




题目
给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 ‘.’ 和 ‘*’ 的正则表达式匹配。
‘.’ 匹配任意单个字符
‘*’ 匹配零个或多个前面的那一个元素
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
示例 1:
输入:s = “aa” p = “a”
输出:false
解释:“a” 无法匹配 “aa” 整个字符串。
示例 2:
输入:s = “aa” p = “a*”
输出:true
解释:因为 ‘*’ 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 ‘a’。因此,字符串 “aa” 可被视为 ‘a’ 重复了一次。
示例 3:
输入:s = “ab” p = “."
输出:true
解释:".” 表示可匹配零个或多个(‘*’)任意字符(‘.’)。
示例 4:
输入:s = “aab” p = “cab”
输出:true
解释:因为 ‘*’ 表示零个或多个,这里 ‘c’ 为 0 个, ‘a’ 被重复一次。因此可以匹配字符串 “aab”。
示例 5:
输入:s = “mississippi” p = “misisp*.”
输出:false
提示:
0 <= s.length <= 20
0 <= p.length <= 30
s 可能为空,且只包含从 a-z 的小写字母。
p 可能为空,且只包含从 a-z 的小写字母,以及字符 . 和 *。
保证每次出现字符 * 时,前面都匹配到有效的字符
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/regular-expression-matching
解题:
class Solution {
public:
// isMatch("aa", "a"); 第一步 s[0] == p[0]相等,
// 第二步调用isMatch("a", ""); !s.empty() && p.empty() 返回false
bool isMatch(string s, string p) {
if (p.empty()) {
return s.empty();
}
if (!s.empty() && (s[0] == p[0] || p[0] == '.')) {
// 匹配一个字符,则往后去匹配下一个字符
if (p.size() >= 2 && p[1] == '*') { // *匹配0个或多个
//if (s.size() == 1 && p.size() == 2) // s最后一个字符命中且p也匹配结束
//return true;
// 匹配0个,则s不变,p减去二个字符
// 匹配多个,则s减掉匹配的这个字符,p不变
return isMatch(s, p.substr(2)) || isMatch(s.substr(1), p);
} else {
// 字符相等,则匹配下一个
return isMatch(s.substr(1), p.substr(1));
}
} else {
if (p.size() >= 2 && p[1] == '*') // 字符不相等,就尝试不匹配,因为*可匹配0个字符
return isMatch(s, p.substr(2));
else
return false;
}
}
};
算法
1. 算法定义
算法是解决特定问题的一系列明确指令步骤,具有以下特性:
有穷性:必须在有限步骤内结束。
确定性:每一步骤无歧义。
可行性:可通过基本操作实现。
输入/输出:有零或多个输入,至少一个输出。
2. 算法分类
(1) 按设计范式
类型 特点 典型算法
分治法 将问题分解为子问题递归求解 归并排序、快速排序
动态规划 通过存储子问题解避免重复计算 背包问题、最短路径(Floyd)
贪心算法 每一步选择局部最优解 Dijkstra算法、霍夫曼编码
回溯法 尝试所有可能的解并通过剪枝优化 N皇后问题、数独求解
分支限界法 结合广度优先搜索与剪枝策略 旅行商问题(TSP)
(2) 按应用领域
排序算法:快速排序、堆排序、桶排序
搜索算法:二分查找、深度优先搜索(DFS)、广度优先搜索(BFS)
图算法:最小生成树(Prim/Kruskal)、拓扑排序
加密算法:RSA、AES、SHA-256
3. 复杂度分析
衡量算法效率的核心指标:
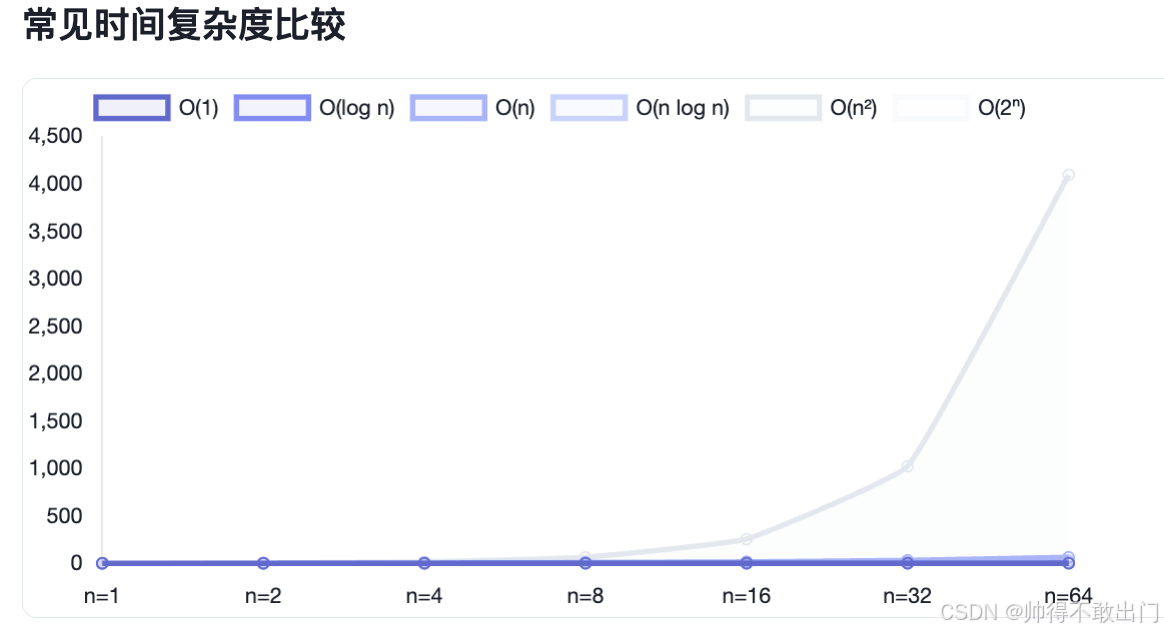
时间复杂度:执行所需时间随输入规模的增长趋势
(常见:O(1)、O(log n)、O(n)、O(n²)、O(2ⁿ))
空间复杂度:执行所需额外内存空间
示例对比:
算法 平均时间复杂度 空间复杂度 稳定性
冒泡排序 O(n²) O(1) 稳定
快速排序 O(n log n) O(log n) 不稳定
归并排序 O(n log n) O(n) 稳定
4. 算法设计技巧
(1) 递归 vs. 迭代
递归实现斐波那契数列
def fib(n):
if n <= 1: return n
return fib(n-1) + fib(n-2) # 时间复杂度O(2ⁿ)
迭代优化(动态规划)
def fib_dp(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b # 时间复杂度O(n)
return a
(2) 空间换时间
哈希表:用O(n)空间将查找时间从O(n)降至O(1)
前缀和数组:预处理数组以实现区间和的快速查询
5. 实际应用场景
推荐系统:协同过滤算法(基于用户/物品的相似度)
路径规划:A*算法(结合启发式搜索)
数据压缩:LZ77、DEFLATE(ZIP文件基础)
机器学习:梯度下降(模型优化核心)
6. 学习资源推荐
书籍
《算法导论》——经典理论教材
《算法图解》——入门友好型
在线平台
LeetCode(面试向)
Codeforces(竞赛向)
可视化工具
VisuAlgo(https://visualgo.net/)
7. 常见误区
过度追求最优解:实际工程中常需权衡效率与可维护性。
忽视边界条件:如空输入、极端值处理。
混淆时间/空间复杂度:例如递归算法的栈空间消耗。
作者:帅得不敢出门


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












