Over the past decade, data science has shifted from deterministic models to probabilistic systems, with large language models now defining the state of the art.
In that era, our models weren't so... "unsure." They were deterministic.
Think about that for a second. "Deterministic" meant reliability. It meant that if you gave the same input to the RandomForestClassifier you spent weeks tuning, you would get the exact same output. Every. Single. Time. We could write unit tests for our models. We could build predictable, high-stakes production systems on top of them. That predictability was our bedrock.
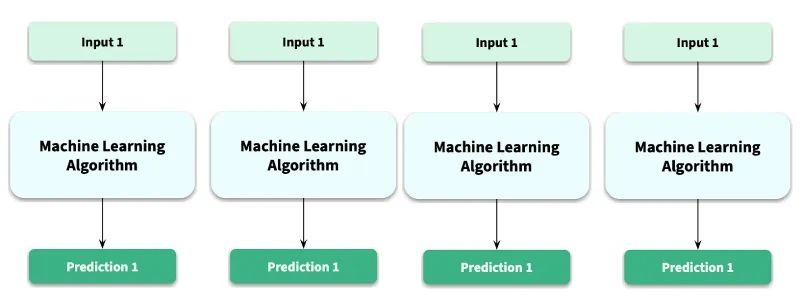
Fast forward to today, and the script has flipped entirely. The onus of making sure the predictions are consistent is now on us, the end-user. This challenge has become so critical that it has spawned an entire field of its own: Prompt Engineering.
Generative AI, by its very nature, is probabilistic. It’s generative. When you give an input to an LLM, it’s not looking up an answer; it’s predicting the next word, and the next, and the next, based on a complex web of probabilities. A tiny shift in that path can lead to a completely different, yet equally valid, response.
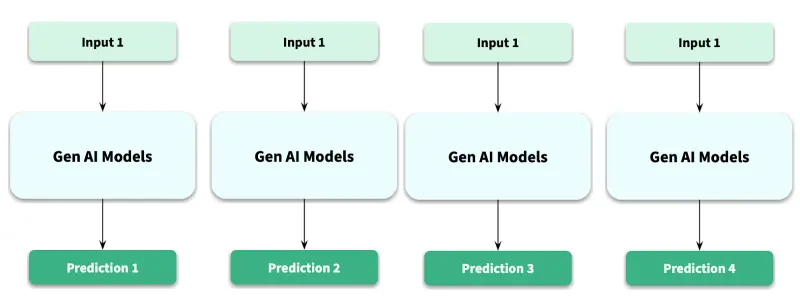
This shift from a predictable world to a probabilistic one is, in my opinion, the central challenge and opportunity for not just data scientists but also AI organisations like Open AI, Anthropic, and Google today.
And this isn't just a minor technical hurdle; it's having massive real-world consequences. We are already seeing large organisations struggling with 'AI slop' (the flood of low-quality, AI-generated content) and failing on projects. In a recent MIT study, 95% of generative AI use cases are failing to move out of the pilot phase, often due to these very issues of unreliability and inconsistency.
Let’s look at my perspective on how AI will be used in the future.
Tools
Today, we will look at something called SHAP.
SHAP, which stands for SHapley Additive exPlanations, is a powerful method used to increase the transparency of machine learning models.
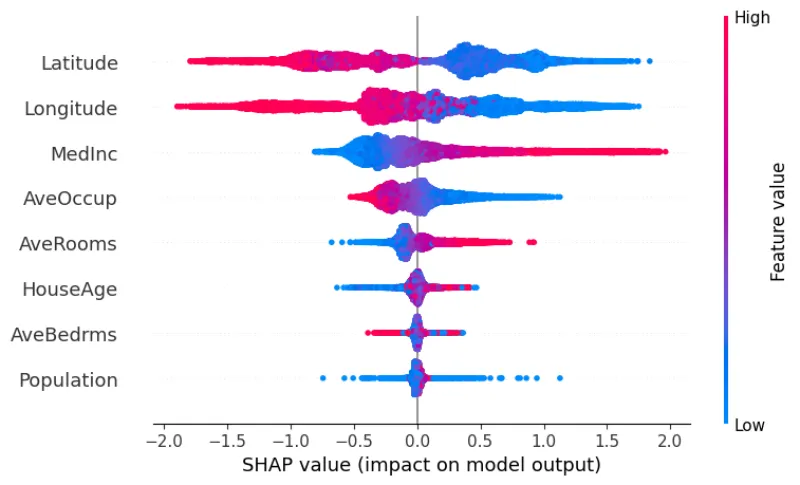
At its core, SHAP leverages a concept from cooperative game theory, the Shapley value, to explain the output of any machine learning model. It connects game theory with local explanations, producing a clear and individualized explanation for each prediction.

Instead of just knowing what the model predicted, SHAP tells you why by quantifying the contribution of each feature to the prediction. This allows data scientists to understand how different features or variables in their data influence the model's decisions, moving beyond the "black box" problem and offering a more interpretable and trustworthy approach to machine learning.
Usecase
But here's the catch with tools like SHAP (which we all love), and it's a big one: they are fantastic for us—data scientists and other technical folks. We can look at a beeswarm plot and instantly understand what's going on.
But what about our business stakeholders? The project managers, the marketing leads, the VPs? They're the ultimate decision-makers, and showing them a raw SHAP plot is often more confusing than helpful. They'll struggle to make heads or tails of it, and we'll lose them in the technical jargon.
This is exactly where Generative AI shines. It acts as our "universal translator."
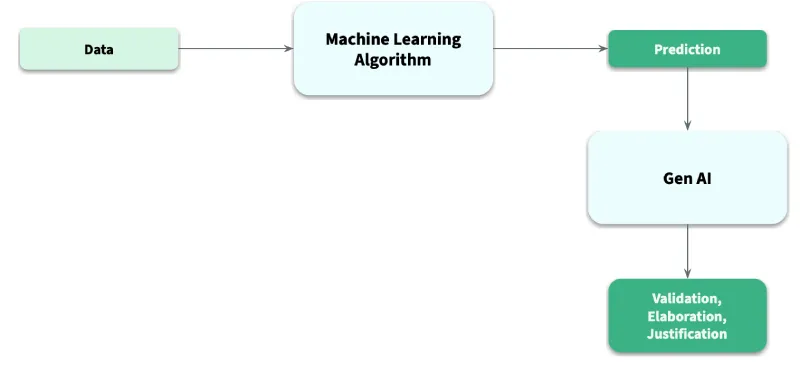
We, as data scientists, can now use Gen AI to bridge this communication gap, making our complex explainable AI (XAI) insights accessible to everyone, regardless of their technical background. Instead of us trying to manually translate our findings, we can feed the SHAP data and the plot's insights into an LLM.
Use a prompt as simple as following:
Act as a data scientist explaining this model's prediction to a project manager. Use the SHAP plot and data to explain why the model arrived at this specific output.
We can get the following output from an LLM:
Justification:
- MedInc = 8.325: The median income in the block group is very high (8.325 is a high value for this dataset). It is logical that a higher income area would have more expensive houses. The model correctly identifies this as the strongest factor increasing the price.
- AveRooms = 6.984: An average of nearly 7 rooms per dwelling is also high. More rooms generally mean a larger, more valuable house. The model correctly identifies this as a factor pushing the price up.
- Longitude and Latitude: These features represent location. The specific coordinates (-122.2, 37.88) likely correspond to a desirable, high-value area (e.g., the San Francisco Bay Area in the California Housing dataset). The model has learned that this specific longitude heavily increases the price, while the latitude has a slight counter-active effect, possibly indicating a location that is slightly less premium than another nearby latitude.
Suddenly, our model's "brain" is understandable to the person signing the checks. That's a huge win. This turns our complex models from a black box into a valuable business partner.
What’s New
Claude Agent Skills
https://claude.com/blog/skills
Speaking of blending predictability and non-determinism, did you see Anthropic's recent announcement about "Skills" for Claude? This feels like a direct answer to the problem we've been discussing. The basic idea is that you can give Claude a folder of instructions, scripts, and resources for a specific task.
This is the brilliant part: these "Skills" can include executable code for jobs where traditional programming is just plain better and more reliable than probabilistic token generation. Think about that. Instead of trying to coax an LLM into formatting a complex JSON or CSV perfectly every single time, you give it a rock-solid Python script as a "Skill" and it just uses it. It's a move back towards determinism, giving us "less prompt wrangling" and "more predictable results" for the parts of our job that absolutely need it, while still letting the LLM handle the creative parts.
This "conductor" role is exactly what 'Skills' are built for. It forces us to think more like conductors of an orchestra than solo musicians. Instead of trying to make our "violinist" (the LLM) also play the drums (do complex, logical tasks), we can now hand that job to a dedicated "percussionist" (an executable script) by wrapping it in a Skill. Our job is shifting from pure prompt engineering to being systems integrators, or orchestrators, intelligently blending these two powerful forces—probabilistic creativity and deterministic logic—to solve problems. That, to me, is the most exciting part of this new era.
DeepSeek OCR
https://huggingface.co/deepseek-ai/DeepSeek-OCR
On the topic of specialized tools, another fascinating release is DeepSeek-OCR. For years, OCR has been a mostly "solved" but clunky problem. The new challenge is feeding massive, complex documents into LLMs, which costs a fortune in tokens. DeepSeek's approach is brilliant: it doesn't feed the text to the model; it feeds an image of the text. It calls this "Context Optical Compression," and it's incredibly efficient, compressing what might be thousands of text tokens into just a few hundred "vision tokens."
This isn't just a simple text dump, either. Because it's a Vision-Language Model, it understands the structure of the document—headings, columns, and even complex tables. It can output clean, structured Markdown from a messy PDF, something that was notoriously difficult before. This is another perfect example of a specialized, deterministic-style tool. It's an open-source "percussionist" built specifically for document understanding, freeing up the generalist LLM to do the creative work.
