藏语语音识别模型Tibetan_ASR,微调whisper-small,藏语音频转文本。
·
项目地址GitHub:链接
tibetan_ASR/README.md at master · wang0471/tibetan_ASR
通过迁移学习微调openai/whisper-small模型。
使用TTS合成音频,在原有的数据集上加入10%的合成数据。
使用多种数据增强,变速、调节音量、加入噪声、混响等方法。
使用[mask]掩码遮掩15%的音频,提高了模型的鲁棒性。
模型和推理代码可以直接下载使用。
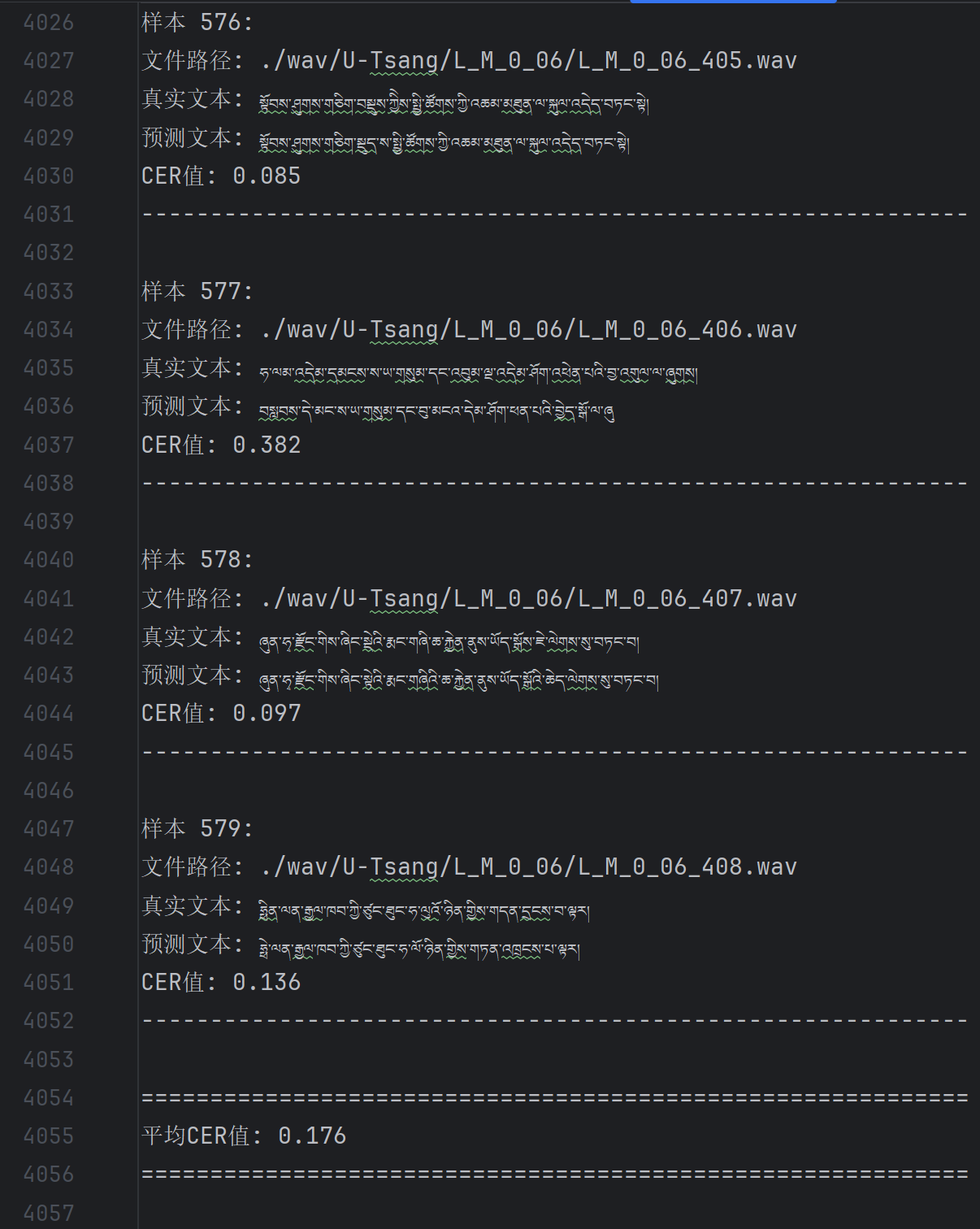
以下是在陌生测试集上进行语音识别的部分示例
运行环境
python 3.9.0
pytorch 2.7.0
transformers 4.31.0
librosa 0.11.0
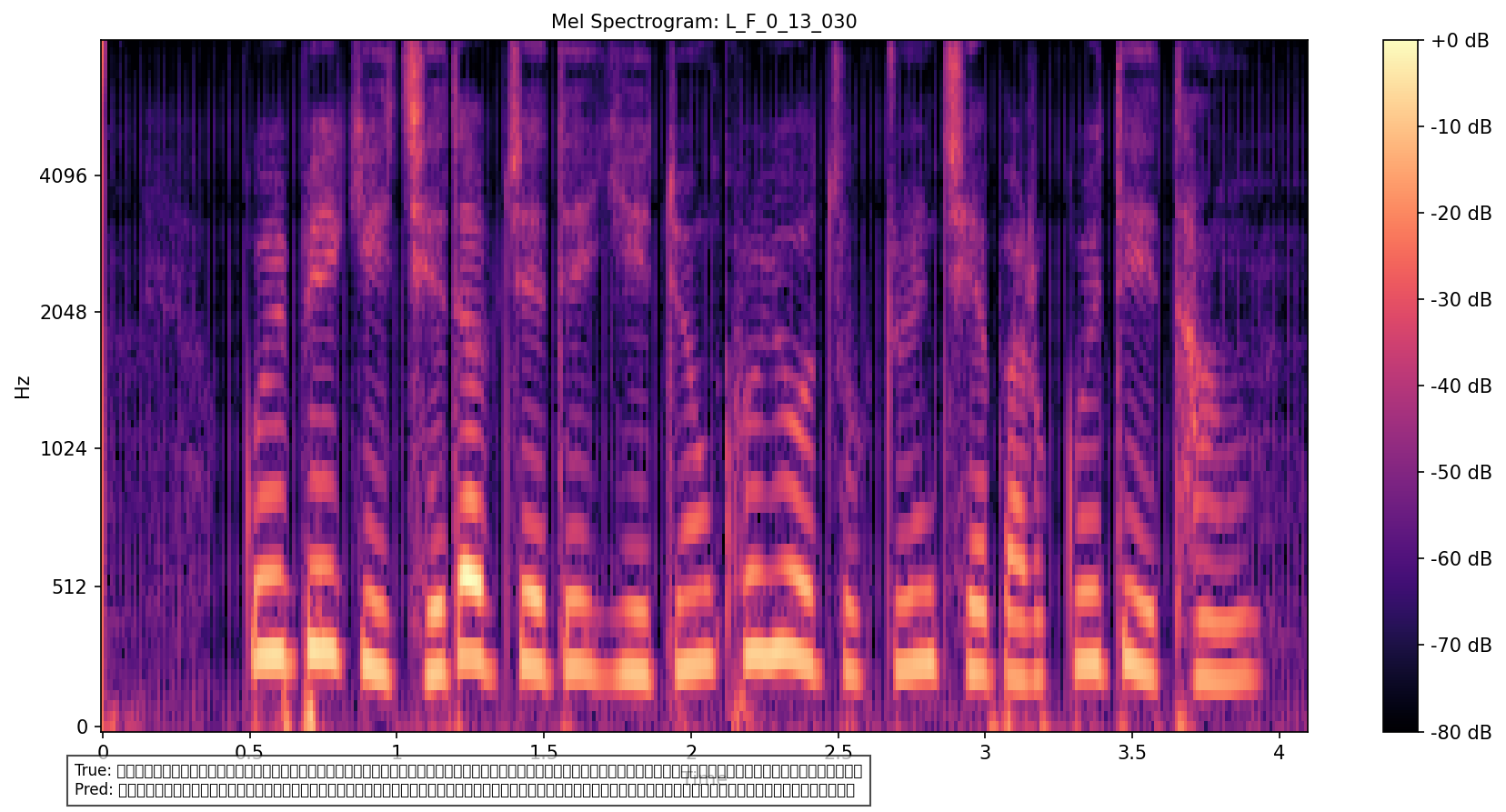
测试集上的mel谱图示例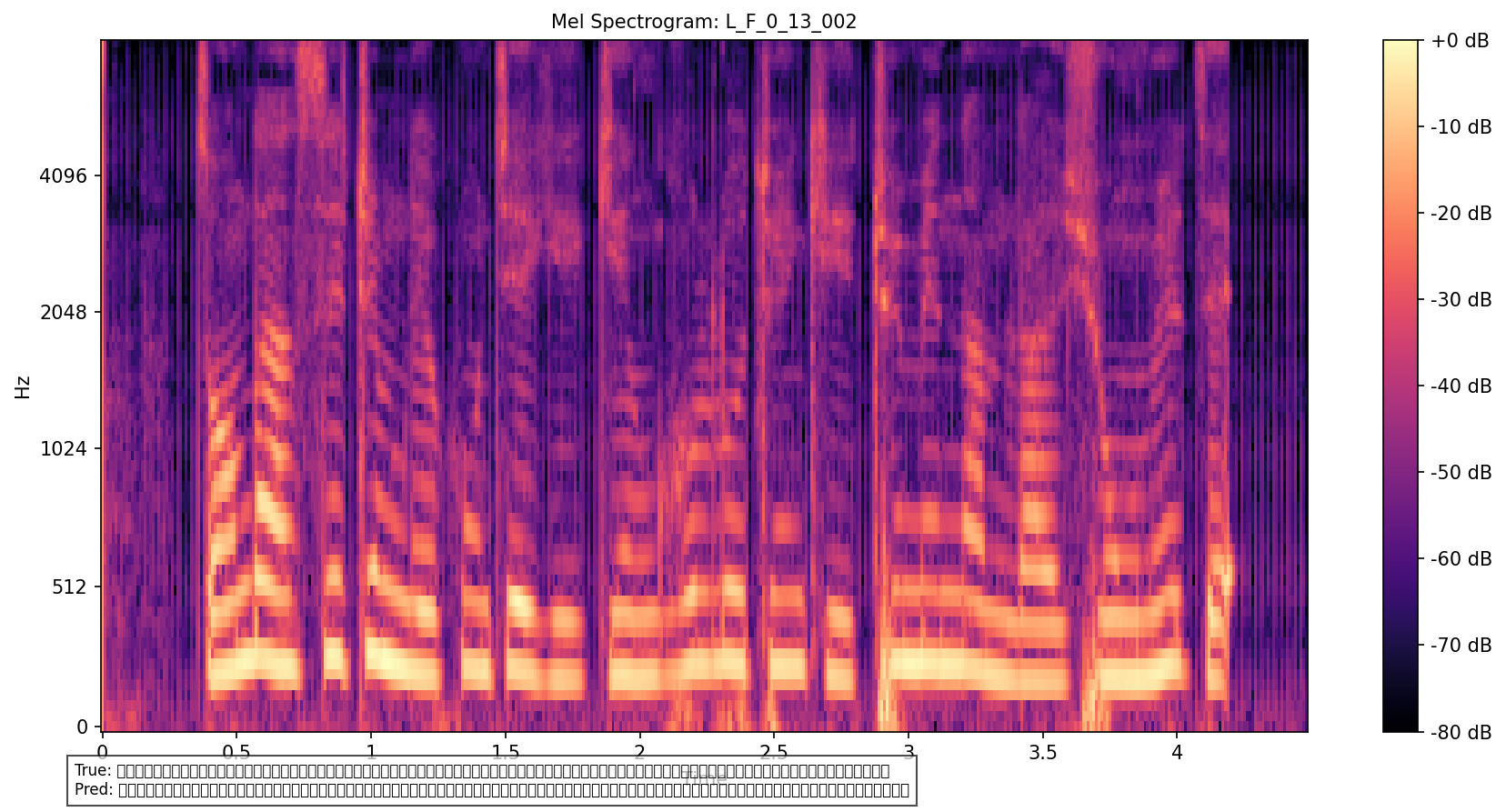

智能硬件社区聚焦AI智能硬件技术生态,汇聚嵌入式AI、物联网硬件开发者,打造交流分享平台,同步全国赛事资讯、开展 OPC 核心人才招募,助力技术落地与开发者成长。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容


所有评论(0)