
TL;DR
| Tool | Best for | Quick differentiator |
|---|---|---|
| Firecrawl | AI and LLM data pipelines | Open source (top 100 GitHub repos), clean Markdown and JSON from one API, plus search, interact, and monitoring |
| Bright Data | Enterprise-scale proxy operations | Large proxy network with per-product scraping APIs |
| Apify | Marketplace-led automation | 40,000+ prebuilt Actors and full platform control |
| Oxylabs | Proxy-heavy scraping at scale | Premium proxy infrastructure with a managed scraper API |
| Octoparse | Non-technical, point-and-click users | Desktop no-code builder with templates |
- Choose Firecrawl if you want machine-readable output your model can use immediately.
- Choose Bright Data or Oxylabs if your bottleneck is proxy scale and unblocking.
- Choose Apify if you want a marketplace of ready-made scrapers.
- Choose Octoparse if you want a visual tool and write no code.
We have to tip our hats to ScrapingBee. The team has built quite a capable web scraping API, and for many teams it handles all scraping needs well. But you may still hit a point where credit costs, output format, or the scale cap pushes you to look around. And if you're already there, this guide is for you.
I looked at five ScrapingBee alternatives, the closest competitors in 2026, and tested them myself rather than relying on secondhand reviews, so the numbers here are what I actually saw.
The data is updated as of June 16, 2026.
What is ScrapingBee?
ScrapingBee is a web scraping API that handles proxies, headless browsers, and anti-bot defenses so you can simply request a page and get its contents back. It's positioned as the web scraping API that prevents you from getting blocked.
The core product is a scraping API that returns the page source by default, with a handful of capabilities layered on top:
- JavaScript rendering in a headless Chrome browser
- Automatic proxy rotation, with premium and stealth residential proxies for harder targets
- Geotargeting and full-page screenshots
- CSS and XPath extraction rules, so you can pull specific fields without parsing the HTML yourself
- AI data extraction via additional parameters (
ai_queryandai_extract_rules) for schema-based or prompt-based output - A Google Search API, plus dedicated Amazon and Walmart endpoints
As of June 2026, the pricing is credit based and plans run from Freelance at $49/mo (250,000 credits, 10 concurrent requests) up to Business+ at $599/mo (8,000,000 credits, 200 concurrent requests), with a free trial of 1,000 credits and no card required.
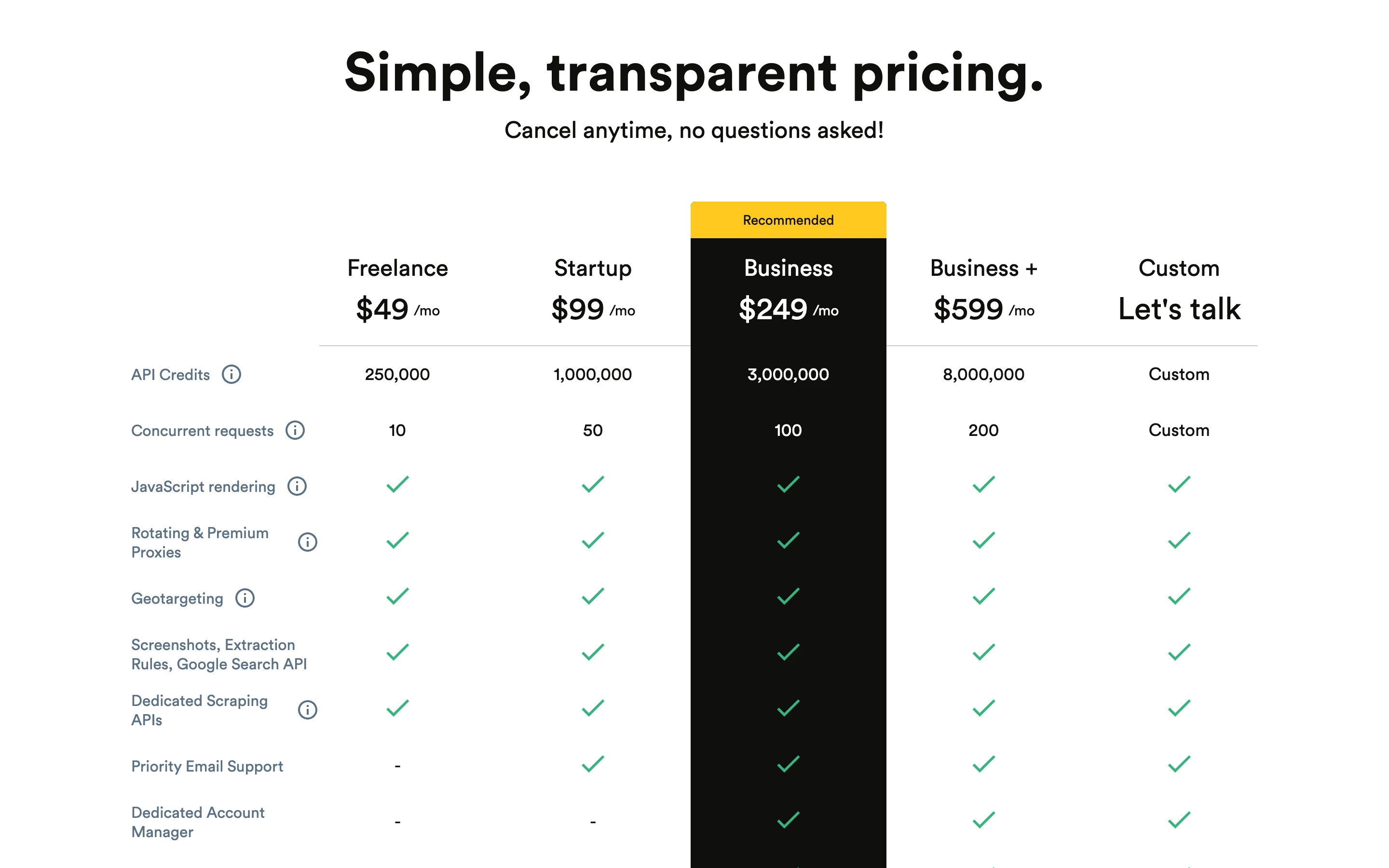
ScrapingBee's docs say a basic request is cheap, but the premium and stealth proxies you need for tough sites cost far more. A single stealth-proxy call costs 75 credits, so a plan's credits can run out much faster than the advertised number suggests when you scrape hard targets.
Top 5 ScrapingBee alternatives in 2026
Each tool below wins on a different axis: Firecrawl for AI-ready output, Bright Data and Oxylabs for proxy scale, Apify for marketplace automation, and Octoparse for no-code access.
| Alternative | Best for | Quick differentiator |
|---|---|---|
| Firecrawl | AI and LLM pipelines | Markdown and JSON output, plus search and monitoring |
| Bright Data | Enterprise proxy scale | Large proxy network and per-product APIs |
| Apify | Marketplace automation | 40,000+ prebuilt Actors |
| Oxylabs | Proxy-heavy scraping | Premium proxy infrastructure |
| Octoparse | No-code users | Visual desktop builder |
1. Firecrawl: API-first scraping built for AI
Firecrawl is an open-source, API-first platform built for teams that feed live web data into models. Where ScrapingBee returns the page source by default and offers AI extraction as an opt-in layer, Firecrawl's default response is already model-ready Markdown or schema-defined JSON in one call.
Key features
- Scrape turns any page into clean Markdown or structured JSON in one call
- Search lets you query the web and get full page content back, not just links
- Interact clicks, fills forms, logs in, and navigates JavaScript-heavy flows
- Crawl and Map pull an entire site or list every URL on a domain
- /monitor watches pages or whole sites and notifies your agent the moment content changes
- Open source, with Python, Node, and REST SDKs and 1,000 free credits per month
How does Firecrawl compare to ScrapingBee?
On the same JavaScript-rendered page (Hacker News), Firecrawl returned roughly 55% fewer characters and ran about 2.5× faster than ScrapingBee. Here are the exact numbers from that test.
ScrapingBee returned 34,873 characters of raw HTML in about 2.85 seconds, with a response cost of 5 credits for the rendered request. Firecrawl returned the same page as 15,371 characters of clean Markdown in about 1.16 seconds, with the page title already parsed into metadata.
Here is the Firecrawl call that produced the output above:
from firecrawl import Firecrawl
firecrawl = Firecrawl(api_key="fc-YOUR-API-KEY")
doc = firecrawl.scrape("https://news.ycombinator.com", formats=["markdown"])
print(doc.markdown)For structured data extraction, you pass a schema and Firecrawl returns JSON directly, with no HTML parsing in between:
schema = {
"type": "object",
"properties": {
"top_stories": {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"points": {"type": "integer"},
},
},
}
},
}
doc = firecrawl.scrape(
"https://news.ycombinator.com",
formats=[{"type": "json", "schema": schema}],
)
print(doc.json)Output
{
"top_stories": [
{ "title": "MiMo Code is now released and open-source", "points": 229 },
{ "title": "Lines of code got a better publicist", "points": 271 },
{ "title": "Show HN: Homebrew 6.0.0", "points": 107 }
]
}Both tools rendered the JavaScript page reliably. ScrapingBee's default scrape returns HTML for you to parse or pass to its AI extraction parameters as a follow-on step, while Firecrawl's default already returns parsed Markdown that maps to what you asked for. In this test that was less than half the characters, 15,371 versus 34,873, which means fewer input tokens reach your model on every call. Firecrawl is built to be token efficient, so every call costs less downstream.
| Feature | Firecrawl | ScrapingBee |
|---|---|---|
| Default scrape output | Markdown and structured JSON | HTML (AI extraction via parameters) |
| Built-in search | Yes (Search suite) | Google Search API |
| Change monitoring | Yes (/monitor) | Via dedicated APIs and polling |
| Interaction / browser | Yes (Interact suite) | JS scenarios in headless Chrome |
| Open source | Yes | Proprietary |
| Language SDKs | Python, Node, REST | Python, Node, REST |
How much does Firecrawl cost?
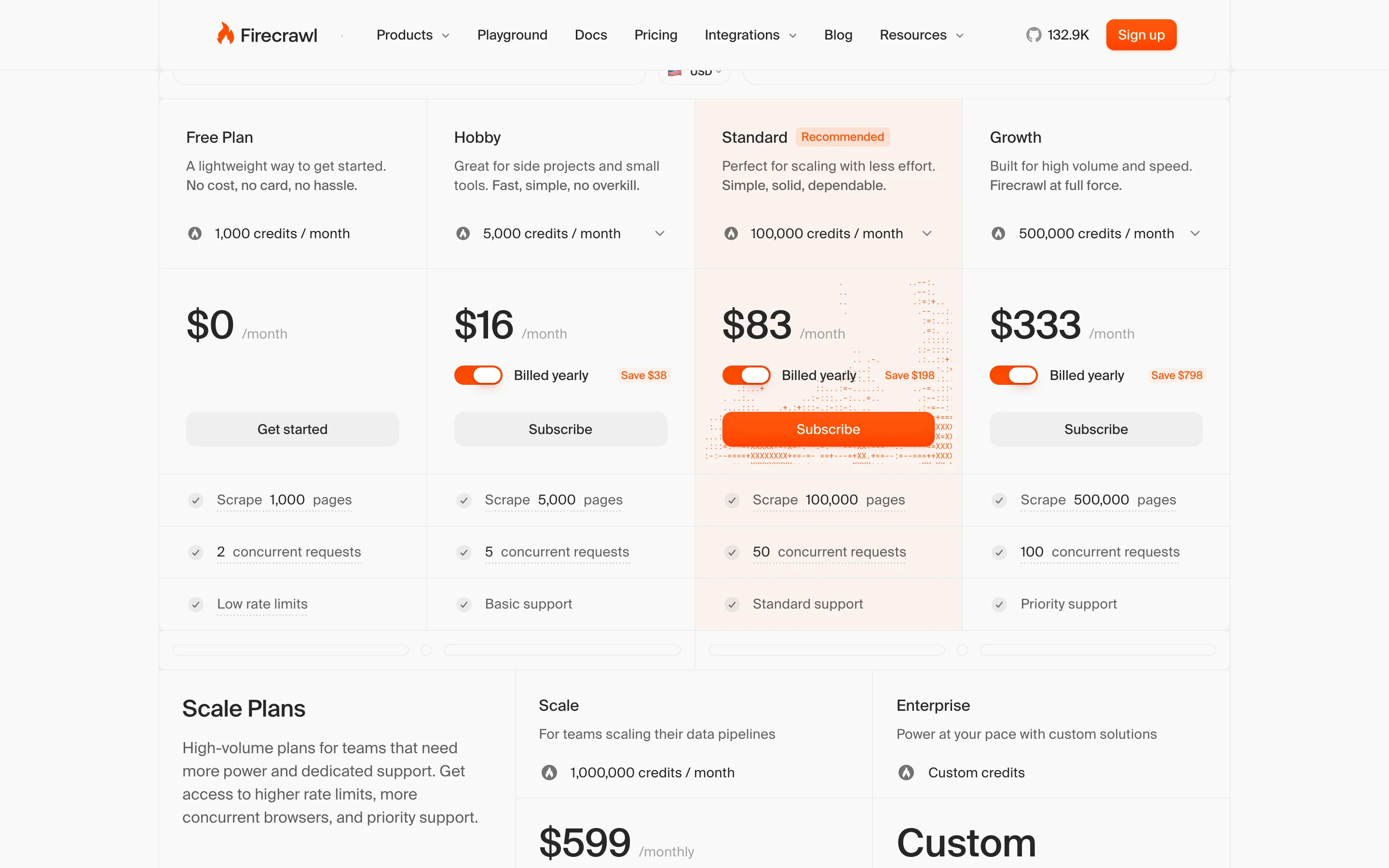
Firecrawl uses transparent, credit-based pricing where one credit covers one page.
| Plan | Monthly cost | Credits included |
|---|---|---|
| Free | $0 | 1,000 |
| Hobby | $16 | 5,000 |
| Standard | $83 | 100,000 |
| Growth | $333 | 500,000 |
| Enterprise | Custom | Custom |
When should you choose Firecrawl over ScrapingBee?
Pick Firecrawl when your output feeds a model, an agent, or a vector store and you want Markdown or JSON without a parsing layer. The combination of scrape, search, interact, and monitoring in one API also suits teams that want a single web-data dependency rather than several.
Firecrawl is the complete web data API. For teams that need to go one layer up and need web search along with web scrape and web crawl, Firecrawl is your best choice.
2. Bright Data: proxy infrastructure at enterprise scale
Bright Data is built around one of the largest proxy networks in the market, with a family of scraping products layered on top. It suits organizations whose main challenge is sustained, high-volume access to heavily defended sites.
The product line includes a Web Scraper API, Web Unlocker, Scraping Browser, SERP API, residential and datacenter proxies, and ready-made datasets. The company reports more than 20,000 customers, and the breadth is aimed at large data operations rather than quick one-off jobs.
Key features
- Web Scraper API with pre-built scrapers for specific domains, returning structured JSON, NDJSON, or CSV
- Web Unlocker returns unblocked HTML with automatic CAPTCHA solving, retries, and JS rendering
- Scraping Browser for Playwright or Puppeteer automation routed through the proxy network
- SERP API for structured search-engine results
- Residential, datacenter, ISP, and mobile proxies on one of the largest networks available
- Ready-made datasets marketplace for common sources
- Bulk async jobs up to 5,000 URLs, delivered to webhook, API, or your own storage
- Pay only for successfully delivered records
How does Bright Data compare to ScrapingBee?
Bright Data returns already-structured JSON, NDJSON, or CSV from pre-built scrapers for specific domains like Amazon, LinkedIn, TikTok, and Zillow, delivered to a webhook, the API, or your storage. It is a bulk, async tool (up to 5,000 URLs per job, billed per delivered record), so it fits supported-domain datasets at scale more than one-off arbitrary pages.
| Bright Data Web Scraper API | ScrapingBee | |
|---|---|---|
| What you get back | Parsed JSON, NDJSON, or CSV | HTML by default; JSON via CSS/XPath rules or AI extraction parameters |
| Coverage model | Pre-built scrapers per supported domain | Generic fetch on any URL |
| Execution | Async bulk jobs, up to 5,000 URLs per request | Synchronous request and response |
| Delivery | Webhook, API, or your own storage | API response body |
| Unblocking | Web Unlocker, sold as a separate product | Premium and stealth proxies in the same call |
| Billing | Per successfully delivered record | Credits per request |
| Best fit | Enterprise datasets on supported domains | Mid-size scraping on any URL |
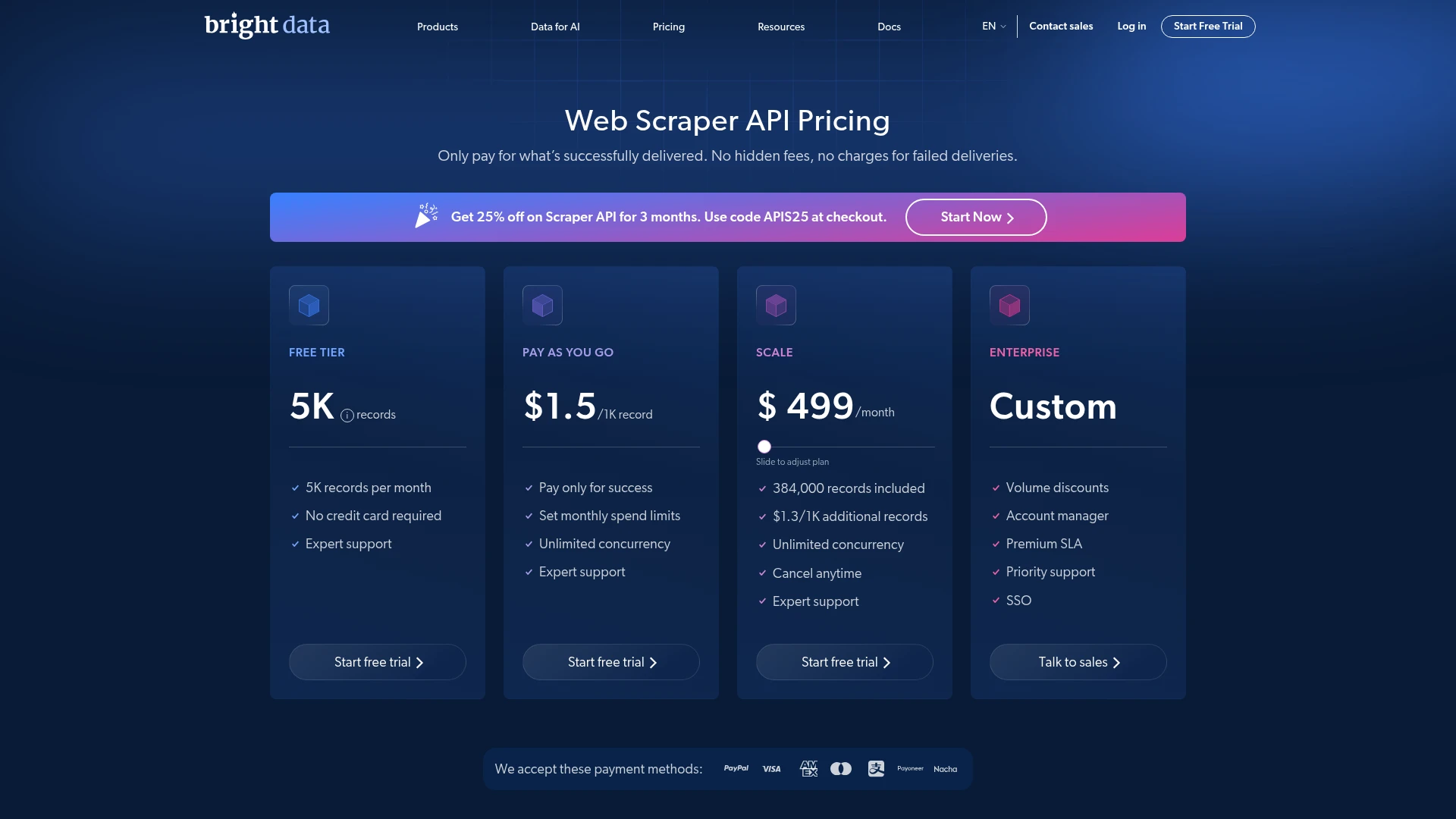
How much does Bright Data cost?
As of June 2026, Bright Data's Web Scraper API offers a free trial of 5,000 records per month, pay-as-you-go at $1.5 per 1,000 records, and a monthly plan that includes 384,000 records with additional records at $1.3 per 1,000.
Other products such as proxies and the Web Unlocker are priced separately, each on its own page.
When should you choose Bright Data over ScrapingBee?
Pick Bright Data when proxy scale and unblocking are your bottleneck and you have the volume to justify an enterprise-grade setup. The per-product pricing rewards teams that know exactly which capabilities they need.
3. Apify: a marketplace of prebuilt scrapers
Apify is a platform built around Actors, which are reusable scraping and automation programs you can run, customize, or publish. Its marketplace holds more than 40,000 prebuilt Actors, so common targets often have a ready-made scraper.
The platform gives you full control over each Actor, with scheduling, storage, and a complete API. That makes it a strong fit for teams that want to assemble workflows from existing parts rather than build every scraper from scratch.
Key features
- Marketplace of 40,000+ prebuilt Actors for common targets
- Website Content Crawler turns sites into clean text, Markdown, or HTML for LLMs and RAG
- Native integrations with LangChain, LlamaIndex, Pinecone, Qdrant, and OpenAI Assistants
- Crawlee open-source library to build, run, and publish your own Actors
- Scheduling, dataset and key-value storage, and a full REST API
- Export results as JSON, CSV, Excel, or XML
- Built-in proxies and anti-blocking
- Free plan with $5 of monthly platform usage
How does Apify compare to ScrapingBee?
Apify is a marketplace of 40,000+ Actors, so instead of one endpoint you pick the Actor that matches the job. To see what that returns, I ran its Google Maps Actor for specialty coffee shops in San Francisco. It came back with ranked places as structured JSON, each record already carrying the title, rating, review count, category, address, phone, website, opening hours, and coordinates, with no HTML to parse. The run took about 13 seconds, since Apify launches an Actor rather than answering a single synchronous request.
ScrapingBee's dedicated endpoints cover Amazon and Walmart but not Maps, so this dataset has no one-call equivalent there. For AI pipelines, a separate Apify Actor, the Website Content Crawler, returns clean Markdown instead of structured fields.
| Apify | ScrapingBee | |
|---|---|---|
| Model | 40,000+ Actors you run and compose | One scraping API |
| Site-specific scrapers | Prebuilt Actor for most popular targets (Maps, Amazon, social) | Dedicated Amazon and Walmart endpoints |
| LLM-ready output | Yes, via the Website Content Crawler (clean Markdown) | Via AI extraction parameters on the scrape API |
| AI integrations | LangChain, LlamaIndex, Pinecone, Qdrant, OpenAI | None native |
| Execution | Async Actor runs, built for batch and scheduling | Synchronous request and response |
| Output and storage | Dataset, exported as JSON/CSV/Excel/XML | API response body |
| Billing | Compute units plus plan usage | Credits per request |
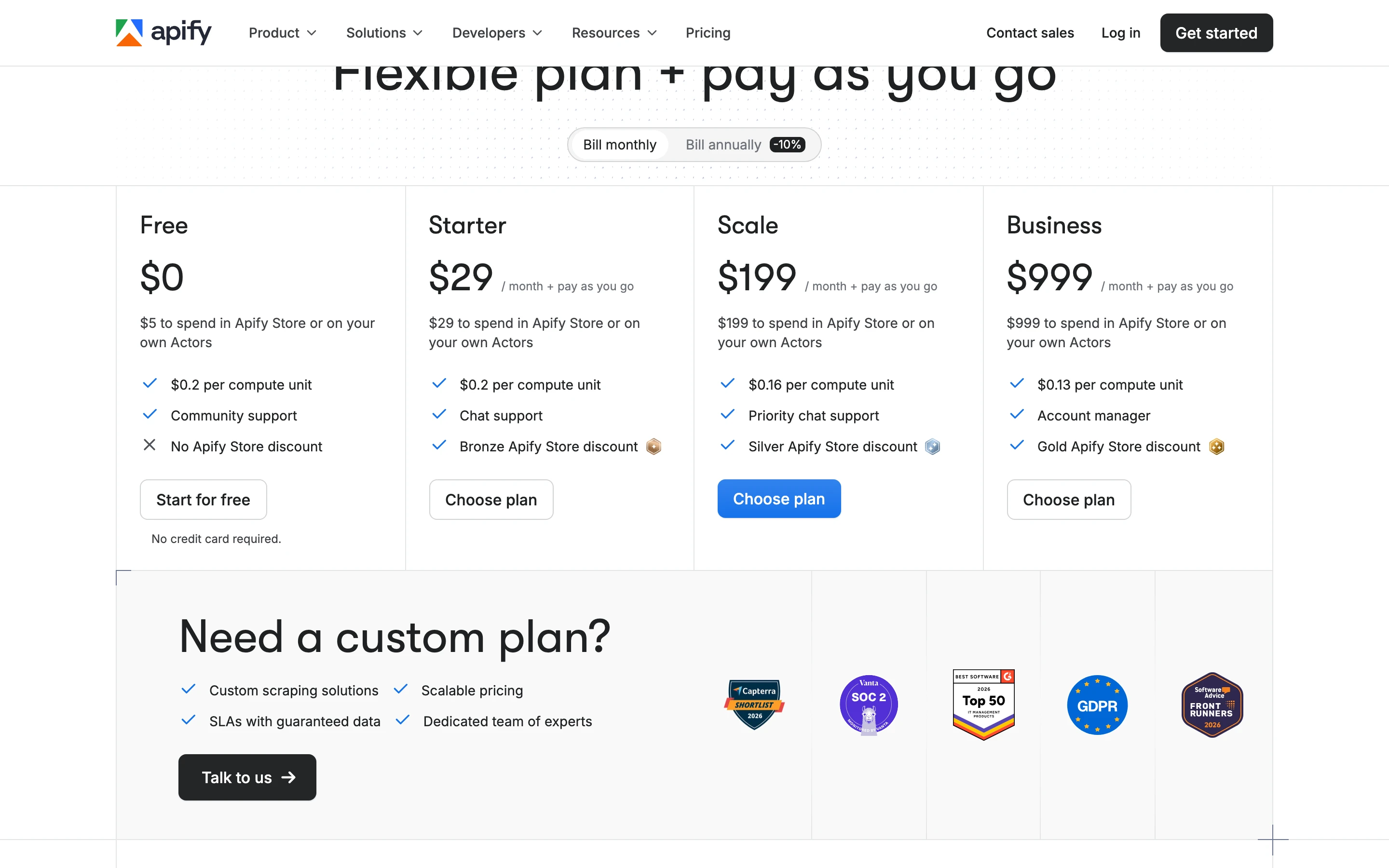
How much does Apify cost?
As of June 2026, Apify's plans are Free at $0 ($5 of platform usage, $0.20 per compute unit), Starter at $29/mo, Scale at $199/mo ($0.16 per compute unit), and Business at $999/mo ($0.13 per compute unit), with pay-as-you-go usage on top and an Enterprise tier.
When should you choose Apify over ScrapingBee?
Pick Apify when a prebuilt Actor already exists for your target or when you want to schedule and orchestrate scraping jobs on a platform. The marketplace can save significant build time for common sources.
4. Oxylabs: premium proxy infrastructure
Oxylabs is an enterprise proxy provider with a managed Web Scraper API on top of its network. It targets the same proxy-heavy, high-volume work as Bright Data, with a focus on reliability and support.
The catalog covers residential, datacenter, mobile, and ISP proxies, plus scraper APIs for general web and search targets. The emphasis is on sustained scale and unblocking rather than developer-experience features.
Key features
- Web Scraper API with dedicated per-domain parsers that return Parsed JSON
- OxyCopilot generates parsing instructions from a natural-language prompt
- SERP scraping including Google AI Overviews and AI Mode, parsed into structured data
- Residential, datacenter, ISP, and mobile proxies sold as separate products
- JavaScript rendering and geotargeting
- Real-time (sync) or async batch jobs, with push (webhook) or pull delivery
- Headless Browser and an AI Agents SDK for agent workflows
- Enterprise reliability with 24/7 support
How does Oxylabs compare to ScrapingBee?
Oxylabs returns Parsed JSON from dedicated per-domain parsers, with JavaScript rendering and geotargeting available, and its OxyCopilot assistant can generate those parsers from a plain-language prompt instead of hand-written selectors.
It can also scrape newer SERP surfaces like Google AI Overviews and AI Mode, which comes in handy if AI search results are what you are after.
| Oxylabs Web Scraper API | ScrapingBee | |
|---|---|---|
| Default output | Raw HTML or Parsed JSON via dedicated parsers | HTML by default, JSON via CSS/XPath rules or AI extraction parameters |
| Building extraction | OxyCopilot generates parsers from a prompt | You write CSS or XPath rules, or use AI extraction parameters |
| Search scraping | SERP API incl. AI Overviews and AI Mode parsing | Google Search API |
| Execution | Sync or async batch, push or pull delivery | Synchronous request and response |
| Best fit | Parsed structured data at scale | Mid-size fetch on any URL |
How much does Oxylabs cost?
As of June 2026, Oxylabs prices its Web Scraper API from $49/mo, with proxy products billed separately by gigabyte or by IP. Enterprise plans and custom commitments are available for larger volumes.
When should you choose Oxylabs over ScrapingBee?
Pick Oxylabs when you need granular control over a premium proxy network at scale and value enterprise support. The separation of proxies and scraper API helps teams that manage the network layer deliberately.
5. Octoparse: no-code, point-and-click scraping
Octoparse is a desktop no-code scraper built for people who want web data without writing code. You point and click to select fields, and a visual workflow builder handles the rest.
A template marketplace covers popular sites, so non-technical users can often start without configuring a scraper at all. The tool runs as a desktop application with optional cloud execution on paid plans.
Key features
- Visual point-and-click desktop builder for Windows and macOS
- Auto-detect plus 500+ prebuilt site templates
- Local extraction or Octoparse Cloud runs with scheduling
- IP rotation, residential proxies, and automatic CAPTCHA solving on paid plans
- Export to Excel, CSV, JSON, and HTML
- Send data to databases (MySQL, SQL Server, PostgreSQL, Oracle), Google Sheets, Google Drive, Dropbox, or S3
- Advanced API and automatic export on higher tiers
- Free plan with 10 tasks and 50,000 rows of monthly export
How does Octoparse compare to ScrapingBee?
ScrapingBee is a code-first API, while Octoparse is a point-and-click desktop app with auto-detect and 500+ templates that runs in the cloud and exports straight to spreadsheets, databases, Google Sheets, or cloud storage. Its Advanced API is a task-based add-on, not an ad-hoc endpoint. Which one fits depends on who does the work: an engineer wiring an API into a pipeline, or an analyst clicking through a visual builder.
| Octoparse | ScrapingBee | |
|---|---|---|
| Interface | Visual desktop app, point and click | REST API |
| Getting started | Auto-detect plus 500+ templates | Write code against an endpoint |
| Where it runs | Local or Octoparse Cloud | Your code, on ScrapingBee's infrastructure |
| Output destinations | Excel, CSV, JSON, databases, Google Sheets, cloud storage | HTTP response body (HTML or JSON) |
| Anti-bot | IP rotation, residential proxies, CAPTCHA solving (paid) | Premium and stealth proxies, CAPTCHA handling |
| API access | Add-on on higher plans, task-based | Core product |
| Best fit | Non-technical, visual data collection | Developers, programmatic scraping |
How much does Octoparse cost?
As of June 2026, Octoparse offers a Free plan with a 50,000-row monthly data export, a Standard plan from $69/mo, a Professional plan at $249/mo, and an Enterprise tier.
When should you choose Octoparse over ScrapingBee?
Pick Octoparse when the people collecting data do not write code and prefer a visual workflow. The template marketplace is a fast start for common, well-structured sites.
Wrapping up
ScrapingBee remains a solid web scraping API, and the right alternative depends entirely on what you are optimizing for. Proxy scale points toward Bright Data or Oxylabs, marketplace automation points toward Apify, and no-code access points toward Octoparse.
For teams feeding web data into models and agents, Firecrawl is the most natural fit because it returns Markdown and structured JSON from one API and adds search, interaction, and change monitoring in the same stack. The fastest way to decide is to run your own hardest target through two or three of these and compare the output you actually get back. You can try Firecrawl keyless with no signup, or start with the free tier and 1,000 monthly credits.
Frequently Asked Questions
What is the best ScrapingBee alternative for AI applications?
Firecrawl is the strongest fit for AI and LLM pipelines. It returns clean Markdown and structured JSON from a single API call, so the output drops straight into a model or vector store without an HTML parsing step.
Why do developers look for ScrapingBee alternatives?
The most common reasons are credit-cost predictability and pricing shape. ScrapingBee's credits are consumed at different rates depending on proxy type and JavaScript rendering, so the effective price per request is hard to forecast before running real traffic.
Is there a free ScrapingBee alternative?
Yes. Firecrawl can be tried keyless with no signup or API key, and its free tier offers 1,000 credits per month after sign-up. Apify gives $5 of platform usage on its free plan, and Octoparse has a free desktop tier with a monthly data export cap. As of June 2026 each lets you test core functionality before paying.
How does ScrapingBee's credit system work?
A request costs a variable number of credits based on the options used. ScrapingBee's documentation lists higher credit costs for premium and stealth proxies than for a classic request, and a JavaScript-rendered call in testing returned a cost of 5 credits, so the effective number of requests per plan depends on the targets being scraped.
Which ScrapingBee alternative is best for large-scale proxy scraping?
Bright Data and Oxylabs are built around large proxy networks and suit high-volume, proxy-dependent jobs. Both price proxy and scraper products separately and offer enterprise support for sustained scale.
How does Firecrawl differ from ScrapingBee on output format?
Both APIs can return structured data. ScrapingBee returns HTML by default and offers AI data extraction through additional parameters. Firecrawl returns clean Markdown or schema-defined JSON by default in a single call, so the AI-ready output is the standard response rather than an opt-in layer.

