
Abstract
Purpose
Good background data are an important requirement in LCA. Practitioners generally make use of LCI databases for such data, and the ecoinvent database is the largest transparent unit-process LCI database worldwide. Since its first release in 2003, it has been continuously updated, and version 3 was published in 2013. The release of version 3 introduced several significant methodological and technological improvements, besides a large number of new and updated datasets. The aim was to expand the content of the database, set the foundation for a truly global database, support regionalized LCIA, offer multiple system models, allow for easier integration of data from different regions, and reduce maintenance efforts. This article describes the methodological developments.
Methods
Modeling choices and raw data were separated in version 3, which enables the application of different sets of modeling choices, or system models, to the same raw data with little effort. This includes one system model for Consequential LCA. Flow properties were added to all exchanges in the database, giving more information on the inventory and allowing a fast calculation of mass and other balances. With version 3.1, the database is generally water-balanced, and water use and consumption can be determined. Consumption mixes called market datasets were consistently added to the database, and global background data was added, often as an extrapolation from regional data.
Results and discussion
In combination with hundreds of new unit processes from regions outside Europe, these changes lead to an improved modeling of global supply chains, and a more realistic distribution of impacts in regionalized LCIA. The new mixes also facilitate further regionalization due to the availability of background data for all regions.
Conclusions
With version 3, the ecoinvent database substantially expands the goals and scopes of LCA studies it can support. The new system models allow new, different studies to be performed. Global supply chains and market datasets significantly increase the relevance of the database outside of Europe, and regionalized LCA is supported by the data. Datasets are more transparent, include more information, and support, e.g., water balances. The developments also support easier collaboration with other database initiatives, as demonstrated by a first successful collaboration with a data project in Québec. Version 3 has set the foundation for expanding ecoinvent from a mostly regional into a truly global database and offers many new insights beyond the thousands of new and updated datasets it also introduced.
Similar content being viewed by others

1 Introduction
Life cycle assessment (LCA) is a very data-intensive methodology. A typical life cycle of a product or service covers thousands of human activities, each of which needs to be understood and documented in terms of environmentally relevant material and energy flows. This information can usually not be gathered within each specific LCA project due to the high cost of primary data collection. It is therefore common practice to focus data collection efforts on selected activities that reflect the immediate space for action—these activities are together called the foreground system—and to use generic data from Life Cycle Inventory (LCI) databases to model the remaining activities, called the background system (Bourgault et al. 2012; Tillman 2000). We estimate that the background system usually covers up to 99 % of the unit processes in the product system; we believe that only in rare cases do the number of unit processes modeled explicitly in the foreground system exceed 5 %, for example in large-scale studies of the energy sector (Hertwich et al. 2014; Laurent and Espinosa 2015; Treyer and Bauer 2013; Treyer et al. 2014). Bearing this in mind, background LCI databases can be considered the backbone of any LCA study. They provide the dominant share of the building blocks required for any LCA: aggregated and/or disaggregated unit process data. Therefore, the available quantity and quality of unit process data provided by LCI databases are of utmost importance.
The ecoinvent LCI database was first published in 2003 with its version 1 (Frischknecht et al. 2005). It represented the results of many person-years of work and built on top of several existing LCI data collection efforts in Switzerland of the 1990s. The common goal of the ecoinvent project partners was to facilitate the application of LCA through the availability of consistent generic background LCI data. Lack of background data can severely impact the quality of LCA studies, and there was a general interest among both research institutions and Swiss government offices to apply LCA more consistently. The project scope was intentionally limited to Life Cycle Inventories. While life cycle impact assessment (LCIA) methods were applied to the cumulative inventory results to support users, LCIA method development was and is still outside of the scope of ecoinvent. While developed for application in Switzerland and with Swiss supply chains in mind, version 1 was also frequently applied in studies with a primary scope outside of Switzerland.
With the release of version 2 in 2007, the data basis was significantly expanded and enriched, adding several new economic sectors such as biofuels, consumer electronics, and others to the database. In addition, the geographical coverage increased, with more data covering areas outside of Europe. Sectors such as electronics were covered with data of production in Asia. Version 2 has been used over the years in many relevant LCA studies (Amor et al. 2014; Arvesen and Hertwich 2015; Bauer et al. 2015; Bouman et al. 2015; Henriksson et al. 2015; Hertwich et al. 2014; Masanet et al. 2013; Scharlemann and Laurance 2008; Simons and Bauer 2012; Sternberg and Bardow 2015; Treyer et al. 2014; Turconi et al. 2014; Volkart et al. 2013; von der Assen et al. 2013; Wernet et al. 2010, 2012, 2011; Yue et al. 2014), setting precedence in the environmental assessment of different product groups and economic sectors. Additionally, first policy instruments were designed based on LCA and referred to ecoinvent as standard background data (Swiss Confederation 2014). Increasingly, it was also used beyond its original intended scope of Switzerland and Europe and has become a reference database for studies and LCA work in North and South America, Asia, Africa, and Australia (Hou et al. 2015).
Due to this increasing international and global use, it was decided to further develop the database into the direction of a globally valid database instead of simply maintaining its status as a Swiss database. The increasingly international use of the database conflicted with some decidedly Swiss supply chains in the database. Users were found to commonly apply Swiss or European datasets to other regions due to lack of geographically appropriate data. This led to inconsistencies on several levels: first of all, conditions and supply chains for important factors, such as electricity mixes, vary with geography for many activities and, secondly, with the increasing evidence of the importance of regionalized impact assessment (Mutel et al. 2013, 2012; Mutel and Hellweg 2009; Pfister et al. 2009; Potting and Hauschild 1997, 2006; Wegener Sleeswijk and Heijungs 2010), these localized supply chains would not be appropriately modeled with Swiss or European data.
At the same time, the continued growth of the database and its user base challenged some aspects of the technical foundation of the database in terms of the required maintenance effort in the long term. First of all, the management of the database and updating required a significant amount of manual work, which was manageable during the early days of the database, but grew to be prohibitive as the database expanded in size and scope. Secondly, it was becoming more and more obvious that, as LCA developed as a tool, its use in policy and standards was increasing, and such applications often require specific modeling rules to be applied. The approach of having all modeling choices fixed within the datasets therefore restricted the usefulness of the data to a limited application range. There was a need for a system that harmonizes some set modeling rules, allows a choice between different sets of rules, and applies them to the whole database consistently. Such an approach would also simplify some aspects of data entry, as data providers would no longer have to apply system modeling rules themselves. Finally, several options for improvements in functionality and data coverage had been identified and a new technological foundation, including an update of the established ecospold data format (Meinshausen et al. 2014) was required for further development of the database. Several of these features were developed specifically to facilitate the collaboration and integration of international data and to facilitate cooperation with a broader range of data providers.
Therefore, the plan for ecoinvent version 3 was developed, with the ambition to provide a technological and methodological foundation for an LCI database with modern capabilities, flexibility and room for future developments as well as the structure necessary to grow into a truly global database. This paper provides an overview of the most important new developments introduced with version 3, focusing on new dataset categories and the different system models used for linking the unit processes.
2 Developments
2.1 From multi-output activities to single product datasets
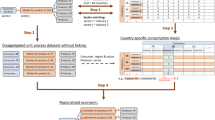
One major change introduced with version 3 is that the database no longer stores data and modeling choices intertwined. Data is stored first as raw, “undefined” datasets, which contain unit process data without influences of, e.g., allocation choices. This version of the database is best suited for understanding a process or activity in its original isolated state since it shows all exchanges, i.e., inputs, co-products, and emissions as originally collected, in one overview. However, calculation of aggregated LCIs and LCIA results requires the application of system modeling, i.e., linking and allocating the unit processes according to a distinct set of rules. Version 3 offers the choice of more than one system model, and the application of these models results then in several system model databases, each in the form of fully linked unit processes. Aggregated LCI and LCIA results are also available for each system model database. Thus, version 3 is available as a primary database with an “undefined” system model and, currently, three system model databases, which have different LCIA results due to the different modeling choices, despite being based on the same unlinked, raw unit process data (Fig. 1).

Flowchart of generating system model results out of the primary raw unlinked data
2.2 Global background data
The decision to support regionalized assessment with version 3 brought with it the consequence that impacts needed to be adequately distributed globally. In versions 1 and 2, the database was focusing on Swiss and European production, while datasets from other regions were often lacking (Steubing et al. 2016). Therefore, users commonly applied the European datasets also to other regions. In these cases, local conditions (e.g., in terms of technologies used) were often inappropriately reflected by the LCI data used and—in this context more important—direct and upstream impacts were thus caused in inappropriate geographies. To introduce a more appropriate representation of global supply chains, to support regionalized impact assessment, and to support a more international user base, global coverage for activities was consistently introduced in version 3. There exists a global dataset for all activities in version 3, and in addition, there may be one or more local (non-global) datasets representing the production activities for specific regions. Geographies in version 3 are described in the KML format (OGC 2014) to support interaction with other machine-readable spatial data, but are also described using country names and codes to simplify human interactions with the geography data.
All activities include data on annual production volume, and in the system model databases, the global datasets are used to approximate the activities in regions not covered by local data. For this, the global dataset is used as the basis for a “Rest-of-the-World” (RoW) dataset applicable to the areas not covered by local data. As the local geographical coverage differs from one activity to another, RoW datasets do not always describe the same geography. Using the KML geographies, the geography of each RoW dataset can be described individually. This geography is then also used to determine the suppliers for the inputs of the dataset. In versions 3.0 and 3.1, RoW datasets were generated by using a production-volume-weighted average of all local datasets and calculating a difference dataset to the global average available in the global dataset. The RoW dataset was then created as a difference dataset so that the weighted sum of all datasets resulted in the values of the global average. However, the chosen implementation of this procedure demanded significant extra effort from data providers, and results were generally not affected much compared to a simpler approach, which has now been implemented with version 3.2. In this new approach, the RoW datasets are identical in flow values to the global dataset, albeit still with supply chains adapted to its geography. A sensitivity analysis of the change in approach revealed generally minimal changes in results due to the transition.
A RoW dataset is only generated if the sum of all local production volumes is lower than the global production volume. Therefore, a RoW dataset is not created if: first, all regions of the world are adequately covered with regional datasets (i.e., full geographical coverage), or second, an activity takes place in only parts of the world (i.e., the complete global production is localized in one region, which is covered by a local dataset). In both cases, the sum of the local production volumes is equal to the global production, and no RoW dataset is generated.
The inclusion of consistently available, global datasets facilitates the expansion of the database into different regions. The global datasets mean that the existence of background supply chains can always be relied on, no matter for which region a dataset is created. Datasets can therefore be created without requiring local supply chain data to also be available immediately. Such supply chains may still become available later and will then be utilized through the linking algorithm (see below).
2.3 Market datasets
When a product is produced by more than one activity (i.e., by different production technologies or by one technology, but in more than one region each covered by an individual dataset), it is important in activities consuming the product to know which production contributes how much to the supply chain of the consumer. For this reason, versions 1 and 2 of ecoinvent contained a number of production, supply, and consumption mixes, but only for a selected number of products. Version 3 introduces independent product names, which are no longer tied to specific process names. The aim is to more easily identify activities with the same product as output. With version 3 also aiming to introduce more geographical coverage, an increased need for geography-specific consumption mix datasets was foreseen. For this reason, version 3 introduces market datasets representing the consumption mixes for a given region and product (so that consumption is supplied by the production within the given geography plus imports minus re-export). Market datasets also contain additional exchanges related to the transport of the good from the producer to the consumer, as well as losses of goods and emissions during transport (e.g., in the case of perishable fruit and vegetables, leaking natural gas pipelines, or transmission and distribution losses for electricity). For most other datasets, the market datasets only reflect a generic model for supply and transport of the products. A market dataset can be used as an input by consuming activities that are lacking more specific supply chain information. However, while market datasets represent a useful and convenient option in the building of a consistent network structure across the ecoinvent database, LCA practitioners should consider using inputs directly from production activities whenever more specific knowledge is available regarding product sourcing, losses and transport distances.
In ecoinvent, a data provider who has sufficient specific information may link an input directly to specific activities or markets. Without such specific information, the data provider will leave the dataset unlinked, in which case the linking is carried out by the database service layer during the linking of the unlinked activities into system model databases. The input is then linked to the geographically appropriate market or markets. In this “indirect” linking, a dataset can at first always rely on the existence of a global market providing a global supply chain. Should more local markets be present, or be added to the database for a future calculation, the same dataset would then link to this more specific market, or even to a set of markets within its region, without requiring any modification of the dataset itself. In this way, data providers can ensure that their supply chains will be updated to the most appropriate data available in the database in the future, thus reducing the updating and maintenance work between database versions.
In a similar fashion, market datasets themselves are only completed during the linking of the unlinked activities into system models. One reason is that different system models have different rules for the composition of consumption mixes (see below). Another reason is that, in this approach, consumption mixes are updated whenever new producers are added to the database. Markets are completed using annual production-volume-weighted averages of the relevant producers and importers in the geography covered by the market. The annual production volumes therefore determine the shares of different activities providing the same product to a certain market. Production output that is already used specifically for a particular consumer and for export does not contribute to markets (Fig. 2). The approach of completing market datasets during linking was chosen on the basis that by default, a new production activity should contribute towards the average consumption mix in a region. The impacts of new datasets on existing market datasets therefore need to be observed and reviewed.

An illustration of linking via market datasets using animal feed production as a theoretical example (** PV stands for production volume). At the bottom of the graph, electricity markets supply electricity mixes without the need for choosing between individual producers such as coal or hydropower. Soybeans, one of the components of animal feed, are produced in two local datasets (USA and Brazil). A RoW dataset covers the remaining global production of soybeans that is not covered by the two local datasets. The local datasets are supplied by their local electricity markets, the RoW dataset by all other electricity markets using a production-volume-weighted average for their contributions. All three soybean datasets supply the global market for soybeans. However, the US production does not supply all of its production to the market, as some of it is specified as directly linked by the US production of animal feed. This direct consumption does not contribute to the global market share of US soybeans, as the market is a consumption mix, not a production mix
With version 3 and the introduction of market datasets, the standard estimations for transport within the database (default values used to estimate transport distances when no specific data were available) were also updated and expanded to cover more forms of transport consistently and with sector-specific data based on global transport statistics (ecoinvent 2014). With these statistical data, market datasets describe the average transport modes and distances for each product, including shipping, road, and rail transport as well as, if appropriate, air transport and other, specialized transport methods, e.g., pipelines.
Together with RoW datasets, market datasets represent the central building blocks for a more realistic representation of global supply chains. Market datasets and the consistent consumption mixes represent a useful tool both for users of the database and for the operation of the ecoinvent database itself. However, it should be noted that in foreground systems, built on top of ecoinvent data, it is not necessary to use market datasets or a structure based on consumption mixes.
2.4 System models in version 3
Versions 1 and 2 of ecoinvent applied one system model to the database, which largely followed a recycled content or “cutoff” approach (Frischknecht et al. 2005). Modeling choices were directly integrated into the datasets by the authors of datasets. Therefore, the consistent application of this modeling choice needed to be reviewed in each dataset individually, and some inconsistencies remained in the database despite the review efforts. With the option of separating inventory data and modeling choices, version 3 allows for more than one system model and is indeed so far currently available in three system models. The modeling rules are defined once and then applied consistently to all datasets. The application of the model therefore only needs to be reviewed once, and inconsistencies are much less likely to occur. The two system models applying allocation rules are intended for use as background data in attributional LCA, and the consequential system model is intended for application in consequential LCA (Earles and Halog 2011; Ekvall and Weidema 2004; Weidema et al. 2009; Zamagni et al. 2012).
2.4.1 Allocation and cutoff by classification
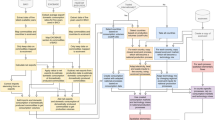
This model follows the same recycled content approach as versions 1 and 2. At the database level, all intermediate exchanges (i.e., exchanges within the technosphere) are classified into either “allocatable byproducts,” “recyclable materials,” or “wastes.” The classification is based on expert judgment of an exchange’s value, use potential, and predicted fate. Depending on this classification, byproducts (i.e., products that are not the reference flow) in multi-functional activities are handled differently (Figs. 3 and 4): Allocatable byproducts are allocated against other products based on the allocation factors specified for the specific system model, e.g., on physical relations, exergy, price, or mass.

The cutoff process in the “cutoff by classification” system model for waste treatment byproducts. The treatment byproduct is available burden-free in the database, while the inputs and emissions of the waste treatment fully contribute to the burdens of the reference product of the waste-producing activity

The upper half shows how Recyclable Materials are cut off in the “cutoff by classification” system model in the producing activity (labelled “Activity”) through the use of the special, empty cutoff dataset (dotted arrows indicate additional inputs and emissions that are not relevant to the allocation process, as in Fig. 3). The producing activity lists the cut byproduct as a negative input to make the cutoff process explicit and to respect mass balances. Within the scope of the producing activity, Wastes and Recyclable Materials are therefore treated the same way. The difference is whether disposal of the material brings with it additional burdens, as in Fig. 3, or no additional burdens, as in this case. In the bottom half, it can be seen how consumers of recyclable materials receive the material burden-free at the site of the producer. Therefore, transport and collection are already contributing to the supply chain of the secondary material. They are then consumed in other activities which describe the recycling process and produce secondary goods or products that are partially based on recyclable materials
Recyclable materials are cut off from the producing product system, i.e., they are removed burden-free from the producing activity, and no impacts or benefits are allocated to them. They are then available burden-free to any consuming activities, e.g., recycling activities. Secondary materials thus bear only the burden of the recycling process and no burdens from the primary production of the material. To introduce the cutoff, the system model introduces special datasets which are named “exchange name, recycled content cutoff” and which contain no flows besides the reference product of the exchange itself. These are used to show that the cutoff is happening in the dataset and to maintain mass balances. The cutoff is taking effect through the lack of inputs or outputs to these special datasets (Fig. 4).
Wastes on the other hand are disposed of in a treatment activity, and the burden of the disposal is completely attributed to the activity producing the waste. This is achieved by first listing the produced wastes as a negative process input in the producing activity using the logic that a positive output is equal to a negative input. Waste treatment activities have the reference product of removing wastes, which is recorded as a negative product. The processes are therefore linked correctly: The burdens of waste treatment increase the burdens of the producing activity (Fig. 3). This approach is identical in results to the approach of versions 1 and 2, where disposal of wastes was an input to datasets. Listing the wastes as negative inputs maintains the mass balance of the dataset, an important validation tool and helpful in understanding the physical reality of the activity. As the burdens of waste treatment are to be fully attributed to the producing activity of the waste, any non-waste byproducts of waste treatments (e.g., heat from waste incineration) are available burden-free in this system model.
2.4.2 Allocation at the point of substitution
The allocation at the point of substitution (APOS) system model is based on the premise that allocation of materials that require further treatment before they can be of immediate value is fundamentally challenging. Neither the price, mass, exergy, nor any other physical property is a useful allocation parameter, e.g., waste glass. The APOS model is therefore performing an expansion of the allocation system to include all treatment processes required for any byproducts (Fig. 5), be they wastes or recyclable, and in fact, the system model makes no such distinction (please note that this is unlike the process some refer to as “system expansion” that is used in consequential LCA, a process we refer to as “substitution” in this article). All products, which are not produced as a positive reference product by any other activity, are defined as materials for treatment (MFT). The MFTs are largely equal to the products classified as recyclable materials and wastes in the cutoff model. Allocation systems are expanded to include all treatment steps necessary for conversion of the MFTs into products that are not MFTs. The expanded system is then allocated to all its co-products based on the allocation factors in the database. Thus, the exchanges of both production and treatments are combined and then allocated to both the production products and the treatment byproducts (Fig. 5).

Overview of the expanded allocation system in the APOS model. While the cutoff model allocates the production process only to its allocatable byproducts, the APOS model expands the allocation system to include both the production and the treatment processes. Impacts of both are combined and allocated to both the product A and the treatment byproduct E
As the allocation system is expanded to cover the whole treatment process, any allocation within the treatment process(es) can be avoided in this system model. Therefore, the distinction between wastes and recyclable materials is not required in this system model. Allocation on wastes and waste products is often a controversial topic in LCA studies (Cherubini et al. 2009; Finnveden 1999; Heijungs and Guinée 2007), so avoiding this issue is a benefit of the APOS model. To allow an analysis of the unit process contributions, the byproducts are allocated in the main producing activity, and the treatment functionality of the treatment processes is part of the supply chain with all the impacts of the treatment (Fig. 6). The allocation then results in datasets for treatment byproducts that are specific to the activity producing the MFT. To simplify the database and the use of such products, all instances of a specific byproduct from a specific treatment are aggregated into one dataset. For example, the datasets for electricity from incineration of municipal solid waste is listed in the APOS model as one dataset. However, as explained above, each instance of municipal solid waste (MSW) output results in an individual dataset for electricity, e.g., one from treatment of MSW from farming, one from treatment of MSW from machinery production, or one from treatment of MSW from other waste treatments. All of these datasets are aggregated into one production-volume-weighted average of all such treatment datasets. This dataset then represents the production of electricity using the average waste origins within the database.

Modeling of joint production activities in the APOS system model (adapted from Weidema et al. 2013). The upper half shows the original process structure. To allocate all 3 products X, Y, and Z against each other, they need to be grouped in one place at the end of the expanded product system. The bottom half shows how the process structure is rearranged after MFT byproducts are considered as negative inputs and how the non-MFT recycling byproduct is moved to the joint production activity to allow allocation within a single activity
The two allocation models only differ in the approach towards allocating recycling and waste treatment products. The differences between the two system models in terms of LCA results are therefore strongest for such products and often negligible otherwise (Steubing et al. 2016).
2.4.3 Consequential, long-term, small scale
The consequential system model follows a substitution-based approach and is intended to serve as a background database in consequential LCA studies (Earles and Halog 2011; Ekvall and Weidema 2004; Pehnt et al. 2008; Reinhard and Zah 2009; Suh and Yang 2014; Tonini et al. 2012; Weidema et al. 2009; Zamagni et al. 2012). In this system model, substitution is used to resolve multi-functionality in datasets instead of allocation. A reference product for an activity is always burdened with the full impacts of all inputs and emissions, but is credited with benefits for any byproducts it produces that can substitute other productions. Byproducts are recorded as negative inputs in the datasets and are linked to the production of the good or service they are substituting. The negative sign results in an environmental credit if the substituted activity has an environmental burden. As previously stated, the term “system expansion” is also sometimes used for this approach; this article uses the term “substitution.” In the consequential model, only unconstrained suppliers (those who can respond to changes in demand by adapting their production) are taken into account.
Byproducts are always constrained in the Consequential system model. The model defines that, as they are not the driver for an activity, they cannot react in an unconstrained way to changes in demand. That means that, in this system model, market datasets generally only have inputs from activities where the product is the reference product. Any direct links to such byproducts are also substituted with the input from the corresponding unconstrained market.
Furthermore, activities can be constrained due to the technology level as defined in the dataset: only the most up-to-date technologies are considered unconstrained. The electricity sector (i.e., the markets) can be regarded as an example for the implementation of these constraints (Treyer and Bauer 2014). Constraints are therefore mostly based on current conditions and not the result of specific forecasting projects. Conditions can vary over time, and this may become relevant especially if data are directly used in foreground modeling. The current implementation of consequential modeling is rather basic since many datasets only exist as averages, and constraints are determined in a basic way but the implementation is sufficient to fulfill the purpose of a background database in many consequential studies, as it offers the core concepts of a consequential model, i.e., use of substitution to avoid allocation completely and use of marginal suppliers instead of average suppliers, and as individual processes can be adapted if needed to include more specific data, e.g., from forecasting studies.
When all suppliers to a market are constrained, for example when the market product is exclusively produced as a byproduct, the consequential model applies the concept of constrained markets (Fig. 7). An example is sodium hydroxide (NaOH), which is currently only produced as a byproduct (NaOH is a byproduct of chlorine production, which drives the demand of their joint production). Activities in the database that require NaOH therefore depend on a product that is constrained by the demand for chlorine. A marginal consumption activity is then determined, which reduces its consumption of NaOH when consumption is increased elsewhere. Therefore, the production of chlorine as an activity receives a credit for the production of NaOH corresponding to this reduction in marginal consumption. In the case of NaOH, the actual credit is given for a reduction of production of sodium carbonate (which can substitute for NaOH as a neutralizing agent), which does not need to be produced due to the increased availability of NaOH. Similarly, consumers of NaOH are burdened with the increase in sodium carbonate production resulting as the indirect consequence of their NaOH consumption.

Example of a “Constrained market”; modeling according to the “Consequential, long-term, small scale” system model (adapted from (Weidema et al. 2013))
2.5 Other developments
Several other changes were introduced with ecoinvent version 3. First of all, the data format was updated to ecospold 2 (Meinshausen et al. 2014). The new format improves the description of exchange data independent of process data. It also includes significantly increased options for documentation directly in the dataset, such as additional documentation fields or the option to include images in dataset documentation fields. In this way, more of the documentation of a dataset can be included directly with the data. The format also includes fields for exchange properties. Each exchange can be defined and described by a number of properties, e.g., fuels can have a heating value property. All exchanges in version 3 have at least the following properties: wet and dry mass, water content, and carbon content (fossil and non-fossil). The consistent availability of these properties also allows a simple calculation of an activity’s wet and dry mass balance, its water balance, and its carbon balance. These balances are an important validation and review tool and are also reported for each activity in the online database. With the release of version 3.1, the database has achieved a water balance sufficient for detailed and accurate water use and consumption assessments (Levova 2013). The new data format also allows for specification of parameters and for direct integration of mathematical relations within the dataset. For example, the carbon dioxide emissions of an incineration can be calculated from a fuel input, the carbon content of the fuel, and any alternative carbon fates such as soot or carbon monoxide. The fuel input itself can be calculated from the required demand for energy and the heating value of the fuel. In this way, calculated values can be easily reviewed as well as understood and reproduced by practitioners; modifications to datasets can be carried out faster, and datasets can be updated more consistently.
Price data was also collected for numerous products to improve the allocation basis for many datasets. This has resulted in a significant improvement in results for many datasets (Steubing et al. 2016). While not all products within the database have price data available, most do, and this is another useful tool for validation purposes within the database. The existing price data is also provided to the users for any other uses they may see in it.
Version 3.0 also introduced many new datasets and updates to many sectors in the database. For example, the electricity sector was updated and expanded substantially (Treyer and Bauer 2013, 2014). Emissions in agriculture were likewise updated to reflect an improved understanding of emission profiles (Nemecek et al. 2014). Road passenger transport was completely updated and expanded with modern technologies, such as electric mobility and alternate fuel sources (Del Duce et al. 2014; Simons 2013), and many datasets for various North American regions were added, with a focus on Québec (Lesage and Samson 2013; Suh et al. 2013). Fruits and vegetables were added as well (Stoessel et al. 2012). Version 3.1 introduced, e.g., global data on aluminium production, new road freight transport data, forestry data, and tap water production. Version 3.2 included among other data another update and expansion of the electricity and heat sectors, data on refrigerated transport, updated cement and concrete data, and data on European aluminum production.
3 Discussion
Much of the development work for version 3 aimed to prepare the database for continued growth in the following years. This resulted in new conceptual designs that are visible in the database structure. At the same time, version 3.0 was not released with the ambition to be a complete database, and the database remains far from being complete. This is apparent in several ways. One is that the global datasets are very often not reflecting truly global data collection but are often extrapolated from regional data for one or a few regions only. While clearly not the best option, this can be an adequate approach to approximate inventories. Extrapolation from single regions, or even single locations, to larger or other geographies has been an established practice within the database since its inception and is a common practice in LCA in general. The benefits of the global datasets are nevertheless apparent in several ways. Firstly, due to the geography-specific linking of activities, such datasets have supply chains appropriate for their regions, be it local, global, or RoW datasets. Secondly, the pedigree information for geographical representativeness is adapted in such datasets, which increases the uncertainties in the dataset (Ciroth et al. 2013; Muller et al. 2014), thus revealing the importance of further improvements in these data. Finally, emissions and resource uses are correctly located for regionalized impact assessment. The main drawback of such extrapolated datasets is that they can be misinterpreted as actual global data. Good and transparent documentation of the extrapolation process and the associated limitations is therefore important. The documentation of datasets includes comments on the data origin, and the datasets contain an explicit “Extrapolations” field. In addition, the pedigree for geographical representativeness communicates the adequacy of data sources. As the database is increasingly filled with regional data, extrapolated global background datasets will decrease in relevance.
As described above, the method for generating the RoW datasets out of global datasets was changed for version 3.2. The reason was that the weighted-average calculation used at first was putting significant strain on data providers for activities where processes vary between regions. The consequences of changing to a simpler algorithm in terms of LCA results were negligible in most cases, and the new algorithm minimizes artifacts and allows for an easier understanding of values in RoW datasets.
The introduction of consistent market datasets expands on the already useful mixes present in versions 1 and 2. As the ecoinvent database grows, the likelihood increases that new datasets are not necessarily describing a new product, but rather an alternative production route for an already existing product, or the production in a different region. The creation of a distinct product list for version 3 allows users to more easily understand which activities have the same products. At the same time, practitioners are increasingly required to choose between several suppliers of a product. Markets as consumption mix datasets can offer valuable support in cases where a product is not explicitly sourced from a specific supplier but consumed “from the market”, hence the name market datasets. At the same time, it is critical to understand that practitioners should carefully choose between market inputs and direct inputs from producers, as relevant. When using the market datasets, the included transport, losses, and emissions simplify the application of the background data.
Market datasets are also beneficial for the maintenance and expansion of the database, as they allow for a simple introduction of new producers into existing supply chains throughout the database, instead of a time-consuming, manual effort to introduce new producers into potentially thousands of consuming datasets. Similarly, practitioners can adapt or modify large sections of their background system with relatively little effort by changing market compositions in a local copy of the database.
The combination of global supply chains and consistent mix datasets for centralized updating of supply chains allows for the integration of regional database projects into the ecoinvent framework. One example is the Quebec LCI database (Lesage and Samson 2013). Due to the structure of the version 3 system, a database can be built first on the backbone of the global supply chains. This avoids one major problem many new data initiatives face: a critical mass of background data is needed to complete supply chains for any dataset, and a project to build an interconnected database will not yield meaningful results until a core set of background data can be adequately covered (Bourgault et al. 2012). Later additions to the database can then substitute the global background data with local suppliers with little effort, as links to a global market can be substituted with local markets if necessary. Such collaborations between data networks can increase efficiency and productive use of resources in LCI collection.
With the possibility to apply different modeling choices to the same background database, version 3 introduces a novel set of tools for LCA practitioners: being able to use the same data in different goal and scope situations, the effects of modeling choices can be observed much more easily. A first application was carried out in (Steubing et al. 2016). Practitioners can use the different system models to answer different questions, or compare results for sensitivity analyses towards modeling choices.
The APOS system model, as a new way of looking at allocation of waste treatment and recycling products, is differing from the established cutoff model in several ways. The cutoff model uses a simple but fundamental decision to separate primary and secondary use stages. The approach strongly incentivizes the use of secondary materials. It does not however incentivize waste producers to maximize reuse of waste materials, as no benefits are given for any useful treatment products. APOS offers a different perspective, in which waste producers are incentivized to assess recycling and reuse possibilities due to the partial allocation of impacts to useful treatment products. The model can therefore be used in studies where the question of waste disposal method is a topic, or as a counterpoint to the cutoff model in a sensitivity analysis. As Steubing et al. (2016) show, the two allocation models generally show only insignificant differences in results, except in the case of waste treatment and recycling products. Therefore, it is either relatively unimportant which model is chosen or it is of added value to assess results with both systems and discuss the difference.
In practical terms, the APOS model is more difficult to implement in foreground systems than the cutoff model, and treatment byproduct datasets are more challenging to analyze and adapt by practitioners than in the cutoff model. This is partially a consequence of the cutoff’s disconnection of product paths—the disconnected systems are easier to assess and modify than the expanded systems of the APOS model. Furthermore, the consolidated datasets for treatment products, while still unit processes, are the result of the merging of sometimes numerous datasets with diverse supply chains. They can therefore reach a level of complexity that makes an assessment of the reasons for impacts challenging. The complexity is a consequence of the varied supply chains of many waste materials—the origin of, e.g., municipal solid waste in an incineration plant is indeed very diverse. At the moment, a weakness of the model is the fact that waste streams are not complete within the database, which influences the impacts allocated to the treatment products: only waste supply chains recorded in the database are taken into account. Wastes from activities not included in the database should have an effect as well but do not. Therefore, the careful comparison of results between the two allocation models is recommended when using the APOS model.
The consequential model offers a very different perspective on the database and is intended for use with goals and scopes of consequential LCA studies. In its current form, it is correctly reflecting the core consequential principles of substitution and the use of marginal suppliers. However, the differentiation between constrained and unconstrained suppliers is limited and the approach to determine marginal suppliers of electricity is a basic one. The use of technology levels to determine marginal producers could be improved upon with, e.g., results of predictive studies regarding future energy use scenarios. It is recommended that users of the system model carefully assess the datasets that are significant for their results and determine whether more detailed information on the predicted situation within their scope is available to improve the reliability of results. Nevertheless, the consequential model can serve as a background database in many applications, and this is the first and at the moment only large LCI database with a consequential perspective. It is hoped that it will form the core of increased research into and development of consequential LCI.
In general, the introduction of multiple system models has increased interest and discussion of system modeling choices significantly as practitioners now face a real choice of background data modeling and have to make an informed decision. There are different opinions on how modeling of systems should be carried out (EC 2010; ISO 2006a, b), and there are sometimes conflicting interpretations of the same set of rules (Weidema 2014). It seems generally agreed that the goal and scope of the study should affect the system model, e.g., the ILCD handbook (EC 2010) acknowledges the need for different system models in different use cases, and the system models ecoinvent now provides cover several of the ILCD scenarios. The consistent separation of inventory data from modeling choices is beneficial in this context. While only three system models are provided at the moment, the datasets before application of any system model choices are also available, and it is envisioned that eventually practitioners can create and modify system models within their LCA software tools to adapt their data models to specific goals and scopes for specialized applications. For example, substitution can also be applied to solve the allocation problem in an otherwise attributive approach with average suppliers, and such a system model could be created using the existing technology and data.
The consistent implementation of flow properties allows for more insight and transparency of the flows in an LCI, as well as increased validation options during dataset creation and analysis. Together with the new transparent and systematic review process, these automatized validations will increase data quality and reduce errors in LCI data. Mass and content balances, such as water balances or carbon balances, can be controlled and are reported for the datasets during, e.g., data entry. In this way, the database has been water balanced within adequate margins for consistent water footprinting (Levova 2013). Properties also offer further development possibilities in the future, such as developing dataset models based on input properties or LCIA based in part on flow property data. The new option of parametrization of unit processes can be regarded as powerful tool for user-friendly modification of LCI data according to specific conditions, e.g., creation of processes for new geographies or carrying out sensitivity analysis. Unfortunately, implementation of the properties and parametrization data of version 3 is still missing in most commercial LCA software tools at the moment.
4 Conclusions
The development of ecoinvent version 3 aimed to establish a robust, flexible data system for the management of a global inventory database. Key features envisioned were the support for regionalized LCI data and regionalized LCIA, application of multiple system models and the flexibility to introduce new models, complex supply chain data, increased transparency in documentation and flow properties, and integration of data models in datasets among others. While the development of version 3 was complex and time-consuming, the core goals were achieved. At the same time, the many changes now need to demonstrate their benefits in application, and a careful assessment of the value versus the cost for some complex features will be carried out. Version 3 was a revolution in the development of the ecoinvent database, and it will be followed by a process of gradual evolution and consolidation to capitalize on the capabilities and benefits it offers. With multiple system models, consistent consumption mixes, global supply chains, support for regionalized LCIA, support for water footprinting, improved transport modeling, increased transparency through parametrization and improved documentation in the datasets, and more flow information in the form of properties, version 3 offers many possibilities on the technical level that previous versions did not.
References
Amor MB, Gaudreault C, Pineau P-O, Samson R (2014) Implications of integrating electricity supply dynamics into life cycle assessment: a case study of renewable distributed generation. Renew Energ 69:410–419
Arvesen A, Hertwich E (2015) More caution is needed when using life cycle assessment to determine energy return on investment (EROI). Energ Policy 76:1–6
Bauer C, Hofer J, Althaus H-J, Del Duce A, Simons A (2015) The environmental performance of current and future passenger vehicles: life cycle assessment based on a novel scenario analysis framework. Appl Energy
Bouman EA, Ramirez A, Hertwich E (2015) Multiregional environmental comparison of fossil fuel power generation—assessment of the contribution of fugitive emissions from conventional and unconventional fossil resources. Int J Greenh Gas Con
Bourgault G, Lesage P, Samson R (2012) Systematic disaggregation: a hybrid LCI computation algorithm enhancing interpretation phase in LCA. Int J Life Cycle Assess 17:774–786
Cherubini F, Bargigli S, Ulgiati S (2009) Life cycle assessment (LCA) of waste management strategies: landfilling, sorting plant and incineration. Energy 34:2116–2123
Ciroth A, Muller S, Weidema B, Lesage P (2013) Empirically based uncertainty factors for the pedigree matrix in ecoinvent. Int J Life Cycle Assess. doi:10.1007/s11367-013-0670-5
Del Duce A, Gauch M, Althaus H-J (2014) Electric passenger car transport and passenger car life cycle inventories in ecoinvent version 3. Int J Life Cycle Assess. doi:10.1007/s11367-014-0792-4
Earles J, Halog A (2011) Consequential life cycle assessment: a review. Int J Life Cycle Assess 16:445–453
EC (2010) International Reference Life Cycle Data System (ILCD) Handbook—general guide for life cycle assessment—detailed guidance. European Commission, Joint Research Centre, Institute for Environment and Sustainability, Luxembourg
Ekvall T, Weidema BP (2004) System boundaries and input data in consequential life cycle inventory analysis. Int J Life Cycle Assess 9:161–171
Finnveden G (1999) Methodological aspects of life cycle assessment of integrated solid waste management systems. Resour Conserv Recycl 26:173–187
Frischknecht R et al (2005) The ecoinvent database: overview and methodological framework. Int J Life Cycle Assess 10:3–9
Heijungs R, Guinée J (2007) Allocation and ‘what-if’ scenarios in life cycle assessment of waste management systems. Waste Manage 27:997–1005
Henriksson P, Zhang W, Guinée JB (2015) Updated unit process data for coal-based energy in China including parameters for overall dispersions. Int J Life Cycle Assess 20:185–195
Hertwich E et al (2014) Integrated life-cycle assessment of electricity-supply scenarios confirms global environmental benefit of low-carbon technologies. Proc Natl Acad Sci U S A. doi:10.1073/pnas.1312753111
Hou Q, Mao G, Zhao L, Du H, Zuo J (2015) Mapping the scientific research on life cycle assessment: a bibliometric analysis. Int J Life Cycle Assess. doi:10.1007/s11367-015-0846-2
ISO (2006a) ISO 14040. Environmental management—life cycle assessment—principles and framework. International Organisation for Standardisation (ISO)
ISO (2006b) ISO 14044. Environmental management—life cycle assessment—requirements and guidelines. International Organisation for Standardisation (ISO)
Laurent A, Espinosa N (2015) Environmental impacts of electricity generation at global, regional and national scales in 1980–2011: what can we learn for future energy planning? Energy Environ Sci 8:689–701
Lesage P, Samson R (2013) The Quebec Life Cycle Inventory Database Project. Int J Life Cycle Assess. doi:10.1007/s11367-013-0593-1
Levova T (2013) Water Use Modelling With ecoinvent v3 Opens New Possibilities. LCA XIII, Orlando, September 30th - October 3rd 2013
Masanet E et al (2013) Life-cycle assessment of electric power systems. Annu Rev Environ Resour 38:107–136
Meinshausen I, Müller-Beilschmidt P, Viere T (2014) The EcoSpold 2 format—why a new format? Int J Life Cycle Assess. doi:10.1007/s11367-014-0789-z
Muller S, Lesage P, Ciroth A, Mutel C, Weidema B, Samson R (2014) The application of the pedigree approach to the distributions foreseen in ecoinvent v3. Int J Life Cycle Assess. doi:10.1007/s11367-014-0759-5
Mutel CL, Hellweg S (2009) Regionalized life cycle assessment: computational methodology and application to inventory databases. Environ Sci Technol 43:5797–5803
Mutel C, Pfister S, Hellweg S (2012) GIS-based regionalized life cycle assessment: how big is small enough? Methodology and case study of electricity generation. Environ Sci Technol 46:1096–1103
Mutel C, de Baan L, Hellweg S (2013) Two-step sensitivity testing of parametrized and regionalized life cycle assessments: methodology and case study. Environ Sci Technol 47:5660–5667
Nemecek T, Schnetzer J, Reinhard J (2014) Updated and harmonised greenhouse gas emissions for crop inventories. Int J Life Cycle Assess. doi:10.1007/s11367-014-0712-7
OGC (2014) KML—Keyhole Markup Language version 2.2. Open Geospatial Consortium, Wayland
Pehnt M, Oeser M, Swider DJ (2008) Consequential environmental system analysis of expected offshore wind electricity production in Germany. Energy 33:747–759
Pfister S, Koehler A, Hellweg S (2009) Assessing the environmental impacts of freshwater consumption in LCA. Environ Sci Technol 43:4098–4104
Potting J, Hauschild M (1997) Spatial differentiation in life-cycle assessment via the site-dependent characterisation of environmental impact from emissions. Int J Life Cycle Assess 2:209–216
Potting J, Hauschild M (2006) Spatial differentiation in life cycle impact assessment: a decade of method development to increase the environmental realism of LCIA. Int J Life Cycle Assess 11:11–13
Reinhard J, Zah R (2009) Global environmental consequences of increased biodiesel consumption in Switzerland: consequential life cycle assessment. J Clean Prod 17(suppl 1):S46–S56
Scharlemann JPW, Laurance WF (2008) Environmental science: how green are biofuels? Science 319:43–44
Simons A (2013) Road transport: new life cycle inventories for fossil-fuelled passenger cars and non-exhaust emissions in ecoinvent v3. Int J Life Cycle Assess. doi:10.1007/s11367-013-0642-9
Simons A, Bauer C (2012) Life cycle assessment of the European pressurized reactor and the influence of different fuel cycle strategies. Proc Inst Mech Eng, Part A: J Power Energy 226:427–444
Sternberg A, Bardow A (2015) Power-to-What?—environmental assessment of energy storage systems. Energy Environ Sci 8:389–400
Steubing B, Wernet G, Reinhard J, Bauer C, Moreno E (2016) The ecoinvent database version 3 (part II): analyzing LCA results and comparison to version 2. Int J Life Cycle Assess. doi:10.1007/s11367-016-1109-6
Stoessel F, Juraske R, Pfister S, Hellweg S (2012) Life cycle inventory and carbon and water foodprint of fruits and vegetables: application to a Swiss retailer. Environ Sci Technol 46:3253–3262
Suh S, Yang Y (2014) On the uncanny capabilities of consequential LCA. Int J Life Cycle Assess 19:1179–1184
Suh S, Leighton M, Tomar S, Chen C (2013) Interoperability between ecoinvent ver. 3 and US LCI database: a case study. Int J Life Cycle Assess. doi:10.1007/s11367-013-0592-2
Swiss Confederation (2014) SR 641.611 - Mineralölsteuerverordnung. Swiss Confederation, Bern
The ecoinvent LCA database, v3.1, “cut-off by classification” (2014) The ecoinvent center. www.ecoinvent.org
Tillman A-M (2000) Significance of decision-making for LCA methodology. Environ Impact Assess Rev 20:113–123
Tonini D, Hamelin L, Wenzel H, Astrup T (2012) Bioenergy production from perennial energy crops: a consequential LCA of 12 bioenergy scenarios including land use changes. Environ Sci Technol 46:13521–13530
Treyer K, Bauer C (2013) Life cycle inventories of electricity generation and power supply in version 3 of the ecoinvent database—part I: electricity generation. Int J Life Cycle Assess. doi:10.1007/s11367-013-0665-2
Treyer K, Bauer C (2014) Life cycle inventories of electricity generation and power supply in version 3 of the ecoinvent database—part II: electricity markets. Int J Life Cycle Assess. doi:10.1007/s11367-013-0694-x
Treyer K, Bauer C, Simons A (2014) Human health impacts in the life cycle of future European electricity generation. Energ Policy 74:S31–S44
Turconi R, Tonini D, Nielsen CFB, Simonsen CG, Astrup T (2014) Environmental impacts of future low-carbon electricity systems: detailed life cycle assessment of a Danish case study. Appl Energy 132:66–73
Volkart K, Bauer C, Boulet C (2013) Life cycle assessment of carbon capture and storage in power generation and industry in Europe. Int J Greenh Gas Con 16:91–106
von der Assen N, Jung J, Bardow A (2013) Life-cycle assessment of carbon dioxide capture and utilization: avoiding the pitfalls. Energy Environ Sci 6:2721–2734
Wegener Sleeswijk A, Heijungs R (2010) GLOBOX: a spatially differentiated global fate, intake and effect model for toxicity assessment in LCA. Sci Total Environ 408:2817–2832
Weidema B (2014) Has ISO 14040/44 failed its role as a standard for life cycle assessment? J Ind Ecol 18:324–326
Weidema B, Ekvall T, Heijungs R (2009) Guidelines for application of deepened and broadened LCA. ENEA, The Italian National Agency on new technologies, energy and the environment
Weidema BP et al (2013) Overview and methodology. Data quality guideline for the ecoinvent database version 3. The ecoinvent Centre, St. Gallen
Wernet G, Conradt S, Isenring H, Jiménez-González C, Hungerbühler K (2010) Life cycle assessment of fine chemical production: a case study of pharmaceutical synthesis. Int J Life Cycle Assess 15:294–303
Wernet G, Mutel C, Hellweg S, Hungerbühler K (2011) The environmental importance of energy use in chemical production. J Ind Ecol 15:96–107
Wernet G, Hellweg S, Hungerbühler K (2012) A tiered approach to estimate inventory data and impacts of chemical products and mixtures. Int J Life Cycle Assess 17:720–728
Yue D, You F, Darling SB (2014) Domestic and overseas manufacturing scenarios of silicon-based photovoltaics: life cycle energy and environmental comparative analysis. Sol Energy 105:669–678
Zamagni A, Guinée J, Heijungs R, Masoni P, Raggi A (2012) Lights and shadows in consequential LCA. Int J Life Cycle Assess 17:904–918
Acknowledgments
The authors would like to thank Tereza Levova, Sofia Parada Tur, Thomas Nemecek, Karin Treyer, Carl Vadenbo and especially Roland Hischier for their many contributions towards the development of ecoinvent version 3, as well as Gabor Doka for the original design of Fig. 5, which is reused here with permission.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Responsible editor: Rainer Zah
Rights and permissions
About this article
Cite this article
Wernet, G., Bauer, C., Steubing, B. et al. The ecoinvent database version 3 (part I): overview and methodology. Int J Life Cycle Assess 21, 1218–1230 (2016). https://doi.org/10.1007/s11367-016-1087-8
Received:
Accepted:
Published:
Issue date:
DOI: https://doi.org/10.1007/s11367-016-1087-8
