




背景
人类不会每秒钟都从头开始思考。当你阅读这篇文章时,你会根据你对以前单词的理解来理解每个单词。你不会把所有东西都扔掉,重新开始思考。你的思想是持久的。
传统的神经网络无法做到这一点,这是一个主要缺点。递归神经网络(Rnn)解决了这个问题,这是一种带有记忆的模型,可以将其认为是同一网络的多个副本,每个副本将消息传递给继任者。

RNN的优势是,它们可能能够将先前的信息与当前任务联系起来,例如使用以前的视频帧为理解当前帧提供信息。但是在实际情况中,它不一定能做到这一点。
有时我们只需要查看最近的信息即可执行当前任务。例如,考虑一个语言模型,它试图根据前一个单词来预测下一个单词。如果我们试图预测“云在天空中”中的最后一个词,我们不需要任何进一步的上下文,很明显下一个词将是天空。在这种情况下,相关信息与需要信息的地方之间的差距很小,RNN可以学习使用过去的信息。
但在某些情况下,我们需要更多的背景信息。不妨试着预测经文中的最后一个字:“我在法国长大…我能说一口流利的法语。最近的信息表明,下一个词可能是一种语言的名称,但如果我们想缩小哪种语言的范围,我们需要从更远的地方开始了解法国的上下文。相关信息与需要信息的点之间的差距完全有可能变得非常大。
不幸的是,随着这种差距的扩大,RNN变得无法学习连接信息。这就是传统RNN的缺点,很难处理长距离的依赖。
长短期记忆网络(通常简称为“LSTM”)解决了这个问题,这是一种特殊的RNN,能够学习长期依赖关系。我们将推导LSTM中每一层的结构,并实现一个pytorch版本LSTM。
推导
长短时记忆网络的思路很简单。传统RNN的隐藏层只有一个状态,即h,它对于短期的输入非常敏感,假如我们再增加一个状态,即c,让它来保存长期的状态,那么问题就解决了:
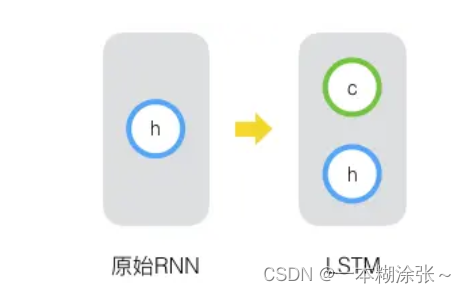
新增加的状态c,称为单元状态(cell state)。我们把上图按照时间维度展开:
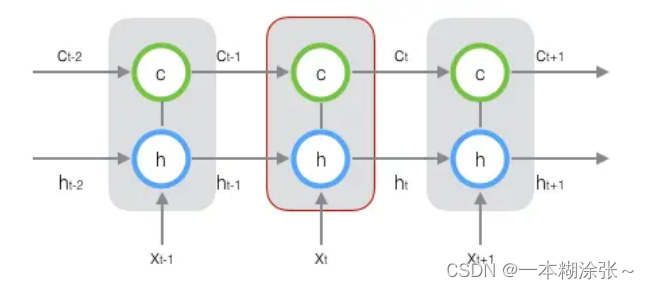
在长短时记忆网络的前向计算中,通过门(gate)控制向量的变化。门实际上就是一层全连接层,它的输入是一个向量,输出是一个0到1之间的实数向量。那么门可以表示为: g ( x ) = σ ( W x + b ) g(x)=\sigma(Wx+b) g(x)=σ(Wx+b) 由于sigmod函数的性质,门的输出是0到1之间的实数向量,那么,当门输出为0时,任何向量与之相乘都会得到0向量;输出为1时,任何向量与之相乘都不会有任何改变。
LSTM用两个门来控制单元状态c的内容,一个是遗忘门(forget gate),它决定了上一时刻的单元状态有多少保留到当前时刻ct;另一个是输入门(input gate),它决定了当前时刻网络的输入xt有多少保存到单元状态ct。LSTM用输出门(output gate)来控制单元状态ct有多少输出到LSTM的当前输出值ht。
遗忘门
遗忘门通过门控制上一时刻的输入的单元状态 c t − 1 c_{t-1} ct−1有多少被保留下来,门的权值通过上一时刻的输出值 h t − 1 h_{t-1} ht−1和这一时刻的输入值 x t x_t xt得到,即: f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f\cdot[h_{t-1},x_t]+b_f) ft=σ(Wf⋅[ht−1,xt]+bf) 这个过程可以被分解为 f t = W f h h t − 1 + W f h x t f_t=W_{fh}h_{t-1}+W_{fh}x_t ft




















&spm=1001.2101.3001.5002&articleId=139295601&d=1&t=3&u=98b1edbc6d414c23a9b51fa6ed85a572)
 1985
1985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












