Synthetic Data has evolved from being a solution for data scarcity into a foundational component of modern AI development. Today, it plays an important role in ensuring user privacy and promoting fairness in Machine Learning workflows. As industries face increasing regulatory pressure and data access limitations, synthetic data offers an effective alternative to real-world datasets.
What is Synthetic Data?
Synthetic data refers to artificially generated data that resembles the structure and statistical properties of real-world datasets. They are created using advanced techniques often powered by Generative AI, synthetic data resembles actual data without revealing sensitive or identifiable information.
As synthetic data lacks direct relations with real individuals or transactions, it is widely used for training machine learning models, testing systems and supplementing incomplete datasets. Industries like finance, healthcare and insurance particularly benefit from synthetic data due to their strict privacy and regulatory constraints.
How Synthetic Data is generated
Synthetic data is created using a range of techniques that fall into three main categories: machine learning-based models, agent-based models and hand-engineered methods. Each approach is chosen based on the desired level of realism and the specific use case.
1. Machine Learning-Based Models
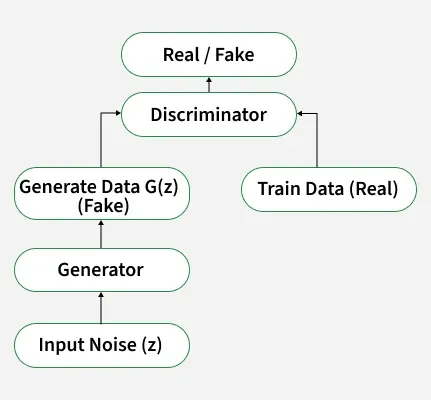
- Generative Adversarial Networks (GANs): GANs consist of two neural networks, the generator and the discriminator. The generator creates synthetic data, while the discriminator evaluates its authenticity. GANs are widely used for generating synthetic images, time series and textual data.
- Variational Autoencoders (VAEs): VAEs combine neural networks with probabilistic modeling. They encode input data and then decode it to generate highly realistic synthetic data that preserves the original structure and features.
- Gaussian Copula Models: These statistical models generate synthetic data based on known distributions. They often assume a normal (Gaussian) structure. They are particularly suited for discrete or categorical datasets, such as event probabilities.
- Transformer-Based Models: Models like GPT (Generative Pre-trained Transformers) are trained on large datasets to learn deep contextual patterns. They are highly effective for generating synthetic text.
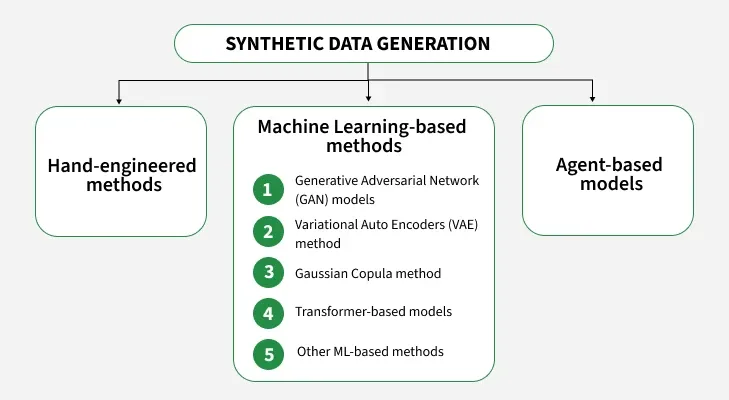
2. Agent-Based Models
- Traffic Simulation: Simulates the movement of individual vehicles, capturing rules like acceleration and lane switching to produce synthetic traffic flow data for transportation planning.
- Epidemiological Models: Simulate disease spread by modeling individuals (agents) and their interactions. This helps generate synthetic data for studying public health conditions and predicting outbreaks.
- Market Simulation: Used in financial markets to replicate the actions of diverse trader agents. These models generate synthetic market behavior data to test trading strategies and risk models.
3. Hand-Engineered Methods
- Rule-Based Generation: Synthetic records are created using predefined rules. For example, generating new sales transactions with randomized amounts and realistic purchase dates.
- Parametric Models: Use mathematical equations to describe the underlying distribution. Synthetic data is then sampled from these parameterized models.
- Random Sampling: Generates synthetic data by randomly selecting or resampling from the original dataset, often used for simple datasets like demographics.
- Linear Interpolation: For time-series data, this method creates new data points between existing ones to smooth or expand the dataset.
Types of Synthetic Data
1. By Data Format
- Synthetic Text : Artificially generated text data is commonly used in natural language processing (NLP) tasks. It helps in training models when real-world textual data is scarce or contains sensitive information that cannot be exposed.
- Synthetic Media : This includes synthetic images, videos and audio clips, widely used in computer vision. These datasets enable tasks such as object detection, facial recognition, image captioning and speech synthesis without relying on large volumes of real media.
- Synthetic Tabular Data : Structured in rows and columns like traditional databases, synthetic tabular data is often used for software testing, machine learning, and data analytics. It helps fill gaps in real-world datasets and simulate rare scenarios.
2. By Synthetic Composition
- Fully Synthetic Data : This type is entirely generated by algorithms with no direct link to real-world records. AI models analyze the statistical patterns of original datasets and create completely artificial records that mimic the same distributions.
- Partially Synthetic Data : Only sensitive or high-risk fields in the dataset are replaced with synthetic values. The rest of the data remains intact, preserving structure and relationships.
- Hybrid Synthetic Data : Hybrid datasets aim to balance realism and privacy. Real records are mixed with synthetic ones or certain sensitive attributes are masked and replaced. This approach provides the advantages of real data insights while significantly reducing privacy risks.
Evaluation of Synthetic Data

- Fidelity : Fidelity refers to how closely synthetic data replicates the statistical characteristics of the original dataset. High-fidelity data preserves correlations, distributions and structural properties found in real data. This ensures the synthetic version behaves similarly to real data.
- Utility : Utility measures how effectively synthetic data serves its intended purpose. Good utility means the synthetic data shows similar insights and performance outcomes as the real data would, making it a reliable substitute for development and evaluation.
- Privacy : Privacy focuses on how well synthetic data safeguards sensitive information. It should prevent re-identification of individuals and ensure that no personal information or protected attributes can be inferred. High privacy standards in synthetic data regulate compliance risks and protect against security breaches or misuse.
Example : Generating Synthetic Tabular Data Using GANs
1. Installing and Importing Libraries
- SDV(Synthetic Data Vault) is a library that provides various tools to generate synthetic data (data that mimics the statistical properties of real data).
CTGANsynthesizeris a model that uses Conditional Generative Adversarial Networks (CGANs) to generate synthetic data. This model learns the distribution of real data and uses that information to generate new data points.
pip install sdv
import pandas as pd
from sdv.single_table import CTGANSynthesizer
from sdv.metadata import SingleTableMetadata
from sklearn.datasets import load_diabetes
2. Loading the dataset
data = load_diabetes()
df = pd.DataFrame(data.data, columns=data.feature_names)
3. Metadata
Metadata is a blueprint that tells SDV what kind of data each column contains and how to interpret and process that data when training a synthesizer like CTGAN.
metadata = SingleTableMetadata()
metadata.detect_from_dataframe(df)
4. Initialize and Train the model
model = CTGANSynthesizer(metadata=metadata)
model.fit(df)
5. Generate Synthetic Samples
synthetic_df = model.sample(num_rows=5)
6. Print both real data and synthetic data
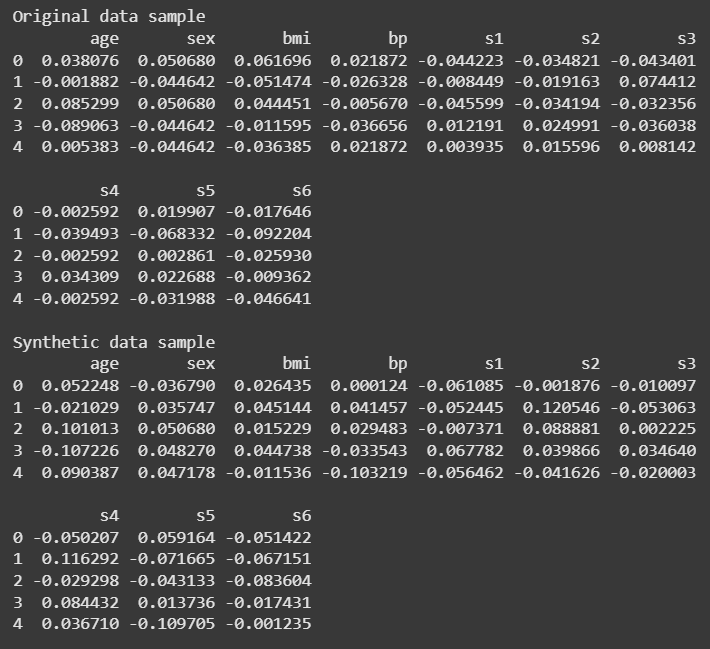
print("Original data sample")
print(df.head(), "\n")
print("Synthetic data sample")
print(synthetic_df)
Output
Key Applications of Synthetic Data
1. Training Robust Machine Learning Models: Synthetic data enables the creation of large, labeled datasets without manual intervention. For computer vision tasks like object detection in self-driving cars or facial recognition systems, synthetic data can simulate rare edge cases such as bad weather or specific demographic attributes.
2. Privacy-Preserving AI Development: As real-world data is becoming harder to access due to privacy laws, synthetic data offers the solution. Organizations can train AI models on data that mimics statistical properties of real datasets without compromising user confidentiality.
3. Bias Mitigation and Fairness: AI models are only as good as the data they learn from. If a dataset is biased, the model will be too. Synthetic data allows for careful design of datasets that represents diverse groups and edge cases, which helps in reducing bias in predictions.
4. Testing and Validation at Scale: Synthetic data enables thorough validation of systems under controlled yet varied conditions. In cybersecurity and finance models can be tested against synthetic attack scenarios or market shifts.
