




文章目录
实验1:Hadoop大数据平台安装实验
1. 实验目的
在大数据时代,存在很多开源的分布式数据采集、计算、存储技术,本实验将在熟练掌握几种常见Linux命令的基础上搭建几种常用的大数据采集、处理分析技术环境。
2. 实验环境
相关安装包下载:
链接:https://pan.baidu.com/s/1Wa2U3qstc54IAUCypcApSQ
提取码:lcd8
Hadoop大数据平台所需工具、软件包、版本及安装目录见下表:
| 软件包名 | 软件名称 | 版本 | 安装 |
|---|---|---|---|
| jdk-7u80-linux-x64.tar.gz | java软件开发工具包 | 1.7.80 | /usr/local/jdk1.7.0_80 |
| mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz | MySQL | 5.6.37 | /usr/local/mysql |
| zookeeper-3.4.6.tar.gz | Zookeeper | 3.4.6 | /usr/local/zookeeper-3.4.6 |
| kafka_2.10-0.8.2.1.tgz | Kafka | 2.10.-0.8.2.1 | /usr/local/kafka_2.10.-0.8.2.1 |
| hadoop-2.6.5.tar.gz | Hadoop | 2.6.5 | /usr/local/hadoop-2.6.5 |
| hbase-1.2.6-bin.tar.gz | HBase | 1.2.6 | /usr/local/hbase-1.2.6 |
| apache-hive-1.1.0-bin.tar.gz | Hive | 1.1.0 | /usr/local/apache-hive-1.1.0-bin |
| mysql-connector-java-5.1.43-bin.jar | MySQL JDBC驱动 | 5.1.43 | /usr/local/mysql |
| scala-2.10.6.tgz | Scala | 2.10.6 | /usr/local/scala-2.10.6 |
| spark-1.6.3-bin-hadoop2.6.tgz | Spark | 1.6.3 | /usr/local/spark-1.6.3-binhadoop2.6 |
| apache-storm-1.1.1.tar.gz | Storm | 1.1.1 | /usr/local/apache-storm-1.1.1 |
所有虚拟机上需要安装的软件与服务如下表:
| 主机名 | 服务器名 |
|---|---|
| cluster1 | zookeeper, Kafka, HDFS(主), YARN(主), HBase(主), Hive, Spark(主), storm(主) |
| cluster2 | zookeeper, Kafka, MySQL, HDFS, YARN, HBase, Hive, Spark, storm |
| cluster3 | zookeeper, Kafka, HDFS, YARN, HBase, Hive, Spark, storm |
3. 实验过程
3.1 虚拟机的搭建
3.1.1 安装虚拟机
-
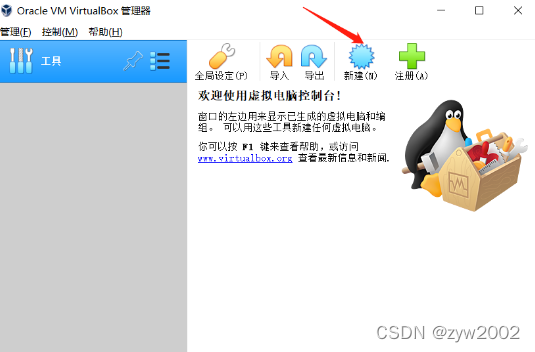
首先下载VirtualBox,点击新建
-
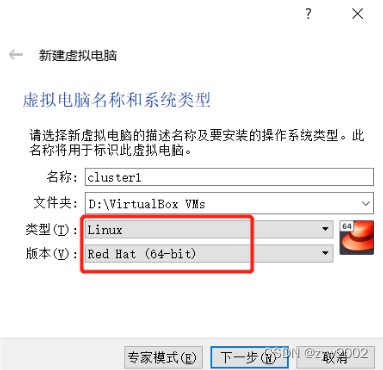
类型选择linux,版本选择Red Hat (64-bit)
-
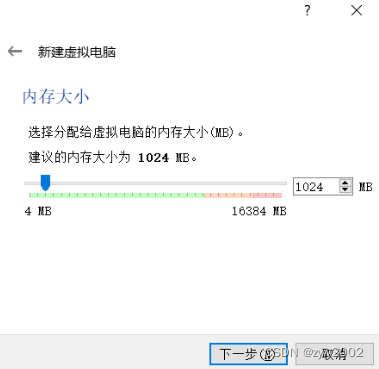
内存大小为1024B
-
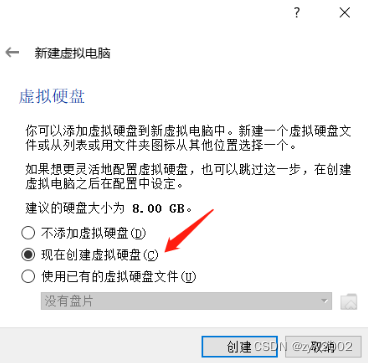
选择现在创建虚拟硬盘
-
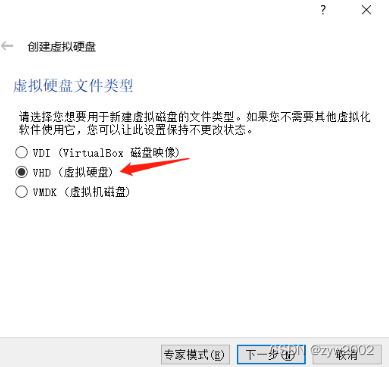
VHD
-
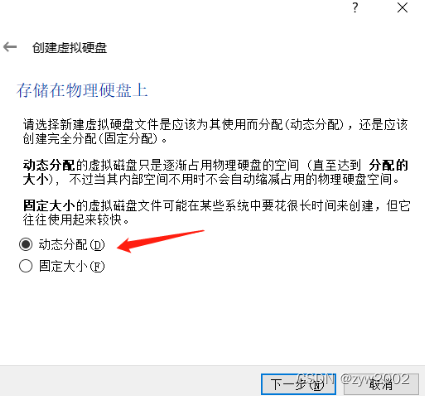
动态分配
-
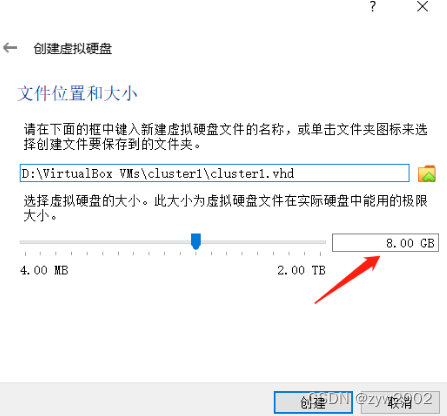
8.00GB
-
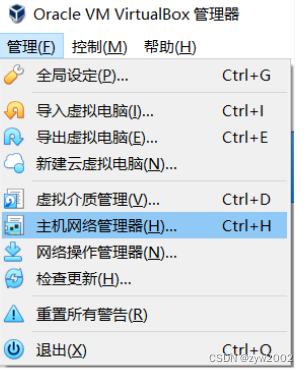
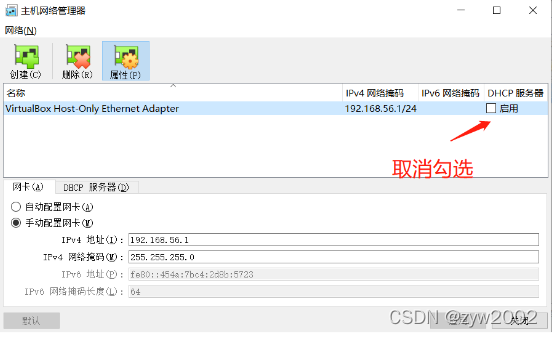
管理——>主机网络管理器
-
取消勾选DHCP;网卡—>手动配置网卡:IPv4
192.168.56.1网络掩码255.255.255.0
-
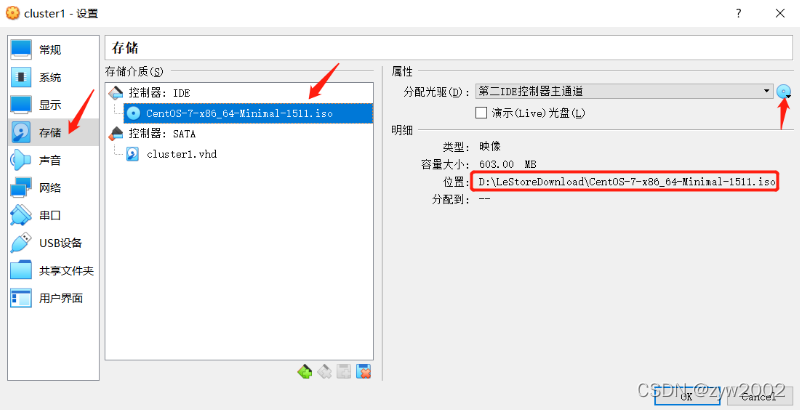
存储——>选择centos7的iso文件
-
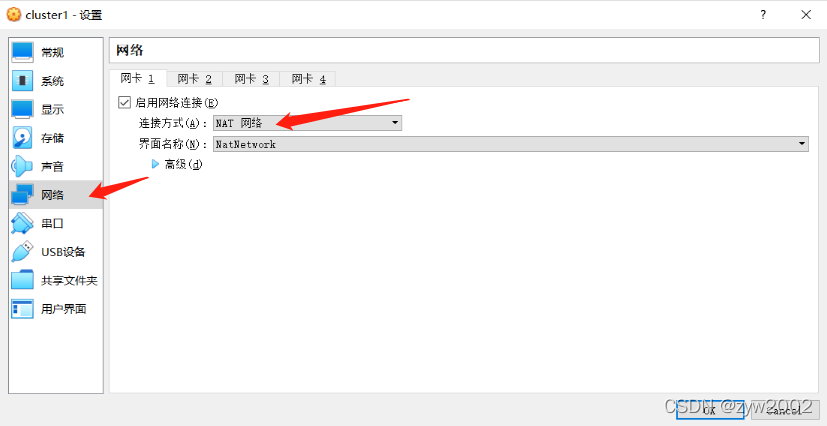
网络——>网卡1——>NAT网络
-
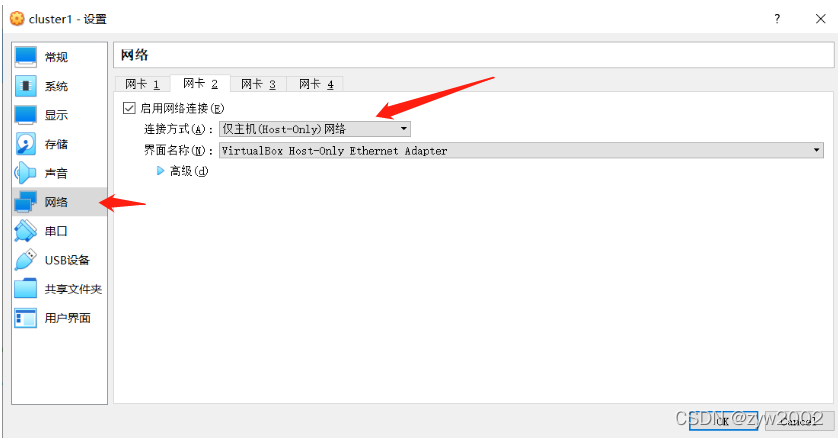
网路——>网卡2——>Host-Only网路
-
开机——>中文
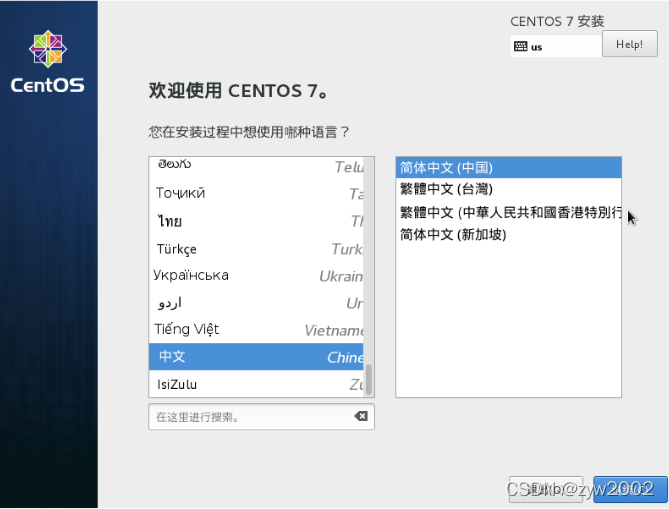
-
日期与时间——>上海——>完成
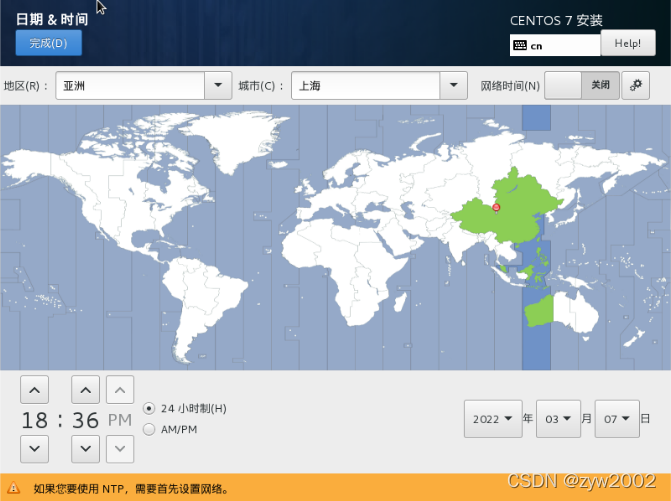
-
安装目标位置——>完成
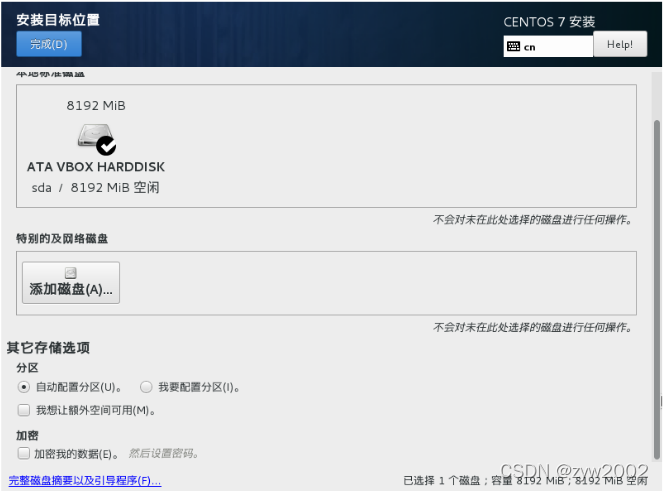
-
网路和主机名——>以太网(enp0s3)——>开启——>主机名:cluster1 (cluster2\cluster3)
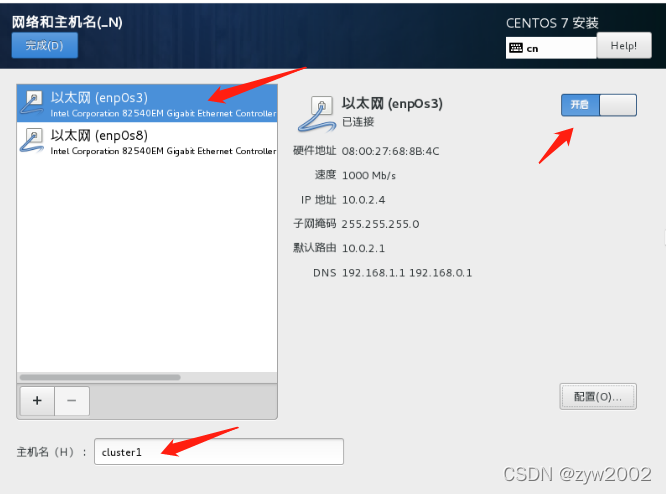
-
网路和主机名——>以太网(enp0s8)——>开启
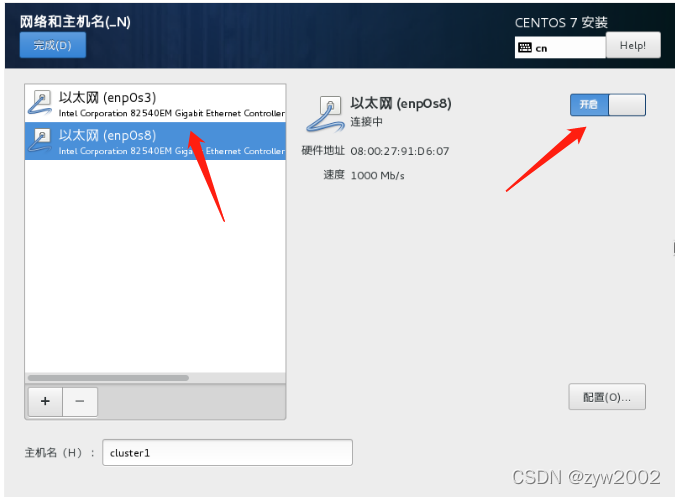
-
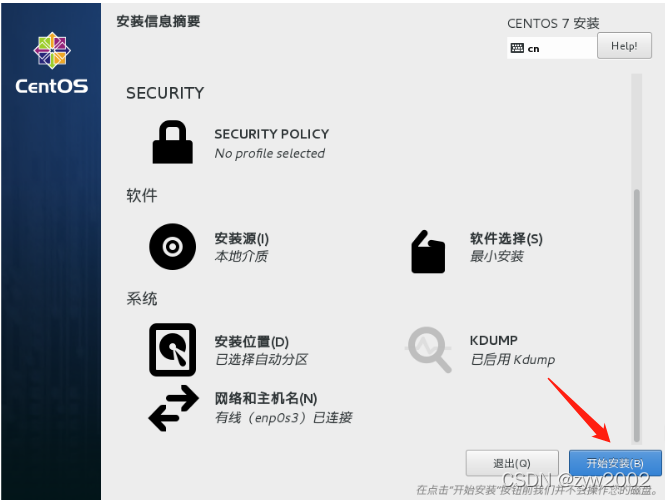
开始安装
-
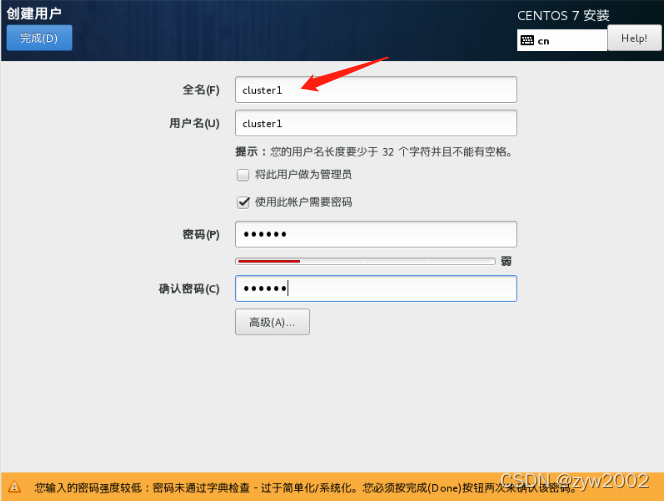
创建用户——>全名:cluster1 ; 设置root密码;完成配置
-
重启
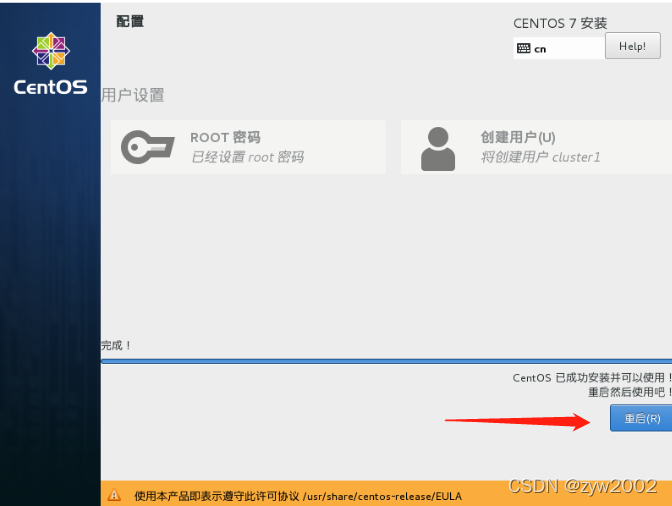
按照上述的方法,再构建两台同样的虚拟机,分别为cluster2和cluster3
3.1.2 基本linux命令
首先以root身份登入cluster1
-
创建一个初始文件夹,以自己的姓名(英文)命名
mkdir zyw;进入该文件夹cd zyw,在这个文件夹下创建一个文件,命名为Hadoop.txt,touch Hadoop.txt

-
查看这个文件夹下的文件列表
ls。

-
在Hadoop.txt中写入“Hello Hadoop!”
vi Hadoop.txt,并保存:wq

-
在该文件夹中创建子文件夹”Sub”
mkdir Sub,随后将Hadoop.txt文件移动到子文件夹中mv Hadoop.txt ~/zyw/Sub

-
递归的删除整个初始文件夹
rm -rf ~/zyw/

3.2 准备工作
3.2.1 关闭Selinux
每台都要执行(我们安装的centOS最小版没有防火墙,在其他centOS上操作时必须要关闭防火墙)
// 关闭防火墙
# systemctl stop firewalld.service
// 禁止firewall 开机启动
# systemctl disable firewalld.service
// 开机关闭Selinux,编辑Selinux配置文件
# vi /etc/selinux/config
将SELINUX设置为disabled 如下: SELINUX=disabled
// 重启
# reboot
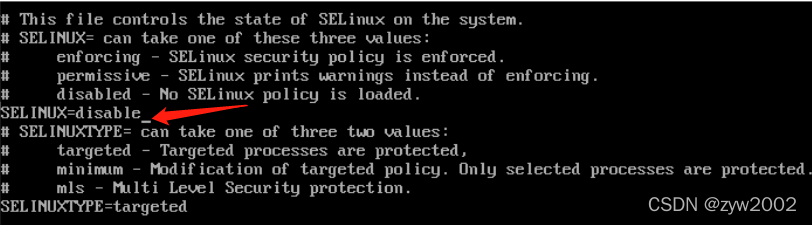
// 重启机器后root用户查看Selinux状态
# getenforce

显示Permissive 表示关闭成功。
3.2.2 安装软件
以下软件是安装时需要的依赖环境,安装MySQL时需要使用perl和libaio,ntpdate负责集群内服务器时间,screen用于新建后台任务。
每台都要执行
# yum install perl*
# yum install ntpdate
# yum install libaio
# yum install screen
3.3.3 检查网卡是否开机自启
每台都要执行
// 查看网卡名,看里面一个enp0s开头的是多少,由于我们开启了两块网卡,注意这两张都是什么名字
// 我的网卡名分别是enp0s3和enp0s8,还有一个lo,这个可以忽略不计
ip addr
//使用这条命令可以查看所有网卡的信息
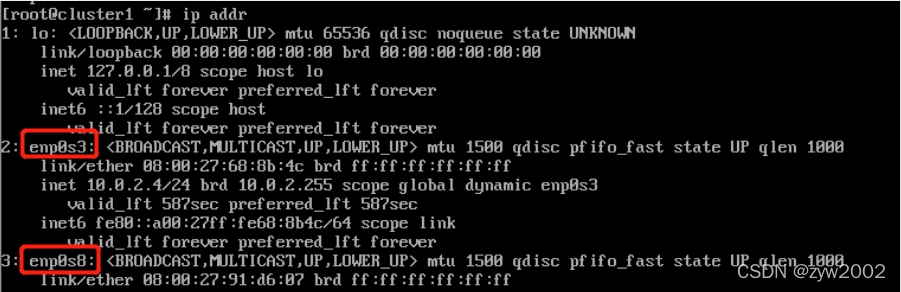
注意:此处有两张网卡,分别是2:enp0s3和3:enp0s8,如果没有,可能是因为在安装系统的过程中,没有打开网络服务,或是网卡没有设定为开机自启。
接下来编辑网卡配置文件 编辑的第一个网卡的配置文件,应该是ip为10.0.2开头的那张网卡,网卡名为enp0s3
// 编辑网卡配置文件
#vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
// 确认ONBOOT为yes,这个设置为yes后,该网卡会开机自启,不会开机连不上网 ONBOOT=yes
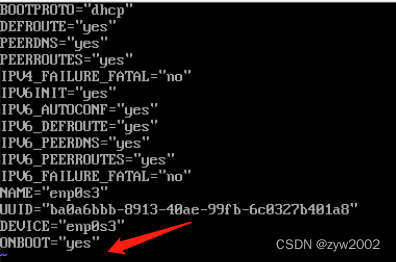
接下来编辑第二张网卡的配置文件,是enp0s8
# vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
BOOTPROTO=none
ONBOOT=yes
新增IPADDR=192.168.56.121(cluster2设置为192.168.56.122,cluster3为192.168.56.123)
NETMASK=255.255.255.0
NETWORK=192.168.56.0
保存后关闭文件.
cluster1:
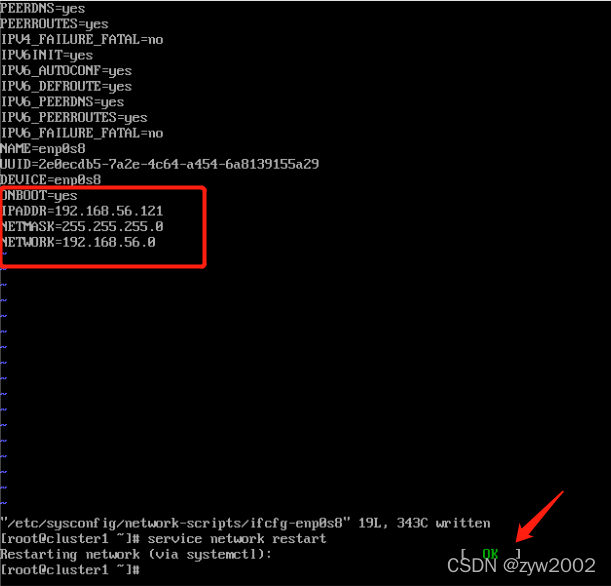
// 重启网络服务
# service network restart
//重启成功后会出现一个绿色的OK,失败则显示红色的failed,若失败,则使用reboot重启服务器即可。
//重启后,使用ip addr 命令查看enp0s8的网址已经成功修改!
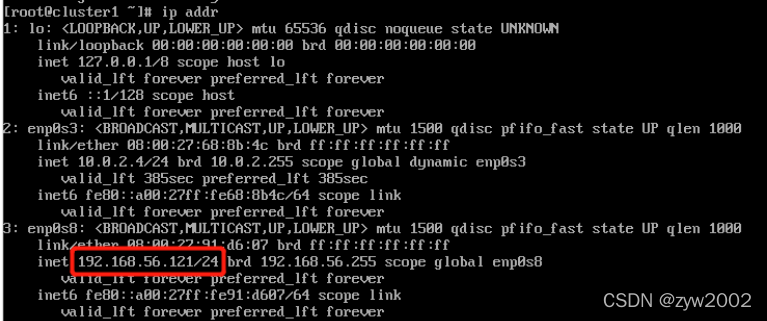
cluster2,cluster3也按照上述的方式进行网络配置
然后分别使用Xshell 软件连接三台主机
使用xftp传输文件,分别连接到三台虚拟机。
3.3.4 修改hosts
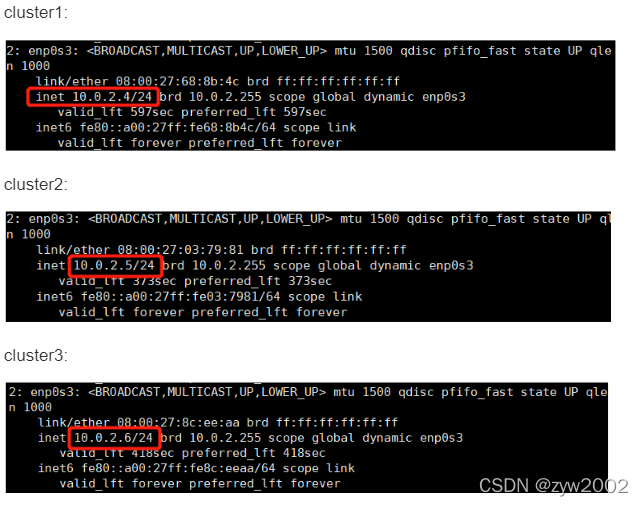
// 记录当前ip地址,要记录第一张网卡的ip地址
# ip addr
// 修改hosts ,三台都需要
# vi /etc/hosts
// 在最下面添加一下几行内容,ip地址写你用ip addr里面显示的第一张网卡(enp0s3)的ip
10.0.2.4 cluster1
10.0.2.5 cluster2
10.0.2.6 cluster3

3.3.5 检查网络是否正常
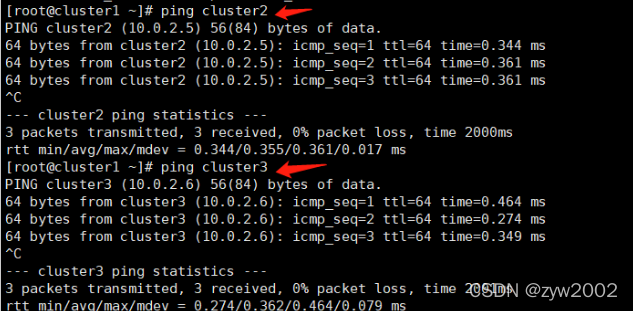
// 在cluster1上
# ping cluster2
出现如下界面说明网络正常
3.3.6 新建hadoop用户
每台都要执行
新建hadoop用户,这个用户专门用来维护集群,因为实际中使用root用户的机会很少,而且不安全。
// 新建hadoop组
# groupadd hadoop
// 新建hadoop用户
# useradd -s /bin/bash -g hadoop -d /home/hadoop -m hadoop
// 修改hadoop这个用户的密码
# passwd hadoop

3.3.7生成ssh密钥并分发
只在cluster1上执行
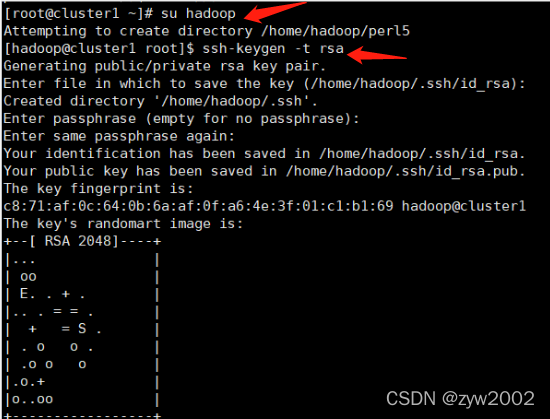
// 生成ssh密钥(cluster1上),切换到hadoop用户
# su hadoop
$ ssh-keygen -t rsa
//然后一路回车
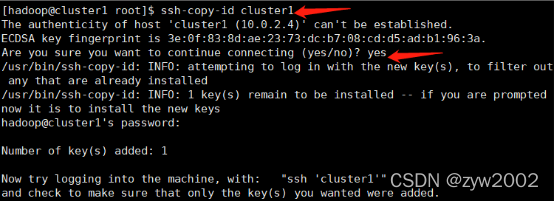
// 接下来分发密钥,请仔细观察显示的内容,会让你输入yes
$ ssh-copy-id cluster1
$ ssh-copy-id cluster2
$ ssh-copy-id cluster3
//测试ssh
$ssh cluster3
$exit
$ssh cluster2

3.3.8 安装NTP服务
三台都要安装
#yum install ntpdate
// cluster1上装ntp
# yum install ntp
// cluster1上执行以下操作
# vi /etc/ntp.conf
//注释如下4行
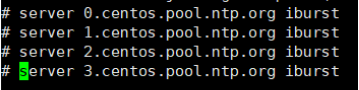
//并在最后加入:
restrict default ignore
restrict 10.0.2.0 mask 255.255.255.0 nomodify notrap
server 127.127.1.0

// 重启ntp服务
# service ntpd restart
// 设置ntp服务器开机自动启动
# chkconfig ntpd on

以下为客户端的配置(除cluster1外其他所有的机器,即cluster2和cluster3)
//设定每天00:00向服务器同步时间,并写入日志
# crontab -e

输入以下内容后保存并退出:
0 0 * * * /usr/sbin/ntpdate cluster1>> /root/ntpd.log
// 手动同步时间,需要在每台机器上(除ntp server),使用ntpdate cluster1同步时间
# ntpdate cluster1

3.3 安装MySQL
3.3.1 安装
只在cluster2上做以下内容,因为我们的集群中,只有cluster2上需要安装一个MySQL
# yum remove mysql mysql-server mysql-libs compat-mysql51
# rm -rf /var/lib/mysql
# rm -rf /etc/my.cnf
下载mysql-5.6.37-linux-glibc2.12-x86_64 (鼠标拖动即可)
# cp mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz /usr/local/
// 解压到/usr/local/
# tar -zxvf mysql-5.6.37-linux-glibc2.12-x86_64.tar.gz
// 改名为mysql
# mv mysql-5.6.37-linux-glibc2.12-x86_64 mysql

// 修改环境变量
# vi /etc/profile 在最下面添加
export MYSQL_HOME=/usr/local/mysql
export PATH=$MYSQL_HOME/bin:$PATH
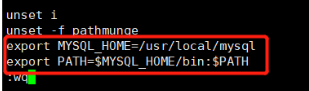
// 刷新环境变量
# source /etc/profile
// 新建mysql用户
# groupadd mysql
//在/etc/group中可以看到
# useradd -r -g mysql -s /bin/false mysql
//在/etc/passwd中可以看到
# cd /usr/local/mysql
# chown -R mysql:mysql .
# scripts/mysql_install_db --user=mysql

// 修改当前目录拥有者为root用户
# chown -R root .
// 修改当前data目录拥有者为mysql用户
# chown -R mysql data

// 新建一个虚拟窗口,叫mysql
# screen -S mysql
# bin/mysqld_safe --user=mysql &

// 退出虚拟窗口
# Ctrl+A+D
# cd /usr/local/mysql
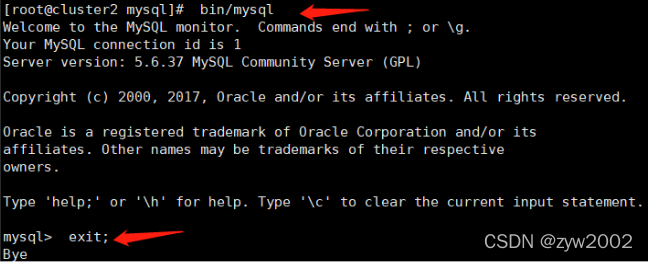
// 登陆mysql
# bin/mysql
// 登陆成功后退出即可
# exit;
// 进行root账户密码的修改等操作
# bin/mysql_secure_installation
//首先要求输入root密码,由于我们没有设置过root密码,括号里面说了,如果没有root密码就直接按回车。
//是否设定root密码,选y,设定密码为cluster,
//是否移除匿名用户:y。
//然后有个是否关闭root账户的远程登录,选n,
//删除test这个数据库?y,
//更新权限?y,然后ok
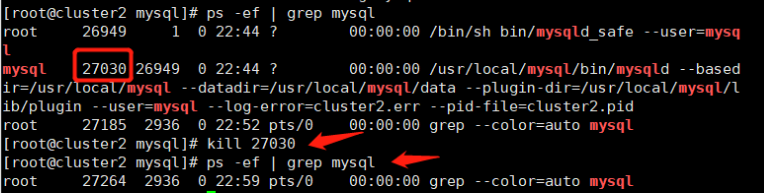
// 查看mysql的进程号
# ps -ef | grep mysql
// 如果有的话就 kill 掉,保证 mysql 已经中断运行了
# kill 进程号
// 启动mysql
# /etc/init.d/mysql.server start -user=mysql

//还需要配置一下访问权限:
# su hadoop
$ mysql -u root -p 密码:cluster
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'cluster' WITH GRANT OPTION;
mysql> FLUSH PRIVILEGES;

// 关闭mysql的指令(不需要执行)
# mysqladmin -u root -p shutdown
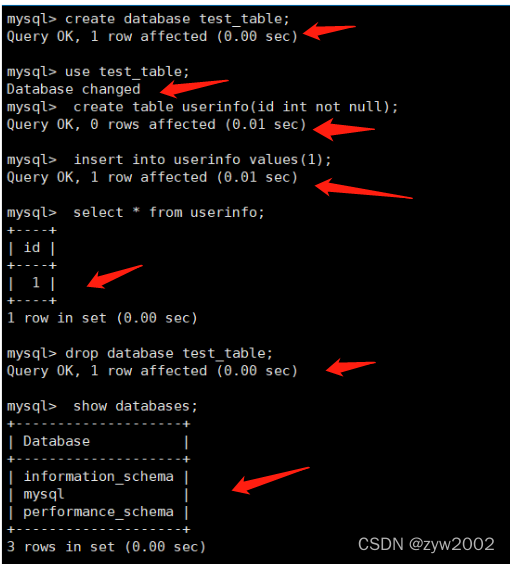
3.3.2 测试
mysql> create database test_table;
mysql> use test_table; mysql> create table userinfo(id int not null);
mysql> insert into userinfo values(1); mysql> select * from userinfo;
mysql> drop database test_table;
mysql> show databases;
3.4 安装JDK
3.4.1 安装
cluster1上执行
复制到cluster1的root目录下

$ su root
# cp jdk-7u80-linux-x64.tar.gz /usr/local/
# cd usr/local/
# tar -zxvf jdk-7u80-linux-x64.tar.gz
// 复制jdk到其他的服务器上
# scp -r /usr/local/jdk1.7.0_80/ cluster2:/usr/local/
# scp -r /usr/local/jdk1.7.0_80/ cluster3:/usr/local/
然后分别在三台服务器上修改环境变量
# vi /etc/profile
// 添加以下内容
export JAVA_HOME=/usr/local/jdk1.7.0_80/
export




















 7119
7119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












