Indexing in LangChain is the process of organizing documents in a vector database such that a language model can quickly find and use them. It works by turning documents into embeddings and keeping them synchronized in the store.
The Indexing API makes this easier by managing updates, avoiding duplicates and skipping re-computation for unchanged content.
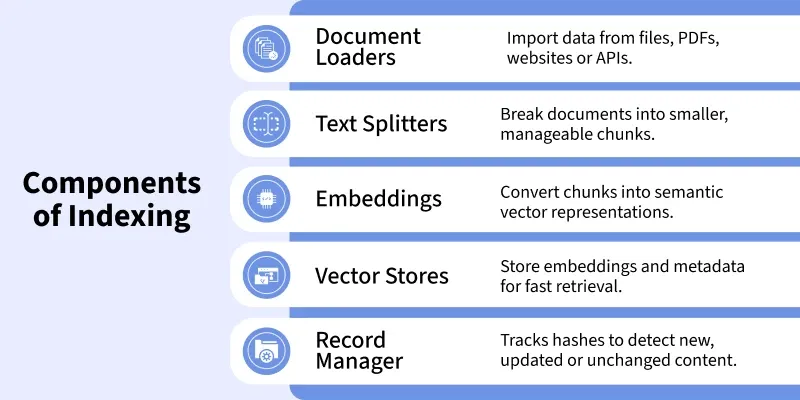
Importance of Indexing
Here’s why indexing matters when building retrieval based systems in LangChain:
- Efficiency and Cost Savings: Vector stores skip redundant computations, prevent duplication and support incremental updates to save storage and compute.
- Data Accuracy and Freshness: They keep the vector store synchronized with source documents, remove outdated content and maintain correct chunk mappings.
- Operational Benefits: Vector stores simplify workflows, improve RAG performance and support multiple indexing strategies.
- Core Functional Role: They organize documents for efficient semantic search and provide accurate, context aware information for LLMs in RAG applications.
Types of Indexes in LangChain
Different types of indexing are used in LangChain to organize and search data depending on the needs of the application.
- Vector Index: Stores document embeddings in a vector database for semantic search in RAG pipelines.
- Keyword Index: Uses inverted indexes for fast keyword based exact matches.
- Hybrid Index: Combines vector and keyword indexes to support both semantic and exact search.
- Metadata Index: Organizes documents by metadata like author, date or tags for filtering.
- Document Index: Stores raw documents or chunks with metadata as the base for further processing.
Working
Here is the working of Indexing in LangChain.
- Document Loading: Load data from sources like text files, PDFs, websites or APIs using a DocumentLoader.
- Text Splitting: Break large documents into smaller chunks with a TextSplitter so they fit within LLM limits.
- Hash Generation: Create a unique hash for each chunk to check if it is new, updated or unchanged.
- Record Manager Check: First run then if no match is found, chunks are embedded and stored. For later runs, skip unchanged chunks and only process new or updated ones.
- Embedding Generation: Convert chunks into vector embeddings using models like text-embedding-ada-002.
- Vector Store Insertion: Store embeddings with metadata in a vector database like FAISS, Pinecone, Weaviate, etc.
- Managing Outdated Documents: Remove old or deleted documents to keep the index up to date.
- Retrieval Ready: The indexed data can now be searched semantically to fetch relevant chunks for the LLM.
Implementation
Steps to implement Indexing in LangChain are:
Step 1: Install Dependencies
Installing LangChain core, OpenAI integration, FAISS for vector storage, dotenv for env vars and community modules.
!pip install langchain langchain-openai faiss-cpu python-dotenv langchain-community
Step 2: Import Libraries
Importing different LangChain's modules and Operating System.
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
import os
Step 3: Environment Setup
Setting up environment using OpenAI API Key, we can also use Gemini's API Key.
os.environ["OPENAI_API_KEY"] = "your-api-key"
Refer to this article for using OpenAI API Key: Fetching OpenAI API Key
Step 4: Load Document
Loading sample document.
loader = TextLoader("your .txt file")
documents = loader.load()
Step 5: Create and Store Embedding
Creating embeddings for documents and storing in a vector database.
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
Step 6: Retrieval
Using retriever in a Retrieval Chain.
query = "What is the company policy on remote work?"
results = retriever.get_relevant_documents(query)
print(results[0].page_content)
Output:

You can download the source code from here.
Indexing vs Retrieval
Comparison table between indexing and retrieval is mentioned below:
Aspect | Indexing | Retrieval |
|---|---|---|
Definition | The process of preparing, chunking, embedding and storing documents in a vector store. | The process of searching the vector store to fetch relevant chunks for a query. |
When it Happens | Done during data preparation or updates to source documents. | Done at query time when the LLM needs context to answer. |
Main Goal | Organize and synchronize data for efficient semantic search. | Provide the LLM with the most relevant and accurate context. |
Components | Document loaders, text splitters, embeddings, vector stores and record manager. | Query embedding, similarity search and retrieval chains. |
Output | A structured, latest vector index of documents. | A set of relevant document chunks passed to the LLM. |
Analogy | Like creating a library catalog that organizes all the books. | Like looking up the right book or page from the catalog to answer a question |
Applications
Indexing in LangChain is applied in several areas like:
- Enterprise Knowledge Management: Indexing company manuals, policies and reports into vector stores so employees can query them quickly.
- Healthcare: Organizing patient records, research papers and treatment guidelines into searchable embeddings for clinical decision support.
- Research Assistance: Indexing academic literature, author networks and citations to make knowledge discovery faster and more accurate.
- Legal and Compliance: Creating indexed repositories of laws, contracts and precedents to assist in legal research and audits.
- E-learning Platforms: Indexing lessons, quizzes and study material so learners can receive context aware assistance during courses.
Advantages
Some of the advantages of Indexing in LangChain are:
- Efficient Retrieval: Enables fast semantic search across large datasets by converting documents into embeddings.
- Accuracy in RAG: Improves context quality for Retrieval Augmented Generation systems reducing irrelevant or incorrect answers.
- Scalability: Works seamlessly with vector databases like Pinecone, FAISS or Weaviate to handle massive document collections.
- Reduced Redundancy: Prevents duplication and avoids re-embedding unchanged documents, saving compute resources.
- Data Organization: Keeps documents structured and synchronized in vector stores ensuring consistent and reliable query results.
Disadvantages
Some of the disadvantages of Indexing in LangChain are:
- Computational Cost: Generating embeddings for very large datasets requires high processing power and time.
- Storage Requirements: Persistent vector storage demands external databases increasing infrastructure needs.
- Complex Setup: Requires configuration of pipelines and vector stores which may be challenging for beginners.
- Update Latency: Frequently changing datasets need re-indexing which can slow down system performance.
- Maintenance Burden: Indexes must be monitored, cleaned and updated regularly to avoid stale or duplicated data.
