In recent times, a new set of models called Diffusion Models has gained popularity, especially for generating high-quality images. Among these, Denoising Diffusion Probabilistic Models (DDPMs) stand out due to their simplicity and ability to produce excellent results.
What is a Diffusion Model?
A diffusion model is a type of generative model. That means it can generate new data, like images, that look similar to real ones.
The key idea is:
- Start with random noise, and
- Gradually turn that noise into a meaningful image.
This is possible as it learns to reverse a noising process step by step.
“Diffusion” Process
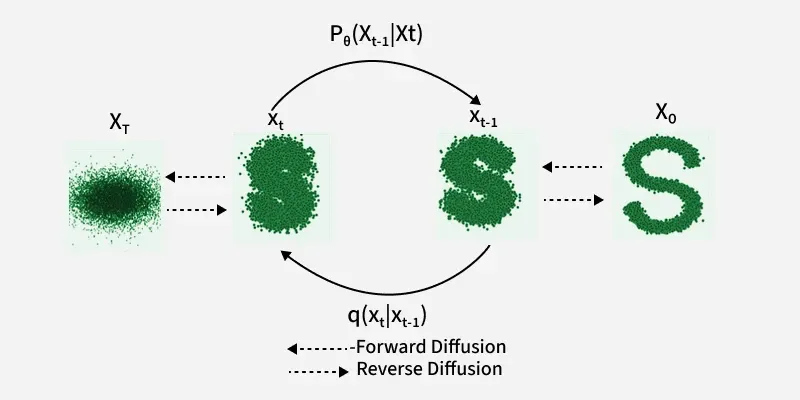
The diffusion process is a way of adding noise to an image over time. In DDPMs, this happens in two phases:
1. Forward Process (Adding Noise): We slowly add small amounts of noise to an image step-by-step, over many steps (say, 1000). By the end, the image becomes pure noise.
Let’s say:
x_0 : original imagex_1, x_2, ..., x_T : noisy versions of the imagex_T : pure noise after T steps
This process is predefined, and we know how the noise is added.
2. Reverse Process (Removing Noise): Now, we want to go backward: from pure noise
What is DDPM
Denoising Diffusion Probabilistic Models (DDPMs) are a type of diffusion model which learn to remove noise from an image at each step. Once trained, they can start from random noise and generate a new image step-by-step.
The Training Process
- Pick an image from the training dataset.
- Add noise to it for a random number of steps
t . - The model is trained to predict the noise that was added.
- This is repeated over many images and steps.
The training objective is to minimize the difference between the actual noise added and the noise the model predicts.
The Reverse Process (Image Generation)
Once the model is trained:
- Start with a random noisy image
x_T . - At each step
t , the model removes a bit of noise. - After many steps (like going from
x_T tox_0 ), you get a sharp, realistic image.
This step-by-step denoising is slow but accurate.
Improvements and Variants
Many improvements have been proposed, such as:
- DDIM (Denoising Diffusion Implicit Models): faster sampling
- Latent Diffusion Models: run diffusion in a smaller, compressed space (used in Stable Diffusion)
- Guided Diffusion: improves control (e.g. text-to-image prompts)
Applications of DDPMs
- Image generation: text-to-image, e.g. DALL·E 2, Stable Diffusion
- Inpainting: filling missing parts of images
- Super-resolution: making blurry images sharp
- Video and audio generation
- Medical imaging: denoising or generating scans
Limitations
- Slow sampling: Takes hundreds or thousands of steps to generate a single image.
- Compute-heavy: Requires strong hardware to train or run.
- Long training time: Needs lots of data and time to train well.
