数,用于可迭代对象(列表、集合、元组、字典、字符串等)中的元素执行布尔运算,支持短路求值
14.1、all()函数
# 语法:
all(iterable)
# 用法:
用于判断可迭代对象中的所有元素是否都为True
# 判断逻辑:
1. 遍历可迭代对象,所有元素都是True,返回True
2. 若可迭代对象为空,则返回True
3. 遍历可迭代对象,"只要找到一个False值,立即返回False",不再继续遍历剩余元素
# 搭配生成器表达式-推荐写法,大数据量省内存,更高效
all(条件 for x in 列表)
if all(is_prime(n) for n in huge_range) # 推荐
if all([is_prime(n) for n in huge_range]) # 不推荐
all([1, 2, 3]) # True
all([1, 0, False]) # False
all([]) # True, 空集合被认为是“所有条件都满足”
# 生成器写法:
def expensive_check(x):
print(f"Checking {x}")
return x > 0
result = all(expensive_check(i) for i in [2, 1, 0, 5])
# 检查一个字典中所有必要的键是否存在且非空
config = {'host': 'localhost', 'port': 8080, 'timeout': None}
all_valid = all(v is not None and v != '' for v in config.values())
data = ["hello", "world", 123]
is_all_str = all(map(lambda x: isinstance(x, str), data)) # False
14.1、any()函数
# 语法:
any(iterable)
# 用法:
用于判断给定的可迭代对象是否至少有一个元素为True
# 判断逻辑:
1. 遍历可迭代对象,所有元素都是False,返回False
2. 如果可迭代对象为空,返回False
3. 遍历可迭代对象,"只要找到一个True值,立即返回True",不再继续遍历剩余的元素
# 搭配生成器表达式-推荐写法,大数据量省内存,更高效
any(条件 for x in 列表)
any([0, False, None]) # False
any([0, 1, False]) # True
any([]) # False
any([""]) # False,空字符串在布尔上下文中被视为False
# 检查密码是否包含特殊字符
password = "123456"
special_chars = ["@", "#", "$"]
print(any(char in password for char in special_chars)) # False
15、type()、isinstance()和issubclass()函数
- type(obj): 获取未知数据类型对象,不考虑继承关系
- isinstance(obj, classinfo): 检查对象是否是某个类或其子类的实例,考虑继承关系
- classinfo: 类、类型元组或递归类型
- issubclass(cls, classinfo): 检查类的继承关系
- cls和classinfo: 必须是类对象或类型元组
class Animal:
pass
class Dog(Animal):
pass
d = Dog()
print(type(d)) # <class '__main__.Dog'>
print(type(d) is Dog) # True
print(type(d) is Animal) # False,因为 type 不考虑继承
print(isinstance(d, Dog)) # True
print(isinstance(d, Animal)) # True(继承关系)
print(isinstance(d, object)) # True(所有类都继承自object)
# 检查多个类型
print(isinstance(3, (int, float, str))) # True
print(issubclass(Dog, Animal)) # True
print(issubclass(Dog, object)) # True
print(issubclass(Animal, Dog)) # False
# 元组形式
print(issubclass(Dog, (str, Animal))) # True
16、range()函数-惰性求值
当我们需要循环固定次数,或者需要一个数字序列时,使用range()函数进行数字循环。
惰性求值:
惰性求值是一种编程语言中的求值策略,它延迟表达式的计算直到真正需要其结果时才进行计算
range() 返回的是一个可迭代对象,不是真正的列表。仅在迭代时逐个产生数值,节省内存。
# 语法: 左闭右开原则
range(stop): 从0到stop-1的整数序列
range(start, stop): 从start到stop-1的整数序列
range(start, stop, step): 从start到stop-1,步长为step的整数序列
# 遍历索引
words = ["apple", "banana", "cherry"]
for i in range(len(words)):
print(i, words[i])
17、split()函数
将字符串按照指定的分隔符拆分成多个子字符串,并返回包含这些子字符串的列表
# 语法:
str.split(sep=None, maxsplit=-1): 默认以空白字符(空格、换行、制表符等)进行分割
# 参数:
- sep(分隔符): 指定用于分割字符串的字符或字符串。
- 默认None,若未指定,split自动识别任意空白字符(包括空格、\t、\n等)作为分隔符,且连续的空白字符会被视为一个分隔符
- 若指定具体字符,则按照该字符进行分割,连续的分隔符之间会产生空字符串
- sep参数不能为空字符串'',否则会抛出ValueError异常
- maxsplit(最大分割次数): 指定分割操作执行的最大次数
- 默认值为-1,表示不限制分割次数
- 若指定数值n,字符串将被分割成"n+1"个元素,剩余部分将作为一个整体保留在列表的最后一个元素中
* rsplit(): 从字符串的右侧开始分割
* splitlines(): 分割多行字符串
# 1、使用默认分隔符
text = "Hello World\tPython"
result = text.split() # 输出:['Hello', 'World', 'Python']
# 2、指定分隔符
csv_data = "apple,banana,orange"
result = csv_data.split(",")
# 3、使用多个字符作为分隔符(结合正则使用)
text = "one--two---three----four"
parts = re.split('--+', text)
print(parts) # ['one', 'two', 'three', 'four']
# 4、限制分割次数
log = "INFO:2023-05-01:System started"
result = log.split(":", 2) # ['INFO', '2023-05-01', 'System started']
text = "one two three four five"
parts = text.split(' ', 2) # ['one', 'two', 'three four five']
# 5、分割空字符串
# 分割空字符串,不指定分隔符
print("".split()) # []
# 分割空字符串,指定分隔符
print("".split(','))
# 分割只有一个字符的字符串
print("a".split(','))
# 6、处理连续的分隔符
text = "one,,two,three,,four"
parts = text.split(',')
# 如果需要忽略连续的分隔符,可以使用正则表达式:
text = "one,,two,three,,four"
parts = re.split(r',+', text)
- 空字符串处理:
当指定了sep且分隔符出现在字符串"开头、结尾或连续出现"时,结果列表中会包含空字符串’';而默认模式下连续空白不会产生空字符串
# 默认分隔符忽略连续空白
" a b ".split() # ['a', 'b']
# 指定分隔符产生空字符串
text = ",apple,banana,,cherry,"
parts = text.split(',')
print(parts) # ['','apple','banana','','cherry','']
# 如果不需要开头和结尾的空字符串,可以结合 strip() 方法使用:
parts = text.strip(',').split(',')
1. 从左/右开始分割
text = "one two three four"
# 从左侧分割
data = text.split(' ', 2) # ['one','two','three four']
# 从右侧分割
data = text.rsplit(' ', 2) # ['one two','three', 'four']
2. 分割多种分隔符的字符串
text = "apple;banana, cherry|dates"
parts = re.split(r'[;,|\s]+', text)
3. 分割多行字符串
text = "Hello\nWorld\r
Python\rAnother line"
data = text.splitlines() # ['Hello', 'World', 'Python', 'Another line']
18、sort()和sorted()函数
* sort(): 对原列表中的元素进行排序,默认按照大小来排序
# 语法:
my_list.sort(key=None, reverse=False)
# 特点:
1. 永久排序
2. 只作用于列表
3. 直接改变原列表顺序,不创建新列表
4. 返回值None
* sorted():
# 语法:
sorted(iterable, key=None, reverse=False)
# 特点:
1. 临时排序
2. 作用于任何可迭代对象(列表、元组、字典键、字符串等)
3. 不改变原列表数据,创建一个新列表
4. 返回一个新的排好序的列表
a = [(1, 2), (4, 1), (9, 10), (13, -3)]
b = [(1, 2), (4, 1), (9, 10), (13, -3)]
c = {'a': [1, 3], 'b': [3, 4], 'c': [0, 2], 'd': [2, 1]}
# a.sort(key=lambda x: x[1])
1. x[1]表示按照a中子元素里的第二个数排序。比如这里用2,1,10,-3来排序
2. x[0]则表示按照a中子元素里的第一个数排序。比如这里用1,4,9,13来排序
1. 使用sorted()临时排序
a1 = sorted(a, key=lambda x: x[1]) # 按照列表中每个子元素里的第二个数排序
b1 = sorted(b, key=lambda x: x[0]) # 按照列表中每个子元素里的第一个数排序
c1 = sorted(c.items(), key=lambda x: x[1][1]) # 按照value中第一个元素排序,x[1][1]表示列表中第二个元素中的第一个数
c1_2 = sorted(c.items(), key=lambda x: x[0]) # 按照key排序
c1_3 = sorted(c.values(), key=lambda x: x[0])
print(a1) # [(13, -3), (4, 1), (1, 2), (9, 10)]
print(b1) # [(1, 2), (4, 1), (9, 10), (13, -3)]
print(c1) # [('d', [2, 1]), ('c', [0, 2]), ('a', [1, 3]), ('b', [3, 4])]
print(c1_2) # [('a', [1, 3]), ('b', [3, 4]), ('c', [0, 2]), ('d', [2, 1])]
item = ['aasda', 'ad', 'weqetfsfa', 'asd', '1dasda']
a = sorted(item, key=lambda x: len(x), reverse=True)
2. 使用sort() 永久排序
a.sort(key=lambda x: x[1])
b.sort(key=lambda x: x[0])
# c是一个字典类型,无法直接使用 sort() 方法,先强转从list形式,再使用 sort() 方法。dict 的items方法返回[(),(),()]
c2 = list(c.items())
c2.sort(key=lambda x: x[1][1])
c3 = list(c.items())
c3.sort(key=lambda x: x[1][0])
c4 = list(c.items())
c4.sort(key=lambda x: x[0])
print(a) # [(13, -3), (4, 1), (1, 2), (9, 10)]
print(b) # [(1, 2), (4, 1), (9, 10), (13, -3)]
print(c2) # [('d', [2, 1]), ('c', [0, 2]), ('a', [1, 3]), ('b', [3, 4])]
print(c3) # [('c', [0, 2]), ('a', [1, 3]), ('d', [2, 1]), ('b', [3, 4])]
print(c4) # [('a', [1, 3]), ('b', [3, 4]), ('c', [0, 2]), ('d', [2, 1])]
19、zip()函数
把多个可迭代对象(列表 / 元组 / 字符串等)中的元素,按对应位置打包成元组,返回一个迭代器
# 语法:
zip(*iterables)
- *iterables: 一个或多个可迭代对象
zip(*zipped): 将已经打包的元组序列解压回原来的多个可迭代对象
# 特性:
1. 长度以最短的输入为准
2. 解包已zip的对象
# 基础示例
a = [1, 2, 3]
b = ['a', 'b', 'c']
print(zip(a, b)) # <zip object at 0x000002B55F06B340>
print(list(zip(a, b))) # [(1, 'a'), (2, 'b'), (3, 'c')]
# 长度以最短的输入为准
x = [1, 2, 3, 4]
y = ['a', 'b']
z = zip(x, y)
print(list(z)) # [(1, 'a'), (2, 'b')] 3和4被丢弃
# 解包已zip的对象
pairs = [(1, 'a'), (2, 'b'), (3, 'c')]
numbers, letters = zip(*pairs)
print(numbers) # (1, 2, 3)
print(letters) # ('a', 'b', 'c')
# for循环中同时遍历多个序列
names = ['Alice', 'Bob', 'Charlie']
scores = [95, 87, 92]
for name, score in zip(names, scores):
print(f"{name}: {score}")
# 使用zip()构建字典
keys = ['name', 'age', 'city']
values = ['Tom', 25, 'New York']
d = dict(zip(keys, values))
print(d) # {'name': 'Tom', 'age': 25, 'city': 'New York'}
20、类型注解
def get_sth(number: int, name: str, a: float, greeting: str="hello") -> str:
return f'{name} {number} {a} {greeting}'
# 可能返回None函数
def find_user(user_id: int) -> dict | None:
users = {1: {"name": "zkc", "age": 25}}
return users.get(user_id)
def get_unique_num() -> set[int]:
return {1, 2, 3, 4}
# 返回一个字符串列表
def get_names() -> list[str]:
return ["zkc", "zkk"]
print(get_names())
# 参数接收字符串列表,返回字符串
def get_first(datas: list[str]) -> str | None:
return datas[0] if datas else None
# 参数接收两个字符串,返回字典
def build_profile(name: str, age: int) -> dict | None:
return {"name": name, "age": age}
二、函数
函数是一段被命名的、可重复使用的代码块,用于执行一个明确的任务
1、一切皆对象
函数是一个对象,对象是内存中用来存储数据的一块区域
- func:表示函数对象
- func():表示函数调用
# 语法:
def function_name(parameters):
"""
这是一个文档字符串(Docstring),用于解释函数的功能
"""
# 函数体,实现函数功能的代码块
statement_1
statement_2
return result # 可选
1. 函数和类可赋值给一个变量
2. 函数和类可存放到集合对象中
3. 函数和类可作为一个函数的参数传递给函数
4. 函数和类可作为返回值
def func1():
print("func1")
def func2():
print("func2")
def func3():
print("func3")
def func4(fn_name):
fn_name()
class Cls4:
name = "cls4"
if __name__ == "__main__":
a = func1
print("函数对象赋值给变量", a)
b = Cls4
print("类对象赋值给变量", b.name)
# 函数对象作为另一个函数参数
func4(func1)
# 函数对象放在list 中
list1 = list()
list1.append(func1)
list1.append(func2)
list1.append(func3)
for fn in list1:
fn()
2、参数类型
函数参数是函数定义中括号内的变量,在函数调用时传递给函数的值。在定义函数时,可以定义数量不等的形参。
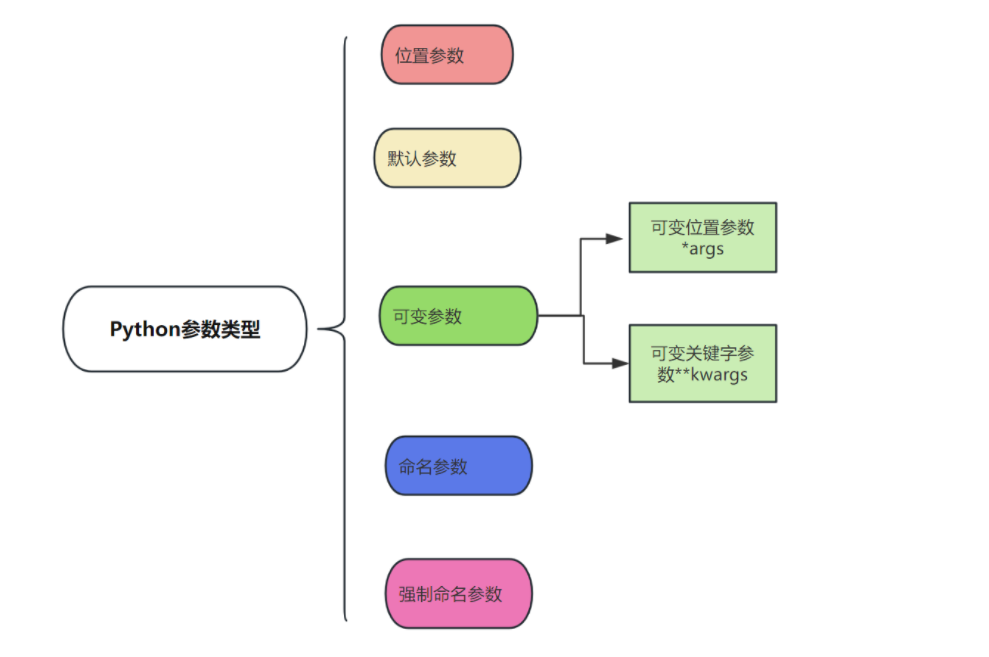
2.1、位置参数和不定长位置参数
1. 位置参数是有顺序的,传递实参的顺序和形参定义的顺序是一致的
2. 位置参数是要必传的,传递实参的数量和形参定义的数量是一致的
3. 不定长位置参数:
- 形参前加 * ,如 *args。将该参数位置所有的实参,封装到一个元组中(装包->解包)
- 带 * 的形参只能有一个
4. 不定长位置参数和其他参数配合使用,它前面的参数必须用位置参数传递,后面的参数必须用关键字参数传递
- 告诉解释器,后面的参数是对应的哪个形参,不然以为都是不定长参数里的元素
"""
可变位置参数放在函数参数的第一位时,其他参数必须是关键字参数
*agrs接收 从 当前位置 到 第一个关键字形式参数 之前 的所有参数,装包成 *args
装包:args = (1, 2, 3)
解包:
a, b, c = args
a, *b = args # a=1, *b=(2, 3)
在函数内部再进行 解包 或者 循环遍历
"""
def func(*args, name_a, name_b):
print(args) # (1, 2, 3)
m, n, k = *agrs # 解包
print(name_a, name_b) # zkc,zkk
func(1, 2, 3, name_a='zkc', name_b='zkk')
"""
可变位置参数在形参的中间位置时,它当前位置前面的参数按位置参数传递,后面的参数用关键字参数传递
*args 接收 从 当前位置 到 第一个关键字形式参数 之前 的所有参数,装包成 *args
"""
def func2(name_a, *args, name_b):
print(name_a) # zkc
print(args) # (1, 2, 3)
m, n, k = *agrs # 解包
print(name_b) # zkk
func2('zkc', 1, 2, 3, name_b='zkk')
"""
可变位置参数在形参的末尾位置时,它当前位置之前的所有参数按照位置参数传递
"""
def func3(name_a, name_b, *args):
print(name_a)
print(name_b)
print(args)
m, n, k = *agrs # 解包
func('zkc', 'zkk', 1, 2, 3)
2.2、关键字参数和不定长关键字参数
1. 关键字参数是通过 "k-v键值对" 形式来传递参数
2. 关键字参数与顺序无关,是通过参数名来进行参数传递
3. 位置参数和关键字参数可以混合使用,关键字参数必须放在位置参数的后面
4. 不定长关键字参数:
- 形参前加 ** ,如 **kwargs。将该位置后面所有参数封装到一个字典中
5. 不定长关键字参数放在形参列表的最后面
"""
关键字参数、位置参数和默认值参数混合使用,默认值参数在最后,关键字参数在默认值参数前面
"""
def func(a, b, c, d=20):
print(a, b, c, d) # 1 2 10 20
func(1, 2, c=10)
"""
关键字参数、位置参数和不定长关键字参数、不定长位置参数混合使用
"""
def func(a, b, *args, **kwargs):
print(a) # 1
print(b) # 2
print(args) # (3, 4, 5)
print(kwargs) # {'name': 'zkc', 'age': 18}
func(1, 2, 3, 4, 5, name='zkc', age=18)
2.3、默认值参数
允许在函数定义时指定默认值。一般将为变化频率低的参数设置默认值
1. 调用函数时,如果实参中不传递该参数,将使用默认值
2. 调用函数时,如果实参中传递参数,将使用传递的值,默认值不生效
3. 默认值参数在位置参数后面
# 函数默认参数值设置:
一般是不可变类型,如果是可变类型,一般设置为None,并在函数内部检查,根据需要创建一个新的对象
def func(a, b=10, c=20):
print(a, b, c)
func(1, 2, 3) # 此时实参传递了b,c,则不使用默认值10,20
func(1) # 此时实参没有传递b,c,则使用默认值10,20
def func(item, my_index=None): # 可变类型,设置为None
if my_index is None:
my_index = []
my_index.append(item)
return my_index
def func(item, my_index=[]):
""" 这种不可取,多次调用时返回值会累加"""
my_index.append(item)
return my_index
2.4、命名关键字参数/强制关键字参数
Python3.8 新增了一个函数形参语法 / 用来指明之前函数形参必须使用指定位置参数,不能使用关键字参数的形式
- 定义: 要求 * 后面所有参数必须以关键字参数进行传递,而不允许使用位置参数
- 作用: 限制要传入的参数的名字,只能传已命名关键字参数
- 特征: 命名关键字参数需要一个特殊分隔符*,而后面的参数被视为命名关键字参数
* 关键字参数 和 命名关键字参数 的区别:
1. 前者可以传递任何名字的关键字参数,而后者只能传递 * 后面名字的关键字参数。
2. 如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*
def func(*, a, b, c):
print(a, b, c)
func(a=1, b=2, c=4)
def person(*, city, sex): # 使用分隔符 *,表示后面的参数必须使用关键字传递
print(city, sex)
person(city='USA',sex='男') # 输出:USA 男
def person(name, age, *, city, sex):
print(name, age, city, sex)
person('John',20,city='USA',sex='男') # 输出:John 20 USA 男
#person('John',20,city='USA',birthday='1996-02-11') 报错 TypeError: person() got an unexpected keyword argument 'birthday'
# 在以下的例子中,形参 a 和 b 必须使用指定位置参数,c 或 d 可以是位置形参或关键字形参,而 e 和 f 要求为关键字形参:
def f(a, b, /, c, d, *, e, f):
print(a, b, c, d, e, f)
# 正确调用方式
f(10, 20, 30, 40, e=50, f=60)
f(10, 20, 30, d=40, e=50, f=60)
# 命名关键字参数和关键字参数区别:
def person(name, age, *args, city, sex):
print(name, age,args, city, sex)
person('John',20, *[1,2,3,4],city='USA',sex='男')
#运行结果:
John 20 (1, 2, 3, 4) USA 男
2.5、参数解包
"""
元组解包:
t = (1, 2, 3)
*t = t
字典解包:
d = {'a': 1, 'b': 2, 'c': 3}
**d = d
1、传递实参时,在序列类型的参数前加 * ,会自动将序列中的元素依次作为参数传递
2、要求序列中元素个数和形参的个数保持一致
"""
def func(a, b, c):
print(a, b, c)
# 创建一个元组
t = (1, 2, 3)
func(*t)
# 创建一个字典
d = {'a': 1, 'b': 2, 'c': 3}
func(**d)
# 示例一
def func(x, y, z):
print(x, y, z)
func(*[1, 2, 3])
func(*(1, 2, 3))
func(**{"x": 1, "y": 2, "z": 3})
# 示例二
def func(x, y, z, *args):
print(x, y, z)
print(args)
func(5, 6, 7, *[1, 2, 3])
2.6、组合使用
参数定义的顺序必须是:
位置参数–>默认参数–>可变参数–>命名关键字参数–>关键字参数
def person(name, age,clas='二班', *args, **kwargs):
print('name:{}, age:{}, clas:{}, args:{}, kwargs:{}'.format(name, age,clas,args, kwargs))
person('John',20) # name:John, age:20, clas:二班, args:(), kwargs:{}
person('John',20,'4班',1,2)
person('John',20,'4班',1,2,city='USA',sex='男')
def f1(a, b, c=0, *, d, **kw):
print('a:{},b:{},c:{},d:{},kw:{}'.format(a,b,c,d,kw))
f1(1,2,d=4) # a:1,b:2,c:0,d:4,kw:{}
f1(1,2,3,d=4,e=5) # a:1,b:2,c:3,d:4,kw:{'e': 5}
3、函数返回值
函数通过return语句将其处理的结果返回给调用者。调用者可以接收这个返回值,并将其赋给一个变量,或直接用于其他表达式
- return 可以返回任意类型的数据
- return 表示函数结束,执行到return语句,它会立即终止,并将值返回。后面的代码不会再执行
- 如果函数没有return语句,或return后面没有跟任何值,默认返回一个None
- 函数可返回多个值,实际上返回的是包含这些值的一个元组
def test():
for i in range(5):
if i == 3:
return
print(i)
print("循环结束")
4、文档字符串
"""
这里函数参数的类型 和 函数返回值的类型都不是强制的,只是一个提示作用
"""
def func(a:int, b:bool, c:str='zkc') -> str:
'''
这是一个文档字符串,通过function_name.__doc__来访问。解释函数用途、参数和返回值
函数的作用是:XXX
函数的参数:
a: 作用,类型,默认值
b: 作用,类型,默认值
'''
return "hello"
# 通过help函数查看函数的说明
help(func)
5、作用域
5.1、作用域的概念
作用域指的是变量生效的区域
- 变量并非在任何位置都能访问,访问权限决定于这个变量是在哪里创建赋值的,变量的作用域决定了在哪一部分程序可以访问哪个特定的变量名称
- 只会在"
模块、类以及函数中才会引入新的作用域",在其它代码块(if/elif/else/、try/except、for/while等)不会引入新的作用域,在这些语句内定义的变量,外部也可以访问
1. 内置作用域 (builtins Scope)
- 通过builtin的标准模块来实现的,但变量名并没有放入内置作用域内,所以必须导入这个文件才能使用
- 查看预定义变量: import builtins; dir(builtins)
2. 全局作用域 (Global Scope)
- 在模块顶层(即不在任何函数内部)定义的变量,拥有全局作用域
- 全局作用域在程序执行时创建,在程序执行结束时销毁
- 全局作用域中定义的变量叫全局变量,全局变量可在程序的任意位置被访问
3. 局部作用域 (Local Scope)
- 函数作用域在函数调用时创建,在调用结束时销毁
- 函数每调用一次,就会产生一个新的函数作用域
- 函数作用域中定义的变量(包括函数的参数),只能在函数内部被访问
4. 闭包作用域 (Enclosing Scope)
- 当一个函数嵌套在另一个函数内部时,就形成了闭包
- 内部函数可以访问外部(但非全局)函数的变量,这个外部函数的局部作用域,对内部函数来说,就是闭包作用域
- 包含非局部(non-local)也非全局(non-global)的变量
5. global 关键字
- 在函数内部对全局变量进行修改,Python会创建一个新的局部变量,而不是修改全局变量
- 这是一种保护机制,防止函数无意中污染了全局空间
6. nonlocal 关键字
- 修改嵌套作用域(enclosing作用域,外层非全局作用域)
- 多层嵌套函数中,用nonlocal关键字声明的变量只影响上一层的变量,再外一层的不受影响
- 两个嵌套函数,一个函数A中又包含一个函数B,那么对于B来说A中变量是nonlocal的
b = 20 # 全局变量
def func():
a = 10 # 局部变量/函数变量
print('函数内部:', 'a = ', a) # a是局部变量,在函数内部能访问
print('函数内部:', 'b = ', b) # b是全局变量,可在任意位置被访问
func()
print('函数外部:', 'a = ', a) # 无法访问
print('函数外部:', 'b = ', b) # b是全局变量,可在任意位置被访问
5.2、作用域的查找
Python主要有四种作用域,变量作用域查找遵循 "LEGB" 规则:
* L (Local): 最内层,包含局部变量和函数的参数,比如一个函数的内部
* E (Enclosing): 闭包函数作用域。指嵌套函数中,外部函数的作用域
* G (Global): 全局作用域。指模块的顶层
* B (Built-in): 内置作用域。包含了内建的变量/关键字等
* 当使用某变量时,优先在当前作用域中寻找该变量
- 如果有则直接使用;如果没有,则继续到上一级作用域中寻找,一直找到全局作用域,若依然没有找到,则抛出异常
* 从 内-->外: 可以看到所有的变量,一层一层往外寻找,直到找到为止
* 从 外-->内: 只能看到全局的变量
"""
1、在函数内部修改全局变量,则需使用 global 关键字
2、global关键字可声明函数内部的变量是全局变量,此时修改的就是全局变量
"""
# 案例1
z = 50 # 全局变量
def modify_global_wrong():
z = 99 # Python认为这里在定义一个新的局部变量z
print(f" Inside, after assignment, z = {z}")
# 案例2
a = 10
def func():
global a
a = 20
print('函数内部', 'a = ', a)
func()
print('函数外部', 'a = ', a)
# 案例3
def scope_test():
def do_local():
spam = "local spam"
def do_nonlocal():
nonlocal spam
spam = "nonlocal spam"
def do_global():
global spam
spam = "global spam"
spam = "test spam"
do_local()
print("After local assignment:", spam)
do_nonlocal()
print("After nonlocal assignment:", spam)
do_global()
print("After global assignment:", spam)
scope_test()
print("In global scope:", spam)
# 案例4
x = 0
def outer():
x = 3
def mid():
x = 2
def inner():
nonlocal x
x = 1
print("x_inn=", x) # x_inn = 1
inner()
print("x_mid=", x) # x_inn = 1 ,受到 nonlocal 关键字影响
mid()
print("x_out=", x) # x_inn = 3,不受到 nonlocal 关键字影响
outer()
print("x_glo=", x) # x_inn = 0,因outer函数内没有使用global关键字定义x_inn ,所以此处输出的还是 0
# 闭包函数外的函数中
x = 0
def outer():
x = 5
def inner():
i = 2
print(x)
inner()
outer() # 5,在inner中找不到变量x,继续向上层outer中找,找到x
# 非全局作用域
def outer():
num = 10
def inner():
nonlocal num # 使用nonlocal关键字,将num从非全局作用域修改为局部作用域
num = 100
print("inner 函数中,num = ",num)
num *= 10.24 # 类型自动转换为float
inner()
print("outer 函数中,num = ",num) # inner中将num修改成局部作用域,覆盖了原来的10
outer()
6、命名空间
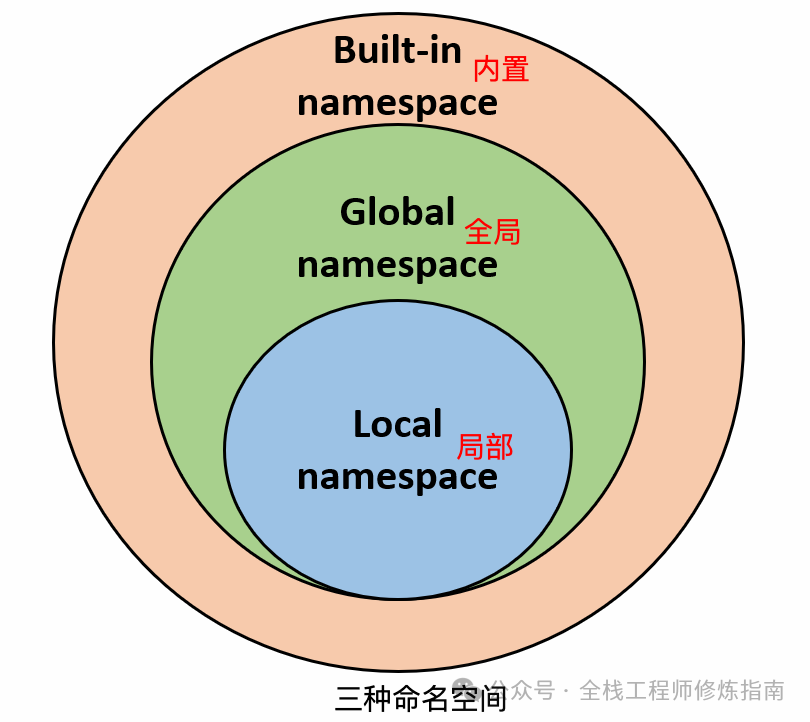
6.1、命名空间(Namespace)的概念
指的就是变量存储的位置,每一个变量都需要存储到指定的命名空间中。也就是说,命名空间实际上是一个专门用来存储变量的字典
# 描述:
命名空间: 是从名称到对象的映射,大部分的命名空间都是通过"字典"来实现的
1. 提供在项目中避免名字冲突的一种方法
2. 各个命名空间是独立的,没有任何关系的,不同命名空间空间下变量可以重名而没有任何影响
# 例如:
计算机系统中,一个文件夹(目录)中可以包含多个文件夹,每个文件夹中不能有相同的文件名,但不同文件夹中的文件可以重名
# 文件夹 A
A/1.txt
A/demo1.txt
# 文件夹 B
B/2.txt
B/demo1.txt
6.2、命名空间种类
每一个作用域都有一个对应的命名空间
* 局部命名空间(local namespace)
- 保存函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量
* 全局命名空间(global namespace)
- 保存模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量
* 内置命名空间(built-in namespace)
- Python内置的名称,比如函数名 abs、char 和异常名称等
6.3、获取命名空间
locals() 用来获取当前作用域的命名空间,返回一个字典
- 全局作用域中调用,则获取全局命名空间
- 函数作用域中调用,则获取局部命名空间
globals() 用来获取全局命名空间,返回一个字典
- 函数作用域中调用,则获取全局命名空间
name = 'zkc'
global_scope = locals()
def ns():
a = 10
local_scope = locals()
print('局部命名空间: ', local_scope)
print('全局命名空间: ', global_scope)
ns()
"""
向字典中添加key-value,相当于在命名空间中创建了一个变量(一般不建议这样做)
"""
name = 'zkc'
global_scope = locals()
global_scope['age'] = 19
def ns():
a = 10
local_scope = locals()
local_scope['b'] = 2000
print('局部命名空间: ', local_scope)
print(local_scope['b'])
print('全局命名空间: ', global_scope)
print(global_scope['age'])
ns()
"""
在函数内部获取全局命名空间(一般不建议这样做)
"""
a = 20
def func():
global_ns = globals()
print('全局命名空间: ', global_ns)
global_ns['b'] = 30
print('全局命名空间: ', global_ns)
func()
6.4、命名空间的查找
局部的命名空间 -> 全局命名空间 -> 内置命名空间
6.5、命名空间的声明周期
取决于对象的作用域,如果对象执行完成,则该命名空间的生命周期就结束, 因此,我们无法从外部命名空间访问内部命名空间的对象
7、递归和其他函数知识
7.1、递归
* 递归式函数
- 在函数中自己调用自己
- 整体思想: 将一个大问题分解成一个个的小问题,直到问题无法分解时,再解决问题
* 递归式函数的要素:
1、基线条件: 问题可以被分解为最小问题,当满足基线条件时,递归不再执行
2、递归条件: 将问题继续分解的条件
循环和递归区别:
循环:编写简单,不容易理解
递归:编码复杂,容易理解
"""
无穷递归(禁止):
函数被调用时,程序内存会溢出,效果类似于死循环。
"""
def fn():
fun()
fun()
"""
创建一个函数,求任意数的阶乘 -- 循环方式 求阶乘
"""
def factorial(n):
result = n
for i in range(1, 10):
result *= i
return result
print(factorial(10))
"""
创建阶乘的递归函数 -- 递归方式 求阶乘
10! = 10 X 9!
9! = 9 X 8!
8! = 8 X 7!
...
1! = 1
"""
def factorial(n):
# 基线条件: 判断 n 是否为 1,如果为 1, 则不再递归
if n == 1:
return 1
# 递归条件
return n * factorial(n-1)
"""
创建一个函数power,来为任意数字做幂运算 n ** i
"""
def power(n, i):
if i == 0:
return 1
if i < 0:
return 1 / power(n, -i)
return n * power(n, i - 1)
print(power(10, -3))
"""
回文字符串:从前往后读和从后往前读是一样的 abcba
创建一个函数,检查任意字符串是否是回文字符串,是则返回True,否则返回False
检查abcdefgfedcba是不是回文
检查bcdefgfedcb是不是回文
检查cdefgfedc是不是回文
检查defgfed是不是回文
检查efgfe是不是回文
检查fgf是不是回文
检查g是不是回文
"""
def hui_wen(s):
# 基线条件,字符串长度小于2,则一定是回文
if len(s) < 2:
return True
elif s[0] != s[-1]: # 第一个字符和最后一个字符不相等,不是回文字符串
return False
return hui_wen(s[1:-1])
print(hui_wen('abcdefgfedcba'))
7.2、高阶函数
在python中,“函数是一等对象”,具有如下特点:
- 对象是在运行时创建的
- 能赋值给变量或者作为数据结构中的元素
- 能作为参数传递
- 能作为返回值返回
什么是高阶函数?
- 接收一个或多个函数作为参数
- 将函数作为返回值返回
当使用一个函数作为参数时,实际上是将指定函数的代码传递进目标函数
1、函数式编程 map()-惰性求值
# 定义:
将一个函数映射到一个输入列表的所有元素上, 生成新的列表
# 语法格式:
map(function, list_of_input)
- function: 函数对象
- list_of_input: 一个或多个可迭代对象,可以是列表/元组/字符串
# 注意事项
1. map返回的是迭代器,如果需要列表,要用 list()转换
2. map不会修改原数据,而是返回新数据
3. map比for循环更高效,因为map是惰性计算(不立即执行,只在需要时计算)
item = [1, 2, 3, 4, 5]
# map使用lambda函数
item1 = list(map(lambda x: x ** 2, item))
# map处理多个可执行对象
item2 = list(map(lambda x, y: x + y, item, item1))
# map处理类型转换
item4 = ['1', '2', '3']
item3 = list(map(int, item4))
# 互换位置
item5 = [(1, 2), (3, 4), (5, 6)]
item6 = list(map(lambda x: (x[1], x[0]), item5))
2、函数式编程 filter()-惰性求值
# 定义:
过滤列表中的元素,返回一个由所有符合要求的元素所构成的列表
# 语法格式:
filter(function, list_of_input)
- function: 函数对象
- list_of_input: 一个或多个可迭代对象,可以是列表/元组/字符串
# func 返回 True:则保留该元素
# func 返回 False:则丢弃该元素
# func 是 None:则直接过滤掉 0, "", '', None, False 的值
# 注意事项
1. filter返回的是迭代器,如果需要列表,要用list()转换
2. filter不会修改原数据,而是返回新数据
3. filter比for循环更高效,因为filter是惰性计算(不立即执行,只在需要时计算)
# filter 和 列表推导式的用法
* filter(): 适用于 函数式编程 或 已有判断函数 的情况
* 列表推导式: 适用于 简单条件 或 需要更直观代码 的情况
my_list = [1, None, 'hello', '', 3.14, False, []]
# 过滤my_list列表的空值
new_list1 = list(filter(lambda x: x is not None and x != '' and x != [], my_list))
new_list2 = list(filter(None, my_list))
3、函数式编程 reduce()
# 定义:
返回计算结果是一个值
# 导入
from functools import reduce
# 语法格式:
filter(function, sequence )
- function: 有两个参数的函数
- sequence: 一个或多个可迭代对象,可以是列表/元组/字符串
- initial: 初始值, 可选参数
# 原理:
把上一次计算的结果作为下一次的计算的输入
1. 把迭代对象的前两个元素传给函数,函数加工后将值返回
2. 把函数上次返回的值和迭代对象中第三个元素作为两个新的参数再传给函数,
函数进行加工后将值返回
3. 把函数上次返回的值和迭代对象中第四个元素作为两个参数传给函数参数,函数再进行加工后将值返回,以此类推
4. 如果传入initial值, 那么首先传给函数的是initial值和sequence的第一个元素
5. 经过这样的累计计算之后合并序列到一个单一返回值
list_aa = list(range(1, 10))
res = reduce(lambda x, y: x + y, list_aa)
res1 = reduce(lambda x, y: x + y, list_aa, 10)
print("reduce", res) ## 45
print("reduce有初始值", res1) ## 55
# 计算一个序列的累积乘积
numbers = [1, 2, 3, 4, 5]
product = reduce(lambda x, y: x * y, numbers)
print("1 * 2 * 3 * 4 * 5 =",product) # 输出:120
7.3、匿名函数
lambda关键字用来创建匿名函数(隐函数),调用完成后,函数从内存中删除
- lambda 主体是一个表达式,而不是一个代码块, 仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数。
- lambda 函数虽然看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
# 语法:
my_lambda = lambda 参数1, 参数2: 表达式
#调用
print(my_lambda(参数1, 参数2))
# 定义形式:
lambda 形参: 返回值表达式 (语法糖)
* 匿名函数一般作为参数使用,其他地方不会使用
# 无参lambda
my_lambda = lambda: "hello, Python"
# 有参lambda
my_lambda = lambda a, b: a * b
# 参数有默认值lambda
my_lambda = lambda a=10, b=25: a + b
def fn(a, b):
return a + b
等价于: lambda a, b: a + b
调用: print((lambda a, b: a + b)(10, 20))
等价于: a = lambda x: x ** 2
调用: a(10, 20)
7.4、闭包
将函数作为返回值返回的一种高阶函数,叫做闭包
通过闭包可以创建一些只有当前函数能访问的变量,可以将一些私有的数据藏到闭包中,总体来说平是为了数据安全。
闭包是一种满足特定要求的内嵌函数,内嵌函数称为子函数,其外部函数称为母函数,当子函数体内有对母函数体内定义的变量的引用时我们称这个子函数为一个闭包。
但当母函数和其闭包都定义了参数时,由于在母函数体外是无法直接对闭包进行函数调用的,为了能够实现对闭包的调用,需要在母函数内增加一条返回闭包函数名本身的语句,这个时候调用母函数后返回的是一个闭包的函数对象,就可以通过这种方法间接调用闭包函数了
# 形成闭包的条件:
1. 函数嵌套
2. 将内部函数作为返回值返回
3. 内部函数必须要使用外部函数的变量
def fn():
a = 10
# 函数内部再定义一个函数
def inner():
print('我是inner', a)
# 将内部函数inner作为函数值返回
return inner
r = fn()
r()
"""
不加外层函数,nums列表就是一个全局变量,在任何位置都能访问和修改
加了外层函数之后,nums变量只在averager()中能访问,在全局中访问不到函数内部的nums
"""
def make_averager():
# 创建一个列表,用来保存数据
nums = []
# 创建一个函数,用来计算平均值
def averager(n):
nums.append(n)
# 求平均值
return sum(nums)/len(nums)
return averager
averager = make_averager()
print(averager(10))
print(averager(10))
print(averager(10))
# 内嵌函数与闭包
def funx(x):
def funy(y):
return x * y
return funy
a = funx(5) # 此时funx已经执行完毕,但是funx返回了一个函数对象,这个函数对象记住了funx中的变量x的值,所以a现在是一个函数<function funx.<locals>.funy at 0x00000146BEE0A170>
b = funx(5)(8) # 相当于a(8)
print(a)
print(b)
# 示例1:nonlocal关键字, 其中值保存在内存之中
def funA():
x = 5 # 函数内部变量,局部变量。
def funB():
nonlocal x # 把x强制表示不是局部变量local variable,所以就不会每次被初始化
x += 13
return x
return funB
a = funA() #当 a 第一次被赋值后,只要没被重新赋值,funA()就没被释放,也就是说局部变量x就没有被重新初始化。
print("闭包中使用 nonlocal 关键字,第一次调用:",a(),"第二次调用:",a(),"第三次调用:",a())
# 示例3. global 关键字, 值还是保存在内存之中
x=1 # 函数外部的变量,全局变量。
def funC():
x = 5
def funD():
global x # 声明全局变量x,所以每次调用都不会被重新初始化。
x += 13
return x
return funD
b = funC() #当 a 第一次被赋值后,只要没被重新赋值,funC()就没被释放,也就是说全局变量x就没有被重新初始化。
print("闭包中使用 global 关键字,第一次调用:",b(),"第二次调用:",b(),"第三次调用:",b())
# 闭包中使用nonlocal关键字,第一次调用:18 第二次调用:31 第三次调用:44
# 闭包中使用global关键字,第一次调用:14 第二次调用:27 第三次调用:40
8、装饰器
又叫修饰符,常用于有切面需求的场景,比如插入日志记录,方法添加,数据验证,性能测试,事务处理等
在不修改原来函数的情况下,来增强函数、类功能的一个函数
1. 在定义函数时,通过"@装饰器"来装饰当前的函数
2. 一个函数同时可执行多个装饰器,按照从内向外的顺序被装饰
3. 直接修改原函数,违反开闭原则(OCP)。如果要修改的函数很多,修改起来麻烦
4. 程序的设计,要求开放对程序的扩展,要关闭对程序的修改
5. 用functools.wraps装饰器,使得被装饰的函数的元信息不会丢失,避免被装饰内部函数的名称、注释等信息被改变
# 装饰器的4种类型:
"函数装饰函数、函数装饰类、类装饰函数、类装饰类"
8.1、装饰器定义
# wrapper装饰器函数名称,func被装饰的函数
def wrapper(func):
# inner: 被返回的函数,用来替代原函数
def inner(*args, **kwargs): # 跟原函数同样的参数配置
res = func(*args, **kwargs) # func() 运行原函数,res是原函数的返回值
return res # 把原函数运行的结果反馈给调用方,在调用方看来,得到的结果依然是原函数的结果
return inner # 用来替代原函数
def func1():
pass
func1 = wrapper(func1) # 可用语法糖 @ 替换
func1()
# 装饰器初始阶段
def log(func):
def wrapper(*args, **kwargs):
print("调用函数前")
result = func(*args, **kwargs)
print("调用函数后")
return wrapper
def calc_add(a: int, b: int) -> int:
print("正在计算a、b的和", a + b)
calc_add = log(calc_add) # 这里的calc_add已经不再是原来的calc_add对象了,而是将log函数返回的wrapper对象赋值给了calc_add。
calc_add(1, 2) # 这里相当于是调用的wrapper函数
# 装饰器成型阶段
# 将 calc_add = log(calc_add) 用 语法糖 "@" 替代
def log(func):
@wraps(func)
def wrapper(*args, **kwargs):
print("调用函数前")
result = func(*args, **kwargs)
print("调用函数后")
return result
return wrapper
@log
def calc_add(a: int, b: int) -> int:
return a + b
def decorate_function(function):
def inner(*args, **kwargs):
inner.co += 1
return function(*args, **kwargs)
inner.co = 0
return inner
@decorate_function
def sample_function():
pass
if __name__ == '__main__':
"""
sample_function()调用时,进入装饰器函数,获取到inner函数局部变量co的初始值0,返回inner对象
装饰器已经将函数decorate_function的返回值inner对象赋值给sample_function,sample_function=inner
sample_function()==inner()
每次调用时,相当于调用inner函数,
第一次调用: co变量值为0+1=1,初始值0加上1
第二次调用: 1+1=2,第一次调用后co的值为1了,第二次调用再加一
第三次调用: 2+1=3
"""
sample_function() # 这里的sample_function不是原函数了,而是装饰器返回的inner函数,这里是在调用inner函数
sample_function()
sample_function()
print(sample_function.co)
def decorate(func):
def wrapper():
print('start')
func()
print('end')
return wrapper
@decorate
def show():
return 'show'
if __name__ == '__main__':
"""
show()调用之后进入装饰器,装饰器将返回值wrapper赋值给show,show()等价于wrapper()
print(show()) 相当于 print(wrapper()),所以输出为None,因为wrapper函数没有返回值
至于为啥装饰器中没有返回值,因为wrapper中,只是调用了函数,没有获取返回值,所以是空的
"""
print(show())
8.2、高阶装饰器
先执行距离函数最近的装饰器(就近原则),再将第一个装饰器返回的函数 作为 下一个装饰器函数的参数,依次类推
def log1(func):
@wraps(func)
def wrapper(*args, **kwargs):
print("调用函数之前的操作1")
result = func(*args, **kwargs)
print("调用函数之后的操作2")
return result
return wrapper
def log2(func):
@wraps(func)
def wrapper(*args, **kwargs):
print("调用函数之前的操作3")
result = func(*args, **kwargs)
print("调用函数之后的操作4")
return result
return wrapper
'''
不用语法糖调用
'''
def calc_add(a: int, b: int) -> int:
print("正在计算a、b的和", a + b)
return a + b
calc_add2 = log2(calc_add) # 返回wrapper对象,赋值给calc_add2
calc_add1 = log1(calc_add2) # 这里的log1函数的参数calc_add参数是,第一步log2函数返回的wrapper函数对象赋值给的calc_add
print(calc_add1(1, 2))
'''
使用语法糖 @
'''
@log1
@log2
def calc_add(a: int, b: int) -> int:
print("正在计算a、b的和", a + b)
return a + b
8.3、不同种类的装饰器
8.3.1、函数装饰函数:不带参数装饰器函数
import time
import functools
def log_execution_time(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.perf_counter()
res = func(*args, **kwargs)
end = time.perf_counter()
print('{} took {} ms'.format(func.__name__, (end - start) * 1000))
return res
return wrapper
@log_execution_time
def calculate_similarity(items):
pass
# 声明装饰器,将被装饰函数传入
def decorator_function(original_function):
@functools.wraps(original_function)
def wrapper(*args, **kwargs):
print("在调用 original_function 函数之前的操作")
result = original_function(*args, **kwargs)
print("在调用 original_function 函数之后的操作")
return result
# 将装饰完之后的函数返回(返回的是函数对象)
return wrapper
# 使用装饰器, 装饰器通过 @ 符号应用在函数定义之前。
@decorator_function
def original_function(arg1, arg2):
print("original_function:",arg1,arg2)
pass
# 调用原函数,触发装饰器
original_function(1024, 2048)
8.3.2、函数装饰函数:带参数装饰器函数
'''
@fn2('zkc', age=19)
这里的 @ 符号后面是函数调用,调用了fn2()这个函数,fn2函数返回了一个装饰器,跟前面的 @ 符号拼接成了装饰器调用
'''
def fn2(*_out_args, **out_kwargs):
def begin_end(func):
# 创建一个新函数
def new_function(*args, **kwargs):
print(f"{out_kwargs['age']}岁的{out_args[0]}开始执行")
# 调用被扩展的函数
r = func(*args, **kwargs)
print(r)
print("结束执行")
return r
# 返回新函数
return new_function
return begin_end
@fn2('zkc', age=19)
def add(a, b):
return a + b
add(3, 6)
# 带参数的装饰器
# repeat 函数是一个带参数的装饰器,它接受一个整数参数 n,然后返回一个装饰器函数,此参数是用来控制装饰器的执行次数。
# 声明装饰器
def repeat(n):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
result = None
for _ in range(n):
result = func(*args, **kwargs)
return result
return wrapper
return decorator
# 使用装饰器
@repeat(5)
def greet(name):
print(f"Hello, {name}!")
# 调用原函数,触发装饰器
greet("WeiyiGeek")
8.3.3、函数装饰类:装饰器函数
def wrapClass(cls):
def inner(a):
print('class name:', cls.__name__)
return cls(a)
return inner
@wrapClass
class Foo:
def __init__(self, a):
self.a = a
def fun(self):
print('self.a =', self.a)
m = Foo('xiemanR')
m.fun()
# 在类初始化时进行数据验证
def validate(cls):
original_init = cls.__init__
def new_init(self, *args, **kwargs):
if args:
for arg in args:
if not isinstance(arg, (int, float)):
raise ValueError(f"Excepted arg int or float, got {type(arg).__name__}")
original_init(self, *args, **kwargs)
if kwargs:
for key, value in kwargs.items():
if not isinstance(value, (int, float)):
raise ValueError(f"Excepted kwarg int or float, got {type(value).__name__}")
original_init(self, *args, **kwargs)
cls.__init__ = new_init
return cls
@validate
class MyClass:
def __init__(self, x, y):
self.x = x
self.y = y
try:
instance = MyClass(x=10, y='20')
except ValueError as e:
print(e)
8.3.4、类装饰函数:类装饰器
# 类装饰器是包含 __call__ 方法的类,它接受一个函数作为参数,并返回一个新的函数。
class DecoratorClass:
# 首先,DecoratorClass 的 __init__ 方法应该只接受 count 参数
def __init__(self, count=3):
self.count = count
self.execution_count = 0
def __call__(self, func):
def wrapper(*args, **kwargs):
self.execution_count += 1
print(f"Execution count: {self.execution_count}")
result = None
for _ in range(self.count):
result = func(*args, **kwargs)
return result
return wrapper
# 使用装饰器
@DecoratorClass(count=5)
def my_function(name):
print(f"Hello, {name}!")
# 调用原函数,触发装饰器
my_function("公众号: 全栈工程师修炼指南")
my_function("公众号: 全栈工程师修炼指南")
8.3.5、类装饰类:类装饰器
class ShowClassName(object):
def __init__(self, cls):
self._cls = cls
def __call__(self, a):
print('class name:', self._cls.__name__)
return self._cls(a)
@ShoClassName
class Foobar(object):
def __init__(self, a):
self.value = a
def fun(self):
print(self.value)
a = Foobar('xiemanR')
a.fun()
9、迭代器 和 生成器
# 可迭代协议 iterable protocol
* 如果一个对象中实现了__iter__(), 称该对象为可迭代对象,如列表、字典
# 迭代器协议 iterator protocol
* 如果一个对象中实现了__next__(), 称该对象为迭代器
一个迭代器对象要可迭代:
1. 必须同时包含另一个方法叫做"__iter__"
2. "__iter__"方法还得返回一个"迭代器"(可迭代),即返回迭代器本身self
9.1、迭代器(Iterator)-惰性求值
Python中实现了迭代协议,即包含 __iter__() 和 __next__() 方法的对象叫迭代器
* 迭代器是一种可以实现惰性计算的对象,可以被用来遍历可迭代对象中的元素
* 迭代器可以被 next() 函数调用,并且逐个返回元素,直到没有元素可返回时抛出 StopIteration 异常
* 迭代器不是一个容器,且判断一个容器是不是有迭代功能只需要查看iter()和 next()方法
* 迭代器只能往前不能后退,当容器中没有元素时,就抛出StopIteration异常表示容器已经没有元素
* 迭代器只能迭代一次值,要是想再迭代,要重新实例化创建迭代器
* 惰性机制,必须调用__next__()或者被 next() 函数调用才会获取数据
# 迭代器的特点:
1. 只在需要时才生成下一个值,这种延迟计算的方式使得迭代器在处理大数据集时非常高效
2. 不会一次性将所有数据都加载到内存中,而是按需生成和处理数据
'''
自定义迭代器
要实现一个迭代器,需定义一个类并实现两个魔法方法:
__iter__():返回迭代器自身(通常是return self)
__next__():返回下一个元素,无元素时抛出StopIteration
'''
class CountIterator:
def __init__(self, start, end):
self.current = start # 初始值
self.end = end # 终止值
def __iter__(self):
return self # 返回迭代器自身
def __next__(self):
if self.current <= self.end:
result = self.current
self.current += 1
return result
else:
raise StopIteration # 终止迭代
counter = CountIterator(1, 3)
for num in counter:
print(num)
class MyIterator:
def __init__(self, content):
self.content = content
self.index = 0
def __iter__(self):
return self
def __next__(self):
if self.index < len(self.content):
result = self.content[self.index]
self.index += 1
return result
else:
raise StopIteration
my_iterator1 = MyIterator([1, 2, 3, 4])
print(next(my_iterator1)) # 输出1
print(next(my_iterator1)) # 输出2
print(next(my_iterator1)) # 输出3
print(next(my_iterator1)) # 输出4
print(next(my_iterator1)) # 抛出StopIteration异常
9.1.1、第一种方式:使用__iter__()和__next__()抽象方法
__iter__()和__next__()是迭代器对象的抽象方法,每个迭代器都实现了这两个方法
# 相当于for循环
from collections.abc import Iterable,Iterator
def func(data):
if isinstance(data, Iterable): # 判断数据是不是可迭代的/迭代器
it = data.__iter__()
while True:
try:
print(it.__next__())
except StopIteration as e:
break
func([1, 2, 3])
data = (1, 2, 4)
it1 = data.__iter__().__iter__().__iter__()... # 迭代器的迭代器还是自己
print(it1) # 不调用__next__()时,只是一个可迭代对象
print(it1.__next__())
print(it1.__next__())
print(it1.__next__())
# 要想再次迭代data,重新调用迭代器
it2 = data.__iter__()
9.1.2、第二种方式:使用内置的 iter() 和 next() 函数
def func(data):
from collections.abc import Iterable
if isinstance(data, Iterable):
it = iter(data)
while True:
try:
iter_data = next(it)
print(iter_data)
except StopIteration as e:
break
func([1, 2, 3, 4, 5])
9.1.3、第三种方式:使用for循环
data = [1, 2, 3, 4, 5]
it = iter(data)
for i in it:
print(i)
it2 = data.__iter__()
for i in it2:
print(i)
9.2、生成器(generator)-惰性求值
生成器(Generator)是一种特殊的迭代器,它可以在需要时动态生成值,而不是一次性将所有值存储在内存中。生成器使用 yield 关键字来定义生成值的逻辑,每次调用生成器的 next() 方法时,它会从上一次的 yield 语句处继续执行,直到遇到下一个 yield 或者函数结束。
生成器在实现上更加简洁和高效,因为它不需要显式地维护整个序列,而是在每次迭代中动态生成下一个值,这种惰性计算的方式使得生成器非常适合处理大数据集或者无限序列。
9.2.1、生成器函数
函数中如果包含了yield关键字,通过yield来返回数据时,这个函数就是生成器函数
# 特点:
- 生成器的本质就是迭代器,所以是可迭代的,可以使用for循环
- 函数名():不是运行函数,而是在创建生成器
- 当函数调用到 yield 时,函数都会暂停运行并保存当前的所有运行信息,然后返回 yield关键字的值,并在下一次执行 next()方法时从当前位置继续执行
- 只有调用生成器的__next__()方法/next()函数,才能触发执行生成器,执行到yield位置,函数被挂起,会返回值并且保存当前的执行状态
- next() 和 send() 函数可以恢复生成器
- 一般不用 next()方式获取元素,而是使用for循环,因为容易触发StopIteration异常
- 当使用while循环时,需要捕获 StopIteration 异常
- __next__(): 是生成器中的方法
- next(): python内置函数
# 基本概念
collections.abc.Generator:
1. 是Python 标准库中定义的一个抽象基类(Abstract Base Class),提供了一系列的生成器对象应该支持的 接口 和 行为,除了迭代器应有的__iter__()和__next__(),还扩展了send(), throw(), close() 等协程相关操作
2. 内置的生成器对象(generator iterator)就实现了这个抽象基类的(更精确地说,是其对应的内置类 <class 'generator'> 实现了该抽象基类)
# generator函数 :
简称为generator,但是为了避免和generator iterator(有时候也会被称为generator)区分开来,最好是两者都使用全称。
1. 定义起来与普通函数相似,区别在于其在函数体内使用了yield表达式
2. 被调用时,即刻返回一个genrator iterator,且不会执行函数体中的任何逻辑,只有其返回的genrator iterator的__next__()被调用时会执行,执行到下一个yield表达式时暂停执行(挂起),并将该yield表达式的值作为__next__()的返回值返回给调用者,当yield后的所有代码执行完毕后抛出StopIteration 异常。
3. 在__next__()的调用过程中,如果执行了return语句,return返回的值不会作为函数的返回值。return语句会结束生成器函数的执行,并抛出 StopIteration 异常。该异常的 value属性存储了 return后面表达式的值。正常迭代时(for循环)这个异常被迭代器捕获以结束迭代。
# generator iterator:
1. 是迭代器iterator的一种,支持 迭代协议(实现了__iter__() 和__next__())
2. generator函数被调用时所创建的对象。其内部 不预先存储 任何要生成的值,仅保存当前 执行状态(如局部变量、指令指针等)。这是其 惰性 的一个体现: 惰性存储
3. 它的存在只是为了维护的是generator函数当前的执行状态(包括局部变量、代码执行位置等),在调用__next__()时,将generator函数的代码执行到下一个yield处并返回值给调用者。这是其 惰性 的另一个体现:惰性读取
''' 普通函数 '''
def func():
print("我是普通函数")
return 123
mm = func()
print(mm)
# 输出
我是普通函数
123
''' 生成器函数 '''
def func():
print("我是生成器函数1")
yield 123
print("我是生成器函数2")
yield 456
mm = func() # 创建生成器对象<generator object func at 0x0000021BBCB72030>,不是调用函数,所以print(mm)时候没有函数中的print输出,因为此时函数没有运行
print("开始第一次调用,执行到第一个yield")
g = mm.__next__()
print(g)
print("开始第二次调用,从第一个yield后开始执行,执行到第二个yield位置")
g1 = mm.__next__() # 获取函数返回值
print(g1)
# 输出
开始第一次调用,执行到下一个yield
我是生成器函数1
123
开始第二次调用,从第一个yield后开始执行
我是生成器函数2
456
9.2.1.1、使用__next__() 和 next() 方法触发生成器
def fn1(name):
print(name)
lst = ['a', 'b', 'c']
yield lst
print('456')
yield 'aaaaaaaa'
# 创建生成器
gen = fn1('zkc') # 创建生成器对象
print(gen.__next__()) # 调用__next__方法执行生成器。输出:zkc ['a', 'b', 'c']
print(next(gen)) # 调用next()函数执行生成器。输出:456 aaaaaaaa
'''
注意:
1. 此时上面共调用执行了两次生成器
2. 第一次调用从开始执行到第一个yield位置,记录当前位置并返回结果
3. 第二次调用从第一个yield记录的位置开始,调用到第二个yield位置,记录位置并返回当前结果
4. 这两次调用 gen 生成器执行完后,此时gen生成器没有可以再迭代的内容,已经空了
5. 因为生成器是特殊的迭代器,是只能调用__next__或者next()来出发,从前往后一直执行的,不能后退
'''
print(gen.__next__()) #这时候,再调用触发生成器时,会报错StopIteration错误
for i in gen: # 此时gen生成器是空的,所以for循环不执行
print('=======', i)
9.2.1.2、使用for循环触发生成器
# 当容器中的元素很多的时候,如果全放到容器中,会特别占用内存
# 这样是一次性生成有99999个元素的列表,会占用大量的内存
my_list = []
# 1.创建列表
for i in range(99999):
my_list.append(i)
# 2.使用列表
for iters in my_list:
print(iters)
# 用生成器优化,节省很大内存
def func():
for i in range(99999):
yield i
my_iter = func() # 创建生成器
for iters in my_iter:
print(iters)
9.2.1.3、yield关键字
核心特点:
- 惰性生成值:生成器函数执行到yield时,会返回右侧的值,并暂停函数执行(保留当前上下文,如变量、执行位置)
- 恢复执行:当调用生成器的 next() 或 send() 时,函数从暂停处继续执行,直到下一个 yield 或函数结束。
# 生成器函数(含yield)
def simple_generator():
print("执行第一步")
yield 1 # 暂停,返回1
print("执行第二步")
yield 2 # 暂停,返回2
print("执行第三步")
yield 3 # 暂停,返回3
# 获取生成器对象(未执行函数体)
gen = simple_generator()
# 第一次调用next():执行到第一个yield,返回1
print(next(gen)) # 输出:执行第一步 → 1
# 第二次调用next():从暂停处继续,执行到第二个yield,返回2
print(next(gen)) # 输出:执行第二步 → 2
# 第三次调用next():继续执行到第三个yield,返回3
print(next(gen)) # 输出:执行第三步 → 3
# 第四次调用next():函数执行完毕,抛出StopIteration
# print(next(gen)) # 报错
# 可直接用for循环遍历(自动处理 StopIteration)
for val in simple_generator():
print(val) # 依次输出1、2、3,自动迭代完毕
9.2.1.4、send():生成器的双向通信
send() 是生成器从 “单向产出值” 升级为 协程(Coroutine)的核心 —— 它不仅能触发生成器恢复执行,还能向暂停的 yield 表达式传递数据,实现 生成器 ↔ 调用方的双向数据交互,即双向通信。
next()只能从生成器获取值,而send()可以向生成器传递值(同时触发生成器恢复执行),实现双向通信。
| 核心点 | 说明 |
|---|---|
send() 本质 | 向暂停的生成器传递数据 + 恢复执行,实现双向通信 |
yield 角色 | 既是 “产出值的出口”,也是 “接收 send 数据的入口”(作为表达式) |
| 交互流程 | send(value) → 给当前 yield 赋值 → 执行到下一个 yield → 返回产出值 |
| 首次调用规则 | 必须 send(None)/next(),否则报错(无暂停的 yield 接收数据) |
| 终止行为 | 无下一个 yield 时,send() 抛出 StopIteration,返回值存在异常中 |
| 状态 | 说明 |
|---|---|
| 未启动 | 生成器对象已创建,但未执行任何代码(未调用 next()/send(None)) |
| 暂停(挂起) | 执行到 yield 语句处暂停,等待外部驱动(next()/send()) |
| 运行中 | 被 next()/send() 唤醒,执行到下一个 yield 或终止 |
| 已终止 | 执行完所有代码 / 遇到 return/ 被 close() 关闭,触发 StopIteration |
# send语法:
* gen.send(value):
- 恢复生成器的执行,作用与next()等价
- value: 要传递给生成器的值(向当前暂停处的yield表达式传递一个值)
- 返回值: 生成器下一个yield抛出的值(或StopIteration)
* send(None) 和 next(gen) 的行为完全一致:
都是启动生成器,且不传递有效数据(yield 表达式返回 None)
# 注意点:
1. 生成器未启动(首次执行)时,调用 send(None) 或 next() 启动,否则报错生成器未启动
2. 首次启动时(send(None)/next()),yield表达式的返回值为 None,因为未传递有效数据
3. 后续send(value),yield 表达式的返回值为value
4. yield XXXX 是一个有返回值的表达式,这个返回值就是send()传递的参数
* send()只能传递值,不能获取返回值?
答: send()的返回值不是传入的value。send()既传递值给生成器,也会返回生成器下一个yield的值
* 后续无yield时send()的行为?
答: 若生成器恢复执行后,没有下一个yield,执行到return/函数结束,send()会直接抛出StopIteration,而非返回值
* send()的返回值是生成器函数的return值?
答: send(value)的直接返回值是生成器中下一个yield产出的值;只有当生成器没有下一个yield时,send()才会触发StopIteration,此时需从异常中取return值
* 首次调用send()可以传非None值?
答: 生成器未启动(未执行到第一个yield)时,send(value) 若value非None会报错,必须先用next(gen) 或 gen.send(None)启动
* 可以直接通过send()获取return值?
答: 必须捕获StopIteration异常,异常中的value值是生成器的return值,send()本身不会直接返回它
9.2.1.4.1、send()执行原理
通过一个简单案例说明
def simple_gen():
print("生成器启动")
# 第一个yield:产出10,暂停;等待接收值
received = yield 10
print(f"收到值: {received}")
# 第二个yield:产出20,暂停;等待接收值
another = yield 20
print(f"收到另一个值: {another}")
return "生成器结束"
# 1. 创建生成器对象(函数体未执行)
g = simple_gen()
步骤一:首次激活生成器(send(None) 或 next())
生成器刚创建时处于未启动状态,此时若直接调用 send(非None值) 会报错(因为没有暂停的 yield 接收值)。必须先用 send(None) 或 next() 启动生成器,执行到第一个 yield 处暂停:
# 方式1:next() 启动(等价于 send(None))
res1 = next(g)
# 输出:生成器启动
# res1 = 10(yield 10 产出的值)
# 方式2:send(None) 启动(与next()效果完全一致)
# res1 = g.send(None)
- 执行函数体直到第一个
yield 10 - 将
10作为next()/send(None)的返回值 - 生成器暂停在
yield 10这一行(received尚未赋值)
步骤 2:调用 send(value) 恢复并传递值
此时生成器已暂停在第一个 yield 处,调用 send(5) 会:
res2 = g.send(5)
# 输出:收到值: 5
# res2 = 20(yield 20 产出的值)
- 将
send(5)中的5赋值给yield 10这个表达式,即received = 5; - 继续执行函数体,直到下一个
yield 20; - 将
20作为send(5)的返回值; - 生成器暂停在
yield 20这一行(another尚未赋值)。
步骤 3:再次调用 send(value) 直至生成器结束
try:
res3 = g.send(8)
# 输出:收到另一个值: 8
except StopIteration as e:
print(f"生成器返回值: {e.value}") # 输出:生成器返回值: 生成器结束
- 将
8赋值给yield 20表达式,即another = 8; - 继续执行函数体,直到
return语句; - 生成器抛出
StopIteration异常,异常的value属性为返回值; - 若此时再调用
send()/next(),会直接抛出StopIteration(无返回值)。
9.2.1.4.2、用send()给生成器传值
def coroutine_demo():
print("生成器启动")
# 首次执行到此处,暂停并返回"等待接收值";恢复时,x接收send()传递的值
x = yield "等待接收值"
print(f"收到第一个值:{x}")
# 再次暂停,返回x*2;恢复时,y接收下一个send()的值
y = yield x * 2
print(f"收到第二个值:{y}")
# 再次暂停,返回y+10;恢复时,z接收下一个send()的值
z = yield y + 10
print(f"收到第三个值:{z}")
yield z - 10 # 最后一次暂停,返回z-10, 此时生成器空闲,下一次调用send()会抛出StopIteration异常
return "生成器结束"
# 1. 创建生成器对象
gen = coroutine_demo()
# 2. 首次启动:必须send(None) 或 next()
# 等价于next(gen)、gen.__next__()
res1 = gen.send(None) # 输出:生成器启动,等待接收值
print(res1) # send的返回值是第一个yield "等待接收值"表达式的值
# 3. 向暂停的yield表达式中传递值10,10成为yield "等待接收值"表达式的返回值,赋值给x,生成器恢复执行,执行到下一个yield,暂停并返回 x*2 的值
res2 = gen.send(10) # 输出: 收到第一个值:10
print("yield x * 2表达式的值: ", res2) # send的返回值是下一个yield x * 2表达式的值
# 4. 向暂停的yield表达式中传递值20,20成为yield x * 2表达式的返回值,赋值给y,生成器恢复执行,执行到下一个yield,暂停并返回 y+10 的值
res3 = gen.send(20) # 输出:收到第二个值:20
print("yield y + 10表达式的值: ", res3) # send的返回值是下一个yield y + 10表达式的值
# 5. 向暂停的yield表达式中传递值30,30成为yield y + 10表达式的返回值,赋值给z,生成器恢复执行,执行到下一个yield,暂停并返回 z-10 的值
res3 = gen.send(30) # 输出:收到第三个值:30
print("yield z - 10表达式的值", res3) # send的返回值是下一个yield z - 10表达式的值
# 6. 继续调用:生成器执行完毕,抛出StopIteration
try:
# gen.send(40) # 再次send()会抛出StopIteration异常,
next(gen)
except StopIteration as e:
print(f"函数返回值: {e.value}") # 输出:函数返回值: 生成器结束
"""
第一步:print(f.__next__())
调用 __next__():生成器开始执行,直到yield b暂停。
执行流程:
n=0<5,进入循环
执行 temp = yield b:先返回 b=1(打印结果为 1),生成器暂停;
注意:yield 暂停后,print(temp) 及后续代码未执行,temp 此时无值(为 None)。
控制台输出:1
第二步:print(f.send("Super Man 超人"))
send() 作用:
向暂停的 yield b 传递值 "Super Man 超人",该值成为 yield b 的返回值,赋值给 temp;
恢复生成器执行,从 print(temp) 开始。
执行流程:
temp = "Super Man 超人",执行 print(temp) → 控制台输出 "Super Man 超人";
执行 a, b = b, a+b → a=1, b=0+1=1;
n += 1 → n=1;
回到循环,n=1 < 5,执行 temp = yield b → 返回 b=1(打印结果为 1),生成器暂停。
控制台输出:
Super Man 超人
1
第三步:print(f.send("lron Man 钢铁侠"))
执行流程:
temp = "lron Man 钢铁侠",执行 print(temp) → 控制台输出 "lron Man 钢铁侠";
执行 a, b = b, a+b → a=1, b=1+1=2;
n += 1 → n=2;
回到循环,n=2 < 5,执行 temp = yield b → 返回 b=2(打印结果为 2),生成器暂停。
控制台输出:
lron Man 钢铁侠
2
"""
def fib(times):
n = 0
a, b = 0, 1
while n < times:
temp = yield b # 先yield暂停并返回b;恢复时接收send的值并赋值给temp
print(temp) # 打印接收到的send值(首次__next__时temp为None)
a, b = b, a + b
n += 1
f = fib(5)
print(f.__next__()) # 调用 __next__ 打印值 等价于 # print(next(f)) 、print(f.send(None))
print(f.send("Super Man 超人")) # 使用send()方法传入值
print(f.send("lron Man 钢铁侠"))
# 如果继续执行:
# print(f.__next__()) # 无传入值,temp=None,打印None,返回3
# print(f.__next__()) # temp=None,打印None,返回5
def counter():
count = 0
step = 1 # 默认步长
while True:
# 暂停并返回当前count;恢复时接收新的步长
new_step = yield count
# 如果传递了新步长,就更新
if new_step is not None:
step = new_step
count += step
# 初始化生成器
gen = counter()
# 启动
print(next(gen)) # 启动生成器,进入while循环,暂停在yield处,返回count=0
# 动态调整步长
print(gen.send(2)) # 生成器恢复执行,yield count表达式值为2,赋值给new_step,count更新为0+2,步长变为2,再次进入循环,暂停在yield处,返回count=2
print(gen.send(3)) # 生成器恢复执行,yield count表达式值为3,赋值给new_step,count更新为2+3,步长变为3,再次进入循环,暂停在yield处,返回count=5
print(gen.send(1)) # 生成器恢复执行,yield count表达式值为1,赋值给new_step,count更新为5+1,步长变为1,再次进入循环,暂停在yield处,返回count=6
# 消息处理器(生产者 - 消费者模型)
# 生成器作为「消费者」,通过 send() 接收「生产者」发送的消息,按类型分支处理(普通消息 / 错误消息 / 退出信号)。
def message_processor():
print("✅ 消息处理器启动")
while True:
# 仅接收消息,无初始返回值
msg = yield
if msg is None: # 退出信号
print("❌ 消息处理器退出")
break
# 分支处理不同类型消息
if isinstance(msg, str):
if msg.startswith("[ERROR]"):
print(f"⚠️ 处理错误消息: {msg}")
else:
print(f"📩 处理普通消息: {msg}")
else:
print(f"❓ 不支持的消息类型: {type(msg)}")
# 使用示例
processor = message_processor()
next(processor) # 启动生成器,执行到yield处暂停
# 发送不同类型消息
processor.send("用户ID:123 登录成功")
processor.send("[ERROR]数据库连接超时")
processor.send(12345) # 非字符串类型
processor.send(None) # 发送退出信号
9.2.1.5、生成器函数返回值
| 特性 | 普通函数 | 生成器函数 |
|---|---|---|
return val 行为 | 直接返回 val 给调用者 | 抛出 StopIteration,val 存入 e.value |
无 return 时 | 返回 None | 抛出 StopIteration,e.value 为 None |
| 执行时机 | 函数执行到 return 立即返回 | 生成器迭代完毕(无更多 yield)时触发 |
1. 生成器函数中,return value不会直接返回值,而是在生成器终止时触发StopIteration异常,且异常对象的value属性会保存该返回值
2. 普通生成器函数,若未显式return,终止时也会触发StopIteration,但value为 None
3. 只有当生成器执行完所有代码或遇到return时,才会抛出StopIteration,在此之前无法直接获取返回值
4. 生成器函数的return不是"返回值给调用方",而是"标记生成器终止,并将值存入 StopIteration 异常",必须通过捕获该异常才能获取
5. 调用coro.send(value),生成器恢复执行:
- 若有未执行的yield: 将value赋值给yield左侧变量 → 执行到下一个yield并产出值
- 若无未执行的yield: 触发return→ 抛出StopIteration,value为return的值
9.2.1.5.1、普通生成器函数的返回值
def gen_func():
yield 1
yield 2
return "生成器执行完毕" # 返回值封装到StopIteration
# 方式1:通过迭代捕获(迭代终止时触发StopIteration)
gen = gen_func()
next(gen) # 取1
next(gen) # 取2
# 迭代结束后,手动触发StopIteration(若需获取返回值)
try:
next(gen)
except StopIteration as e:
print("返回值:", e.value) # 输出:返回值:生成器执行完毕
# 方式2:直接通过send/next触发终止
gen2 = gen_func()
next(gen2) # 取1
next(gen2) # 取2
try:
gen2.send(None) # 无更多yield,触发return
except StopIteration as e:
print("返回值:", e.value) # 输出:返回值:生成器执行完毕
9.2.1.5.2、send() 触发生成器返回值
def coro_func():
x = yield "第一步:等待接收值" # 暂停1:产出提示,等待send值
print(f"接收send值:{x}")
y = yield f"第二步:已接收{x},等待下一个值" # 暂停2:产出结果,等待send值
print(f"接收send值:{y}")
return f"最终返回:x={x}, y={y}" # 无更多yield,send会触发return
# 1. 启动协程(执行到第一个yield暂停)
coro = coro_func()
print(next(coro)) # 输出:第一步:等待接收值
# 2. 第一次send:传递值到x,执行到第二个yield并产出值
print(coro.send(10)) # 输出:接收send值:10 → 第二步:已接收10,等待下一个值
# 3. 第二次send:传递值到y,无更多yield,触发return → 抛出StopIteration
try:
coro.send(20) # 输出:接收send值:20
except StopIteration as e:
print("生成器返回值:", e.value) # 输出:生成器返回值:最终返回:x=10, y=20
9.2.1.6、yield from+send()双向通信
yield from 本质是生成器委托(Generator Delegation),它把外层生成器的 “迭代、通信、异常处理” 全部委托给内层生成器,解决了手动嵌套 yield 的繁琐问题
# 用于简化嵌套生成器的迭代,核心作用是:
1. 将外层生成器的迭代控制权"委托"给内层生成器;
2. 自动处理内层生成器的StopIteration;
3. 支持内层与外层生成器的双向通信(结合 send())
yield from 后面的对象必须是可迭代对象(生成器、列表、迭代器等)
* yield from x 等价于 for val in x: yield val吗?
答: 仅对"单向迭代"等价;对"双向通信、返回值、异常处理"不等价,yield from更强大
9.2.1.6.1、简单案例:代理内层生成器
如果直接用 yield 遍历内层生成器,需要手动循环;yield from 可直接代理
# 内层生成器
def inner_generator():
yield 1
yield 2
yield 3
# 外层生成器(用yield from代理内层)
def outer_generator():
print("外层开始")
yield from inner_generator() # 代理内层生成器的所有yield
print("外层结束")
yield 4
# 迭代外层生成器
for val in outer_generator():
print(val)
9.2.1.6.2、简单案例:简化嵌套迭代
# 手动yield(繁琐)
def outer_manual():
for val in [1,2,3]:
yield val
for val in [4,5,6]:
yield val
# yield from(简洁)
def outer_delegate():
yield from [1,2,3]
yield from [4,5,6]
# 效果一致
print(list(outer_manual())) # [1,2,3,4,5,6]
print(list(outer_delegate())) # [1,2,3,4,5,6]
9.2.1.6.3、简单案例:自动转发 send () 数据
yield from 会自动将外层 send() 的值传递给内层生成器,也会将内层的返回值传递给外层
# 动态调整步长的数字生成器
# 内层生成器(接收步长)
def inner_counter():
count = 0
while True:
step = yield count
count += step if step else 1
# 外层生成器(委托内层)
def outer_counter():
print("外层启动")
yield from inner_counter() # 代理内层的所有通信
print("外层结束")
gen = outer_counter()
next(gen) # 启动外层生成器
print(gen.send(2)) # 步长2 → 0+2=2(值透传给inner)
print(gen.send(3)) # 步长3 → 2+3=5(值透传给inner)
# 基础累加器(接收外部值并计算)
# 生成器维护一个累加值,通过 send() 发送数值实现动态累加,发送 None 终止
def sub_coroutine():
total = 0
while True:
n = yield total # 接收传入的值,并返回累计总和
if n is None:
break
total += n
return total
def delegate_coroutine():
res = yield from sub_coroutine()
print("子生成器返回值: ", res)
return f"委托协程结束, 总和: {res}"
if __name__ == '__main__':
gen = delegate_coroutine()
gen.send(None) # 启动协程, 执行到第一个yield,暂停,等待send值
print(gen.send(5)) # 恢复执行,从第一次循环的yield处继续,把yield 5的返回值5赋值给n。total=5,然后进入下次循环的yield处暂停
print(gen.send(10)) # 恢复执行,从第二次循环的yield处继续,把yield 10的返回值10赋值给n。total=5+10,然后进入下次循环的yield处暂停
# 发送None终止子生成器,触发返回值
try:
gen.send(None)
except StopIteration as e:
print(f"最终结果:{e.value}") # 输出:最终结果:委托协程结束,总和:15
def inner_coroutine():
x = yield "内层等待接收值"
yield f"内层收到:{x}"
y = yield "内层再次等待"
yield f"内层收到:{y}"
def outer_coroutine():
print("外层启动")
# 代理内层协程的通信
yield from inner_coroutine()
print("外层结束")
gen = outer_coroutine()
# 首次启动生成器
print(gen.send(None)) # 输出:外层启动 \n 内层等待接收值
# 传递值10给内层
res1 = gen.send(10) # yield "内层等待接收值"表达式的值为10,赋值给x,生成器恢复执行,执行下一行代码
print(res1) # 输出yield的值:内层收到:10,然后暂停,等待下次send()传递值
# 传递值20给内层
res2 = gen.send(20) # 从 yield 内层收到:10 继续执行,执行到 yield "内层再次等待",返回"内层再次等待"并暂停
print(res2)# 输出:内层再次等待,等待下次send()传递值
# # 传递值30给内层
res3 = gen.send(30) # yield "内层再次等待"表达式的值为30,赋值给y,生成器恢复执行,执行下一行代码
print(res3)# 输出yield的值:内层收到:30
gen.close() # 关闭生成器
9.2.1.6.4、简单案例:自动处理 StopIteration
def inner():
yield 1
yield 2 # 结束后抛StopIteration
# 手动处理(需捕获异常),不手动捕获异常会报错StopIteration
def outer_manual():
g = inner()
while True:
try:
yield next(g)
except StopIteration:
break
yield 3
# yield from(自动处理)
def outer_delegate():
yield from inner()
yield 3
# 效果一致
print(list(outer_manual())) # [1,2,3]
print(list(outer_delegate())) # [1,2,3]
9.2.1.6.5、高级用法:获取内层子生成器的返回值
def inner():
yield 1
yield 2
return "内层执行完毕,总计2个值" # 返回值会被StopIteration携带,StopIteration: 内层执行完毕,总计2个值
def outer():
# 捕获内层的返回值
ret = yield from inner()
print(f"外层收到内层返回值:{ret}")
yield 3
gen = outer()
print(next(gen)) # 1
print(next(gen)) # 2
print(next(gen)) # 外层收到内层返回值:内层执行完毕,总计2个值 \n 返回outer的yield返回值3
def sub_coro():
yield 10
yield 20
return "子生成器返回值"
def main_coro():
# yield from 自动捕获sub_coro的StopIteration,将value赋值给res
res = yield from sub_coro()
print("main_coro接收子生成器返回值:", res) # 输出:main_coro接收子生成器返回值:子生成器返回值
return f"main_coro最终返回:{res}"
coro = main_coro()
next(coro) # 启动
coro.send(None) # 执行子生成器到return
try:
coro.send(None) # 执行main_coro的return
except StopIteration as e:
print("最终返回值:", e.value) # 输出:最终返回值:main_coro最终返回:子生成器返回值
send() + yield 的组合常用于双向通信的生成器(生成器既产出值,也接收外部输入)
def counter():
count = 0
while True:
# 接收外部指令:重置/加1
cmd = yield count
if cmd == "reset":
count = 0
else:
count += 1
g = counter()
print(next(g)) # 启动,返回0
print(g.send(None)) # 无指令,count+1 → 1
print(g.send("reset")) # 重置,count=0 → 返回0
print(g.send(None)) # count+1 → 1
9.2.1.7、throw()
用于主动向生成器注入异常 ,是生成器 “可控生命周期管理” 的关键
# 语法:
gen.throw(type[, value[, traceback]])
# 核心作用
在生成器暂停的 yield 表达式处抛出指定异常,触发生成器内部的异常处理逻辑;若生成器未捕获该异常,异常会向上冒泡到调用方
# 底层逻辑
1. 生成器从暂停的 yield 处恢复执行
2. 在该 yield 表达式位置抛出指定异常
3. 若生成器捕获并处理了异常,会继续执行到下一个 yield,返回其值
4. 若未捕获,异常会抛到调用方,生成器进入"终止状态"
# 注意点
1. 若生成器未启动(未调用next()/send(None)),调用throw()会直接抛异常(无暂停的yield可注入)
2. 注入的异常若被生成器捕获,生成器可继续执行;若未捕获,生成器终止,异常抛给调用方
3. throw()的返回值: 生成器处理异常后,下一个yield抛出的值(若有)
9.2.1.7.1、生成器内部捕获throw() 注入的异常
"""
throw()在生成器暂停的yield 1位置注入了ValueError,生成器直接进入except块处理异常,跳过了后续的yield 2/yield 3执行逻辑
"""
def generator_demo():
try:
yield 1
yield 2
yield 3
except ValueError as e:
print(f"生成器内部捕获ValueError:{e}")
yield "异常处理后继续"
finally:
print("生成器执行finally(清理资源)")
# 1. 创建生成器并启动
gen = generator_demo()
print(next(gen)) # 启动生成器,开始执行,执行到第一个yield。返回第一个yield值,并且暂停。输出:1
# 2. 向暂停的第一个yield处注入ValueError
res = gen.throw(ValueError, "手动注入的值错误")
print(res) # 输出:生成器内部捕获ValueError:手动注入的值错误,继续往下执行到yield "异常处理后继续",返回"异常处理后继续"并暂停
# 3. 继续迭代(执行finally)
try:
next(gen) # 继续从yield "异常处理后继续"恢复往下执行,但是后面没有yield了,所以进入finally块执行其中代码
except StopIteration:
pass
# 输出:生成器执行finally(清理资源)
# 捕获TypeError异常
def catch_exception_gen():
try:
yield "初始值" # 暂停点:第一次next()会停在此处
except TypeError as e:
print(f"生成器内部捕获异常:{e}")
yield "异常处理后返回值" # 处理异常后继续返回值
# 1. 创建生成器对象
gen = catch_exception_gen()
# 2. 启动生成器(执行到第一个yield,返回初始值)
first_val = next(gen)
print("第一次调用next:", first_val) # 输出:第一次调用next:初始值
# 3. 向暂停的yield处注入TypeError
second_val = gen.throw(TypeError, "手动注入的类型错误") # 输出:生成器内部捕获异常:手动注入的类型错误
print("调用throw后返回值:", second_val) # 继续往下执行到yield "异常处理后返回值",返回"异常处理后返回值"并暂停
# 4. 继续调用next(),生成器执行完毕(无更多yield)
try:
next(gen)
except StopIteration:
print("生成器执行完毕")
9.2.1.7.2、生成器未捕获throw() 注入的异常
# 无异常捕获逻辑
def no_catch_exception_gen():
yield "初始值" # 暂停点:第一次next()会停在此处
yield "后续值" # 因异常,这行永远不会执行
# 1. 创建生成器对象
gen = no_catch_exception_gen()
# 2. 启动生成器(执行到第一个yield,返回初始值)
first_val = next(gen)
print("第一次调用next:", first_val) # 输出:第一次调用next:初始值
# 3. 向暂停的yield处注入ValueError(生成器无处理逻辑)
try: # 这里tyr/except的作用是,如果在生成器中未捕获异常,则异常会向上抛给调用者
gen.throw(ValueError, "手动注入的值错误")
except ValueError as e:
print(f"调用方捕获异常:{e}") # 输出:调用方捕获异常:手动注入的值错误
# 4. 生成器已终止,后续调用直接抛StopIteration
try:
next(gen)
except StopIteration:
print("生成器已终止")
9.2.1.8、close()
用于优雅终止生成器 ,是生成器 “可控生命周期管理” 的关键
# 核心作用:
用于主动终止生成器
# 本质:
向生成器暂停的yield处注入GeneratorExit异常:
1. 生成器可捕获GeneratorExit做资源清理(如关闭文件、释放连接)
2. 生成器不能向调用方返回新值,捕获GeneratorExit后若继续yield,会抛RuntimeError
3. 调用close()后,生成器进入"终止状态",后续调用next()/send()会直接抛 StopIteration
# 底层逻辑:
1. 若生成器未启动: 直接终止,无操作
2. 若生成器已暂停: 在暂停的yield处抛出GeneratorExit
3. 生成器执行finally块(若有),完成资源清理
3. 生成器终止,后续调用无响应
# 注意:
1. GeneratorExit是特殊异常,生成器可捕获但不可抛出(手动raise GeneratorExit 会报错)
2. 捕获GeneratorExit后,若生成器继续yield,会抛RuntimeError
3. 多次调用close()无副作用,生成器终止后,重复close()不会报错
4. Python解释器的自动资源回收机制
* 当脚本执行完所有代码(gen.send()之后无更多代码),Python 解释器会退出并自动清理资源
* 此时生成器对象gen被垃圾回收(GC),Python会隐式调用gen.close(),进而触发GeneratorExit异常
# 为什么close()不是必须显式写?
1. 垃圾回收(GC)触发
当生成器对象失去所有引用,如脚本执行完毕、变量被赋值为None、函数作用域结束,Python的垃圾回收机制会自动回收生成器,回收时会隐式调用gen.close(),进而触发GeneratorExit异常和资源清理逻辑。
比如下面例子:
如果不加try/finally,也没有显式close,脚本执行完gen.send("第二行内容")后无后续代码,gen失去引用→GC回收→隐式close()→输出except/finally内容。
2. 解释器退出触发
当Python解释器整体退出,如脚本运行完毕、手动关闭终端,会遍历所有未销毁的生成器,强制调用close(),确保文件、网络连接等资源被释放
# 为什么推荐显式写close()?
close()是"可选但推荐"——显式调用让资源释放"看得见、控得住"
def file_generator(file_path):
f = open(file_path, "w", encoding="utf-8")
try:
while True:
content = yield
f.write(content + "\n")
except GeneratorExit:
print("捕获GeneratorExit,关闭文件")
f.close() # 清理资源
finally:
print("finally执行:确认文件关闭")
# 1. 创建并启动生成器
gen = file_generator("text.txt")
next(gen)
# 2. 向生成器发送内容(写入文件)
"""
注意,这里有个问题,在写入第二行内容之后,还没有调用close方法,但生成器也执行了except和finally模块,这是为啥?
因为Python解释器退出前的自动清理,对生成器对象,Python会自动调用gen.close(),这是解释器的默认行为,目的是确保资源释放
"""
try:
gen.send("第一行内容")
gen.send("第二行内容")
finally:
# 3. 主动终止生成器(触发GeneratorExit)
gen.close() # 输出:捕获GeneratorExit,关闭文件 -> finally执行:确认文件关闭
# 4. 终止后调用send()
# gen.send("第三行内容") # 报错,直接抛StopIteration
9.2.2、生成器表达式
- 列表推导式中的 [] 换成 () 就会变成一个生成器
- 生成器表达式 和 列表推导式 区别
- 列表推导式:会将列表中的所有元素都创建出来放到内存中,元素很多时,会占用内存
- 生成器表达式:只在内存中存了创建生成器的代码,当需要取数据进行for循环时,才进行一个一个迭代获取。节省内存
# 列表推导式
lst = [x + 1 for x in range(10) if x % 2 == 0]
# 生成器表达式,
# 将推导式的[] 换成(), 会创建一个生成器对象, 再用for循环迭代
# 其实没有元组推导式,因为元组中的数据是不允许变化的
# (x for i in range(10) if x % 2 == 0) 其实不是元组推导式,而是生成器表达式
my_gen = (x + 1 for x in range(10) if x % 2 == 0)
9.2.3、面试题
def func():
print("111")
yield 222
g = func() # 生成器
g1 = (i for i in g) # 生成器
g2 = (i for i in g1) # 生成器
'''
以上代码只是定义生成器,还没有开始调用执行生成器,所以在此时print(g)是没有任何输出,生成器有惰性机制,生成器只有在调用/触发的时候才会执行函数
'''
# list()函数中有for方法,所以list(g)开始调用生成器
'''
以下调用,不管调用顺序怎么变,为什么输出结果顺序不变?
因为生成器是从前往后一个方向执行的,不能向后执行
比如,第一次打印list(g2), 此时开始触发调用生成器g2,根据上面g2生成器代码,会先循环g1,此时触发g1生成器,
'''
print(list(g)) #开始调用g生成器,从生成器g中通过for循环取数据,取出来后生成列表[2, 2, 2],直到取完数据
print(list(g1)) # 开始调用g1生成器,从生成器g中通过for循环取数据,但是g中数据已经在上步取完了,所以g是空的,所以g1生成了一个空列表
print(list(g2)) # 开始调用g2生成器,从生成器g1中通过for循环取数据,但是g1是个空列表,所以g2也生成了一个空列表
# 输出
111
[2, 2, 2]
[]
[]
9.3、场景案例
9.3.1、生成器案例
9.3.1.1、处理大文件(逐行读取,避免加载整个文件到内存)
# 大文件逐行读取
# 处理 GB 级大文件时,readlines() 会一次性加载所有行到内存,生成器则逐行读取,内存占用极低
# 无论文件多大,内存占用始终保持在一行数据的大小,避免 OOM(内存溢出)
def read_large_file(file_path, encoding='utf-8'):
"""逐行读取大文件(生成器函数)"""
with open(file_path, 'r', encoding=encoding, errors='ignore') as f:
for line in f: # 文件对象本身是可迭代的,天然支持惰性读取
yield line.strip() # 去除换行符,返回当前行
# 用法:迭代读取,处理每行数据
file_path = "large_file.txt" # 可替换为你的大文件路径
for line in read_large_file(file_path):
# 处理逻辑(如解析日志、统计关键词等)
if "error" in line.lower():
print(f"错误日志:{line}")
current_path = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(current_path, "demo.txt")
def file_gen(file_url):
with open(file_url, "r", encoding="utf-8") as f:
while True:
line = f.readline()
if not line:
# time.sleep(0.1) # 短暂休眠,避免cpu占用过高
break # 如果要实时监控文件内容,模拟tail -f,改成continue,并在前面加time.sleep(0.1)
yield line.strip()
if __name__ == '__main__':
file_g = file_gen(file_path)
for i in file_g:
print(i)
9.3.1.2、多个文件读取的生成器
# 实现一个生成器,能够按行读取多个文件,就像它们是单个文件一样
current_path = os.path.dirname(os.path.abspath(__file__))
file_path1 = os.path.join(current_path, "demo.txt")
file_path2 = os.path.join(current_path, "demo1.txt")
# 第一种写法:
current_path = os.path.dirname(os.path.abspath(__file__))
def multi_file_gen(*file_urls):
for file_url in file_urls:
# 先校验文件存在性
if not os.path.exists(file_url):
print(f"警告:文件 {file_url} 不存在,跳过")
continue
# 校验是否是文件(避免路径是目录)
if not os.path.isfile(file_url):
print(f"警告:{file_url} 不是文件,跳过")
continue
try:
with open(file_url, "r", encoding="utf-8") as file:
while True: # 可直接使用for循环,自动判断是否到最后一行
line = file.readline()
if not line:
break
yield line.strip()
except FileNotFoundError:
print(f"文件 {file_url} 不存在,跳过")
except PermissionError:
print(f"无权限读取 {file_url},跳过")
except Exception as e:
print(f"读取 {file_url} 出错:{e},跳过")
def multi_file():
yield from multi_file_gen(file_path1, file_path2)
if __name__ == '__main__':
file_path1 = os.path.join(current_path, "demo.txt")
file_path2 = os.path.join(current_path, "demo1.txt")
file_g = multi_file()
for text in file_g:
stripped_text = text.strip()
if stripped_text: # 仅输出非空内容
print(stripped_text)
# 第二种写法:
"""
直接将文件对象委托给yield from是Python中优雅且高效的多文件逐行迭代方式
文件对象(open() 返回的 _io.TextIOWrapper)本身是可迭代对象,迭代时会逐行返回文件内容(每行包含末尾的换行符\n)
"""
current_path = os.path.dirname(os.path.abspath(__file__))
def multi_file_gen(*file_urls):
for file_url in file_urls:
# 先校验文件存在性
if not os.path.exists(file_url):
print(f"警告:文件 {file_url} 不存在,跳过")
continue
# 校验是否是文件(避免路径是目录)
if not os.path.isfile(file_url):
print(f"警告:{file_url} 不是文件,跳过")
continue
try:
with open(file_url, "r", encoding="utf-8") as file:
yield from file
except FileNotFoundError:
print(f"文件 {file_url} 不存在,跳过")
except PermissionError:
print(f"无权限读取 {file_url},跳过")
except Exception as e:
print(f"读取 {file_url} 出错:{e},跳过")
if __name__ == '__main__':
file_path1 = os.path.join(current_path, "demo.txt")
file_path2 = os.path.join(current_path, "demo1.txt")
file_g = multi_file_gen(file_path1, file_path2)
for text in file_g:
stripped_text = text.strip()
if stripped_text: # 仅输出非空内容
print(stripped_text)
简化复杂迭代逻辑(如多步骤数据处理流水线)
def data_pipeline(data):
# 第一步:过滤
filtered = (x for x in data if x > 0)
# 第二步:转换
transformed = (x*2 for x in filtered)
# 第三步:返回结果
yield from transformed # 简化生成器嵌套
for res in data_pipeline([-1, 2, -3, 4]):
print(res) # 4、8(2*2=4,4*2=8)
9.3.1.3、基于可迭代对象和生成器实现:自定义range
class Xrange(object):
def __init__(self, num):
self.__num = num
def __iter__(self):
count = 0
while count < self.__num:
yield count
count += 1
obj1 = Xrange(10)
for i in obj1:
print(i)
9.3.2、迭代器案例
9.3.2.1、处理100万条用户数据的CSV文件
# 错误方式(列表推导式)
# 一次性加载所有数据到内存
all_users = [line.strip().split(',') for line in open('users.csv')] # 内存爆炸
# 正确方式(生成器):
def load_users(file_path):
with open(file_path) as f:
for line in f:
yield line.strip().split(',')
# 按需处理数据
user_gen = load_users('users.csv')
for user in user_gen:
if user[2] == 'VIP': # 筛选VIP用户
send_promotion(user)
9.3.2.2、处理大型数据集
读取大文件时,通过迭代器逐行读取(非一次性加载整个文件),减少内存占用
class LogFileIterator:
def __init__(self, file_path):
self.file_path = file_path
self.file_obj = None
def __iter__(self):
# 打开文件并返回迭代器自身
self.file_obj = open(self.file_path, "r", encoding="utf-8")
return self
def __next__(self):
if self.file_obj is None:
raise StopIteration("File not opened")
# 读取下一行,文件结束时抛出 StopIteration
line = self.file_obj.readline()
if not line:
self.file_obj.close() # 关闭文件
raise StopIteration
return line.strip() # 去除行尾换行符
ger = LogFileIterator('00.iree.json')
for i in ger:
print(i)
9.3.2.3、基于可迭代对象和迭代器实现:自定义range
class IterObject(object):
def __init__(self, num):
self.__num = num
self.__count = -1
def __iter__(self):
return self
def __next__(self):
self.__count += 1
if self.__count >= self.__num:
raise StopIteration
return self.__count
class Xrange(object):
def __init__(self, max_num):
self.__max_num = max_num
def __iter__(self):
return IterObject(self.__max_num)
obj = Xrange(10)
for i in obj:
print(i)
9.4、迭代器和生成器区别
# 迭代器:
* 定义:
迭代器是实现了迭代协议(__iter__()和__next__()方法)的对象,用于逐个访问集合元素。
* 实现:
需显式定义类并实现协议方法,例如遍历列表的自定义迭代器类。
# 生成器
* 定义:
生成器是通过函数和yield关键字实现的特殊迭代器,无需手动定义类。
* 实现:
函数执行到yield时暂停并返回值,下次调用从暂停处继续。
# 核心特性对比:
* 内存效率:
生成器天然支持惰性求值,每次仅生成一个值,适合处理无限序列或大文件;迭代器若需预加载数据则内存占用较高。
* 代码复杂度:
生成器代码更简洁(如斐波那契数列生成),而迭代器适合需复杂状态管理的场景。
* 单向性:两者均只能向前遍历,不可回退
| 维度 | 迭代器(Iterator) | 生成器(Generator) |
|---|---|---|
| 实现方式 | 需手动定义__iter__()和__next__() | 用 yield 函数或生成器表达式,无需手动实现迭代方法 |
| 状态管理 | 需手动维护迭代状态(如current变量) | 自动保存函数内部状态(无需手动处理) |
| 代码复杂度 | 较高(需处理StopIteration) | 极低(无需手动处理异常) |
| 内存效率 | 惰性计算(较高效) | 惰性计算(同样高效,且更轻量) |
| 适用场景 | 自定义容器迭代逻辑 | 简化迭代逻辑、处理大数据 / 流数据 |
10、python 自省机制
- 自省(Introspection)是指程序在运行时能够检查自身对象的类型、属性、方法等信息的能力
- Python是一门高度自省的语言,几乎所有对象都可以在运行时被检查和动态操作
# 常用的自省函数
dir(obj): 返回对象的所有属性和方法名(列表)
id(obj): 返回对象的唯一标识(内存地址,整数)
type(obj): 返回对象的类型
help(obj): 显示对象的帮助文档
isinstance(obj, cls): 判断对象是否是某个类或其子类的实例
hasattr(obj, name): 判断对象是否有某个属性/方法
getattr(obj, name): 获取对象的某个属性/方法
callable(obj): 判断对象是否可调用(如函数、方法、类等)
class Demo:
def foo(self):
pass
obj = Demo()
print(dir(obj)) # 查看所有属性和方法
print(type(obj)) # <class '__main__.Demo'>
print(isinstance(obj, Demo)) # True
print(hasattr(obj, 'foo')) # True
print(callable(getattr(obj, 'foo', None))) # True
print(id(obj)) # 对象的唯一标识
help(obj) # 查看帮助文档
class MyClass:
def __init__(self):
self.attribute = "value"
obj = MyClass()
print(getattr(obj, 'attribute')) # 输出: value
print(hasattr(obj, 'attribute')) # 输出: True
三、面向对象编程
1、面向对象编程中的基本概念
* 类: 具有相同的属性和方法的事物的集合,是抽象的,不能直接使用
* 方法: 定义在类内部的函数,用于描述对象的行为
* 类对象: 类定义完之后就是类对象,可以对类的属性和方法直接访问
* 实例对象: 一个类可以实例化出的具体对象
* 实例化: 创建对象的过程,一个类的具体实例对象
* 类变量: 定义在类中且在函数体之外,在整个实例化对象中是公用的。类变量通常不作为实例变量使用,用于类所有实例共享的属性
* 实例变量: 定义在方法中用构造方法初始化的属性,只作用于当前实例的类,对每个实例都是唯一的数据
* 继承: 子类继承父类的属性和方法,可以重用父类的属性和方法
* 封装: 将属性和方法封装在一个独立的对象,对外部隐藏对象的工作细节
* 多态: 可以对不同类的对象调用相同的方法,从而实现相同的操作,产生不同的结果
* 方法重用: 指的是通过类的继承、组合和模块化等技术,使得代码可被多个不同的程序或不同的部分重复使用,从而减少代码重复,提升开发效率和代码的可维护性
* 方法重写: 如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程也叫方法的覆盖
2、抽象基类(abc模块,也称 “元类”)
* 抽象基类(abstract base class,ABC):抽象基类就是类里定义了纯虚成员函数的类。纯虚函数只提供了接口,并没有具体实现。
* 抽象基类不能被实例化(不能创建对象),通常是作为基类供子类继承,子类中重写虚函数,实现具体的接口。
* 抽象基类就是定义各种方法而不做具体实现的类,任何继承自抽象基类的类必须实现这些方法,否则无法实例化。
"""
@abstractmethod 装饰的抽象方法,在子类必须要重写
"""
from abc import ABCMeta, abstractmethod
class CacheBase(object, metaclass=ABCMeta):
@abstractmethod
def get(self,key):
pass
@abstractmethod
def set(self,key,value):
pass
class RedisCache(CacheBase):
def get(self,key):
pass
def set(self,key,value):
pass
r = RedisCache()
r.get('zkc')
class Foo:
def A(self):
# 告诉子类应该重写该方法,子类直接调用父类该方法会报错
raise NotImplementedError("sub class must override this method.")
class Bar(Foo):
def A(self):
print("重写了父类的方法")
b = Bar()
b.A()
3、类和对象
图3.0
# 什么是对象?
- 对象是内存中用来存储任意数据的一块区域
- 对象由三部分组成:
1. 对象标识(id)
2. 对象类型(type)
3. 对象的值(value)
4. 引用计数(refcount)
# 面向对象(oop)
- 面向对象编程: 语言中的所有操作都是通过一个个对象来进行的
- 面向过程编程: 将程序逻辑分解为一个个步骤,通过对每个步骤的抽象,来完成程序
# 面向对象编程和面向过程编程的区别:
- 面向过程语言: 分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候再依次调用,类似流水线的工作原理。
- 面向对象语言: 把构成问题事务分解成各个对象,依靠各个对象之间的交互推动程序执行,进而实现问题的解决。建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在完整解决问题步骤中的行为。
# 喝可乐
* 面向过程:
我-起床-走到冰箱前-打开冰箱门-拿出可乐-关闭冰箱门-喝可乐
* 面向对象
我-创建对象-命令对象打开冰箱拿出可乐再关闭冰箱后给我-喝可乐
让对象去干活,我负责创建可以干活的对象,然后命令对象去干活,不关心对象干活的过程
- 类和对象都是生活中事物或者程序中内容的抽象
* 类和对象:
1. 类: 对事物的抽象,如球类
2. 对象: 是事物的实例,如足球
- 类: 是对一群具有相同"特征"或"行为"的事物的一个抽象的模板,不能直接使用
1. 特征: 属性
2. 行为: 方法
- 对象: 由类创建出来的一个具体的实例,可以直接使用
- 由哪一个类创建出来的对象,就拥有在哪个类中定义的"属性"和"方法"
3.1、 类的定义
图3.1

# 上图中,p1 和 p2 是两个实例化对象,Person是类对象
p1和p2中没有name属性
1. 如图3.0,当使用a=p1.name 时,从当前实例对象中寻找name属性,找不到时再去该实例的类对象中寻找,所以a='swk'
2. 如图3.1,当使用p1.name='zbj'时,此时是在p1对象中设置name属性的值,因为p1中原先没有name属性,所以会新增一个name属性。再使用a = p1.name 时,获取到的a='zbj'。因为编辑器在当前对象中找到了name属性
3. 当使用b=p2.name 时,从当前实例对象找,找不到时再去当前实例的类对象中寻找。因为刚才只改了 p1实例对象中的name属性,p2中的没变,所以b='swk'
# 类设计:
1. 类名: 这类事物的名字,满足"大驼峰命名法"
2. 属性: 这类事物具有什么样的特征
3. 方法: 这类事物具有什么样的行为
- 类对象 和 实例对象都可以保存属性(方法)
- 如果这个属性(方法)是所有实例共享的,则应该将其保存到类对象中
- 如果这个属性(方法)是某个实例独有的,则应该将其保存到实例对象中
- 一般情况下:
1. 属性保存在实例对象中
2. 方法保存在类对象中
3.2、创建对象基本流程
- 创建对象的流程
# p = Person()的运行流程
1. 创建一个变量
2. 在内存中创建一个对象
3. 执行init方法
4. 将对象id赋值给变量
4、面向对象编程的三大特性之–封装
封装是指将数据(属性)和操作这些数据的方法(行为)捆绑在一个独立的对象中,并对对象的内部细节进行隐藏,只暴露有限的、安全的接口供外部使用
# 封装实现: ["约定俗成"]
* 私有属性/方法: 用公有方法返回
# 使用封装,增加了类定义的复杂程度,但确保了数据的安全性
* 隐藏了属性名,调用者无法随意修改对象中的属性
* 增加getter、setter方法,控制属性是否是只读的。如果属性只读,去掉setter方法,只写是同理的操作
* 使用setter方法可以进行数据的正确性验证等
* 封装的好处:
将对象的内部状态与外部接口隔离开来,增强代码的安全性、可维护性和灵活性。在实际开发中,善于利用封装可以显著提高代码质量。
- 定义一个类,简单演示类的封装特性
class MyClass:
name = '程序员' # 公共属性
msg = 'I Love Python'
__score = 0 # 私有属性,类外部无法直接进行访问
def __init__(self, name, msg, score): # 构造函数
self.__name = name
self.__msg = msg
self.__score = score
def get_name(self): # 获取全局的类属性name
return self.name
def get_alias_name(self): # 获取实例中的私有属性name
return self.__name
def get_msg(self): # 获取公有属性msg
return self.msg
def get_other_msg(self): # 获取私有属性msg
return self.__msg
def set_name(self, name): # 设置name属性
self.__name = name
def get_score(self): # 获取私有属性
return self.__score
def set_score(self, score): # 设置私有属性
if 0 < score < 120:
self.__score = score
obj = MyClass("全栈工程师修炼指南", "人生苦短,快用python", 256) # 实例化
print("姓名:", obj.get_name()) # 获取公有name属性
print("别名:", obj.get_alias_name()) # 获取公有name属性
print("信息:", obj.get_msg())
print("信息补充:", obj.get_other_msg())
print("分数:", obj.get_score()) # 获取score属性
obj.set_score(110) # 设置score属性值
print("设置后的分数:", obj.get_score()) # 获取修改后的score属性
4.1、属性权限(私有、公有)
# _开头: 相当于 protected
# __开头: 相当于 private
* 普通属性/方法: 被视为公开的(Public),可以从任何地方访问
* 公有属性: 在类中定义,在类的内外调用,可以通过析构函数进行初始化
* 私有属性: 调用公有方法返回
* 内置属性: 由系统在定义类的时候默认添加的由前后双下划线构成,如__dic__,__module__
# 私有属性/方法的重命名:
python将双下划线开头的属性或方法进行重命名: "name mangling"
__attr: 重命名为"_类名__属性"
__method: 重命名为"_类名__方法()"
在类外部无法通过"对象.__属性/对象.__方法()"进行访问调用
* 私有属性:
1. 表面私有: _单个下划线开头,声明该属性是私有的,受保护的。虽然可以直接在外部访问,但是约定俗成,不建议在类的外部调用。
2. 实际私有: __两个下划线开头,声明该属性是私有的。不能在类的外部直接被调用。可通过instance._classname__attribute方式访问
* 私有方法:
1. 表面私有: _单个下划线开头,声明该方法是私有的,受保护的。虽然可以直接在外部访问,但是约定俗称,不建议在类的外部调用。
2. 实际私有: __两个下划线开头,声明该方法是私有的。不能在类的外部直接被调用。可以通过instance._classname__menthod()调用
PRIVATE_PASSWD = "xyzsqwedasadas"
class Test:
count = 0 # 静态属性,每实例化一次+1
_age = 19 # 单下划线表示受保护的,不建议在外部直接访问
__private_passwd = "123456" # 私有属性
public_name = "zkc" # 公共属性
def __init__(self):
Test.count += 1 # 访问静态属性
self.__security_key = "1111"
self.__number = 0
def __private_func(self, passw):
"""私有方法"""
print("this is private func....", self)
str1 = base64.b64encode(passw.encode('utf-8')).decode('utf-8')
return str1
def set_number(self, number):
self.__number = number
def get_number(self):
""" 通过公有方法返回私有属性"""
return self.__number
def public_func(self):
print("1、this is public function")
username = self.public_name # 在内部调用公共属性
print("2、内部调用类公共属性: {}".format(username))
passwd = self.__private_passwd # 在内部直接调用私有属性
print("3、内部调用类私有属性: %s" % passwd)
print("4、内部调用类私有方法", self.__class__)
self.__private_func(PRIVATE_PASSWD) # 在内部直接调用私有方法
secret = self.__security_key # 在内部调用私有实例变量
print("5、内部调用实例私有属性: %s" % secret)
if __name__ == '__main__':
t = Test()
t.public_func()
print(t._Test__number)
t.set_number(10)
a = t.get_number() # 通过公有方法访问私有变量
print(a)
print("6、外部调用私有实例变量", t._Test__security_key) # 在类的外部调用私有实例变量
print("7、外部调用私有类变量", t._Test__private_passwd) # 在类的外部调用私有类变量
print("8、外部调用私有类方法")
aa = t._Test__private_func('ZKCLASDHIWIQEQW') # 在类的外部调用私有方法
print(aa)
class Person:
def __init__(self, name):
self._name = name
self.__age = 19
def __greet(self):
print(f"hello,{self._name}, nice to meet you")
class Student(Person):
def __init__(self, name):
super().__init__(name)
s = Student("emma")
s.__greet()
print(s.__age)
# 会报错,因为age属性和greet()方法是私有的,子类不能继承
4.2、property 装饰器
* 使用@property装饰器将方法转换成相同名称的只读属性,像访问属性一样调用方法
- 配合@setter和@deleter装饰器来控制其写和删除操作。
* 可以直接通过方法名来调用方法,不需要在方法名后添加"()"
class Person:
def __init__(self, first_name, last_name):
self.first_name = first_name
self.last_name = last_name
self._age = 0 # "受保护"的内部变量
@property
def full_name(self):
"""将一个方法伪装成只读属性"""
return f"{self.first_name} {self.last_name}"
@property
def age(self):
"""age的getter"""
return self._age
@age.setter
def age(self, value):
"""age的setter,带有验证逻辑"""
if not isinstance(value, int) or value < 0:
raise ValueError("Age must be a non-negative integer.")
self._age = value
p = Person("Albert", "Einstein")
# 像访问属性一样调用 full_name 方法,无需括号
print(p.full_name) # 输出: Albert Einstein
# 使用setter
p.age = 50 # 这会自动调用 @age.setter 方法
# p.age = -1 # ValueError: Age must be a non-negative integer.
# 使用getter
print(p.age) # 输出: 50
5、面向对象编程的三大特性之–继承
继承是一种允许我们创建一个新类(子类),使其自动获得另一个已存在类(父类或基类)的所有属性和方法的机制。
- 继承的好处:
- 代码复用: 将多个类共有的属性和方法提取到父类中,子类只需继承即可,避免了代码冗余,符合OCP原则
- 逻辑分层: 从泛化到特化,构建起清晰的类层次结构
- 促进扩展: 当需要新功能时,可通过创建一个新的子类来实现,无需修改父类
# 继承特性:
子类继承父类以及父类的父类中封装的"所有的属性和方法",可以重写父类的属性和方法,还可以扩展子类的属性和方法。适用于"是一个,即is-a" 的情形。
父类: 有抽象方法的抽象类
* 调用类中的成员时,遵循:
1. 优先在自己所在类中找,没有则去父类中找
2. 如果类存在多继承,则在子类中未找到时,从左到右查找父类中是否包含
5.1、单继承
- 单继承:一个类只继承一个父类,简单且常见
#!/usr/bin/python3
# -*- coding: UTF-8 -*-
class Person:
name = '' # 基本属性
__UID = 0 # 私有属性
# 构造函数
def __init__(self, *args):
self.name = args[0]
self.__UID = args[1]
# 类方法
def get_person_info(self):
print("人员信息: %s , %d" %(self.name,self.__UID))
class Student(Person):
grade = ''
def __init__(self, *args):
# 调用父类的构造函数
Person.__init__(self,args[0],args[1])
self.grade = args[2]
def get_student_info(self):
print("姓名: %s , 年级: %s ,身份证号:%d " %(self.name,self.grade,self._Person__UID))
# 实例化对象
xs = Student('经天纬地',512301198010284307,'2018级')
# 调用父类的方法
xs.get_person_info()
# 调用自身类方法
xs.get_student_info()
5.2、多继承
多重继承指一个类可以继承多个父类,可以组合多个父类中的功能,但继承关系复杂。
多重继承使用不当会导致重复调用(也叫钻石继承、菱形继承)的问题,导致代码执行效率低
Python使用C3线性化算法来确定类的MRO,这决定了在多重继承的情况下方法的查找顺序。C3 算法确保同一个类只会被搜寻一次。
# 多重继承的顺序:
1. 调用所有父类都有的方法时,只调用第一个父类的方法
2. 谁是第一个父类,与调用的父类初始化方法的顺序无关,与子类继承的父类参数顺序有关
3. 调用各个父类中不同的方法时,按照调用的方法名称进行依次调用
4. super()函数调用父类初始化方法时,只调用第一个父类的初始化方法
# 方法解析顺序(Method Resolution Order,MRO):
在避免同一类被调用多次的前提下,使用广度优先和从左到右的原则去寻找需要的属性和方法
# 查看MRO顺序:
1. 类名.__mro__
2. mro(类名)
# 易错点:
1. 继承链中所有类都必须使用super(),"不能混用类名调用"
2. 所有 __init__ 方法参数保持一致(统一用 *args, **kwarg)
class A:
nameA = "a"
def __init__(self,*args):
self.nameA = args[0]
print("Class A", args[0])
def get_a(self):
print(self.nameA," -> ",self.__class__)
class B:
nameB = "b"
def __init__(self,*args):
self.nameB = args[0]
print("Class B", args[0])
def get_b(self):
print(self.nameB," -> ",self.__class__)
# C 类同时继承了 A 和 B 类,并可以使用这两个父类中的方法。
class C(A, B):
name = ""
def __init__(self,*args):
A.__init__(self,args[0])
B.__init__(self,args[1])
self.name = args[2]
print("Class C", args[2])
def get_c(self):
print(self.name," -> ",self.__class__)
c = C("父类 A","父类 B","类 C")
# 调用多重继承的方法
c.get_a()
c.get_b()
c.get_c()
class Father(object):
def __init__(self, name):
self._name = name
def eat(self):
print("%s 在大吃大喝" % self._name)
def gamer(self):
print("%s 正在玩游戏" % self._name)
class Mather(object):
def __init__(self, name):
self._name = name
def eat(self):
print("%s 在吃水果" % self._name)
def song(self):
print("%s 正在唱歌" % self._name)
class Musician(object):
def __init__(self, name):
self._name = name
def eat(self):
print("%s 在细嚼慢咽" % self._name)
def piano(self):
print("%s 正在弹钢琴" % self._name)
class Son(Father, Mather, Musician):
def __init__(self, name):
super().__init__(name) # super()函数调用父类初始化方法时,只调用第一个父类的初始化方法
def eat(self):
print("%s 正在吃东西" % self._name)
# 调用了Father中的eat方法。如果把Father与Musician交换位置,则调用Musician中的eat
super().eat()
son = Son("小明")
son.eat()
print(Son.__mro__)
5.3、钻石/菱形继承
- 问题:
如何避免钻石继承(菱形继承)问题? - 原因:
一个子类继承两个父类,两个父类又共同继承同一个祖先类,形成菱形结构。
如果处理不当,会出现"祖先类被重复初始化、部分父类方法未调用的问题"。 - 解决方法:
Python有严格的方法解析顺序,super()不是简单调用直接父类,而是按照MRO顺序调用下一个类,错误使用会破坏调用链。
Python的MRO决定了方法的调用顺序,始终使用super()来调用父类的方法,并确保理解当前类的MRO。
class A(object):
def __init__(self):
print("进入A")
print("离开A")
def foo(self):
print("foo of A", self)
class B(A):
def __init__(self):
print("进入B")
super().__init__() # 超类
print("离开B")
def foo(self):
print("foo of B", self)
class C(A):
def __init__(self):
print("进入C")
super().__init__() # 超类
print("离开C")
def foo(self):
print("foo of C", self)
class D(B, C):
def __init__(self):
print("进入D")
super().__init__() # 超类
print("离开D")
pass
class E(D):
def __init__(self):
print("进入E")
super().__init__() # 根据MRO依次调用父类的初始化方法
print("离开E")
def foo(self):
print("foo of E", self)
super().foo() # 调用父类 foo(),但是父类是 D,它没有 foo(), 所以会继续向上找, 找到 B 的 foo()
super(B, self).foo() # super()中的参数是子类和self,用于确定从哪里开始查找。根据MRO, 会从B的下一个类开始找,即C的foo(),没有则继续从C的下一个类寻找
super(C, self).foo() # super()中的参数是子类和self,用于确定从哪里开始查找。根据MRO, 会从C的下一个类开始找,即A的foo(),没有则继续从A的父类开始寻找
if __name__ == '__main__':
d = D()
d.foo()
e = E()
e.foo()
class A:
def __init__(self):
self.n = 2
def add(self, m):
# 第四步
# 来自 C.add 中的super
# self是d实例对象
print('start self is {0} @A.add'.format(self))
# 第五步
self.n += m #此时 n==7 ,执行完再返回到 C.add
print('end self is {0} @A.add'.format(self))
class B(A):
def __init__(self):
self.n = 3
def add(self, m):
# 第二步
# 来自 D.add 中的 super
# self是d实例对象
print('start self is {0} @B.add'.format(self))
# 从 B 之后的[C, A, object]中查找 add 方法
super().add(m) # 调用 C.add
# 第七步
self.n += 3 # C中n=11传递过来,此时d.n=14 ,执行完再返回到 D.add
print('end self is {0} @B.add'.format(self))
class C(A):
def __init__(self):
self.n = 4
def add(self, m):
# 第三步
# 来自 B.add 中的 super
# self是d实例对象
print('start self is {0} @C.add'.format(self))
# 从 C 之后的[A, object] 中查找 add 方法
super().add(m) # 调用 A.add
# 第六步
self.n += 4 # A中n=7传递过来,此时d.n=11 ,执行完再返回到 B.add
print('end self is {0} @C.add'.format(self))
class D(B, C):
def __init__(self):
self.n = 5
def add(self, m):
# 第一步
print('start self is {0} @D.add'.format(self))
# self 的 MRO 是[D, B, C, A, object]
# 从 D 之后的[B, C, A, object]中查找 add 方法
super().add(m) # 调用 B.add
# 第八步
self.n += 5 # B中n=14传递过来,此时d.n=19
print('end self is {0} @D.add'.format(self))
d = D()
d.add(2)
print(d.n)
print(D.mro())
# 输出结果:
start self is <__main__.D object at 0x00000267C097D2B0> @D.add
start self is <__main__.D object at 0x00000267C097D2B0> @B.add
start self is <__main__.D object at 0x00000267C097D2B0> @C.add
start self is <__main__.D object at 0x00000267C097D2B0> @A.add
end self is <__main__.D object at 0x00000267C097D2B0> @A.add
end self is <__main__.D object at 0x00000267C097D2B0> @C.add
end self is <__main__.D object at 0x00000267C097D2B0> @B.add
end self is <__main__.D object at 0x00000267C097D2B0> @D.add
19
[<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
- 调用过程图如下:

5.4、super()方法
# 三种调用父类的初始化方法
* super().__init__(参数1, 参数2, ....)
* super(子类,self).__init__(参数1, 参数2, ....)
* 父类名称.__init__(self, 参数1, 参数2, ...) # 不常用
注意:
* 子类不重写 __init__,实例化子类时,会自动调用父类定义的 __init__
* 子类重写__init__ ,实例化子类时,不会自动调用父类定义的 __init__
* 子类重写了__init__,可使用 super 关键字继承父类的构造方法
1. 通过 "类名.方法名" 这种方式调用父类中的方法时,如果父类名称发生改变,那么所有引用到该类的地方全部要进行修改
2. 通过 "父类.方法名" 这种方法调用父类中的方法时,传参的时候需要再传入一个self参数
3. 通过super().方法名 这种方式引用父类,如果父类名称发生变化,代码不需要进行更新,因为super()会自动解析父类的信息。
4. super()在复杂的继承关系中,是按照mro算法来进行调用的
# 解释super(子类, self).方法()
super()中的参数是子类和self,查找顺序是从super参数中子类的下一个类(父类)开始寻找,找到则调用执行,找不到则继续从父类的下一个类寻找,以此类推,直到找不到后报错
在多继承中,self的使用非常重要,self是跟调用方法的对象绑定的,谁调用方法,谁就是self对象,并且会随着super(子类名,self)传递到父类的方法中
class People:
def __init__(self, name, age):
self._name = name
self._age = age
class Teacher(People):
def __init__(self, name, age, title):
# 下面三种都是调用父类的初始化方法
super().__init__(name, age)
super(Teacher, self).__init__(name, age)
People.__init__(self, name, age) # 不常用
self._title = title
6、面向对象编程的三大特性之–多态
多态是指不同的子类对象在响应同一个方法调用时,表现出各自不同的行为。
- 多态是指一种对象能够以多种形式出现,允许不同类对象通过相同的接口调用方法,从而实现相同的操作
- 多态通常与继承和方法重写结合在一起,处理不同类型的对象,无需关心具体子类
- 定义时的类型和运行时的类型不一样,就是定义的时候不知道调用谁,运行的时候才知道调用谁
- 允许不同类的对象可以通过相同的接口调用方法,从而实现相同的操作
# 一个对象能通过len()来获取对象长度,因为对象中有一个特殊方法__len__
# 只要对象中具有__len__特殊方法,就可以通过len()来获取他的长度
# 与对象的类型无关,只要有__len__这个魔术方法即可
my_list = [1, 2, 3, 4]
my_str = "hello"
len(my_list)
len(my_str)
# 自创对象验证多态
class Person(object):
def __init__(self, name):
self._name = name
@property
def name(self):
return self._name
@name.setter
def name(self, new_name):
self._name = new_name
# 自定义__len__()方法
def __len__(self):
print("这是我自定义的__len__()")
return 10
p = Person('zkc')
print(len(p))
6.1、方法重写 Method Overriding
在 Python 继承机制中, 子类可以重写父类的属性或方法, 来达到当父类方法功能不足时可自定义扩展的目的。
方法重写的两种情况:
- 子类重写的方法"完全覆盖"父类中的方法, 在子类中重新编写方法的实现
- 子类重写的方法使用**
super()**调用父类方法,且在子类重写的方法中编写子类特有的功能,达到对父类方法的扩展
import random as r
class Animal:
def __init__(self):
self.x = r.randint(0,10)
self.y = r.randint(0,10)
def eat(self):
print("前往 Fishc 位置坐标({},{}), Shark 动物开始进食".format(self.x,self.y))
class Fish:
def __init__(self):
self.x = r.randint(0,10)
self.y = r.randint(0,10)
def move(self):
self.x -= 1
print("Fish 位置坐标是:",self.x,self.y)
class Shark(Animal,Fish):
def __init__(self):
super().__init__() # 方法1:设置super() 指代 父类
self.hungry = True
# 覆盖Animal 父类的 eat() 方法
def eat(self):
if self.hungry:
print("饿了,要吃饭@!")
self.hungry = False
else:
print("太撑了,吃不下了")
# 实例化类
obj = Shark()
# 调用父类方法
obj.move()
obj.eat()
# 使用 super 函数,用子类对象调用父类已被覆盖的方法。
super(Shark,obj).eat()
obj.eat()
obj.move()
6.2、鸭子类型 Duck Typing
鸭子类型是动态类型的一种风格,一个对象有效的语义不是由继承自特定的类或实现特定的接口,而是由当前方法和属性的集合决定;
在鸭子类型中,关注的不是对象的类型本身,而是它是如何使用的。
如果一个对象"看起来像鸭子,叫起来像鸭子",那么它就可以被视为鸭子,即"无需显式继承",只要实现了所需的方法即可。
class Animal:
def __init__(self, name):
self.name = name
def speak(self):
# 这里用抛出异常的方式,强制子类必须实现它
raise NotImplementedError("子类必须实现speak()方法")
class Dog(Animal):
def speak(self):
return f"{self.name} 在汪汪叫(Woof! Woof!)"
class Cat(Animal):
def speak(self):
return f"{self.name} 在喵喵叫 (Meow~)"
# 一个完全不相关的类,但它也实现了 speak 方法 (鸭子类型)
class Duck:
def __init__(self, name):
self.name = name
def speak(self):
return f"{self.name} 在嘎嘎叫 (Quack! Quack!)"
# --- 体现多态的核心代码 ---
# 1. 创建一个包含不同类型对象的列表
# 这个列表里有 Dog, Cat, 甚至 Duck 对象
animals_in_orchestra = [
Dog("指挥家旺财"),
Cat("女高音咪咪"),
Duck("男中音唐纳德"),
Cat("小提琴手汤姆")
]
# 2. 编写一个通用的、面向“接口”的循环
# 这个循环不关心每个 animal 是什么具体类型
# 它只关心一件事:这个 animal会不会speak()
print("--- 动物交响乐团开始演奏 ---")
for animal in animals_in_orchestra:
# 同一个animal.speak()调用
# 对于Dog对象,执行的是Dog的speak
# 对于Cat对象,执行的是Cat的speak
# 对于Duck对象,执行的是Duck的speak
print(animal.speak())
print("--- 演奏结束 ---")
6.3、猴子补丁 Monkey Patch
在内存中发挥作用,不会修改源码,因此只对当前运行的程序实例有效。
添加的功能函数,如果要用实例调用,则函数第一个参数为self。如果用类名调用,则不需要self参数。
主要作用:
1、在运行时替换方法、属性
2、在不修改源码的情况下,对程序本身添加之前没有的功能
3、在运行时的对象中添加补丁,而不是在磁盘的源代码上
4、新增的函数参数可以带self.具体已经是否需要调用源码类中的属性和方法
class Bird:
count = 1000
def fly(self, name):
print(f"a {name} bird is flying...")
def eat(self, food_name):
if self.number > 0:
print(f"about {self.number} birds is eating {food_name}...")
else:
print("no eat")
def sum_num(a, b):
return a+b
class MonkeyJson:
@staticmethod
def json_test():
""" 猴子补丁实测 """
data = """{"name": "kid","age": 18}"""
text = json.loads(data)
print(data)
context = json.dumps(text)
print(context)
print("调用猴子补丁")
Bird.number = 4 # 相当于给Bird类增加了一个属性,而调用方式和类的内部定义的属性和方法一样
Bird.sum_num = sum_num(1, 2)
Bird.eat = eat # 相当于给Bird类增加了一个eat方法,而调用方式和类的内部定义的属性和方法一样
b = Bird()
b.fly('kid')
b.eat('eagle')
print(b.sum_num)
import os
import json
import ujson
from duck_monkey import Bird, MonkeyJson
from practice2_extend import Turtle
from practice6_private import Test
print("猴子补丁新增函数")
def plus_func(self) -> str:
self.name = "zkc"
print("猴子补丁,新增的一个方法", self.__class__)
print("猴子补丁,新增的一个方法,在新方法中获取源码中的属性", self.count)
return "添加成功"
def count_age(self) -> int:
age = self._Turtle__turtle_age
if age > 1000:
print("海归的年龄大于1000岁")
else:
age += 500
print("海归的年龄小于1000岁")
return age
def plus_func_test(self):
passwd = self._Test__private_passwd
return self._Test__private_func(passwd)
def plus_func_1(self):
print("aaaa")
def plus_func_2():
print("bbb")
def monkey_patch_json():
json.__name__ = "ujson"
json.loads = ujson.loads
json.dumps = ujson.dumps
if __name__ == '__main__':
print("猴子补丁新增函数测试1")
Bird.plus_func = plus_func # 给Bird 类新增了一个功能函数,self为原始类的实例化对象
c = Bird()
c.fly("kkkkk")
c.plus_func() # 调用新增的函数
print(c.count)
c.count = 2000
print(c.count)
print(c.name)
print("猴子补丁新增函数测试2")
Turtle.count_age = count_age
t = Turtle(1)
age = t.count_age()
print(age)
print("猴子补丁新增函数测试3")
Test.plus_func_test = plus_func_test
test = Test()
secret_pass = test.plus_func_test()
secret_key = test._Test__security_key
print(f"秘钥是: {secret_key}, 密码是: {secret_pass}")
print(test._age)
print("猴子补丁新增函数测试4")
Test.plus_func_1 = plus_func_1
test = Test()
test.plus_func_1()
print("猴子补丁新增函数测试5")
Test.plus_func_2 = plus_func_2
Test.plus_func_2()
print("猴子补丁新增函数测试6")
MonkeyJson.monkey_patch_json = monkey_patch_json
MonkeyJson.monkey_patch_json()
MonkeyJson.json_test() # 使用ujson进行json序列化和反序列化
7、类重用 Reusability
Python继承机制容易把代码复杂化以及依赖隐含继承。因此我们可以使用组合来代替。适用于 “有什么,has-a” 的情形
类的重用性指的是通过设计和实现类,使其可以在不同的上下文或项目中反复使用,从而避免代码重复,提升开发效率和代码的可维护性。
7.1、继承 Inheritance
通过继承,可以让一个类(子类)获得另一个类(父类)的属性和方法,从而实现代码重用。
class Animal:
def __init__(self, name):
self.name = name
def sound(self):
return "Some sound"
class Dog(Animal):
def sound(self):
return "Bark"
class Cat(Animal):
def sound(self):
return "Meow"
dog = Dog("Buddy")
cat = Cat("Whiskers")
print(dog.sound())
print(cat.sound())
7.2、组合 Composition
通过将一个类的实例作为另一个类的属性来实现代码重用,这种方式也称为“has-a”关系。
class Engine:
def start(self):
return "Engine started"
class Car:
def __init__(self, brand):
self.brand = brand
self.engine = Engine() # 组合
def start(self):
return f"{self.brand} car: {self.engine.start()}"
car = Car("Toyota")
print(car.start())
7.3、模块化 Modularity
将相关的类和函数组织到模块中,可以在不同的程序中重用这些模块。
# utils.py
class MathUtils:
@staticmethod
def add(a, b):
return a + b
@staticmethod
def subtract(a, b):
return a - b
# main.py
from utils import MathUtils
print(MathUtils.add(5, 3))
print(MathUtils.subtract(5, 3))
8、self 、类属性和类方法
* self表示当前正在调用该方法的对象,与实例对象进行绑定,不需要主动传参,调用实例方法时,解析器会自动将self传递给方法参数
# self作用:
1. 绑定方法,区分是哪个实例对象在调用方法
2. 代表类的实例对象本身
3. 实例对象的唯一标志。
- 类的方法与普通的函数的区别:
1. 类方法在类的内部使用def关键字来定义
2. 类方法第一个参数必须是参数self
3. 方法调用时,第一个参数由解析器自动传递,所以定义方法时,至少要定义一个形参self
* 类中定义的属性和方法都是公共的,任何该类实例都能访问
* 属性和方法查找的流程:
- 当调用一个对象属性时,解析器会先在当前对象中寻找是否有该属性
- 如果有,则返回当前对象的属性值
- 如果没有,则去当前对象的类对象中寻找,如果找到则返回类对象的属性值,如果没有则报错
* 变量访问顺序:
- 实例对象可以访问实例属性和类属性,从内-外都可以访问
- 当实例对象中没有要访问的属性时,会去类对象中查找,若有则返回,若没有,则报错
- 类对象只能访问类属性
* 类变量:
- 直接在类定义下,但在任何方法之外定义的属性,被该类的所有实例所共享,修改类属性会影响到所有实例
- 被所有对象共享,用于给对象提供公共数据(类似于全局变量)
- 访问类变量: "类.变量名"和"实例对象.变量名"
- 修改类变量: "类.变量名=XX"
* 实例变量:
- 在__init__()方法中定义的变量
- 访问实例变量: "实例对象.变量名",不能使用类.变量名来访问
- 修改实例变量: "实例对象.变量名=XX"
* 类方法:
1. 实例方法 (Instance Method)
- 定义: 第一个参数是self,代表实例对象
- 调用: 通过实例调用,obj.method()
- 作用: 操作实例的属性,self.attribute
2. 类方法 (Class Method)
- 定义: 使用@classmethod装饰器,第一个参数是cls,代表类本身
- 调用方法时才会分配地址 随调用随分配
3. 静态方法 (Static Method)
- 定义: 使用@staticmethod装饰器,没有self或cls这样的特殊首参数
- 作用: 逻辑上归属于这个类,但完全独立的辅助函数。不能访问类属性和实例属性
- 代码一运行就会分配内存地址的 不管怎么调用该方法,实例化类都不会变
"""
1、如果方法内部涉及到实例对象属性的操作,用普通方法
2、如果方法内部没有操作实例属性的操作,仅包含工具性的操作,用静态方法
3、如果需要对类属性,即静态变量进行操作,用类方法
三种函数说明:
【普通方法(实例方法)】:
第一个参数self参数,代表实例对象本身,可使用self直接引用定义的实例属性和普通方法。如果需要调用 静态方法 和 类方法,使用 类名.方法名() 调用
【静态方法】:
使用 类名.静态变量 来引用静态变量,使用 类名.方法名() 来引用静态方法和其他类方法。如要引用普通方法,需要先实例化一个对象,再去调用普通方法
【类方法】:
第一个参数cls参数,代表类本身(等价)。通过 cls.静态变量 或 类名.静态变量 引用静态变量。利用 cls.方法名() 或者 类名.方法名() 来引用静态方法和类方法,若要调用普通方法,则需要先实例化一个对象,再去调用普通方法
建议:
1、静态函数 和 类函数 一般建议使用 类名.方法名()。也可使用 实例对象名.方法名()调用。但是用类名调用的话,不需要实例化对象,降低代码运行和维护的开销
2、不需要访问实例成员,但需要访问类成员时,建议使用@classmethod 将方法定义为类方法
3、不需要访问实例成员,也不需要访问类成员时,建议使用@staticmethod 将方法定义为静态方法
"""
class A(object):
'''
类属性:
1、可以通过类或者类的实例访问
2、只能通过类对象修改,实例对象无法修改
'''
count = 0
def __init__(self, name):
'''
实例属性:
1、通过实例对象添加的属性,如 a.sex = 'man'
2、通过self添加的属性
3、只能实例对象访问,类对象无法访问
'''
self._name = name
self._age = 19
def test(self):
'''
实例方法:
1. 在类中定义,第一个参数为self
2. 实例方法可以通过实例对象和类对象调用
2.1 通过实例调用对象时,Python会自动将实例对象传入给实例方法的第一个参数self,不用显式传递self参数
2.2 通过类对象调用时,不会自动传递self,必须手动传递self
'''
print("这是实例方法")
@classmethod
def test2(cls):
'''
类方法:
1. 使用 @classmethod 装饰器修饰的方法
2.在类中定义,第一个参数为cls,会被自动传递,就是当前类对象
3. 类方法可以通过实例对象和类对象调用,建议一般使用类对象调用,可以省略实例化过程
'''
print('这是类方法')
@staticmethod
def test3():
'''
静态方法:
1. @staticmethod 修饰,不需要指定任何参数
2. 静态方法可以通过实例对象和类对象调用,建议一般使用类对象调用,可以省略实例化过程
3. 静态方法是一个和当前类无关的方法,只是保存到当前类的函数
4. 静态方法一般是一些工具方法
'''
print("这是静态方法")
a = A('zkc')
a.sex = 'man' # 通过实例对象添加的属性
a.test() # 通过实例对象调用实例方法, py自动将a对象传递给test()的self参数
A.test(a) # 通过类对象调用实例方法,需要显式传递 实例对象,给实例方法的第一个参数self
a.test2()
A.test2()
a.test3()
A.test3()
# 类变量和实例变量访问
class Person(object):
country = "中国"
def __init__(self, name, age):
self.name = name
self.age = age
print(Person.country) # 中国
p1 = Person("小峰",20)
print(p1.name)
print(p1.age)
print(p1.country) # 中国
p1.name = "root" # 在对象p1中将name重置为root
p1.country = "china" # 在对象p1中新增实例变量 country="china"
print(p1.country) # 优先访问实例中的属性,没有再去类对象中寻找
print(Person.country) # 中国
Person.country="china" # 修改类对象的属性值
print(Person.country) #china
data = {
"name": "Alice",
"age": 30,
"hobbies": ["reading", "coding"],
"is_student": False
}
class Person:
def __init__(self, name):
self.name = name
def greet(self):
print(f"hello,{self.name}, nice to meet you")
@classmethod
def from_dict(cls, content):
name = content['name']
return cls(name) # 实例化并返回实例对象,用的最多
@classmethod
def from_dict1(cls, content):
name = content['name']
x = cls(name)
x.age = 19 # 创建实例对象后,还可以进行实例属性的初始化操作
return x
p = Person("Bob")
p.greet()
p_1 = p.from_dict(data) # 调用类方法返回实例化对象
p_1.greet()
p_2 = Person.from_dict1(data) # 调用类方法返回实例化对象
p_2.greet()
import sys
from time import localtime, time, sleep
"""
时钟:
要点:时,分,秒
1、初始化传参,设置默认值
2、计算当前时间,并且实例化,参数传入当前时间
"""
class Clock(object):
def __init__(self, hour=0, minute=0, second=0):
self._hour = hour
self._minute = minute
self._second = second
def __run(self):
self._second += 1
if self._second == 60:
self._minute += 1
self._second = 0
if self._minute == 60:
self._hour += 1
self._minute = 0
if self._hour == 24:
self._minute = 0
self._second = 0
@classmethod
def now_time(cls):
"""
获取当前时间,并且实例化时钟对象
"""
curr_time = localtime(time())
return cls(curr_time.tm_hour, curr_time.tm_min, curr_time.tm_sec)
def show(self):
time_str = "%02d:%02d:%02d" % (self._hour, self._minute, self._second)
print(time_str)
sleep(1)
self.__run()
def main():
clock = Clock.now_time()
while True:
clock.show()
if __name__ == '__main__':
if not main():
sys.exit(1)
class Home(object):
# 房间中人数
_number = 0
def __new__(cls):
Home.add_person_number()
return super().__new__(cls) # 创建并返回Home实例,在子类中使用 new() 时,通常要调用父类的 new() 方法来确保对象被正确创建
@classmethod
def add_person_number(cls):
cls._number += 1
@classmethod
def get_person_number(cls):
return cls._number
class Person(Home):
def __init__(self):
self._name = 'zkc'
# 创建人员对象时,会调用父类Home的__new__()方法
tom = Person()
bob = Person()
test = Person()
print(Home.get_person_number())
9、垃圾回收
# 程序在运行过程中会产生垃圾,会影响到程序的运行性能,所以必须被清理
1. 没有被引用的对象是垃圾
2. 程序执行结束,也会调用 __del__()方法进行垃圾回收
# 垃圾回收:将没被引用的对象从内存中删除
# Python 有自动垃圾回收机制,会自动将这些没有被引用的对象删除,不需要手动处理
class A:
def __init__(self):
self.name = 'A类'
# 特殊方法,在对象被垃圾回收前调用
def __del__(self):
print('A()对象被删除了~~~',self)
a = A()
print(a.name)
# 不加 a = None, 不会执行__del__方法。加上之后会执行
# 将a设置为None,此时A()对象没有被任何变量引用,就变成了垃圾
a = None
input("按回车键退出~~~~")
# 不加的输出结果(按完回车,程序执行结束,也会调用 __del__()方法进行垃圾回收)
A类
按回车键退出~~~~
A()对象被删除了~~~ <__main__.A object at 0x0000019BD2D462F0>
#加的输出结果
A类
A()对象被删除了~~~ <__main__.A object at 0x0000019A2A2E62F0>
按回车键退出~~~~
10、类的魔术方法
Python 中的类中的魔术方法(magic methods),也称为特殊方法或双下方法(dunder methods),是一组特殊的方法,它们以双下划线(__)开头和结尾。这些方法允许我们定制类的行为,包括对象的创建、表示、运算符重载等。
* __init__(self, ...): 初始化方法,在创建对象时自动调用。
* __del__(self): 析构方法,在对象被垃圾回收时自动调用。
* __new__(cls, ...): 创建对象时自动调用,用于自定义对象的创建过程。
* __str__(self): 定义当使用 str() 或 print() 函数输出对象时的字符串表示。
* __repr__(self): 定义对象的官方字符串表示,通常用于调试。
* __call__(self, ...): 定义当对象被调用时自动执行。
* __add__(self, other): 定义加法运算符 + 的行为。
* __sub__(self, other): 定义减法运算符 - 的行为。
* __mul__(self, other): 定义乘法运算符 * 的行为。
* __truediv__(self, other): 定义真除法运算符 / 的行为。
* __mod__(self, other): 定义取模(求余数)运算符 % 的行为。
* __pow__(self, other): 定义幂运算符 ** 的行为。
* __cmp__(self, other): 定义比较运算符 <、> 和 == 的行为。
* __getattr__(self, name): 在访问不存在的属性时调用。
* __setattr__(self, name, value): 在设置属性值时调用。
* __delattr__(self, name): 在删除属性时调用。
* __len__(self): 定义对象的长度,使用 len() 函数时调用。
* __getitem__(self, key): 定义按键获取项目的行为,使用 obj[key] 时调用。
* __setitem__(self, key, value): 定义按键设置项目的行为,使用 obj[key] = value 时调用。
* __delitem__(self, key): 定义按键删除项目的行为,使用 del obj[key] 时调用。
10.1、对象的创建与销毁
* __new__(): 用来控制对象的生成过程,在对象生成之前调用
* __init__(): 用来对对象进行初始化,在对象生成之后调用
* 若__new__()不返回对象,就不会调用__init__()函数
__new__(cls,…):Python 中创建实例的特殊方法,它在__init__之前执行,负责创建并返回实例对象
python解释器获得对象的引用后,将引用作为第一个参数,传递给__init__方法
1. super()在这里会查找Home类的父类,即object类
2. object.__new__(cls)是创建实例的基础方法,负责在内存中为对象分配空间并返回实例对象的引用
4. new()方法必须返回一个类的实例。如果 new() 不返回任何内容(即返回 None),那么 init() 方法将不会被调用
5. 在子类中使用 new() 时,通常要调用父类的 new() 方法来确保对象被正确创建
class Home(object):
def __new__(cls):
return super().__new__(cls)
def __new__(cls):
return object.__new__(cls)
__init__(self, …):初始化方法,在创建对象时自动调用,用于初始化对象的属性。
class MyClass:
def __init__(self, value):
self.value = value
obj = MyClass(10)
__del__(self):析构方法,在对象被垃圾回收时自动调用,用于清理资源。
class MyClass:
def __del__(self):
print("Object is being deleted")
class FileHandler:
def __init__(self, filename, mode):
print(f"--- 调用 __init__ ---")
print(f"正在打开文件: {filename}")
self.filename = filename
# 在构造时打开文件,持有资源
self.file = open(filename, mode)
def write(self, content):
self.file.write(content)
print(f"向 {self.filename} 写入内容。")
def __del__(self):
print(f"--- 调用 __del__ ---")
print(f"对象即将被销毁,正在关闭文件: {self.filename}")
# 在析构时确保文件被关闭
if self.file:
self.file.close()
def __new__(cls, *args, **kwargs):
print("--- 调用 __new__ ---")
return object.__new__(cls)
def manage_file():
print("进入 manage_file 函数,创建对象...")
handler = FileHandler("my_log.txt", "w")
handler.write("对象生命周期测试。\n")
print("manage_file 函数即将结束,handler 变量将超出作用域.")
manage_file()
print("manage_file 函数已结束。")
10.2、对象的表示
# __str__(self):
1. 当使用 str() 或 print() 函数输出对象时的字符串表示。
2. 当我们打印一个对象时,实际上打印的是对象中的特殊方法 __str__() 的返回值
3. 在尝试将对象转换为字符串时调用
4. 作用: 指定对象转换为字符串的结果(print函数里打印对象时)
# __repr__(self):
1. 对象的官方字符串表示,通常用于调试,在对当前对象使用 repr() 函数时调用
2. 作用: 指定对象在 "交互模式" 中直接输出的结果
# __str__与__repr__的区别:
1. __str__魔术方法,需要print输出
2. __repr__魔术方法,直接对象输出
3. 无__str__时,str(obj)也会走__repr__
class MyClass:
def __init__(self, name, value):
self.name = name
self.value = value
def __str__(self):
return "MyClass [name=%s, value=%d]" % (self.name, self.value)
def __repr__(self):
return f"MyClass({self.value})"
obj = MyClass(10)
print(obj) # 输出: MyClass [name=zkc, value=10]
print(str(obj)) # 输出: MyClass [name=zkc, value=10]
print(repr(obj)) # 输出: MyClass(10)
"""
python 使用"=="判断两个对象时会调用__eq__方法,
假设判断 A==B
若AB之间无继承关系,则调用A中的__eq__方法
若AB之间有继承关系,且子类重写了__eq__方法,则调用子类的__eq__方法
"""
class Foo:
def __init__(self, name):
self._name = name
def __str__(self):
return self._name
def __eq__(self, other):
return self is other
class Bar(Foo):
def __eq__(self, other):
return str(self) == str(other)
foo = Foo('Hello')
bar = Bar('Hello')
"""
有继承关系,所以下面两个都调用子类的__eq__方法,没有使用父类的__eq__方法
问题:子类中没有重载__str__方法,为啥输出还是True?
虽然子类没有重载__str__方法,但继承了父类重载的__str__方法,将对象转换成字符串输出
子类的__eq__方法,返回的是字符串比较,所以是一样的,都是"Hello"
有继承关系的时候没有进行对象之间的比较,因为使用的子类的__eq__方法
"""
print(foo == bar)
print(bar == foo)
print("============================================================================")
class Foo:
def __init__(self, name):
self._name = name
def __str__(self):
return self._name
def __eq__(self, other):
return self is other
class Bar:
def __init__(self, name):
self._name = name
def __str__(self):
return self._name
def __eq__(self, other):
return str(self) == str(other)
foo = Foo('Hello')
bar = Bar('Hello')
"""
没有继承关系,所以分情况
1. foo == bar,使用的Foo中的__eq__方法,这个方法中返回 self is other,因为Foo中重写了__str__方法,可以将foo对象转换成字符串输出
所以self是"Hello",Bar中没有重写__str__,所以bar是对象信息字符串。所以为False
如果在Bar中重载了__str__方法,那么self和other的值都是字符串"Hello",但最后还是False,因为self和other是两个不同的类的字符串"Hello"
is关键字既比较值又比较地址
2. bar == foo,使用的Bar中的__eq__方法,这个方法中返回str(self) == str(other),但是Bar中没重写__str__方法,所以使用了默认的__str__方法
,默认的输出是对象信息字符串,两个不同的类对象输出的对象信息字符串肯定也不桶,所以返回也是False
如果想要返回True,需要重载__str__()方法
"""
print(foo == bar)
print(bar == foo)
10.3、比较运算符
lt(self, other): 小于
le(self, other): 小于等于
eq(self, other): 等于
ne(self, other): 不等于
gt(self, other): 大于
ge(self, other): 大于等于
在对象之间作比较的时候调用,该方法的返回值将会作为比较的结果
第一个参数是self表示当前对象, 第二个参数other表示和当前对象比较的对象
class Person:
def __init__(self, name, value):
self.name = name
self.value = value
def __gt__(self, other):
# 如果写死成 return True/return False ,这样的话总是self>other/self<other
# 所以用具体的数值来做比较
return self.value > other.value
def __lt__(self, other):
return self.value < other.value
p1 = Person('zkc1', 10)
p2 = Person('zkc2', 18)
print(p1 > p2) # False
print(p2 > p1) # True
print(p1 < p2) # True
print(p2 < p1) # False
10.4、运算符重载
add(self, other):定义加法运算符 + 的行为。
sub(self, other):定义减法运算符 - 的行为。
mul(self, other):定义乘法运算符 * 的行为。
truediv(self, other):定义真除法运算符 / 的行为
class MyClass:
def __init__(self, value):
self.value = value
def __add__(self, other):
return MyClass(self.value + other.value)
def __sub__(self, other):
return MyClass(self.value - other.value)
def __mul__(self, other):
return MyClass(self.value * other.value)
def __truediv__(self, other):
return MyClass(self.value / other.value)
obj1 = MyClass(10)
obj2 = MyClass(20)
result = obj1 + obj2 # result 是 执行__add__(self, other)返回的 MyClass(30) 实例化的对象
print(result) # <__main__.MyClass object at 0x0000013FB5027E20>
print(result.value) # 输出: 30
result2 = obj1 - obj2 # result2 是 执行__sub__(self, other)返回的 MyClass(-10) 实例化的对象
print(result2.value) # 输出: -10
result3 = obj1 * obj2 # result3 是 执行__mul__(self, other)返回的 MyClass(200) 实例化的对象
print(result3.value) # 输出: 200
result4 = obj1 / obj2 # result4 是 执行__truediv__(self, other)返回的 MyClass(0.5) 实例化的对象
print(result4.value) # 输出: 0.5
10.5、属性访问
__getattr__(self, name):在访问不存在的属性时调用
__setattr__(self, name, value):在设置属性值时调用
__delattr__(self, name):在删除属性时调用
__getattribute__(self,name) :当该类的属性被访问时调用
如何优雅地避免访问对象不存在的属性(不产生异常)?
1、使用 hasattr(object, name) 函数判断属性是否存在
2、使用 getattr(object, name[, default]) 函数并设置 default 参数(返回对象指定的属性值,如果指定的属性不存在,返回default(可选参数)的值)
class MyClass:
def __getattr__(self, name):
return f"{name} attribute not found"
def __setattr__(self, name, value):
print(f"Setting {name} to {value}")
self.__dict__[name] = value
def __delattr__(self, name):
print(f"Deleting {name}")
del self.__dict__[name]
def __getattribute__(self, name):
print("调用 getattribute 魔法方法")
return super().__getattribute__(name) #super()自动获取基类,这个类没有继承类默认是object类
obj = MyClass()
# 尝试不存在属性时触发调用getattribute和getattr
print(obj.some_attribute)
# 设置属性 调用 getattribute和setattr
obj.attr = 10
# 获取属性 调用 getattribute
obj.attr
# 删除属性 调用 getattribute和delattr
del obj.attr
10.6、容器类型实现
len(self):定义对象的长度,使用 len() 函数时调用。
getitem(self, key):定义按键获取项目的行为,使用 obj[key] 时调用。
setitem(self, key, value):定义按键设置项目的行为,使用 obj[key] = value 时调用。
delitem(self, key):定义按键删除项目的行为,使用 del obj[key] 时调用。
class MyClass:
def __init__(self, items):
self.items = items
def __len__(self):
return len(self.items)
def __getitem__(self, key):
return self.items[key]
def __setitem__(self, key, value):
self.items[key] = value
def __delitem__(self, key):
del self.items[key]
obj = MyClass([1, 2, 3])
print(len(obj)) # 输出: 3
print(obj[1]) # 输出: 2
obj[1] = 10
print(obj.items) # 输出: [1, 10, 3]
del obj[1]
print(obj.items) # 输出: [1, 3]
10.7、上下文管理
enter(self):进入上下文时调用
exit(self, exc_type, exc_val, exc_tb)
class Foo(object):
def __enter__(self):
print("进入了")
return 666
def __exit__(self, exc_type, exc_val, exc_tb):
print("出去了")
obj = Foo()
with obj as data:
print(data)
10.8、函数/方法调用
class Foo(object):
def __call__(self, *args, **kwargs):
print("执行call方法")
obj = Foo()
obj() # 当调用"对象名()"的时候就会自动执行call方法
11、单例模式
一个类全局只能有唯一一个实例,多次创建对象,得到的都是同一个内存地址的实例
适用场景:配置类、日志工具、数据库连接、全局缓存等
为什么用 __new__ 能实现单例?
因为 new 控制对象创建,判断已有实例就直接复用,不再新建内存
写法一:基础单例
用类属性保存唯一实例,每次创建前判断是否已存在
class Singleton:
__instance = None
def __new__(cls, *args, **kwargs):
if cls.__instance is None:
cls.__instance = super().__new__(cls)
return cls.__instance
def __init__(self, name):
self.name = name
print('__init__')
s1 = Singleton('name1')
s2 = Singleton('name2')
print(s1.name)
print(s2.name)
优化:阻止重复初始化
上面版本有问题,每次 Singleton() 都会执行 init,通过加标记控制只初始化一次
class Singleton:
_instance = None
_is_init = False # 初始化标记
def __new__(cls, *args, **kwargs):
if cls._instance is None:
cls._instance = super().__new__(cls)
return cls._instance
def __init__(self, name):
if not self._is_init:
self.name = name
Singleton._is_init = True
print('__init__')
s1 = Singleton('name1')
s2 = Singleton('name2')
print(s1.name)
print(s2.name)
线程安全单例(多线程场景)
多线程下,基础单例可能同时进入判断,创建多个实例,需要加锁
多线程下单例为什么要加锁?
多个线程同时判断 _instance is None,会同时创建多个实例,锁保证同一时间只有一个线程进入创建逻辑
class Singleton:
_instance = None
_lock = threading.Lock()
def __new__(cls, *args, **kwargs):
if cls._instance is None:
with cls._lock:
cls._instance = super().__new__(cls)
return cls._instance
def create_obj():
obj = Singleton()
print(id(obj)) # 所有线程打印的id完全相同,保证单例
for _ in range(10):
t = threading.Thread(target=create_obj)
t.start()
四、Python模块
1、time 模块
import time
* time.sleep(n): 让程序暂停执行 n 秒
* time.time(): 获取当前时间的时间戳(从1970年1月1日0点0分0秒开始到现在经过了多少秒)
# 计算时间差
def func()
for i in range(100000):
print(i)
start = time.time()
func()
end = time.time()
print('函数一共执行了%s秒' % (end-start))
2、datetime 模块
Python处理日期和时间的标准工具
from datetime import datetime, date, time
'''
date: 表示一个日期(年、月、日)。
time: 表示一个时间(时、分、秒、微秒)。
datetime: 表示一个具体的日期和时间(年、月、日、时、分、秒、微秒)
timedelta: 表示两个日期或时间之间的差值。
'''
* datetime.now(): 获取当前系统时间
* datetime(2025, 9, 10, 15, 39, 40): 创建指定时间
* datetime.now().strftime('%Y-%m-%d %H:%M:%S'): 将当前时间格式化成字符串
* datetime.strftime(datetime.now(),'%Y-%m-%d %H:%M:%S'): 将时间对象格式化成字符串,第一个参数是时间对象,第二个参数是格式化模板
* datetime.strptime('时间字符串', '%Y-%m-%d %H:%M:%S'): 将字符串格式化成时间对象,第一个参数是时间字符串,第二个参数是格式化模板
* date.today(): 获取当前日期
* date.today(2025, 9, 10): 获取指定日期
* date.today().strftime('%Y年%m月%d日'): 将当前日期格式化成字符串
* date.strftime(today(), '%Y年%m月%d日'): 将当前日期格式化成字符串,第一个参数是日期对象,第二个参数是格式化模板
* timedelta对象代表一段时间。可以对datetime对象进行加减的操作,来实现时间的推算
curr_date = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
curr_date1 = datetime.now().strftime('%Y年%m月%d日 %H时%M分%S秒')
curr_date2 = datetime.strftime(datetime.now(),'%Y%m%d%H%M%S')
curr_date3 = datetime.strftime(datetime(2025, 9, 10, 15, 39, 40),'%Y-%m-%d %H:%M:%S')
print(curr_date) # 2025-09-10 16:55:30
print(curr_date1) # 2025年09月10日 16时55分30秒
print(curr_date2) # 20250910165530
print(curr_date3) # 2025-09-10 15:39:40
# 求时间差,只有时间对象类型可以相减,字符串不能相减
curr_date4 = datetime.strptime('2025-09-10 16:04:35', '%Y-%m-%d %H:%M:%S')
curr_date5 = datetime.strptime('2025-09-11 15:04:35', '%Y-%m-%d %H:%M:%S')
print(curr_date5-curr_date4) # 23:00:00
print(date.today().strftime('%Y年%m月%d日')) # 2025年09月10日
print(date.strftime(today(), '%Y年%m月%d日')) # 2025年09月10日
from datetime import timedelta
# 创建一个 timedelta 对象
one_day = timedelta(days=1)
one_week = timedelta(weeks=1)
two_hours_thirty_minutes = timedelta(hours=2, minutes=30)
# 时间计算
tomorrow = now + one_day
print(f"明天同一时间: {tomorrow}")
last_week = now - one_week
print(f"上周同一时间: {last_week}")
# 计算两个日期之间的差值
delta = new_year_2026 - now
print(f"距离2026年元旦还有: {delta.days} 天, {delta.seconds // 3600} 小时")
3、random 模块
import random
* random.random(): 生成(0,1)范围内的随机小数,不包含边界
* random.uniform(m,n): 生成指定范围的随机小数,不包含边界
* random.randint(m,n): 生成指定范围的随机整数,包含边界
* random.choice(list): 从容器中随机选择一个元素
* random.sample(list, n): 从列表中随机抽取n个元素
print(random.random())
print(random.uniform(1, 10))
print(random.randint(1, 10))
print(random.randrange(1, 10))
lst = [1, 2, 3]
print(random.choice(lst))
print(random.sample(lst,2))
print(random.sample(lst,3))
# 随机验证码
def rand_num():
return str(random.randint(0, 9)) # 0-9的随机整数
def rand_upper():
return chr(random.randint(65, 90)) # 随机大写字母
def rand_lower():
return chr(random.randint(97, 122)) # 随机小写字母
def get_verify_code(n=4):
lst = []
for i in range(n):
swich = random.randint(1, 3)
if swich == 1:
s = rand_int()
elif swich == 2:
s = rand_upper()
elif swich == 3:
s = rand_lower()
lst.append(s)
return ''.join(lst)
print(get_verify_code(8))
4、os 模块
os模块主要封装了关于操作系统、文件系统的相关操作,比如创建文件夹、删除文件夹等
__file__ 是 Python 中的一个内置变量,它返回当前脚本的绝对路径(文件的路径)
# 参数 path 为相对或者绝对路径,一般写绝对路径
* os.makedirs('/dirname1/dirname2'): 创建多层递归目录。若文件夹已存在,则报错FileExistError
* os.removedirs('/dirname1/dirname2'): 递归删除空目录。若目录为空,则删除,并递归到上一级目录,如若也为空,则删除。若目录不为空,则报错OSError目录不为空
* os.mkdir(path): 创建单级目录
* os.rmdir(path): 删除单级空目录,若目录不为空,则无法删除
* os.remove(path): 删除一个文件
* os.rename(old_path, new_path): 将文件/目录重命名或者将文件从源路径移动到目标路径并且重命名
- os.rename('aa.txt', 'demo.txt') # 当前同一目录下文件重命名
- os.rename('/opt/zkc/aa.txt', '/opt/demo.txt') # 从原路径移动到目标路径并且重命名
- os.rename('/opt/zkc/aa.txt', 'demo.txt') # 移动到当前位置并且重命名
- os.rename('aa.txt', '/opt/demo.txt') # 从当前位置移动到目标路径并且重命名
* os.listdir(path): 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表形式返回文件夹下文件的相对路径
* os.getcwd(): 获取当前工作目录,即当前python脚本工作的目录路径
* os.chdir(path): 改变当前脚本工作目录
# os.path
# 下面函数除过判断的函数,其它函数可使用绝对路径,也可使用相对路径
* os.path.isfile(path): 需要包含文件名的文件的绝对路径,只要路径包含文件名,并且文件要存在,则返回True
* os.path.isdir(path): 需要文件的绝对路径,不包含文件名,并且路径要存在, 则返回True
* os.path.exists(path): 包含文件名的文件的绝对路径/不包含文件名的绝对路径,都返回True
* os.path.isabs(path): 如果path是绝对路径,则返回True
* os.path.splitext(path): 获取文件扩展名,返回元组,元组第一个元素是文件路径,第二个元素是文件扩展名
* os.path.split(path): 获取文件名,返回元组,元组第一个元素是文件路径,第二个元素是文件名
* os.path.dirname(path):返回指定目录或文件的父目录。每调用一次 os.path.dirname() 都会返回路径的上一级目录
* os.path.basename(path): 返回文件名,即:os.path.split(path)[-1]
* os.path.abspath(path): 返回文件的绝对路径
* os.path.join(path1, path2,...): 将多个路径进行拼接后返回
* os.path.getsize(path): 获取文件大小
* os.environ 获取系统的环境变量
* os.system() 执行操作系统的命令
- os.system('dir')
- os.system('pwd')
# 如果 path 是 /home/user/myproject/manage.py,则 os.path.dirname(path) 返回 /home/user/myproject
import os
curr_path = os.path.dirname(os.path.abspath(__file__)) # 获取当前文件所在目录 E:\zkc\file\code\python-workspace\shell
for file in os.listdir(curr_path):
abs_file_path = os.path.join(curr_path, file) # 拼接得到绝对路径
# 判断是否是文件,并且文件后缀是.sh结尾
if os.path.isfile(abs_file_path) and os.path.splitext(abs_file_path)[-1] == '.sh':
file_name = os.path.split(abs_file_path)[-1] # 获取文件名
file_name1 = os.path.basename(abs_file_path) # 获取文件名
if not os.path.isdir(abs_file_path): # 判断路径是否是目录
continue
- 递归查找所有文件
# 递归查找所有文件
# 获取当前文件所在目录 E:\zkc\file\code\python-workspace\shell
curr_path = os.path.dirname(os.path.abspath(__file__))
shell_path = os.path.join(os.path.dirname(curr_path), 'zkc')
def find_files(path, ceng):
"""
定义一个函数,用于查找指定路径下的所有文件
"""
for file_name in os.listdir(path):
new_path = os.path.join(path, file_name)
if os.path.isdir(new_path):
print("|---- " * ceng, file_name, sep="")
find_files(new_path, ceng + 1)
else:
print("|---- " * ceng, file_name, sep="")
find_files(shell_path, 1)
- 创建文件的正常流程
# 创建文件的正常流程
def create_file(path, is_cover: bool):
file_path = os.path.dirname(path)
# 判断路径是否存在
if not os.path.exists(file_path):
os.makedirs(file_path)
# 判断文件是否存在
if os.path.exists(path):
# 是否需要覆盖
if is_cover:
open(path, 'w').close()
else:
return
else:
open(path, 'w').close()
create_file('/opt/zkc/aa.txt', True)
5、文件操作
# open/with open操作文件的模式:
* r : 只读模式,文件不存在会报错
* r+ : 可读可写,覆盖写,文件不存在会报错
* w : 只写模式,覆盖写,文件不存在则新建
* w+ : 可读可写,覆盖写,文件不存在则新建
* a : 只写模式,追加写,文件不存在则创建
* a+ : 可读可写,追加写,文件不存在则创建
* b : 读取二进制文件(读取非文本文件,不能省略), 如'rb'
* t : 读取文本文件(默认值, 可省略)。如'w'='wt', 'r'='rt', 'a'='at', 'r+'='rt+'
* x : 新建文件,文件不存在则创建,存在则报错
# 读取文件内容:
- read(): 一次性读取全部内容 将整个文件内容读取为一个单一的字符串
- 适用于小文件,对于大文件要小心,因为它会消耗大量内存
- readline(): 一次读取一行,包括行尾的换行符\n,并返回一个字符串。当读到文件末尾时,返回一个空字符串""
- readlines(): 一次性读取所有行 将整个文件内容按行读取,并返回一个包含所有行的列表,列表中的每个元素都是一个字符串(包含行尾的\n)
- 遍历文件对象: 最高效的逐行读取方式 文件对象本身是可迭代的
# 向文件写入内容
- write(string): 将指定的字符串写入文件
- write()不会自动添加换行符,需要手动添加\n
- writelines(list_of_strings): 将一个包含多个字符串的列表,一次性地写入文件
- writelines()不会自动添加换行符,需要手动添加\n
5.1、open()
操作文件时使用内置的open()函数来打开一个文件,它会返回一个文件对象,这个对象就代表了我们与该文件之间的连接。
# 基本语法:
file_object = open(file_path, mode='r', buffering=None, encoding=None, errors=None, newline=None, closefd=True)
# 参数:
* file_path: 表示文件的路径(可以是相对路径或绝对路径)
* mode: 指定打开文件的模式
* encoding: 指定读写文件时使用的字符编码
* errors: 报错级别
* newline: 区分换行符
* closefd: 传入的file参数类型
* buffering: 设置缓冲
file_name = 'demo1.txt'
curr_path = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(curr_path, file_name)
file = None
try:
file = open(file_path, 'r', encoding='utf-8')
context = file.read()
print(context)
except FileNotFoundError:
raise FileNotFoundError('file is not found') from None
finally:
if file is not None:
file.close()
print("\n--- 逐行遍历文件 ---")
with open('my_document.txt', 'r', encoding='utf-8') as f:
for line_number, line in enumerate(f, 1):
print(f"第 {line_number} 行: {line.strip()}")
"""
比较两个文件内容是否相等
"""
import os.path
def file_compare(file1, file2):
differ = []
count = 0 # 统计行数
with open(file1, 'r') as f1, open(file2, 'r')as f2:
for line in f1:
line2 = f2.readline()
count += 1
if line != line2:
differ.append(count)
return differ
def main():
file1_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'file', 'a.txt')
file2_path = os.path.join(os.path.dirname(os.path.abspath(__file__)), 'file', 'b.txt')
diff = file_compare(file1_path, file2_path)
if len(diff) == 0:
print('两个文件完全一样')
else:
print('两个文件共有 %s 处不同' %(len(diff)))
for item in diff:
print("第 %d 行不一样" % item)
if __name__ == '__main__':
main()
5.2、with语句
自动管理资源的生命周期。当代码块执行完毕或中途发生任何异常退出时,with都会确保文件被自动、正确地关闭
- 文件读取方法
from pathlib import Path
import os
if __name__ == '__main__':
file_name = "file_read.txt"
fill_path = os.path.dirname(os.path.abspath(__file__))
full_path = os.path.join(fill_path, file_name)
"""
1、Path 读取/写入文件
"""
# 1、Path,需要pathlib库导入
# 读取整个文本内容
file = Path(full_path)
context = file.read_text(encoding='utf-8')
print(context)
# 读取每一行内容
every_lines = context.splitlines()
for every_line in every_lines:
print("Path 读取每一行内容:", every_line)
# Path 写入
file = Path(full_path)
file.write_text("hello world\n")
"""
2、open 读取文件
"""
""" 要手动关闭文件流"""
file = open(full_path, 'r', encoding='utf-8')
context1 = file.read()
print(context1)
open_lines = context1.splitlines()
for open_line in open_lines:
print("open 读取每一行内容:", open_line)
# 将上面read()读取文件后的指针从文件末尾移动到文件开头。不然读取不到文件
file.seek(0, 0)
open_read_lines = file.readlines()
for open_read_line in open_read_lines:
print("open filelines 读取所有行内容", open_read_line.strip())
# 将上面readlines()读取文件后的指针从文件末尾移动到文件开头。不然读取不到文件
file.seek(0, 0)
while True:
file_read_line = file.readline()
if not file_read_line:
break
print("open fileline 读取每一行内容", file_read_line.strip())
file.close()
"""
3、with open 文件读取/写入
"""
with open(full_path, 'r', encoding='utf-8') as file:
# 读取所有内容
context2 = file.read()
print(context2)
# 读取每一行内容
with_open_lines = context2.splitlines()
for with_open_line in with_open_lines:
print("with open 读取每一行内容", with_open_line)
file.seek(0, 0)
with_open_read_lines = file.readlines()
for with_open_read_line in with_open_read_lines:
print("with open filelines 读取所有行内容", with_open_read_line.strip())
file.seek(0, 0)
while True:
with_open_read_line = file.readline()
if not with_open_read_line:
break
print("with open fileline 读取所有行内容", with_open_read_line.strip())
'''
4、二进制文件读取
'''
binary_name = 'demo.flac'
curr_path = os.path.dirname(os.path.abspath(__file__))
file_path = os.path.join(curr_path, binary_name)
with open(file_path, 'rb') as file:
new_file = 'aa.flac'
with open(file_path, 'wb') as new_file:
chunk = 1024 * 100 # 定义每次读取的大小
while True:
#从旧文件中读取数据,每次100字节
context = file.read(chunk)
if not context:
break
new_file.write(context)
- 同时操作多个文件
# 把Tom+8 改成 8 Tom
with open('name_age.txt', 'r') as fread, open('age_name.txt', 'w') as fwrite:
line = fread.readline()
while line:
name, age = line.rstrip().split('+') # 列表解包
fwrite.write('{}-{}\n'.format(age, name))
line = fread.readline()
"""
比较两个文件内容是否相等
"""
import os.path
def file_compare(file1, file2):
differ = []
count = 0 # 统计行数
with open(file1, 'r') as f1, open(file2, 'r')as f2:
for line in f1:
line2 = f2.readline()
count += 1
if line != line2:
differ.append(count)
return differ
def main():
file1_path = os.path.join(file_path, 'a.txt')
file2_path = os.path.join(file_path, 'b.txt')
diff = file_compare(file1_path, file2_path)
if len(diff) == 0:
print('两个文件完全一样')
else:
print('两个文件共有 %s 处不同' %(len(diff)))
for item in diff:
print("第 %d 行不一样" % item)
if __name__ == '__main__':
main()
5.3、文件指针(File Pointer)
文件对象内部维护着一个“文件指针”,它记录了下一次读写操作应该在文件的哪个位置进行。
- tell(): 用来查看当前读取到的位置
- seek(offset, whence=0): 用来修改当前读取到的位置
- offset: 偏移量(字节)
- whence: 计算位置方式,文本模式不支持从当前/末尾位置偏移,二进制模式支持从当前/末尾位置偏移
* 0: 从头计算,默认值可省略
* 1: 从当前位置计算,往后/往后偏移,再从偏移后的位置开始往后读
* 2: 从末尾位置计算,往后/往后偏移,再从偏移后的位置开始往后读
with open(file_path, 'rt', encoding='utf-8') as file:
context = file.read(100)
context1 = file.read(10)
file.seek(20) # 将指针指向第20个字节处
print('当前读取到了:', file.tell())
with open(file_path, 'rb', encoding='utf-8') as file:
# 文本模式和二进制模式都可以从文件偏移量为0处读取
file.seek(0, 0) # 将指针切换到文本开头
file.seek(70, 0) # 将指针从开头切换到第70个字节,指针指向第70个字节位置处,从第70个字节开始往后读
# 只有二进制模式才能从当前位置位移或者末尾位置位移
file.seek(50, 1) # 将指针从当前70个字节位置开始,再往后累加50个字节,指针指向第120个字节位置处,从第120个字节开始往后读
file.seek(-40, 1) # 将指针从当前120个字节处,往前位移40个字节,此时指针指向第80个字节处,从第80个字节处往后读
file.seek(-100, 2) # 将指针从末尾位置开始,往前累加100个字节,指针指向倒数第100个字节处,从倒数第100个字节处往后读
5、sys 模块
import sys
* sys.argv: 接收命令行参数,返回一个list,第一个参数是文件名,后面跟着脚本参数
* sys.exit(n): 退出程序,正常退出时sys.exit(0),异常退出时sys.exit(1),n可以根据自定义配置
* sys.version: 获取python解释程序的版本信息
* sys.path: 返回模块的搜索路径,import模块时,解释器会根据这些路径搜索模块
* sys.platform: 返回操作系统平台名称
* sys.modules: 获取当前程序中引入的所有模块, 以字典形式保存所有参数
# 获取脚本参数
python3 test.py 'zkc' 18 'math'
input_data = sys.argv # # ['test,py', 'zkc', 18, 'math']
file_anme = input_data[0] # 文件名
user_name = input_data[1] # 第一个参数,以此类推
6、pickle 和 json模块
通过文件操作,我们可以将字符串写入到一个本地文件。但是,如果是一个对象(例如列表、字典、元组等),就无法直接写入到一个文件里,需要对这个对象进行序列化,然后才能写入到文件里。
1、把内存中数据变成可存储或传输的过程称 “序列化 pickling”
2、把数据从序列化的对象重新读到内存里称 “反序列化 unpickling”
json模块是将对象转换成为字符串,而pickle模块是将对象转换成为二进制
6.1、pickle
pickle 是 Python 内置的序列化模块,用于将 Python 对象(如字典、列表、类实例等)转换为字节流(序列化),或从字节流恢复为原始对象(反序列化)
import pickle
# 序列化(对象-字节流)
* pickle.dump(obj, file_obj): 将对象序列化成二进制后写入文件对象
* pickle.dumps(obj): 将对象序列化为二进制
# 反序列化(字符流-对象)
* pickle.load(file_obj): 从文件对象中读取二进制,并反序列化为对象
* pickle.loads(bytes): 将二进制反序列化为对象
data = {
"name": "Alice",
"age": 30,
"hobbies": ["reading", "coding"],
"is_student": False
}
# 对象 序列化成 二进制
pk_byte = pickle.dumps(data)
# 将二进制 反序列化成 对象
py_dict = pickle.loads(pk_byte)
# 将对象 序列化成 二进制 后写入文件,两个文件相同
with open('b.txt', 'wb+') as byte_file:
pickle.dump(data, byte_file)
with open('c.txt', 'wb+') as f:
f.write(pk_byte )
# 从文件读取二进制 反序列化成 对象
with open('b.txt', 'rb') as byte_file2:
py_dict2 = pickle.load(byte_file2)
print(py_dict, type(py_dict2))
6.2、json
import json
* json.dumps(obj): 将对象"序列化"成json字符串,只用来转换,不具备将数据写入到文件的功能
- indent=4: 指定了每个层级的缩进为4个空格
- sort_keys=True: 确保字典的键按照字母顺序排序的
- ensure_ascii=False: 不使用ASCII码(有中文时使用)
* json.loads(json_str): 将字符串"反序列化"为对象
* json.dump(obj, file_obj): 将对象"序列化"成字符串后写入文件对象,以json格式存储
- indent=4: 指定了每个层级的缩进为4个空格
- sort_keys=True: 确保字典的键按照字母顺序排序的
- ensure_ascii=False: 不使用ASCII码(有中文时使用)
* json.load(file_obj): 从文件对象中读取字符串,并"反序列化"为对象
json_str = '{"name": "Alice", "age": 30}'
# 字符串 反序列化成 对象
py_obj = json.loads(json_str)
# 对象 序列化成 字符串
json_str2 = json.dumps(py_obj)
# 对象 序列化成 字符串 后写入文件,两个文件相同
with open('a.txt', 'w+', encoding='utf-8') as file:
json.dump(py_obj, file, indent=4)
with open('c.txt', 'w+') as f:
f.write(json_str2)
# 从文件中读取字符串,反序列化成 对象
with open('a.txt', 'r', encoding='utf-8') as file1:
py_obj2 = json.load(file1)
print(py_obj2, type(py_obj2))
6.3、实例对象的序列化和反序列化
默认情况下,dumps()方法不知道如何将实例对象变为一个JSON对象
# 使用转换函数,将转换函数传递给dumps的default参数
class Student(object):
def __init__(self, name="NoOne", age=0, score=0):
self.name = name
self.age = age
self.score = score
def student2dict(std):
return {
"name": std.name,
"age": std.age,
"score": std.score
}
def dict2student(dic_type):
"""
返回值为一个对象实例,json.loads()解析时不会使用默认的dict类型解析
"""
return Student(dic_type['name'], dic_type['age'], dic_type['score'])
def dict3student(dic_type):
return Student(**dic_type)
s = Student("zkc", 30, 90)
# 实例对象 序列化成 json对象
stu_info = json.dumps(s, default=student2dict)
print(stu_info, type(stu_info))
# 一般类的实例中都有__dict__属性
stu_info1 = json.dumps(s,default=lambda obj:obj.__dict__)
# json对象 反序列化成 实例对象
stu_obj= json.loads(stu_info, object_hook=dict2student)
stu_obj1= json.loads(stu_info1, object_hook=dict3student)
# 使用转换类,传递给dumps的cls参数
class Student(object):
def __init__(self, name="NoOne", age=0, score=0):
self.name = name
self.age = age
self.score = score
"""
创建继承json.JSONEncoder的转换类,指定给实例对象
"""
class JsonEncoder(json.JSONEncoder):
def default(self, obj):
return obj.__dict__
"""
返回值为一个对象实例,参数为字典类型
"""
def dict3student(dic_type):
return Student(**dic_type)
s = Student("zkc", 30, 90)
# 实例对象 序列化成 json对象
stu_info = json.dumps(s, cls=JsonEncoder)
print(stu_info, type(stu_info))
# json对象 反序列化成 字典
stu_dict = json.loads(stu_info)
# json对象 反序列化成 实例对象
stu_obj= json.loads(stu_info, object_hook=dict3student)
7、String模块
7.1、% 占位符
# 语法:
"字符串 %s %d" % (变量1, 变量2)
# 常用占位符:
%s: 字符串
%d: 整数
%f: 浮点数,保留以为小数点 %.1f
# 映射:
* 元组或字典
# 元组传值
name = "小明"
age = 17
print("my name is %s,my age is %d" % (name, age))
# 字典传值
city = {"addr": "兰州", "school": "兰州交通大学"}
print("City:%(addr)s, school:%(school)s" % city)
data = {"name": "Bob", "score": 97.5}
print("Student: %(name)s,Score: %(score).1f" % data)
7.2、format格式化
| 语法 | 含义 | 示例 |
|---|---|---|
| {:<10} | 左对齐(宽度10) | “{:<10}”.format(“hi”) → 'hi ’ |
| {:>10} | 右对齐 | “{:>10}”.format(“hi”) → ’ hi’ |
| {:^10} | 居中对齐 | |
| {:.2f} | 保留两位小数 | |
| {:,} | 千位分隔符 | “{:,}”.format(1234567) → ‘1,234,567’ |
| {:.3s} | 截断字符串到3字符 | “{:.3s}”.format(“python”) → ‘pyt’ |
| {!r} | 使用 repr() | “{!r}”.format(“hi”) → “‘hi’” |
| {!a} | 使用 ascii() | |
| {!s} | 使用 str() (默认) |
# 语法:
"字符串 {变量名} {索引}".format(变量)
"template string".format(*args, **kwargs)
# 用法:
1. 位置占位符:
{}、{0}、{1}
2. 关键字占位符:
{name}
3. 格式说明符:
{value:format_spec}
4. 左右对齐:
>代表右对齐,>前是要填充的字符,>后是填充后字符串宽度
<代表左对齐,<前是要填充的字符,<后是填充后字符串宽度
^代表左对齐,^前是要填充的字符,^后是填充后字符串宽度
name = "小明"
age = 17
# 1、按位置
text = "我叫{},今年{}岁了".format(name, age)
# 2、按索引,可重复使用
text = "我叫{0}, 今年{1}岁了".format(name, age)
text = "{0} {1} {0}".format("hello", "world")
# 3、按关键字
text = "我叫{name},今年{age}岁了".format(name=name, age=age)
text = "{name} scored {score:.1f}".format(name="Bob", score=95.567)
# 4、匹配字典中的参数
dict = {"name1": "Beijing", "name2": "city"}
str1 = "{name1} is a beautiful {name2}!".format(**dict)
# 5、匹配列表中的参数
list = ["Beijing", "city"]
str1 = "{} is a beautiful {}!".format(*list)
str2 = "{1} is a beautiful {0}!".format(*list)
# 6、模板
template = '{name} is {age} years old.'
text = template.format(name=name, age=age))
# 7、类对象格式化
class Names:
Name1 = "Beijing"
Name2 = "city"
str1 = "{names.Name1} is a beautiful {names.Name2}!".format(names=Names)
# 7、高级格式化
# 保留2位小数
print("价格: {:.2f}".format(19.9)) # 19.90
# 百分比
print("完成率: {:.2%}".format(0.85)) # 85.00%
# 补齐位数
print("编号:{:0>4d}".format(5)) # 0005
for x in ['*', '****', '*******']:
progress_bar = '{:-<10}'.format(x)
progress_bar = '{:+>10}'.format(x)
progress_bar = '{:@^10}'.format(x)
7.3、f-string格式化
# 语法:
f"字符串 {变量} {表达式}"
name = "小红"
age = 18
text = f"我叫{name},今年{age}岁了"
# 2、直接计算表达式
a, b = 10, 20
print(f"a + b = {a + b}") # a + b = 30
print(f"Next year, {name} will be {age + 1}")
# 多行 f-string
msg = f"""
User: {name}
Age: {age}
"""
# 3、高级格式化
# 保留2位小数
pi = 3.1415926
print(f"π ≈ {pi:.2f}") # 3.14
# 百分比
score = 0.95
print(f"得分:{score:.1%}") # 95.0%
x = 42
print(f"{x=}") # 输出x=42
print(f"{x=:.2f}") # x=42.00
7.4、string.Template
用于用户输入需要被安全插入模板的场景(比如配置文件、邮件模板)。它限制表达式能力,避免任意代码执行
# 语法:
占位符: $identifier 或 ${identifier}
# 方法:
* substitute(**mapping): 缺少键时抛出 KeyError
* safe_substitute(**mapping): 缺少键时保留占位符原样
from string import Template
name = "Alin"
age = 17
# 定义模板
template = Template("我叫$name,今年$age岁了")
# 使用关键字参数渲染数据
info = template.substitute(name=name, age=age)
t = Template("Hello $name, your score is ${score}%")
result = t.substitute(name="Alice", score=95)
# 使用字典传参渲染数据
data = {"name": "Bob", "age": 17}
message = template.substitute(data)
# 使用 safe_substitute
t2 = Template("$name is $age years old")
res = t2.safe_substitute(name="Bob") # Bob is $age years old
# 自定义分隔符
# 通过继承Template并修改delimiter属性实现
class MyTemplate(Template):
delimiter = "@"
data = {"name": "zkc", "msg": "hello"}
t = MyTemplate("@name says: @msg")
# 渲染数据
print(t.safe_substitute(data))
# 邮件内容模板
email_template = """
尊敬的 $username:
您好!您的订单 $order_id 已发货。
订单金额:¥${price:.2f}
"""
order_info = {
"username": "zkc",
"order_id": 2025052401,
"price": 95.5
}
# 渲染数据
template = Template(email_template)
email = template.safe_substitute(order_info)
9、模块和包
9.1、模块module
Python中,一个py文件就是一个模块,创建模块就是创建一个py文件
# 模块化:
将一个完整的程序,分解为多个的小模块,通过将模块组合,搭建出一个完整的程序
# 模块的类别:
1. Python自带模块(在./python/Lib路径下)
2. 第三方模块(pip安装)
3. 自定义模块(写好*.py放到./python/Lib路径下)
# 模块化优点:
1. 方便开发和维护
2. 模块可以复用
* 同一模块可以导入多次,但模块的实例之创建一个
* import可以在程序的任何位置使用,但一般写在程序的开头
* 每个模块内部 都有一个"__name__"属性,可以显示引用进来的模块的名字
* __name__的属性值为__main__的模块是主模块,一个程序只有一个主模块。用python执行哪个py文件,哪个就是主模块
* 私有变量/方法不会被引入,如"_name" ,只能在模块内部访问
1. 创建与导入模块:
* 创建模块: 创建一个模块只需要创建一个.py文件
* 导入模块:在另一个文件中,可使用import语句来导入并使用创建的模块
1. 导入特定某个函数: from test_module import test_func
2. 导入特定函数并且起别名: from test_module import test_funcas tf
3. 导入整个模块: import test_module
4. 导入整个模块并起别名: import test_module as tm
5. 导入模块中的所有函数: from test_module import *
9.2、包Package
包就是包含多个模块的文件夹。
当模块数量增多时,使用Package来组织它们
要让Python将一个文件夹视为一个包,这个文件夹中必须包含一个(可以是空的)名为__init__.py的文件
* 当一个包被导入时,__init__.py文件会被自动执行
* 可以在这里进行包的初始化工作,或使用__all__变量来定义from package import *时应该导入哪些模块
my_project/
├── main.py
└── my_app/
├── __init__.py
├── utils/
│ ├── __init__.py
│ └── string_helpers.py
└── models/
├── __init__.py
└── user.py
在这个结构中,my_app、my_app.utils和my_app.models都是包
# 从包中导入: 可以使用点"."从包中导入模块
from my_app.models import user
from my_app.utils.string_helpers import capitalize_name
user_instance = user.User("alice")
capitalized = capitalize_name("bob")
五、Python错误与异常处理
语法错误:
又称解析错误,即编写的程序没有通过语法的检查。
异 常:
运行期间检测到的错误,解释器会尝试处理,如果无法处理则程序会终止并提示错误信息。
5.1、处理异常
程序运行过程中,一旦出现异常将会导致程序运行立即终止,异常代码之后的所有代码将不会再执行。
python希望在出现异常时,我们可以编写代码对异常进行处理,避免因为一个异常,导致整个程序的终止。
- try语句的代码,如果没有错误,则正常执行。如果有错误,则执行except子句中的代码
- except 后 "使用元组指定 不同的异常 执行 相同的处理异常的代码"
- except 后 "不跟任何类型或者跟Exception,则会捕获所有的异常"
- Exception是所有异常的父类,也会捕获所有异常
- except 后跟具体异常类型,则只会捕获该类型的异常
- 使用 as e,将异常对象赋值给e,可看到具体的异常信息
# 捕获异常
try:
代码块(可能出现错误的语句)
except [异常类型1] as [异常名,e/其他]:
代码块(出现错误以后的处理方式)
except [异常类型2] as [异常名,e/其他]:
代码块(出现错误以后的处理方式)
except (异常类型3, 异常类型4) as [异常名,e/其他]:
代码块(出现错误以后的处理方式)
else:
代码块("try中没出错时要执行的代码")
finally:
代码块("无论是否出现异常,该子句都会执行")
5.2、异常的传播
- 当在函数中出现异常,如果在函数中对异常进行了处理,则异常不会再继续传播
- 如果函数中没有对异常进行处理,则异常会继续向函数调用处传播。如果处理,则不再传播
- 如果函数调用处没有处理异常,则继续向调用处传播,以此类推
- 直到传递到全局作用域,如果没有处理,则程序终止,并且显示异常信息
- 程序不仅会处理在try子句中立刻发生的异常,还会处理在try子句中调用(包括间接调用)的函数
def fn():
print('fn')
print(10/0)
def fun2():
print('fn2')
fn()
def fun3():
print('fn3')
fn2()
fn3()
# 输出结果
Traceback (most recent call last):
File "E:execute.py", line 10, in <module>
fn3()
File "E:execute.py", line 9, in fn3
fn2()
File "E:execute.py", line 6, in fn2
fn()
File "E:execute.py", line 3, in fn
print(10/0)
ZeroDivisionError: division by zero
5.3、raise触发异常
-
触发异常(也称异常抛出):
使用raise语句,支持强制触发指定的异常,其参数必须是异常实例或异常类(派生自BaseException类,如Exception或其子类) -
异常链:
若在 except 部分内发生未处理的异常,将会有已被处理的异常附加到 它上面,并包括在错误信息中。
为了表明一个异常是另一个异常的直接后果, raise 语句使用 from None/exec 表达禁用/启用自动异常链。
raise [ExceptionType [, args [, traceback]]]
# 常规使用格式
# raise 语句如果不带参数,就会把当前错误原样抛出
raise # 触发异常后若不处理该异常,使用raise重新触发
raise ExceptionType
raise ExceptionType(**args)
raise ExceptionType from [exc, None]
# 抛出指定异常
try:
if 'a' > '0':
raise TypeError("TypeError.")
else:
raise NameError("NameError.")
except (TypeError,NameError) as errvalue:
print("异常原因:",errvalue)
# 异常原因: TypeError
# 直接抛出
def foo(s):
n = int(s)
if n==0:
raise ValueError('invalid value: %s' % s)
return 10 / n
def bar():
try:
foo('0')
except ValueError as e:
print('ValueError!')
raise
bar()
# 启动异常链
def func():
print("open database.sqlite")
raise ConnectionError
try:
func()
except ConnectionError as exc:
raise RuntimeError('Failed to open database') from exec
# 执行结果:
# open database.sqlite
# Traceback (most recent call last):
# ConnectionError
# During handling of the above exception, another exception occurred:
# Traceback (most recent call last):
# TypeError: exception causes must derive from BaseException
# 禁用自动异常链
try:
open('database.sqlite')
except OSError as exc:
raise RuntimeError("Failed to open database") from None
# 执行结果:
# open database.sqlite
# Traceback (most recent call last):
# RuntimeError: Failed to open database
5.4、异常注释
在一个异常被创建以引发时,通常被初始化为描述所发生错误的信息,此时我们可以使用 BaseException 异常类型中的 add_note(note) 方法, 在异常实例中附加相信额外的信息,并将其添加到异常的注释列表。
try:
raise TypeError('bad type')
except Exception as e:
e.add_note('Add info')
e.add_note('Add more info')
raise
# 执行结果:
# Traceback (most recent call last)
# TypeError: bad type
# Add info
# Add more info
5.5、自定义异常类
在Python中自定义异常是一种用于处理特定错误情况的强大工具,通过定义自定义异常,可以提高代码的可读性和可维护性。
class DetailedError(Exception):
"""
Exception raised for detailed errors.
Attributes:
code -- error code
message -- explanation of the error
"""
def __init__(self, code, message):
self.code = code
self.message = message
super().__init__(self.message)
def __str__(self):
return f"[Error {self.code}]: {self.message}"
def process_data(data):
if not isinstance(data, list):
raise DetailedError(1001, "Data must be a list")
if not data:
raise DetailedError(1002, "Data list is empty")
# Process data...
return "Processing complete"
try:
process_data({})
except DetailedError as e:
print(f"Caught an exception: {e}")
5.6、常见问题
1、try语句中包含break、continue或return语句,则finally子句在执行break、continue或return语句之前执行。
# 底层执行流程:
1. 代码进入try
2. 遇到return/break/continue
3. 暂停这个动作
4. 立刻执行finally
5. finally执行完
6. 再真正执行 return/break/continue
def test():
try:
print("进入try")
return "返回值"
finally:
print("finally 先执行")
# try语句包含break/continue
while True:
try:
print("进入try")
break # 准备跳出循环
# continue
finally:
print("finally先执行")
print("循环结束")
2、如果finally子句中包含break、continue或return等语句,异常将不会被重新引发
# finally子句包含return
def test():
try:
raise ValueError("我出错啦!") # 抛出的异常
finally:
return "ok" # finally 优先执行
print(test()) # 输出: ok
# 异常完全消失
# finally子句包含break/continue
while True:
try:
raise Exception("报错了")
finally:
break # 直接跳出循环,异常被丢弃
#continue # 直接进入下一轮循环,异常被丢弃
print("执行结束") # 会正常执行
3、如果 finally 子句中包含 return 语句,则返回值来自 finally 子句的某个 return 语句的返回值,而不是来自 try 子句的 return 语句的返回值
只要 finally里写了return,不管try里return了什么,最终生效的永远是 finally 的返回值。
try 里的返回值会被覆盖,try里的异常会被吃掉,最终只认finally里的return
# 执行流程:
1. 进入try,执行到return "try的值"
2. Python先把返回值暂存起来,但不真正返回
3. 强制执行finally
4. 发现finally 里也有return
5. 直接用finally 的返回值覆盖之前暂存的值
6. 函数结束,只返回finally的结果
def test():
try:
return "我是 try 里的返回值" # 准备返回这个
finally:
return "我是 finally 里的返回值" # 最终返回这个!
print(test())
5.7、内置异常
BaseException # Python所有内置异常的最顶层父类,包含系统退出、中断、普通业务异常
├── BaseExceptionGroup # 异常组,可将下述异常打包到序列 excs 中
├── GeneratorExit # 当 generator 或 coroutine 被主动关闭时抛出
├── KeyboardInterrupt # 当用户按下中断键 (Ctrl+C) 时抛出
├── SystemExit # 当执行 sys.exit() 函数程序主动退出时触发
└── Exception # 所有内置的非系统退出类异常都派生自此类
├── ArithmeticError # 所有算术运算错误总基类
│ ├── FloatingPointError # 浮点数运算出错
│ ├── OverflowError # 数值运算结果超出当前类型存储范围
│ └── ZeroDivisionError # 除法 / 取模运算除数为 0
├── AssertionError # assert 断言条件不成立时将被引发
├── AttributeError # 访问/赋值对象不存在的属性时触发
├── BufferError # 缓冲区相关操作执行失败
├── EOFError # input() 函数未读取任何数据即达到文件结束条件(EOF) 时触发
├── ExceptionGroup [BaseExceptionGroup]
├── ImportError # 当 import导入/加载模块失败时触发
│ └── ModuleNotFoundError # 找不到指定导入的模块
├── LookupError # 当映射或序列所使用的键或索引无效时引发的异常
│ ├── IndexError # 序列下标超出有效范围
│ └── KeyError # 字典中不存在指定键
├── MemoryError # 程序内存耗尽,仍有恢复可能性(通过删除一些对象)
├── NameError # 访问未定义的全局 / 局部变量名
│ └── UnboundLocalError # 函数内读取声明后未赋值的局部变量
├── OSError # 操作系统底层调用、文件 IO 相关错误总基类
│ ├── BlockingIOError # 非阻塞 IO 无数据可读写
│ ├── ChildProcessError # 子进程执行失败、返回非 0 状态码
│ ├── ConnectionError # 网络连接相关错误总基类
│ │ ├── BrokenPipeError # 管道 / 套接字另一端已关闭,无法写入
│ │ ├── ConnectionAbortedError # 连接被本地操作系统终止
│ │ ├── ConnectionRefusedError # 对方端口未开放,拒绝连接
│ │ └── ConnectionResetError # 远程主机强制断开连接
│ ├── FileExistsError # 创建已存在的文件 / 目录
│ ├── FileNotFoundError # 访问不存在的文件 / 路径
│ ├── InterruptedError # 系统调用被信号中途打断
│ ├── IsADirectoryError # 把目录当作普通文件操作
│ ├── NotADirectoryError # 路径不是目录,却执行目录操作
│ ├── PermissionError # 权限不足,无法读写 / 执行文件
│ ├── ProcessLookupError # 操作不存在的进程 ID
│ └── TimeoutError # 系统操作超时未完成
├── ReferenceError # 使用 weakref.proxy() 函数所创建的弱引用来访问该引用的某个已被作为垃圾回收的属性时被引发。
├── RuntimeError # 当检测到一个不归属于任何其他类别的错误时将被引发
│ ├── NotImplementedError
│ └── RecursionError
├── StopAsyncIteration # 异步迭代器无更多元素
├── StopIteration # 普通迭代器无更多元素
├── SyntaxError # 当解析器遇到语法错误时引发。
│ └── IndentationError
│ └── TabError
├── SystemError # 当解释器发现内部错误,但情况看起来尚未严重到要放弃所有希望时将被引发。
├── TypeError # 当一个操作或函数被应用于类型不适当的对象时将被引发。
├── ValueError # 数据类型正确,但数值不符合函数要求
│ └── UnicodeError
│ ├── UnicodeDecodeError
│ ├── UnicodeEncodeError
│ └── UnicodeTranslateError
└── Warning # 所有警告类别的基类。
├── BytesWarning
├── DeprecationWarning
├── EncodingWarning
├── FutureWarning
├── ImportWarning
├── PendingDeprecationWarning
├── ResourceWarning
├── RuntimeWarning
├── SyntaxWarning
├── UnicodeWarning
└── UserWarning



















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












