 全新NVIDIA Nemotron 3 Super模型重磅发布
全新NVIDIA Nemotron 3 Super模型重磅发布

一款全新的开放 1,200 亿参数混合式 MoE (mixture‑of‑experts) 模型,专为 NVIDIA Blackwell 进行了优化,可解决拖慢自主智能体工作流的长时推理和上下文爆炸的成本难题。
NVIDIA Nemotron 3 Super 于今日发布,其为一款 1,200 亿参数开放模型,拥有 120 亿个活跃参数,旨在大规模运行复杂的代理式 AI 系统。
该模型现已上线,融合先进的推理能力,能够高效并精准地完成自主智能体的任务。
AI 原生公司:Perplexity 不仅为用户提供 Nemotron 3 Super 访问权限用于搜索,还将其作为 ‘Computer’ 平台中 20 个编排模型的组成部分。CodeRabbit、Factory 和 Greptile 等提供软件开发智能体的公司将该模型与自有模型结合,并集成到 AI 智能体中,在降低成本的同时提升准确性。Edison Scientific 和 Lila Sciences 等生命科学及前沿 AI 机构则将借助该模型为其智能体赋予深度文献检索、数据科学与分子理解能力。
企业软件平台:Amdocs、Palantir、Cadence、达索系统和西门子等行业领先企业,正部署并定制该模型,用于电信、网络安全、半导体设计与制造等领域的工作流自动化。
企业从聊天机器人向多智能体应用演进时,会面临两大制约因素。
第一个制约因素是上下文爆炸。与标准聊天相比,多智能体工作流生成的 token 数量多达其 15 倍,因为每次交互都需要重新发送完整的历史记录,包括工具输出和中间推理结果。
在长任务中,这样庞大的上下文不仅增加了成本,还可能导致目标偏离,即智能体在执行过程中逐渐脱离最初设定的任务目标。
第二个制约因素则是思考税。复杂智能体每一步都必须进行推理,但如果每个子任务都使用大模型,多智能体应用就会变得成本高昂和迟缓,难以投入实际使用。
Nemotron 3 Super 拥有一个 100 万 token 的上下文窗口,允许智能体在显存中保留完整的工作流状态,并防止目标偏离。
Nemotron 3 Super 树立了新标准,在 Artificial Analysis 的效率和开放性排名中位居榜首,并在同等规模的模型中展现出领先的准确性。
该模型还助力 NVIDIA AI-Q 研究智能体在 DeepResearch Bench 和 DeepResearch Bench II 排行榜上取得第一名。这些基准测试旨在衡量 AI 系统在海量文档中开展全面多步骤研究,并保持推理连贯性的能力。
混合架构
Nemotron 3 Super 采用了混合 MoE (mixture‑of‑experts) 架构,结合了三项主要创新,与之前的 Nemotron Super 模型相比,实现了高达 5 倍的吞吐量提升和高达 2 倍的准确率提升。
混合架构:Mamba 层实现 4 倍显存与计算效率提升,Transformer 层则提供高级推理能力。
混合专家 (MoE):在其 1,200 亿参数中,推理时仅激活 120 亿参数。
潜在混合专家 (MoE) 架构:这是一种新的推理技术,它以单个专家的成本来激活四个专家,从而显著提升 token 生成的准确率。
多 token 预测:能够同时预测多个未来的词语,从而使推理速度提高 3 倍。
在 NVIDIA Blackwell 平台上,该模型以 NVFP4 精度运行,降低了显存需求,并使推理速度较之在 NVIDIA Hopper 平台上使用 FP8 至高提升 4 倍,同时不损失准确性。
开放权重、数据和方案
NVIDIA 将 Nemotron 3 Super 的权重完全开放,并配以宽松许可协议。开发者可在工作站、数据中心或云端来进行部署和定制。
Nemotron 3 Super 基于前沿推理模型生成的合成数据训练而成。NVIDIA 将公布完整的训练方法,其中包括超过 10 万亿个 token 的预训练和后训练数据集,15 个用于强化学习的训练环境以及评估方案。研究人员还可借助 NVIDIA NeMo 平台对模型进行微调或构建专属模型。
在代理式系统中的应用
Nemotron 3 Super 旨在处理多智能体系统中的复杂子任务。
一个软件开发智能体可以一次性将整个代码库加载到上下文中,从而实现端到端的代码生成和调试,且无需进行文档分割。
在金融分析中,它能够将数千页的报告加载到显存中,避免在长对话中重复推理,从而提高效率。
Nemotron 3 Super 具有高精度的工具调用能力,确保自主智能体能够在海量的函数库中导航,避免在高风险环境中出现执行错误 (例如网络安全中的自主安全编排)。
如何获取
NVIDIA Nemotron 3 Super 作为 Nemotron 3 系列的一部分,可通过 NVIDIA 官网、Perplexity、OpenRouter 和 Hugging Face 获取。戴尔科技公司正将该模型引入 Hugging Face 上的 Dell Enterprise Hub,并针对 Dell AI Factory 的本地部署进行了优化,以推动多智能体 AI 工作流的发展。慧与 (HPE) 也将 NVIDIA Nemotron 引入其 Agents Hub,帮助确保在企业中扩展应用代理式 AI 。
企业与开发者可通过多家合作伙伴部署该模型:
云服务提供商:谷歌云的 Vertex AI、Oracle Cloud Infrastructure;即将登陆亚马逊云科技的 Amazon Bedrock 及 Microsoft Azure。
NVIDIA 云合作伙伴:Coreweave、Crusoe、Nebius 与 Together AI。
推理服务提供商:Baseten、CloudFlare、DeepInfra、Fireworks AI、Inference.net、Lightning AI、Modal 和 FriendliAI。
数据平台与服务:Distyl、Dataiku、DataRobot、德勤、安永及塔塔咨询服务。
该模型以 NVIDIA NIM 形式提供,支持从本地系统到云端的部署。
-
NVIDIA
+关注
关注
14文章
5682浏览量
110079 -
AI
+关注
关注
91文章
40865浏览量
302459 -
模型
+关注
关注
1文章
3810浏览量
52244
原文标题:全新 NVIDIA Nemotron 3 Super 将代理式 AI 吞吐量提升 5 倍
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA与亚马逊云科技深化合作伙伴关系
NVIDIA 成立由全球领先 AI 实验室组成的 Nemotron Coalition,推动开放前沿模型发展

NVIDIA 扩展开放模型系列,推动代理式、物理和医疗 AI 下一阶段发展

NVIDIA Jetson模型赋能AI在边缘端落地

利用NVIDIA Nemotron开放模型构建智能文档处理系统
NVIDIA在CES 2026发布全新开放模型、数据和工具
深入解析NVIDIA Nemotron 3系列开放模型
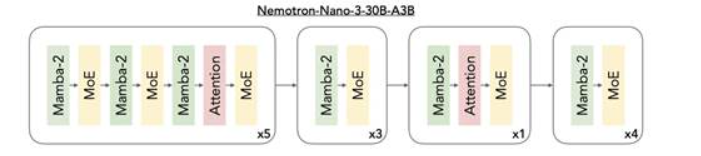
NVIDIA 推出 Nemotron 3 系列开放模型

NVIDIA携手Mistral AI发布全新开源大语言模型系列
NVIDIA推动面向数字与物理AI的开源模型发展
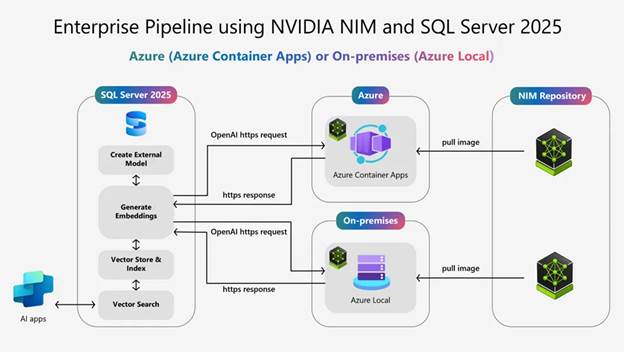
使用NVIDIA Nemotron RAG和Microsoft SQL Server 2025构建高性能AI应用
NVIDIA Nemotron Nano 2推理模型发布




 工商网监
工商网监

评论