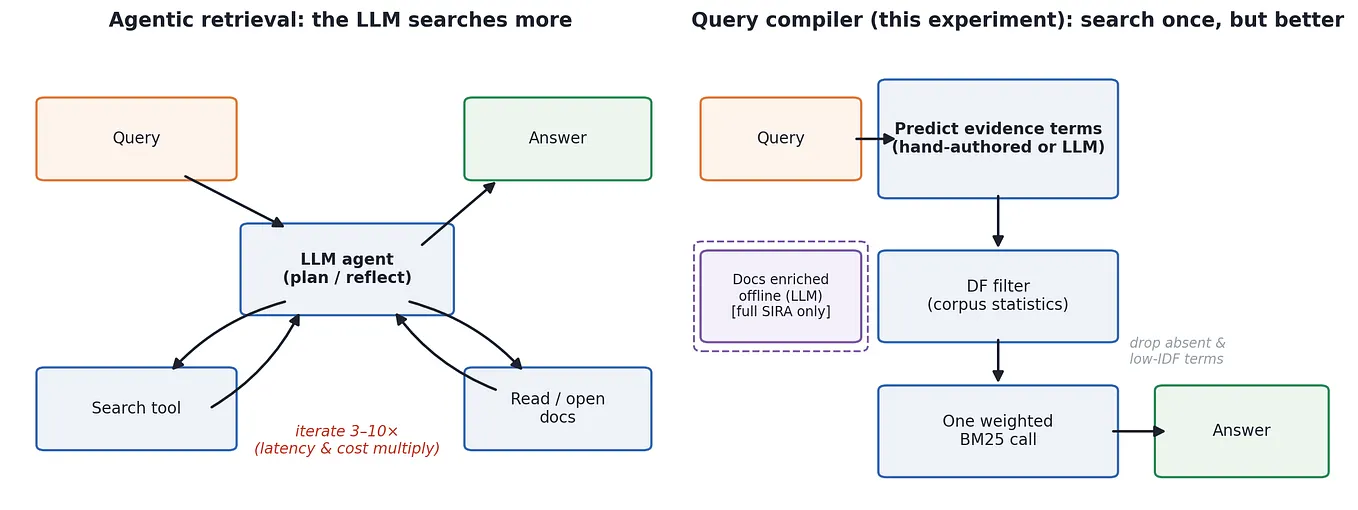
InData Science CollectivebyCagatay Akcam·6d agoBefore Another RAG Hop, Try Compiling the Query for BM25Meta’s SIRA paper made me stop and rethink the usual RAG stack — embeddings, rerankers, agent loops. Their pipeline ends in a weighted BM25…A response icon4
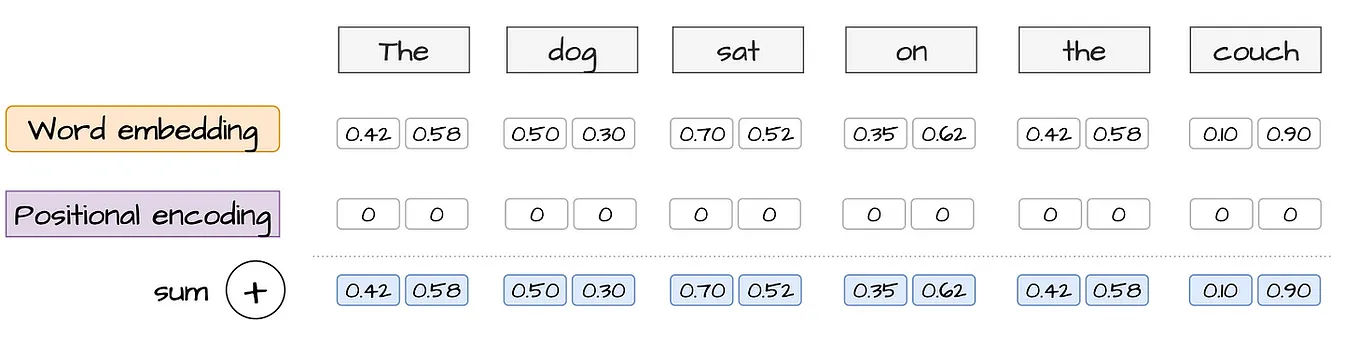
InData Science CollectivebyJose Parreño·May 9Understanding Transformers (Part 3): Positional encodings and word embeddingsWhy position matters and how sine and cosine waves saved TransformersA response icon3
InAI AdvancesbyNajib Sharifi, Ph.D.·May 7Back Propagation Through Time: The Mathematical Foundation of RNNsWhat do stock data, a half finished sentence and an audio clip all have in common?A response icon3A response icon3
InStackademicbyOkan Yenigün·May 3Understanding Mamba: The Architecture That Challenges the TransformerFrom RNNs to Mamba: How Sequence Models Learned to Remember SelectivelyA response icon2A response icon2
InTowards AIbyFabio Angeletti·Apr 8Training a Tokenizer That Actually Speaks ItalianWhy every English tokenizer butchers Italian, the encoding switch that wasted my first attempt, and the regex that keeps “dell’algoritmo”…A response icon4A response icon4
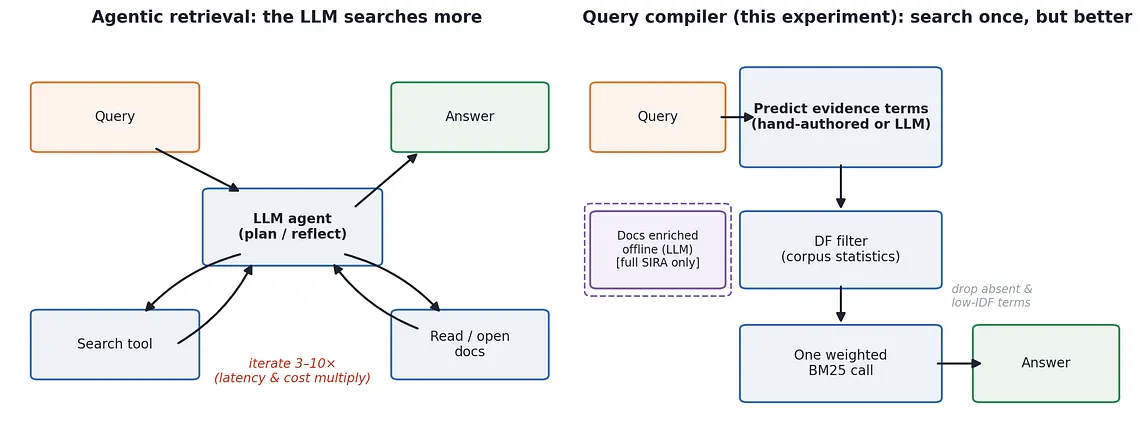
InData Science CollectivebyCagatay Akcam·6d agoBefore Another RAG Hop, Try Compiling the Query for BM25Meta’s SIRA paper made me stop and rethink the usual RAG stack — embeddings, rerankers, agent loops. Their pipeline ends in a weighted BM25…A response icon4
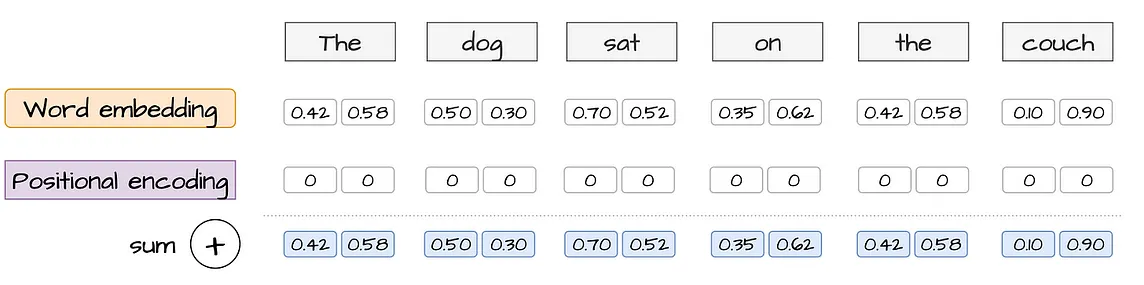
InData Science CollectivebyJose Parreño·May 9Understanding Transformers (Part 3): Positional encodings and word embeddingsWhy position matters and how sine and cosine waves saved TransformersA response icon3
InAI AdvancesbyNajib Sharifi, Ph.D.·May 7Back Propagation Through Time: The Mathematical Foundation of RNNsWhat do stock data, a half finished sentence and an audio clip all have in common?A response icon3
InStackademicbyOkan Yenigün·May 3Understanding Mamba: The Architecture That Challenges the TransformerFrom RNNs to Mamba: How Sequence Models Learned to Remember SelectivelyA response icon2
InTowards AIbyFabio Angeletti·Apr 8Training a Tokenizer That Actually Speaks ItalianWhy every English tokenizer butchers Italian, the encoding switch that wasted my first attempt, and the regex that keeps “dell’algoritmo”…A response icon4
InTowards AIbyFabio Yáñez Romero·Mar 30From Text to Knowledge Graph in One Command: Building a Modular LLM-Backed FrameworkHow abstraction, registries, and a clean CLI turn chaotic text into structured, queryable knowledge — without locking you into a single…A response icon4
InTowards AIbyAnthony Menghi - antocreadev·Mar 27You Don’t Need RAG. You Need Semantic Compression.How I solved a chunk selection problem that the current state of the art overlooks and why K-means is the unexpected answerA response icon13
InTowards AIbyClement Piat·Mar 165 Thoughts on LLM Capabilities and LimitationsThere are different views on the fundamental limitations of Large Language Models.